正期望策略也可能因为下注规模失误而爆仓。我们从公式推导一路讲到策略组合,剖析凯利公式:为什么 full Kelly 很危险,分数凯利如何用一半的波动率换来 75% 的增长,以及在量化交易中真正可用的仓位配方是什么。文章中段有一个交互式计算器,让你直观看到凯利比例如何牵动收益与风险。
任何策略都必须回答的那个问题
你有一个具备正向优势(edge)的策略:长期来看它能赚钱。剩下的只有一个细节——单笔交易该投入多少比例的资本,或者一个策略该分配多少资本。
这不是次要问题,而是核心问题。正的数学期望并不能让你免于爆仓:押注太多——一连串失利就会把账户拖进一个统计上无法回归的区域(见 盈亏的不对称性)。押注太少——你又会把大部分潜在增长白白留在桌上。
凯利公式给出了精确答案:它是那个能最大化长期增长速度的资本比例——是几何增长,而非算术增长。正是几何增长决定了你的账户在一千笔交易后会落在哪里,因为收益是相乘的,而不是相加的(见 收益的乘法本质)。
公式从何而来:最大化资本的对数
凯利(1956)以及之后索普的核心思想是:需要优化的不是单笔交易的期望利润,而是最终资本的期望对数。对数的出现并非偶然——它是唯一一个在最大化时能让资本以最大几何速度增长的函数。
二元情形:有两种结果的下注
设以概率 ,下注每单位带来净赔付 (赔率),而以概率 ,我们输掉本金。我们押上资本的比例 。一笔交易后,赢时资本乘以 ,输时乘以 。
期望对数增长:
对 求导并令其为零:
解出来就是凯利公式:
用文字说:最优比例等于你的优势除以赔率。没有优势()——就不下注。
示例
某策略在 55% 的交易中获胜,赔付比为 1:1():
full Kelly 要求每笔交易拿 10% 的资本去冒险。记住这个数字——下文我们会看到,为什么几乎没人应该恰好押这么多。
连续情形:用收益率代替下注
在交易中,一笔交易很少表现为只有两种结果的下注——存在的是一个收益率分布。对于单期均值为 、方差为 的收益率,在杠杆(比例) 下的期望对数增长近似等于:
最大值在以下处取得:
这就是著名的凯利连续形式(也叫默顿比例)。而最优点处的增长速度与夏普比率 的关系优美到了极致:
一个值得挂在墙上的结论:组合的最大几何增长速度等于其夏普比率平方的一半。夏普翻倍——资本增长速度就翻四倍。
为什么 full Kelly 太过头了
公式给出的是关于增长的数学最优。但这个最优有一个公式没有说出的代价:路径的可怕波动和回撤,任何真实账户、任何真实的人都会在这上面崩溃。
偏离最优点的几何
把比例 (其中 是凯利乘子: 是 full Kelly, 是 half Kelly)代入增长公式。相对于最大值,我们得到:
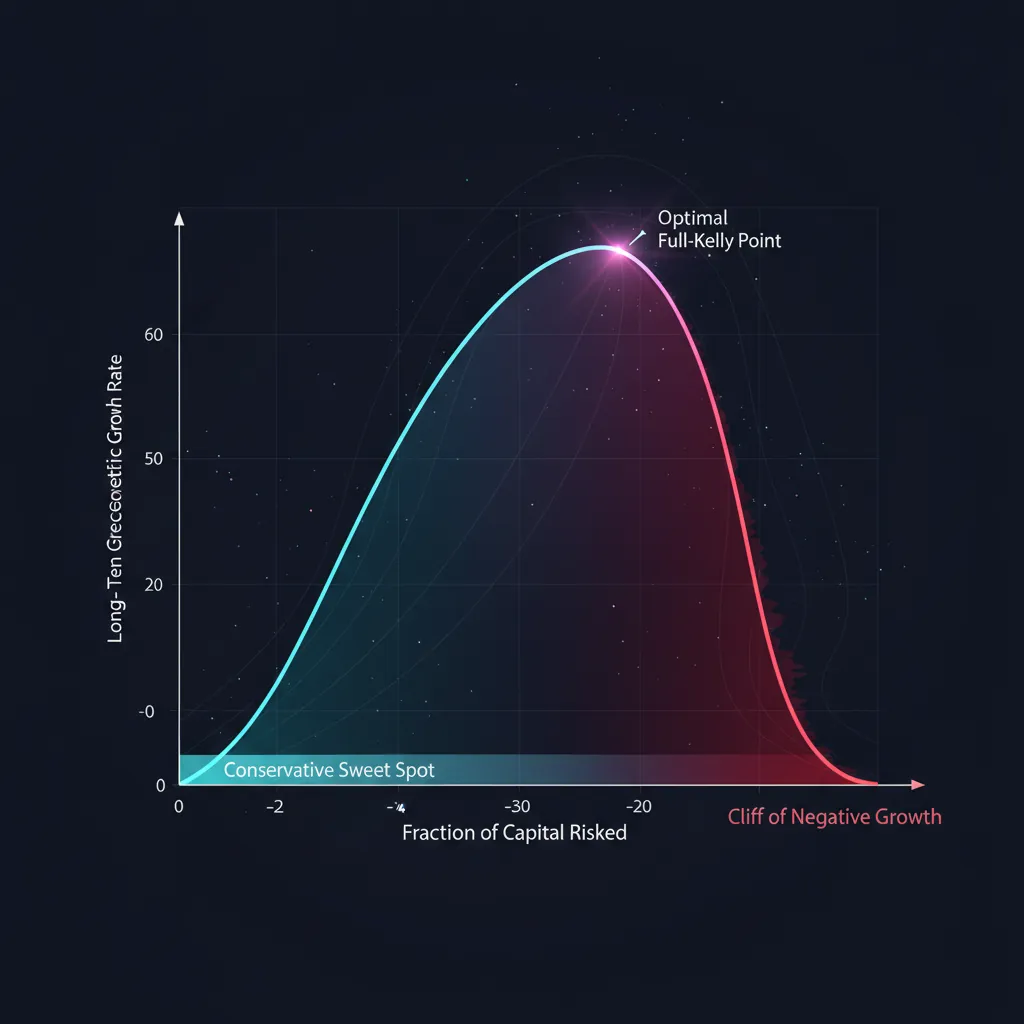
这条抛物线用一行字讲完了风险管理的全部故事:
| 乘子 | 增长占比 | 波动率 | 评注 |
|---|---|---|---|
| 0.25 (quarter) | 43.8% | 25% | 用四分之一的风险拿到近一半的增长 |
| 0.50 (half) | 75.0% | 50% | 实战者的黄金中道 |
| 1.00 (full) | 100.0% | 100% | 增长最大,波动疯狂 |
| 1.50 | 75.0% | 150% | 与 half 相同的增长,但风险高三倍 |
| 2.00 (double) | 0.0% | 200% | 没有增长,风险最大 |
| > 2.00 | 负值 | — | 即便 edge 为正也会爆仓 |
三个结论:
- half Kelly 用一半的波动率拿走 75% 的增长。 从风险/收益比来看,这远好于 full Kelly。
- 抛物线关于 对称。 押 凯利得到的增长与 相同,但波动高三倍。过头比不足受到的惩罚更狠。
- 在 凯利处增长归零,再往后就变成负的。即便是一个能赢的策略,过于激进的仓位也会杀死资本。
full Kelly 的回撤:一个让人清醒的公式
对于连续模型,资本曾经跌到初始值某个比例 的概率等于:
代入各凯利档位——就得到这张表,看完之后 full Kelly 就不再显得有吸引力了:
| 乘子 | P(曾经 −50%) | P(曾经 −75%) |
|---|---|---|
| 1.00 (full) | 50% | 75% |
| 0.50 (half) | 12.5% | 1.6% |
| 0.25 (quarter) | 0.78% | 0.006% |
| 2.00 (double) | 100% | 100% |
在 full Kelly 下,账户在某个时刻经历 50% 回撤的概率等于 50%。这不是尾部情景——这是抛硬币。half Kelly 把它压到 12.5%,quarter Kelly——压到不到一个百分点。而且这还是在理想化的高斯模型里;现实中的肥尾会让实际回撤更深。
计算器:调整凯利比例——观察收益与风险
拖动滑块。上面两个设定策略的优势(获胜概率和赔付率),下面那个是凯利乘子 。看资本增长速度和深度回撤概率如何同时变化。注意文章的主线情节:当从 half 移向 full Kelly 时,增长只涨了一点点,而回撤风险——成倍上升。
把凯利比例滑块在 0.5 和 1.0 附近来回拨一拨:相对最大值的增长从 75% 升到 100%,而 50% 回撤的风险却从 13% 跳到 50%。这正是专业人士活在抛物线左半边的原因。
分数 Kelly 作为行业标准
严肃的管理人几乎从不押 full Kelly。典型区间是 到 凯利。除了回撤之外,还有四个根本性的理由去削减比例。
1. 参数估计误差。 公式假设你知道真实的 、、、。而实际上你是在用有限样本去估计它们。增长函数又是不对称的:高估优势会把你推到最优点之外,那里增长下跌的速度比同等幅度低估时增长上涨的速度更快。如果真实凯利为 ,而你带误差地估计了它,那么系统性地押少一些会更安全。粗略规则:估计存在不确定性时,把比例减半。
2. 非平稳性。 策略的优势不是常数——市场状态会变,edge 会衰减,竞争对手会复制你的想法。用昨天的数据算出的凯利,到了明天可能就偏高了。分数乘子是应对 edge 衰减的缓冲垫。
3. 肥尾。 高斯公式 低估了极端波动的风险。在现实中具有重尾的分布上,它会系统性地下注过头。分数 Kelly 在一定程度上补偿了这一点。
4. 业务上回撤的成本。 对做市商而言,回撤不只是心理问题。它意味着追加保证金、在最糟糕的时刻被迫减仓、投资者资本流出、融资成本上升(见 funding rates 如何杀死杠杆)。一条平滑的资本曲线本身就有独立的价值,而凯利公式里并没有这一项。
策略组合的 Kelly
到目前为止我们谈的都是单一策略。但真正的问题是复数意义上的为多个策略选择凯利:你有好几个策略,需要在它们之间分配资本。
朴素的做法——为每个策略单独算凯利再相加——是灾难性地错误,因为它忽略了相关性。两个高度相关的策略,本质上就是一个加倍的下注,总风险必须按一个来算。
矩阵形式
对于期望收益向量 和协方差矩阵 ,一次性求出所有策略的最优比例向量:
最优点处的增长速度推广为组合夏普的平方:
请注意: 正是最大夏普组合(切点组合)的方向。凯利和均值-方差优化是同一枚硬币的两面:凯利只是把杠杆水平固定在那个能最大化几何增长的水平上。
协方差逆矩阵在做什么
- 相关的策略分摊风险预算。 如果两个策略几乎相同,矩阵会把它们的总比例削减到一个策略的水平——自动完成,不需要手工打补丁。
- 不相关的策略获得分散化溢价。 它们可以保持在接近各自单独的规模,而组合的总夏普会高于其中任何一个。
- 负相关的策略可能获得加大的比例——它们互相对冲,矩阵会鼓励这一点。
关于估计 的警告
协方差矩阵求逆在数值上是不稳定的:在有噪声的估计上, 会把微小误差放大成离谱的权重。协方差向对角线的收缩(shrinkage)、杠杆约束以及同一个分数乘子都是必须的。没有这些,矩阵凯利会给出在回测上漂亮、在实盘中致命的比例。
量化交易与做市的修正
纯粹的公式活在一个无菌的世界里。在真实的引擎中需要做修正。
- 手续费和滑点 会削减有效优势。请用扣除所有成本之后的收益率来算凯利,否则你会系统性地下注过头。
- 下注的离散性和手数 让你无法恰好押到 ——请向下取整,而不是向上。
- 非平稳的 edge 需要随时间重新计算:用带半衰期的滑动窗口去估计 和 ,而不是用全部历史。
- 回撤约束。 在凯利之上设一个硬上限:最大回撤、最大杠杆、单策略最大比例。存在正式的带回撤约束的凯利版本(Bassett、Boyd),但实践中一个简单的上限就够了。
- 诚实评估 edge。 最大的错误是把样本内(in-sample)测出来的优势喂给凯利。只取样本外(out-of-sample)的估计,走 walk-forward,扣除手续费之后。喂进公式的 edge 被高估了——出来的下注就被高估了。
配方:如何应用
- 诚实地评估优势。 样本外、走 walk-forward、扣除手续费和滑点。这是最重要的一步——输入端的垃圾会在输出端变成爆仓。
- 算出 full Kelly。 离散结果用二元式 ,收益率用连续式 。
- 取一个分数。 默认是 full Kelly 的 –。edge 越不稳定——乘子就越小。
- 组合就用矩阵算。 ,对协方差做收缩,然后用同一个分数乘子。
- 设硬性上限。 单仓位上限、杠杆上限、回撤限制——凌驾于一切之上。
- 重新计算。 随着估计的更新,在不确定性上升和 edge 衰减时削减比例。
代码
import numpy as np
def kelly_binary(p, b):
"""p — 获胜概率,b — 每 1 单位下注的净赔付率。"""
q = 1 - p
return (b * p - q) / b # = p - q/b
def kelly_continuous(mu, sigma):
"""mu, sigma — 单期收益率的均值和标准差(同一单位)。"""
return mu / sigma ** 2
def kelly_portfolio(mu, cov, shrink=0.0):
"""策略组合的矩阵凯利。
mu — 期望收益向量;
cov — 收益率的协方差矩阵;
shrink — 向对角线收缩的系数(0..1),用于求逆的稳定性。"""
cov = np.asarray(cov, float)
if shrink:
cov = (1 - shrink) * cov + shrink * np.diag(np.diag(cov))
return np.linalg.solve(cov, np.asarray(mu, float))
def sized(f_star, kelly_fraction=0.25, cap=0.2):
"""带比例硬上限的分数凯利。"""
return float(np.clip(f_star * kelly_fraction, -cap, cap))
f = kelly_binary(p=0.55, b=1.0) # 0.10 — full Kelly
print(sized(f)) # 0.025 — quarter Kelly,安全的规模
常见错误
- 在样本内 edge 上用凯利。 最昂贵的错误。被高估的优势 → 下注过头 → 负增长。
- 忽略策略之间的相关性。 单个凯利之和不等于组合凯利。
- 在实盘中用 full Kelly。 增长的数学最大值,但有 50% 的概率回撤掉一半本金。几乎不适合任何人。
- 在不稳定的 edge 上用凯利。 如果优势在衰减,公式会系统性地高估下注。
- 混淆目标。 凯利最大化的是资本的几何增长——不是夏普,不是保持盈利的概率,也不是舒适度。如果你更看重曲线的平滑,那就有意识地押分数凯利。
总结
凯利公式用一个最大化长期几何增长的公式,回答了任何策略的核心问题——押多少:下注用 ,收益率用 ,组合则用 。
但 full Kelly 是关于增长的数学最优,而非关于存活的最优。分数 Kelly(–)用成倍更小的波动和回撤,拿走了大部分增长。所以关于为策略选择凯利这个问题,实战上的答案是这样的:诚实地算出 full Kelly——然后只押它的一个分数,并凌驾于硬性风险限额之上。
相关阅读:
Authors

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.