Criterio di Kelly per le strategie: come scegliere la dimensione della posizione e allocare il capitale

Una strategia con aspettativa matematica positiva può mandare in rovina il deposito se si sbaglia la dimensione della puntata. Analizziamo il criterio di Kelly dalla derivazione della formula al portafoglio di strategie: perché il full Kelly è pericoloso, come il Kelly frazionario offre il 75% della crescita a metà della volatilità, e quale ricetta di sizing applicare davvero nel trading algoritmico. A metà articolo trovi un calcolatore interattivo dove si vede come la frazione di Kelly sposta rendimento e rischio.
La domanda a cui ogni strategia deve rispondere
Hai una strategia con un vantaggio positivo (edge): sulla lunga distanza guadagna. Resta un solo dettaglio: quale frazione di capitale puntare in una singola operazione o destinare a una singola strategia.
Non è una domanda secondaria, è quella principale. Un'aspettativa matematica positiva non salva dalla rovina: punta troppo e una serie di insuccessi porterà il deposito in una zona da cui non c'è ritorno statistico (vedi Asimmetria tra perdite e profitti). Punta troppo poco e lascerai sul tavolo gran parte della crescita potenziale.
Il criterio di Kelly fornisce la risposta esatta: è la frazione di capitale che massimizza la velocità di crescita di lungo periodo, quella geometrica e non quella aritmetica. È proprio la crescita geometrica a determinare dove sarà il tuo conto dopo mille operazioni, perché i rendimenti si moltiplicano e non si sommano (vedi Natura moltiplicativa dei rendimenti).
Da dove arriva la formula: la massimizzazione del logaritmo del capitale
L'idea chiave di Kelly (1956) e poi di Thorp: non bisogna ottimizzare il profitto atteso di una singola operazione, ma il logaritmo atteso del capitale finale. Il logaritmo non compare per caso: è l'unica funzione la cui massimizzazione fa crescere il capitale alla massima velocità geometrica.
Caso binario: una puntata con due esiti
Supponiamo che con probabilità la puntata porti una vincita netta per unità (quota), e che con probabilità si perda la puntata stessa. Puntiamo una frazione del capitale. Dopo un'operazione il capitale viene moltiplicato per in caso di vincita e per in caso di perdita.
Logaritmo atteso della crescita:
Calcoliamo la derivata rispetto a e la poniamo uguale a zero:
La soluzione è proprio la formula di Kelly:
In parole: la frazione ottimale è pari al tuo vantaggio diviso per la quota. Nessun vantaggio (), nessuna puntata.
Esempio
Una strategia vince nel 55% delle operazioni con un rapporto di vincita 1:1 ():
Il full Kelly impone di rischiare il 10% del capitale per operazione. Tieni a mente questo numero: più avanti vedremo perché quasi nessuno dovrebbe puntare esattamente tanto.
Caso continuo: rendimenti al posto delle puntate
Nel trading un'operazione raramente si presenta come una puntata con due esiti: c'è una distribuzione di rendimenti. Per rendimenti con media e varianza per periodo, la crescita logaritmica attesa con leva (frazione) è approssimativamente:
Il massimo si raggiunge in:
È la celebre forma continua di Kelly (nota anche come frazione di Merton). E la velocità di crescita all'ottimo è legata allo Sharpe ratio in modo straordinariamente elegante:
Una conclusione da appendere al muro: la massima velocità di crescita geometrica di un portafoglio è pari a metà del quadrato del suo Sharpe. Raddoppia lo Sharpe e quadruplichi la velocità di crescita del capitale.
Perché il full Kelly è troppo
La formula fornisce l'ottimo matematico per la crescita. Ma questo ottimo ha un prezzo di cui la formula tace: una mostruosa volatilità del percorso e drawdown su cui si rompono qualunque conto reale e qualunque persona reale.
Geometria dello scostamento dall'ottimo
Sostituiamo la frazione (dove è il moltiplicatore di Kelly: è full Kelly, è half Kelly) nella formula della crescita. Rispetto al massimo otteniamo:
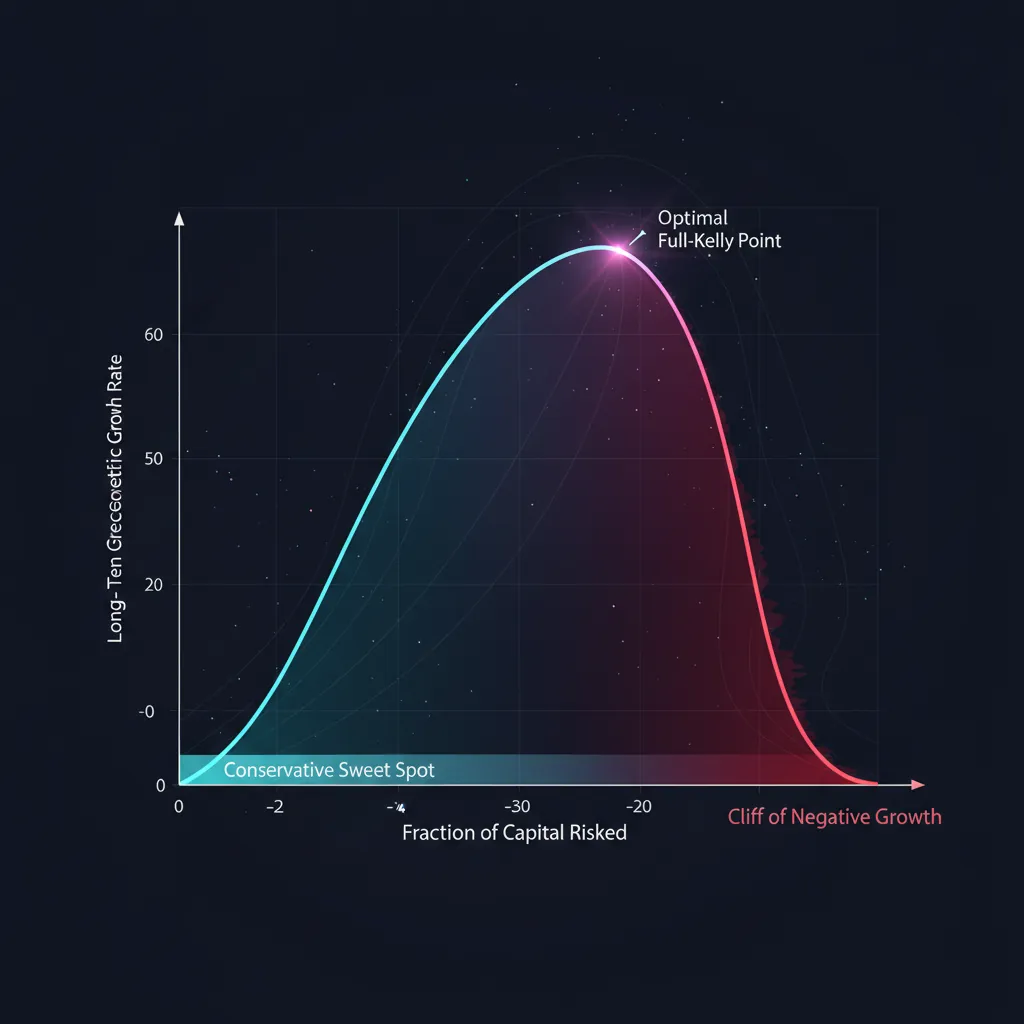
Questa parabola racconta tutta la storia del risk management in una sola riga:
| Moltiplicatore | Quota di crescita | Volatilità | Commento |
|---|---|---|---|
| 0.25 (quarter) | 43.8% | 25% | quasi metà della crescita a un quarto del rischio |
| 0.50 (half) | 75.0% | 50% | il giusto mezzo dei professionisti |
| 1.00 (full) | 100.0% | 100% | massima crescita, volatilità selvaggia |
| 1.50 | 75.0% | 150% | stessa crescita dell'half, ma rischio triplo |
| 2.00 (double) | 0.0% | 200% | nessuna crescita, rischio massimo |
| > 2.00 | negativa | — | rovina pur con edge positivo |
Tre conclusioni:
- L'half Kelly cattura il 75% della crescita a metà della volatilità. In termini di rapporto rischio/rendimento è nettamente migliore del full Kelly.
- La parabola è simmetrica rispetto a . Puntare a Kelly dà la stessa crescita di , ma è tre volte più volatile. L'eccesso è punito più duramente del difetto.
- A Kelly la crescita si azzera e oltre diventa negativa. Un sizing troppo aggressivo uccide il capitale anche con una strategia vincente.
I drawdown del full Kelly: una formula che fa tornare la lucidità
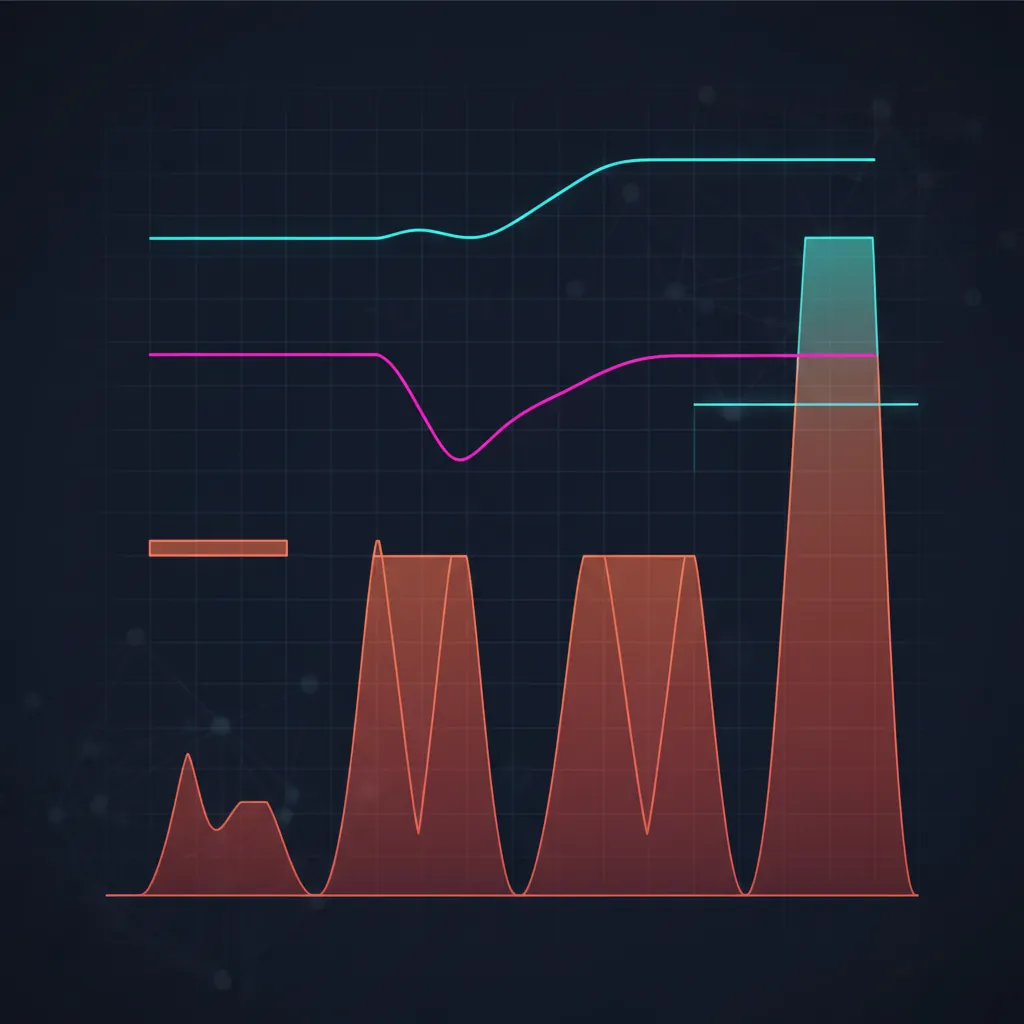
Per il modello continuo, la probabilità che il capitale scenda prima o poi alla frazione di quello iniziale è pari a:
Sostituiamo i livelli di Kelly e otteniamo una tabella dopo la quale il full Kelly smette di sembrare allettante:
| Moltiplicatore | P(mai −50%) | P(mai −75%) |
|---|---|---|
| 1.00 (full) | 50% | 75% |
| 0.50 (half) | 12.5% | 1.6% |
| 0.25 (quarter) | 0.78% | 0.006% |
| 2.00 (double) | 100% | 100% |
Con il full Kelly la probabilità di vedere prima o poi un drawdown del 50% è pari al 50%. Non è uno scenario di coda: è un lancio di moneta. L'half Kelly la abbatte al 12.5%, il quarter Kelly a una frazione di punto percentuale. E questo in un modello gaussiano idealizzato; le code spesse reali rendono i drawdown effettivi ancora più profondi.
Calcolatore: cambia la frazione di Kelly e osserva rendimento e rischio
Muovi i cursori. I due in alto definiscono il vantaggio della strategia (probabilità di vincita e quota di vincita), quello in basso il moltiplicatore di Kelly . Osserva come cambiano contemporaneamente la velocità di crescita del capitale e la probabilità di un drawdown profondo. Nota il filo conduttore dell'articolo: passando dall'half al full Kelly la crescita aumenta di poco, mentre il rischio di drawdown aumenta in modo proporzionale.
Gioca con il cursore della frazione di Kelly intorno ai valori 0.5 e 1.0: la crescita rispetto al massimo sale dal 75% al 100%, ma il rischio di un drawdown del 50% salta dal 13% al 50%. È proprio questo il motivo per cui i professionisti vivono nella metà sinistra della parabola.
Il Kelly frazionario come standard di settore
I gestori seri quasi mai puntano il full Kelly. L'intervallo tipico va da a Kelly. Oltre ai drawdown ci sono quattro motivi fondamentali per tagliare la frazione.
1. Errore di stima dei parametri. La formula presuppone che tu conosca i veri , , , . In realtà li stimi su un campione finito. E la funzione di crescita è asimmetrica: una sopravvalutazione del vantaggio ti spinge oltre l'ottimo, dove la crescita cala più rapidamente di quanto aumenti a parità di sottovalutazione. Se il vero Kelly è e lo hai stimato con un errore, è più sicuro puntare sistematicamente di meno. Regola grossolana: in presenza di incertezza nella stima, dimezza la frazione.
2. Non stazionarietà. Il vantaggio di una strategia non è una costante: i regimi di mercato cambiano, l'edge decade, i concorrenti copiano l'idea. Un Kelly calcolato sui dati di ieri domani può rivelarsi sovrastimato. Il moltiplicatore frazionario è un cuscinetto contro il decadimento dell'edge.
3. Code spesse. La formula gaussiana sottostima il rischio di movimenti estremi. Su distribuzioni reali a code pesanti si sovraespone sistematicamente. Il Kelly frazionario compensa in parte questo effetto.
4. Costo del drawdown nel business. Per un market maker il drawdown non è solo psicologia. Sono margin call, riduzione forzata delle posizioni nel momento peggiore, deflusso di capitale degli investitori, aumento del costo di finanziamento (vedi Come i funding rate uccidono la leva). Una curva del capitale liscia ha un valore proprio, assente nella formula di Kelly.
Kelly per un portafoglio di strategie
Finora abbiamo parlato di una singola strategia. Ma la vera domanda è la scelta di Kelly per le strategie al plurale: hai più strategie e devi allocare il capitale tra di esse.
L'approccio ingenuo — calcolare il Kelly di ciascuna separatamente e sommarli — è catastroficamente sbagliato, perché ignora le correlazioni. Due strategie fortemente correlate sono, di fatto, un'unica puntata raddoppiata, e il rischio complessivo va calcolato come per una sola.
Forma matriciale
Per il vettore dei rendimenti attesi e la matrice di covarianza , il vettore ottimale delle frazioni su tutte le strategie in un colpo solo:
La velocità di crescita all'ottimo si generalizza al quadrato dello Sharpe di portafoglio:
Nota: è la direzione del portafoglio con massimo Sharpe (il portafoglio tangente). Kelly e l'ottimizzazione mean-variance sono due facce della stessa medaglia: Kelly fissa semplicemente il livello di leva su quello che massimizza la crescita geometrica.
Cosa fa l'inversa della covarianza
- Le strategie correlate dividono il budget di rischio. Se due strategie sono quasi identiche, la matrice riduce la loro frazione complessiva al livello di una sola, automaticamente, senza espedienti manuali.
- Le strategie non correlate ricevono un premio per la diversificazione. Si possono tenere più vicine alle dimensioni individuali, mentre lo Sharpe complessivo del portafoglio sarà superiore a ciascuno preso singolarmente.
- Le strategie negativamente correlate possono ricevere frazioni maggiorate: si fanno da assicurazione a vicenda, e la matrice lo incentiva.
Avvertenza sulla stima di
L'inversione della matrice di covarianza è numericamente instabile: su stime rumorose amplifica piccoli errori in pesi assurdi. Sono obbligatori lo shrinkage della covarianza verso la diagonale, il limite sulle leve e lo stesso moltiplicatore frazionario. Senza di ciò il Kelly matriciale produce frazioni belle in backtest e letali in produzione.
Correzioni per trading algoritmico e market making
La formula pura vive in un mondo sterile. In un motore reale servono correzioni.
- Commissioni e slippage riducono il vantaggio effettivo. Calcola il Kelly sui rendimenti al netto di tutti i costi, altrimenti ti sovraesponi sistematicamente.
- Discretizzazione delle puntate e lottizzazione non permettono di puntare esattamente : arrotonda per difetto, non per eccesso.
- Un edge non stazionario richiede un ricalcolo nel tempo: stime di e su finestra mobile con un periodo di emivita, non su tutta la storia.
- Limite sul drawdown. Sopra Kelly imponi un tetto rigido: massimo drawdown, massima leva, massima frazione su una singola strategia. Esistono versioni formali di Kelly con vincolo di drawdown (Bassett, Boyd), ma in pratica basta un semplice cap.
- Onestà nella stima dell'edge. L'errore principale è alimentare Kelly con un vantaggio misurato in-sample. Prendi solo la stima out-of-sample, su walk-forward, al netto delle commissioni. Un edge sovrastimato in ingresso alla formula significa una puntata sovrastimata in uscita.
Ricetta: come applicarlo
- Stima il vantaggio onestamente. Out-of-sample, su walk-forward, al netto di commissioni e slippage. È il passo più importante: spazzatura in ingresso si trasforma in rovina in uscita.
- Calcola il full Kelly. Binario per esiti discreti oppure continuo per i rendimenti.
- Prendi una frazione. Per default – del full Kelly. Meno è stabile l'edge, più piccolo il moltiplicatore.
- Per il portafoglio calcola in forma matriciale. con shrinkage della covarianza, poi lo stesso moltiplicatore frazionario.
- Imposta cap rigidi. Massimo per posizione, massimo di leva, limite di drawdown, sopra ogni cosa.
- Ricalcola. Man mano che le stime si aggiornano, taglia la frazione al crescere dell'incertezza e al decadere dell'edge.
Codice
import numpy as np
def kelly_binary(p, b):
"""p — probabilità di vincita, b — quota di vincita netta per 1 unità di puntata."""
q = 1 - p
return (b * p - q) / b # = p - q/b
def kelly_continuous(mu, sigma):
"""mu, sigma — media e deviazione standard del rendimento per periodo (nelle stesse unità)."""
return mu / sigma ** 2
def kelly_portfolio(mu, cov, shrink=0.0):
"""Kelly matriciale per un portafoglio di strategie.
mu — vettore dei rendimenti attesi;
cov — matrice di covarianza dei rendimenti;
shrink — coefficiente di shrinkage verso la diagonale (0..1) per la stabilità dell'inversione."""
cov = np.asarray(cov, float)
if shrink:
cov = (1 - shrink) * cov + shrink * np.diag(np.diag(cov))
return np.linalg.solve(cov, np.asarray(mu, float))
def sized(f_star, kelly_fraction=0.25, cap=0.2):
"""Kelly frazionario con cap rigido sulla frazione."""
return float(np.clip(f_star * kelly_fraction, -cap, cap))
f = kelly_binary(p=0.55, b=1.0) # 0.10 — full Kelly
print(sized(f)) # 0.025 — quarter Kelly, dimensione sicura
Errori frequenti
- Kelly su edge in-sample. L'errore più costoso. Vantaggio sovrastimato → sovraesposizione → crescita negativa.
- Ignorare le correlazioni tra le strategie. La somma dei Kelly individuali non è il Kelly di portafoglio.
- Full Kelly in produzione. Massimo matematico di crescita, ma 50% di probabilità di un drawdown di metà deposito. Non va bene quasi a nessuno.
- Kelly con un edge instabile. Se il vantaggio decade, la formula sovrastima sistematicamente la puntata.
- Confusione degli obiettivi. Kelly massimizza la crescita geometrica del capitale, non lo Sharpe, non la probabilità di restare in positivo e non il comfort. Se per te conta di più la liscezza della curva, punta consapevolmente un Kelly frazionario.
Conclusione
Il criterio di Kelly risponde alla domanda principale di ogni strategia — quanto puntare — con una formula che massimizza la crescita geometrica di lungo periodo: per le puntate e per i rendimenti, e per il portafoglio .
Ma il full Kelly è l'ottimo matematico per la crescita, non per la sopravvivenza. Il Kelly frazionario (–) cattura gran parte della crescita con volatilità e drawdown proporzionalmente minori. Perciò la risposta pratica alla domanda sulla scelta di Kelly per le strategie suona così: calcola il full Kelly onestamente, ma punta la sua frazione, sopra rigidi limiti di rischio.
Materiali correlati:
Autori

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Leggi di Più
La Coda Dentro il Muro: Analisi della Posizione degli Ordini nella Densità del Book degli Ordini

QuestDB per il Trading Algoritmico: Le Estensioni SQL che Cambiano le Regole del Gioco
