전략을 위한 켈리 기준: 포지션 크기를 정하고 자본을 배분하는 법

양의 기대값을 가진 전략이라도 베팅 크기를 잘못 잡으면 계좌를 날릴 수 있다. 공식 유도부터 전략 포트폴리오까지 켈리 기준을 파헤친다: 왜 full Kelly가 위험한지, 어떻게 분수 켈리가 절반의 변동성으로 75%의 성장을 주는지, 그리고 알고리즘 트레이딩에서 실제로 적용할 수 있는 사이징 레시피는 무엇인지. 글 중간에는 켈리 비율이 수익과 리스크를 어떻게 움직이는지 보여주는 인터랙티브 계산기가 있다.
모든 전략이 반드시 답해야 하는 질문
당신에게는 양의 우위(edge)를 가진 전략이 있다. 긴 안목에서 보면 돈을 번다. 남은 디테일은 하나뿐이다 — 한 거래에 자본의 몇 퍼센트를 걸 것인가, 혹은 하나의 전략에 얼마를 배분할 것인가.
이것은 부차적인 질문이 아니라 핵심 질문이다. 양의 기대값이 파산을 막아주지는 않는다. 너무 많이 걸면 연속된 손실이 통계적으로 회복 불가능한 영역으로 계좌를 끌고 간다(참고: 손실과 이익의 비대칭). 너무 적게 걸면 잠재적 성장의 상당 부분을 테이블 위에 남겨두게 된다.
켈리 기준은 정확한 답을 준다: 그것은 장기 성장률 — 산술이 아닌 기하 성장률 — 을 극대화하는 자본의 비율이다. 천 번의 거래 후에 당신의 계좌가 어디에 있을지를 결정하는 것은 바로 기하 성장이다. 수익은 합산되는 것이 아니라 곱해지기 때문이다(참고: 수익의 곱셈적 본질).
공식은 어디서 나오는가: 자본 로그의 극대화
켈리(1956)와 그 뒤를 이은 소프(Thorp)의 핵심 아이디어: 최적화해야 할 대상은 한 거래의 기대 수익이 아니라 최종 자본의 기대 로그값이다. 로그가 등장하는 것은 우연이 아니다 — 이것은 극대화했을 때 자본이 최대 기하 속도로 성장하는 유일한 함수다.
이항 경우: 두 가지 결과를 가진 베팅
확률 로 베팅이 단위당 순수익 (배당률)를 가져다주고, 확률 로 베팅 자체를 잃는다고 하자. 자본의 비율 를 건다. 한 번의 거래 후 자본은 이겼을 때 , 졌을 때 만큼 곱해진다.
기대 로그 성장:
에 대해 미분하여 0과 같다고 놓는다:
그 해가 바로 켈리 공식이다:
말로 풀면: 최적 비율은 당신의 우위를 배당률로 나눈 값이다. 우위가 없으면() 베팅도 없다.
예시
전략이 1:1 배당 비율()로 거래의 55%에서 이긴다:
full Kelly는 거래당 자본의 10%를 걸라고 명령한다. 이 숫자를 기억해 두라 — 아래에서 거의 누구도 정확히 그만큼 걸어서는 안 되는 이유를 보게 될 것이다.
연속 경우: 베팅 대신 수익률
트레이딩에서 거래는 두 가지 결과를 가진 베팅처럼 보이는 경우가 드물다 — 수익률의 분포가 존재한다. 기간당 평균 와 분산 를 갖는 수익률에 대해, 레버리지(비율) 에서의 기대 로그 성장은 근사적으로 다음과 같다:
최대값은 다음에서 달성된다:
이것이 유명한 켈리의 연속형(머튼 비율이라고도 한다)이다. 그리고 최적점에서의 성장률은 샤프 비율 와 더없이 아름답게 연결된다:
벽에 붙여둘 만한 결론: 포트폴리오의 최대 기하 성장률은 그 Sharp의 제곱의 절반과 같다. Sharp를 두 배로 올리면 자본 성장률은 네 배가 된다.
왜 full Kelly는 과한가
공식은 성장에 대한 수학적 최적값을 준다. 그러나 이 최적값에는 공식이 침묵하는 대가가 있다: 어떤 실제 계좌도, 어떤 실제 인간도 견디지 못하고 무너지는 끔찍한 경로 변동성과 낙폭이다.
최적점에서 벗어났을 때의 기하
비율 (여기서 는 켈리 배수: 은 full Kelly, 는 half Kelly)를 성장 공식에 대입한다. 최대값을 기준으로 하면 다음을 얻는다:
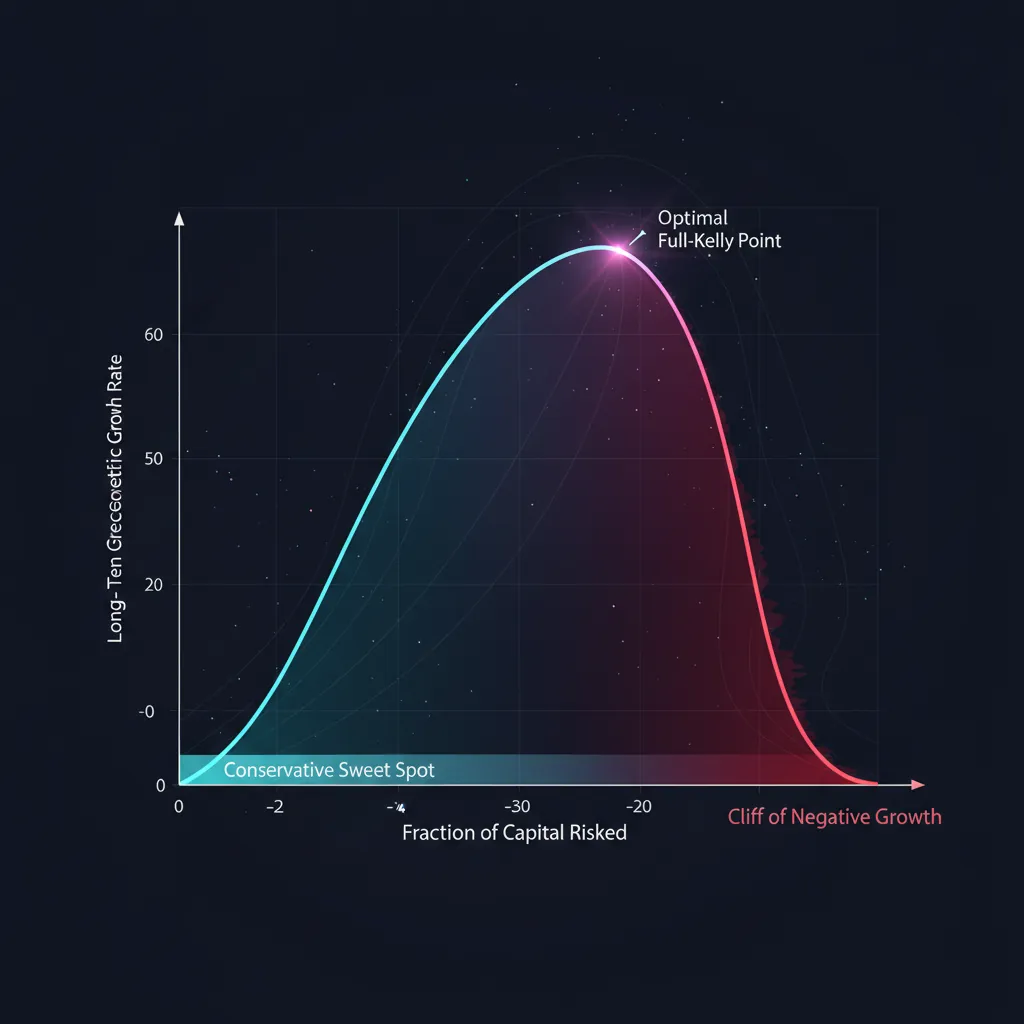
이 포물선은 리스크 관리의 전체 이야기를 한 줄로 들려준다:
| 배수 | 성장 비율 | 변동성 | 코멘트 |
|---|---|---|---|
| 0.25 (quarter) | 43.8% | 25% | 1/4의 리스크로 성장의 거의 절반 |
| 0.50 (half) | 75.0% | 50% | 실무자들의 황금률 |
| 1.00 (full) | 100.0% | 100% | 최대 성장, 광적인 변동성 |
| 1.50 | 75.0% | 150% | half와 같은 성장이지만 리스크는 세 배 |
| 2.00 (double) | 0.0% | 200% | 성장 없음, 리스크 최대 |
| > 2.00 | 음수 | — | 양의 edge에도 불구하고 파산 |
세 가지 결론:
- half Kelly는 절반의 변동성으로 성장의 75%를 가져간다. 리스크/수익 비율로 보면 full Kelly보다 훨씬 낫다.
- 포물선은 을 기준으로 대칭이다. 켈리의 에 거는 것은 와 같은 성장을 주지만 변동성은 세 배다. 과도함은 부족함보다 더 가혹하게 처벌받는다.
- 켈리의 에서 성장은 0이 되고, 그 너머에서는 음수가 된다. 지나치게 공격적인 사이징은 이기는 전략에서도 자본을 죽인다.
full Kelly의 낙폭: 정신을 번쩍 들게 하는 공식
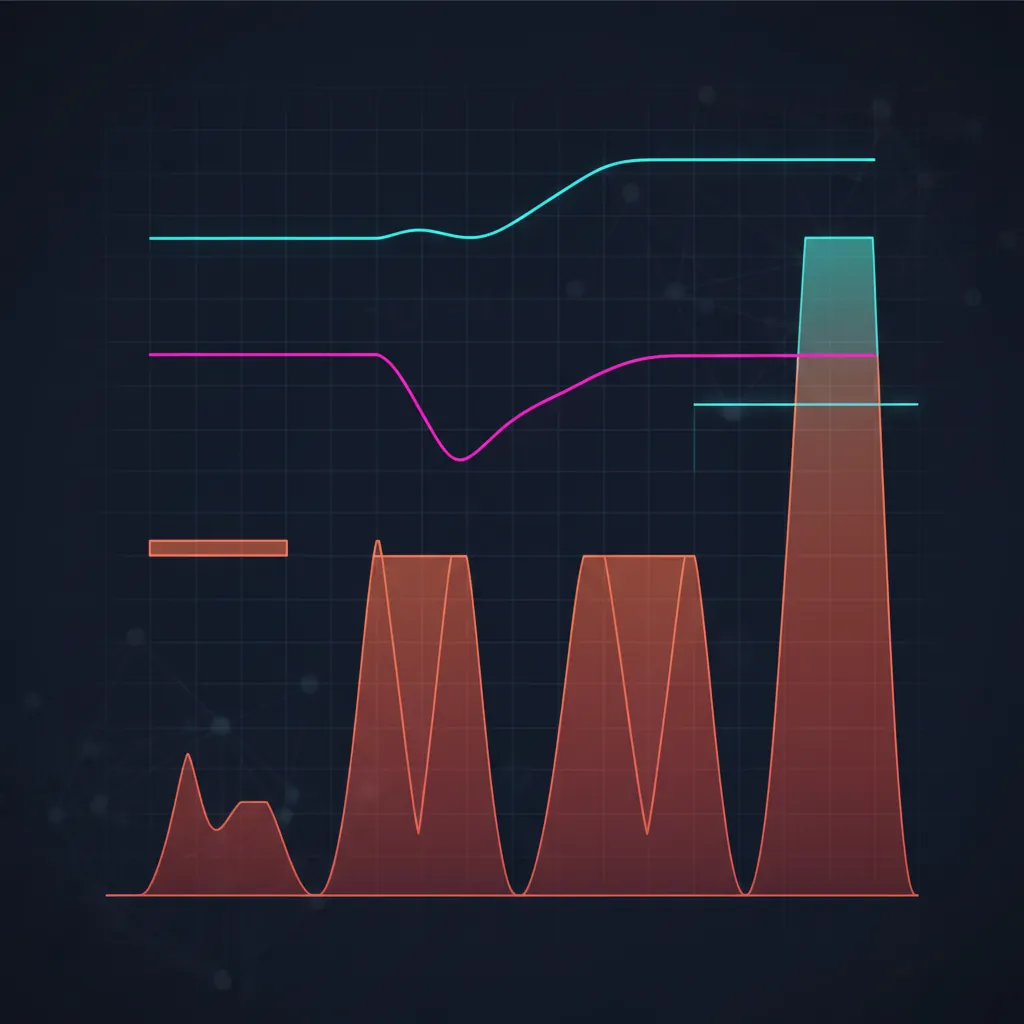
연속 모델에서 자본이 언젠가 초기값의 비율 까지 떨어질 확률은 다음과 같다:
켈리 수준을 대입하면 — full Kelly가 더 이상 매력적으로 보이지 않게 되는 표를 얻는다:
| 배수 | P(언젠가 −50%) | P(언젠가 −75%) |
|---|---|---|
| 1.00 (full) | 50% | 75% |
| 0.50 (half) | 12.5% | 1.6% |
| 0.25 (quarter) | 0.78% | 0.006% |
| 2.00 (double) | 100% | 100% |
full Kelly에서 언젠가 50%의 낙폭을 보게 될 확률은 50%다. 이것은 꼬리 시나리오가 아니다 — 동전 던지기다. half Kelly는 이를 12.5%로 낮추고, quarter Kelly는 1퍼센트 미만으로 낮춘다. 그리고 이것은 이상화된 가우스 모델에서의 이야기다. 실제의 두꺼운 꼬리는 실제 낙폭을 더 깊게 만든다.
계산기: 켈리 비율을 바꿔 보며 수익과 리스크를 살펴보라
슬라이더를 움직여 보라. 위쪽 두 개는 전략의 우위(승률과 배당 비율)를 설정하고, 아래쪽은 켈리 배수 를 설정한다. 자본 성장률과 깊은 낙폭 확률이 동시에 어떻게 변하는지 살펴보라. 이 글의 핵심 줄거리에 주목하라: half에서 full Kelly로 이동하면 성장은 조금 늘지만 낙폭 리스크는 배수로 커진다.
켈리 비율 슬라이더를 0.5와 1.0 근처에서 움직여 보라: 최대값 대비 성장은 75%에서 100%로 올라가는데, 50% 낙폭 리스크는 13%에서 50%로 뛴다. 바로 이것이 전문가들이 포물선의 왼쪽 절반에서 사는 이유다.
산업 표준으로서의 분수 Kelly
진지한 운용자들은 거의 full Kelly로 걸지 않는다. 전형적인 범위는 켈리의 에서 다. 낙폭 외에도 비율을 줄여야 하는 네 가지 근본적인 이유가 있다.
1. 파라미터 추정 오차. 공식은 당신이 참값 , , , 를 안다고 가정한다. 실제로는 유한한 표본으로 이들을 추정한다. 그리고 성장 함수는 비대칭적이다: 우위를 과대평가하면 최적점 너머로 밀려나는데, 거기서는 같은 크기의 과소평가일 때 성장이 오르는 것보다 더 빠르게 떨어진다. 참 켈리가 인데 오차를 가지고 추정했다면, 체계적으로 더 적게 거는 것이 안전하다. 거친 규칙: 추정에 불확실성이 있으면 비율을 절반으로 줄여라.
2. 비정상성(non-stationarity). 전략의 우위는 상수가 아니다 — 시장 국면은 변하고, edge는 붕괴되며, 경쟁자들이 아이디어를 복제한다. 어제의 데이터로 계산된 켈리가 내일은 과대 산정된 것으로 드러날 수 있다. 분수 배수는 edge 붕괴에 대한 완충재다.
3. 두꺼운 꼬리. 가우스 공식 는 극단적 움직임의 리스크를 과소평가한다. 꼬리가 두꺼운 실제 분포에서는 체계적으로 과도하게 걸게 된다. 분수 Kelly는 이를 부분적으로 보완한다.
4. 비즈니스에서 낙폭의 비용. 마켓메이커에게 낙폭은 단지 심리의 문제가 아니다. 그것은 마진콜, 최악의 순간에 강제 포지션 축소, 투자자 자본의 이탈, 펀딩 비용의 상승이다(참고: funding rate가 어떻게 레버리지를 죽이는가). 매끄러운 자본 곡선은 켈리 공식에는 없는 그 자체로의 가치를 지닌다.
전략 포트폴리오를 위한 Kelly
지금까지 우리는 하나의 전략에 대해 이야기했다. 그러나 진짜 질문은 복수형으로 전략들을 위한 켈리 선택처럼 들린다: 당신에게는 여러 전략이 있고, 그들 사이에 자본을 배분해야 한다.
순진한 접근 — 각각에 대해 켈리를 따로 계산해서 더하는 것 — 은 상관관계를 무시하기 때문에 치명적으로 틀렸다. 강하게 상관된 두 전략은 본질적으로 두 배가 된 하나의 베팅이며, 총 리스크는 하나처럼 계산해야 한다.
행렬 형태
기대 수익률 벡터 와 공분산 행렬 에 대해, 모든 전략에 걸친 최적 비율 벡터는 한 번에 다음과 같다:
최적점에서의 성장률은 포트폴리오 Sharp의 제곱으로 일반화된다:
주목하라: 는 최대 Sharp를 갖는 포트폴리오(접점 포트폴리오)의 방향이다. 켈리와 평균-분산 최적화는 한 동전의 양면이다: 켈리는 단지 레버리지 수준을 기하 성장을 극대화하는 지점에 고정할 뿐이다.
역공분산이 하는 일
- 상관된 전략들은 리스크 예산을 나눈다. 두 전략이 거의 동일하다면, 행렬은 그들의 총 비율을 하나의 수준으로 줄여준다 — 수동적인 임시방편 없이 자동으로.
- 상관되지 않은 전략들은 분산 프리미엄을 받는다. 이들은 개별 크기에 가깝게 유지할 수 있으며, 포트폴리오의 총 Sharp는 각각보다 높아진다.
- 음으로 상관된 전략들은 늘어난 비율을 받을 수 있다 — 이들은 서로를 보장하며, 행렬은 이를 장려한다.
추정에 관한 경고
공분산 행렬의 역변환은 수치적으로 불안정하다: 잡음이 섞인 추정에서 는 작은 오차를 미친 가중치로 부풀린다. 공분산을 대각선으로 수축(shrinkage)하는 것, 레버리지 제한, 그리고 동일한 분수 배수가 필수다. 이것 없이는 행렬 켈리가 백테스트에서는 아름답지만 실전에서는 치명적인 비율을 내놓는다.
알고리즘 트레이딩과 마켓메이킹을 위한 보정
순수한 공식은 멸균된 세계에서 산다. 실제 엔진에서는 보정이 필요하다.
- 수수료와 슬리피지는 실효 우위를 줄인다. 모든 비용 이후의 수익률로 켈리를 계산하라. 그렇지 않으면 체계적으로 과도하게 걸게 된다.
- 베팅의 이산성과 로트 단위는 정확히 를 걸지 못하게 한다 — 올림이 아니라 내림으로 반올림하라.
- 비정상적인 edge는 시간에 따른 재계산을 요구한다: 와 의 추정을 전체 역사가 아니라 반감기를 가진 이동 윈도우에서 하라.
- 낙폭 제한. 켈리 위에 엄격한 상한선을 두어라: 최대 낙폭, 최대 레버리지, 단일 전략당 최대 비율. 공식적인 낙폭 제약(drawdown-constrained) 버전의 켈리(바세티, 보이드)가 존재하지만, 실무에서는 단순한 캡으로 충분하다.
- edge 평가의 정직함. 가장 큰 실수는 in-sample로 측정된 우위를 켈리에 먹이는 것이다. 오직 out-of-sample 추정, walk-forward, 수수료 이후의 값만 취하라. 공식에 입력되는 과대평가된 edge는 출력되는 과대 베팅이다.
레시피: 어떻게 적용할 것인가
- 우위를 정직하게 평가하라. Out-of-sample, walk-forward, 수수료와 슬리피지 이후. 이것이 가장 중요한 단계다 — 입력의 쓰레기는 출력의 파산으로 변한다.
- full Kelly를 계산하라. 이산 결과에는 이항 , 수익률에는 연속형 .
- 분수를 취하라. 기본값은 full Kelly의 –. edge가 덜 안정적일수록 배수를 더 작게.
- 포트폴리오는 행렬로 계산하라. 공분산 수축을 적용한 , 그다음 동일한 분수 배수.
- 엄격한 캡을 두어라. 포지션당 최대, 레버리지 최대, 낙폭 한도 — 모든 것 위에.
- 다시 계산하라. 추정이 갱신됨에 따라, 불확실성이 커지고 edge가 붕괴되면 비율을 줄여라.
코드
import numpy as np
def kelly_binary(p, b):
"""p — 승률, b — 베팅 1단위당 순 배당률."""
q = 1 - p
return (b * p - q) / b # = p - q/b
def kelly_continuous(mu, sigma):
"""mu, sigma — 기간당 수익률의 평균과 표준편차(동일 단위)."""
return mu / sigma ** 2
def kelly_portfolio(mu, cov, shrink=0.0):
"""전략 포트폴리오를 위한 행렬 켈리.
mu — 기대 수익률 벡터;
cov — 수익률 공분산 행렬;
shrink — 역변환 안정성을 위한 대각선 수축 계수(0..1)."""
cov = np.asarray(cov, float)
if shrink:
cov = (1 - shrink) * cov + shrink * np.diag(np.diag(cov))
return np.linalg.solve(cov, np.asarray(mu, float))
def sized(f_star, kelly_fraction=0.25, cap=0.2):
"""비율에 대한 엄격한 캡을 적용한 분수 켈리."""
return float(np.clip(f_star * kelly_fraction, -cap, cap))
f = kelly_binary(p=0.55, b=1.0) # 0.10 — full Kelly
print(sized(f)) # 0.025 — quarter Kelly, 안전한 크기
자주 하는 실수
- in-sample edge로 켈리. 가장 비싼 실수. 과대평가된 우위 → 과도한 베팅 → 음의 성장.
- 전략 간 상관관계 무시. 개별 켈리의 합은 포트폴리오 켈리가 아니다.
- 실전에서 full Kelly. 수학적 최대 성장이지만, 계좌 절반의 낙폭 확률이 50%. 거의 누구에게도 맞지 않는다.
- 불안정한 edge에서 켈리. 우위가 붕괴되고 있다면, 공식은 체계적으로 베팅을 과대 산정한다.
- 목표의 혼동. 켈리는 자본의 기하 성장을 극대화한다 — Sharp도, 플러스로 남을 확률도, 편안함도 아니다. 곡선의 매끄러움이 더 중요하다면, 의식적으로 분수 켈리로 걸어라.
결론
켈리 기준은 모든 전략의 핵심 질문 — 얼마나 걸 것인가 — 에 장기 기하 성장을 극대화하는 공식으로 답한다: 베팅에는 , 수익률에는 , 포트폴리오에는 .
그러나 full Kelly는 성장에 대한 수학적 최적값이지 생존에 대한 것이 아니다. 분수 Kelly(–)는 배수로 더 작은 변동성과 낙폭으로 성장의 대부분을 가져간다. 따라서 전략을 위한 켈리 선택이라는 질문에 대한 실용적인 답은 이렇다: full Kelly를 정직하게 계산하라 — 그리고 엄격한 리스크 한도 위에서 그것의 분수 부분을 걸어라.
관련 자료:
Authors

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.