Deflated Sharpe Ratio: Có Bao Nhiêu Chiến Lược 'Thắng' Trong Backtest Của Bạn Sống Sót Qua Multiple Testing?
Bài viết thuộc series "Backtest Không Ảo Tưởng".
📄 Bài viết này đã phát triển thành một bài báo nghiên cứu. Mọi con số dưới đây đến từ một script tất định duy nhất xây dựng ground truth có kiểm soát — các tìm kiếm nhiễu thuần túy, các tìm kiếm với lợi thế được cài đặt, và một lưới tham số tương quan thực tế — sau đó chạy Deflated Sharpe Ratio, haircut multiple-testing Harvey-Liu, và White's Reality Check / Hansen's SPA trên đó, đo trực tiếp tỷ lệ phát hiện sai và sức mạnh phát hiện của từng phương pháp. Đọc bài báo trực tuyến (phiên bản tương tác + PDF) tại deflated-sharpe.marketmaker.cc, mã nguồn và dữ liệu tại github.com/suenot/deflated-sharpe-search.
Bạn chạy một parameter sweep. Mười sáu độ dài fast, bốn mươi độ dài slow, 640 tổ hợp của một giao cắt trung bình động (moving-average crossover). Lưới quét chạy xong và một ô sáng rực: Sharpe hàng năm 3.9, p-value kiểm định đơn lẻ là . Mười hai số không của ý nghĩa thống kê. Bạn đã tìm thấy thứ gì đó.
Hoặc bạn chẳng tìm thấy gì cả, và chính tìm kiếm đã tìm ra nó thay cho bạn.
Một tìm kiếm tham số không phải là một bài kiểm định. Đó là một cỗ máy để tìm ra kẻ may mắn nhất trong N lần thử, và bạn cho nó càng nhiều lần thử, kẻ thắng cuộc của nó trông càng may mắn — bất kể có lợi thế thực nào bên dưới hay không. Sharpe tốt nhất-trong-N bị thổi phồng bởi việc lựa chọn theo đúng cách mà người cao nhất trong một nghìn người ngẫu nhiên là cao: không phải vì chiều cao đó là thật, mà vì bạn đã tìm kiếm. Các thống kê kiểm định đơn lẻ được in cạnh kẻ thắng cuộc — p-value của nó, t-stat của nó, câu hỏi "nó có ý nghĩa thống kê không?" — được thiết kế cho một giả thuyết được đăng ký trước. Đưa cho chúng kẻ sống sót của một tìm kiếm và chúng sẽ nói dối, một cách tự tin, mọi lần.
Bài viết này đo chính xác mức độ chúng nói dối tệ đến đâu, rồi đo ba công cụ khắc phục điều đó. Trọng tâm toàn bộ là ground truth có kiểm soát: chúng tôi tạo ra các lợi nhuận nơi chúng tôi biết đáp án — đôi khi là nhiễu thuần túy với lợi thế bằng không, đôi khi là một lợi thế được cài đặt với cường độ đã biết — để câu hỏi "phương pháp này có đúng không?" là một sự thật, không phải một phán đoán chủ quan. Đây là tiêu đề chính ngay từ đầu. Trên các tìm kiếm known-null, nơi câu trả lời trung thực luôn luôn là "không có phát hiện", đây là tần suất mỗi bài kiểm định "kêu sói" (báo động giả):
| Bài kiểm định | Tỷ lệ phát hiện sai trên các tìm kiếm known-null | Phán quyết |
|---|---|---|
| Ý nghĩa ngây thơ "Sharpe tốt nhất có ý nghĩa thống kê không?" | 1.000 | báo hiệu một phát hiện mọi lần, không sót lần nào |
| Deflated Sharpe Ratio (DSR ≥ 0.95) | 0.001 | được kiểm soát |
| Haircut Harvey-Liu — Bonferroni | 0.057 | ~được kiểm soát |
| Haircut Harvey-Liu — Holm | 0.057 | ~được kiểm soát |
| Haircut Harvey-Liu — BHY | 0.007 | được kiểm soát |
| White's Reality Check (bootstrap) | 0.022 | được kiểm soát |
1,000 chiến lược mỗi tìm kiếm, 1,000 quan sát mỗi chiến lược, 2,000 tìm kiếm null độc lập, Sharpe thực = 0 ở khắp mọi nơi. Lợi nhuận Normal iid tổng hợp, seed 0, α = 0.05, 252 chu kỳ/năm. Tỷ lệ phát hiện sai của bài kiểm định ngây thơ không phải là cao — nó đúng bằng một.
Hãy đọc hàng đầu tiên cho đến khi nó nhức nhối. Một bài kiểm định lẽ ra phải kích hoạt 5% số lần trên nhiễu thuần túy lại kích hoạt 100% số lần — bởi vì bạn không đưa cho nó nhiễu thuần túy, bạn đưa cho nó giá trị lớn nhất của một nghìn lần rút mẫu nhiễu thuần túy, và giá trị lớn nhất của một nghìn người tung đồng xu luôn trông như một thiên tài. Mọi hàng khác là một phương pháp biết điều này và điều chỉnh cho nó. Đây chính là toàn bộ bài viết: tại sao hàng đầu tiên là 1.000, tại sao các hàng khác thì không, và nơi duy nhất (phần cuối cùng) mà ngay cả các phương pháp tốt cũng cần một sự điều chỉnh thứ hai để giữ được sự trung thực.
Màn 1 — Cái bẫy: một tìm kiếm sản xuất Sharpe từ hư không

Hãy bắt đầu với cái bẫy sạch nhất có thể. Tạo ra chiến lược có lợi nhuận là nhiễu Normal chuẩn độc lập — không có drift, không có kỹ năng, Sharpe thực đúng bằng không với tất cả chúng. Mỗi chiến lược có quan sát. Bây giờ hãy làm điều mà mọi tìm kiếm tham số đều làm: giữ lại cái tốt nhất.
Sharpe tốt nhất-trong-1000 tính trên mỗi quan sát trung bình là 0.1027, hàng năm hóa thành 1.63 (suy ra: ). Đó không phải là một con số khiêm tốn. Một Sharpe hàng năm 1.63 là kiểu kết quả khiến một chiến lược được cấp vốn, được viết báo cáo, được phân bổ vốn. Nó đến từ một bộ tạo số ngẫu nhiên với drift được vặn về không.
Bây giờ hãy đưa kẻ thắng cuộc cho bài kiểm định ý nghĩa ngây thơ — bài kiểm định mà mọi thư viện backtest in ra miễn phí. Chuyển Sharpe của nó thành một t-statistic (), lấy p-value một phía, gọi nó là một phát hiện nếu :
P-value kiểm định đơn lẻ trung vị của các kẻ thắng cuộc nhiễu này là 0.000686 — ba số không "ý nghĩa thống kê" từ một chiến lược không có lợi thế nào. Và trên 2,000 tìm kiếm null độc lập, bài kiểm định ngây thơ tuyên bố một phát hiện trong từng cái một trong số đó: một tỷ lệ phát hiện sai 1.000. Không phải "bị thổi phồng." Không phải "hơi cao." Một bài kiểm định mà, theo cấu trúc, đúng nhiều nhất 5% số lần trên một giả thuyết không (null hypothesis) đơn lẻ lại sai 100% số lần trên kẻ thắng cuộc của một tìm kiếm.
Cơ chế này không hề tinh vi một khi đã được gọi tên. Bài kiểm định ngây thơ hỏi "liệu Sharpe này có thể xảy ra do ngẫu nhiên dưới null không?" — một câu hỏi công bằng cho một chiến lược bạn chọn trước khi nhìn vào dữ liệu. Nhưng bạn chọn cái này bởi vì nó có Sharpe cao nhất trong một nghìn cái. Bạn đã điều kiện hóa trên giá trị lớn nhất, và phân phối lấy mẫu của một giá trị lớn nhất chẳng giống gì phân phối lấy mẫu của một lần rút mẫu đơn lẻ. Đây chính là căn bệnh mà phân loại look-ahead bias của chúng tôi đã chẩn đoán từ đầu bên kia — ở đó, một rò rỉ lệch một nến đã sản xuất ra một Sharpe 15 từ nhiễu; ở đây, một tìm kiếm sản xuất ra một Sharpe 1.63 từ nhiễu mà hoàn toàn không có rò rỉ nào, thuần túy chỉ bằng việc lựa chọn. Cơ chế khác nhau, triệu chứng giống hệt nhau: một Sharpe trông tuyệt vời nhưng chẳng có ý nghĩa gì.
Con số 1.63 là con số quan trọng, vì vậy hãy ghi nhớ nó. Đó là trần nhiễu (noise ceiling) cho tìm kiếm này: Sharpe mà bạn nên kỳ vọng kẻ may mắn nhất trong 1,000 chiến lược không-lợi-thế sẽ đạt được. Bất kỳ bài kiểm định trung thực nào cho kẻ thắng cuộc của một tìm kiếm đều phải so sánh nó không phải với không, mà với con số này — với những gì may mắn đơn thuần mang lại khi bạn nhìn một nghìn lần.
Màn 2 — Bộ công cụ: ba cách để định giá tìm kiếm

Ba chương trình nghiên cứu, đến độc lập với nhau, đều đi đến cùng một cách khắc phục: ngừng so sánh kẻ thắng cuộc với không, và bắt đầu so sánh nó với những gì một tìm kiếm với kích thước này tạo ra bằng may mắn. Chúng khác nhau ở cách chúng xây dựng phép so sánh đó.
PSR và Deflated Sharpe Ratio (Bailey & López de Prado, 2012 / 2014)
Probabilistic Sharpe Ratio đặt ra một câu hỏi sắc bén hơn "Sharpe có dương không?" Nó hỏi: với độ dài mẫu và hình dạng của lợi nhuận (skew, đuôi béo/fat tails) đã cho, xác suất mà Sharpe thực vượt qua một chuẩn là bao nhiêu?
Ở đây là CDF Normal chuẩn, là skew, và là kurtosis theo quy ước non-excess (Normal ⇒ ; thay excess kurtosis vào đây mà không cộng thêm 3 thì phép khử lạm phát sẽ sai). Đặt và PSR chỉ đơn giản là một bài kiểm định ý nghĩa thống kê mẫu hữu hạn (finite-sample). Điều kỳ diệu nằm ở việc chọn đúng cách.
Deflated Sharpe Ratio là PSR được tính tại một chuẩn không phải là không, mà là Sharpe lớn nhất kỳ vọng của toàn bộ tìm kiếm:
trong đó là phương sai trên toàn bộ N Sharpe của các lần thử (độ phân tán mà chính tìm kiếm đó tạo ra), là hằng số Euler-Mascheroni, và hai số hạng nghịch đảo-Normal là xấp xỉ Extreme-Value-Theory cho giá trị lớn nhất kỳ vọng của lần rút mẫu Normal chuẩn. Viết bằng code thì nó ngắn đến mức gần như không đáng để ấn tượng:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
Sau đó DSR đơn giản chỉ là PSR với thanh chuẩn đã khử lạm phát đó:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR là một xác suất. Chúng tôi tuyên bố một phát hiện khi : Sharpe thực của kẻ thắng cuộc vượt qua cái tốt nhất-do-may-mắn kỳ vọng với độ tin cậy 95%. Hãy chú ý giả định mang tính nền tảng được cài sẵn vào : lần thử được xử lý như thể độc lập. Toàn bộ Màn 5 nói về điều gì xảy ra khi chúng không độc lập.
Haircut Harvey-Liu (2015)
Harvey và Liu tấn công cùng vấn đề này thông qua các điều chỉnh p-value multiple-testing — bộ máy cổ điển cho "tôi đã chạy M bài kiểm định, đừng để tôi tự lừa dối mình." Sắp xếp p-value kiểm định đơn lẻ và thổi phồng chúng lên:
Bonferroni là công cụ thô bạo (kiểm soát xác suất của bất kỳ dương tính giả nào bằng cách nhân mọi p-value với ); Holm là người anh em step-down mạnh hơn đồng đều (uniformly-more-powerful) của nó. Cái thứ ba, Benjamini-Yekutieli (BHY), kiểm soát tỷ lệ phát hiện sai (false-discovery rate) — tỷ lệ kỳ vọng của các bác bỏ của bạn là sai — và, quan trọng là, nó làm được điều này dưới sự phụ thuộc tùy ý giữa các bài kiểm định, sử dụng bộ chuẩn hóa điều hòa (harmonic normalizer) ở tử số:
Con số đó là cái giá mà BHY tính cho việc không giả định 1,000 lần thử của bạn là độc lập — nó thổi phồng ngưỡng FDR lên một hệ số tăng theo kiểu . Bản thân "haircut" là chỉ số chốt hạ: chuyển p-value đã điều chỉnh trở lại thành một Sharpe và báo cáo bạn đã phải cắt bớt bao nhiêu phần trăm Sharpe gốc. Một haircut 100% nghĩa là kẻ thắng cuộc hoàn toàn được giải thích bởi multiple testing; 15% nghĩa là nó phần lớn sống sót.
White's Reality Check và Hansen's SPA (2000 / 2005)
Công cụ thứ ba không đưa ra bất kỳ giả định phân phối nào cả. Reality Check của White lấy lợi nhuận thực tế của mọi quy tắc, tạo thành thống kê max-trên-các-quy-tắc, và bootstrap trực tiếp phân phối null của nó:
trong đó là hiệu suất trung bình của quy tắc so với chuẩn. Nó lấy mẫu lại lợi nhuận bằng stationary bootstrap (Politis-Romano — các khối có độ dài ngẫu nhiên để tương quan chuỗi sống sót qua việc lấy mẫu lại), tái căn giữa mỗi lần rút mẫu để thỏa mãn null theo cấu trúc, tính lại giá trị lớn nhất trên mỗi lần rút mẫu, và báo cáo p-value là tỷ lệ các giá trị lớn nhất bootstrap vượt qua giá trị quan sát được. SPA của Hansen làm sắc bén RC theo hai cách: studentization (chia trung bình của mỗi quy tắc cho sai số chuẩn của chính nó, để một quy tắc phương sai cao ngông cuồng không thể chiếm đoạt giá trị lớn nhất) và một sự tái căn giữa null nhất quán, phụ thuộc mẫu. Triển khai của chúng tôi thêm vào studentization nhưng không có bước tái căn giữa nhất quán đầy đủ — vì vậy bất cứ khi nào bài viết này báo cáo một p-value kiểu-SPA, hãy đọc nó như một Reality Check đã studentized, không phải Hansen SPA đầy đủ. Trong khi DSR hỏi "kẻ thắng cuộc có đặc biệt trong tìm kiếm này không?", Reality Check hỏi "quy tắc tốt nhất có đánh bại tiền mặt sau khi tính đến một cách trung thực số quy tắc tôi đã thử không?" — và nó xử lý các quy tắc tương quan một cách tự nhiên, thông qua bootstrap, mà không bao giờ cần đếm số lần thử. Hãy ghi nhớ sự phân biệt đó; phần cuối cùng xoay quanh nó.
Màn 3 — Hiệu chuẩn là toàn bộ bằng chứng
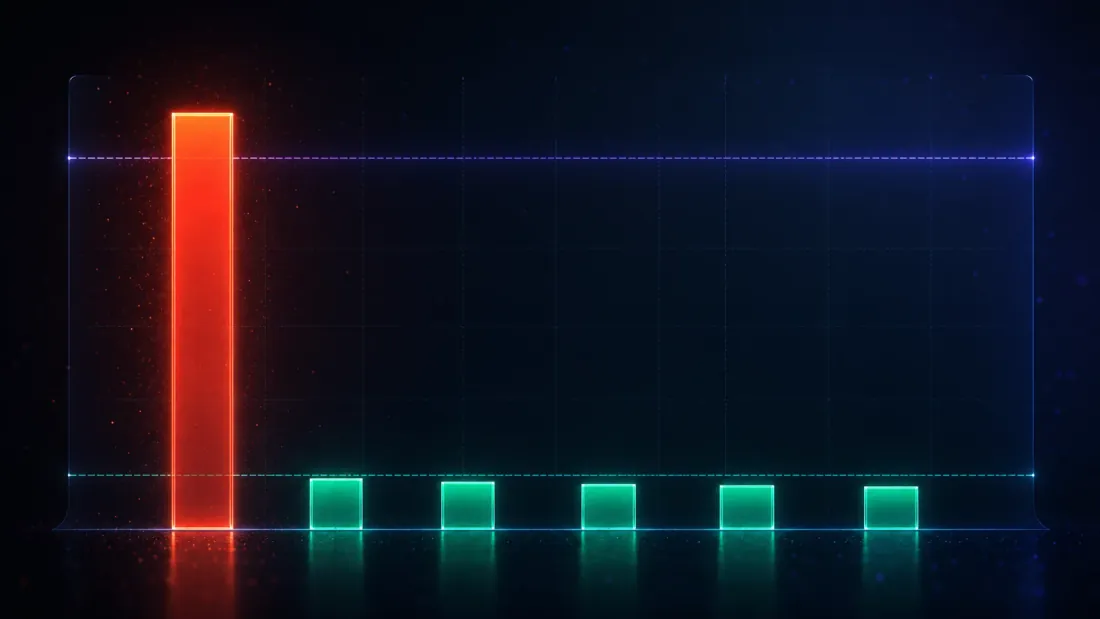
Một phương pháp không báo hiệu bất cứ điều gì cũng sẽ có tỷ lệ phát hiện sai bằng không — và vô dụng. Vì vậy bài kiểm định có ý nghĩa duy nhất cho các công cụ này là một bài kiểm định hai mặt: trên dữ liệu known-null chúng phải kiểm soát phát hiện sai ở mức hoặc dưới , và trên dữ liệu known-edge (phần tiếp theo) chúng vẫn phải kích hoạt. Phần này là nửa đầu tiên.
Chạy 2,000 tìm kiếm độc lập, mỗi tìm kiếm trên 1,000 chiến lược không-lợi-thế, và đếm tần suất mỗi phương pháp tuyên bố một phát hiện. Số đếm đó, chia cho 2,000, là tỷ lệ phát hiện sai — và bởi vì sự thật là không có lợi thế nào, mọi phát hiện đều là sai:
| Bài kiểm định | Tỷ lệ phát hiện sai (α = 0.05) |
|---|---|
| Ý nghĩa ngây thơ | 1.000 |
| Deflated Sharpe Ratio | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| White's Reality Check | 0.022 |
Mọi phương pháp có nguyên tắc đều rơi vào hoặc gần đường 5% — hai haircut FWER nhỉnh hơn một chút, DSR/BHY/RC thấp hơn — trong khi bài kiểm định ngây thơ nằm ở mức 100. (Bonferroni và Holm in ra cùng con số 0.057 ở đây, và không phải do may mắn: đối với chiến lược tốt nhất duy nhất, bước đầu tiên của Holm là , giống hệt Bonferroni theo cấu trúc, vì vậy chúng là một sự xác nhận, không phải hai.) Nhưng con số sâu sắc nhất trong toàn bộ nghiên cứu không nằm trong bảng này — đó là chuẩn đã khử lạm phát tạo ra cột DSR. Trung bình trên các tìm kiếm null, ra kết quả là 0.1030 tính trên mỗi quan sát, hàng năm hóa thành 1.63 (suy ra: ) — chính là con số 1.63 mà kẻ thắng cuộc nhiễu trung bình đạt được (1.63). Đó không phải là sự trùng hợp; đó là toàn bộ ý tưởng đang vận hành:
Thanh chuẩn đã khử lạm phát nằm chính xác tại trần nhiễu. DSR không yêu cầu kẻ thắng cuộc của một tìm kiếm đánh bại không. Nó yêu cầu kẻ thắng cuộc đánh bại điểm số tốt nhất mà may mắn đơn thuần tạo ra từ một tìm kiếm với kích thước này — 1.63 hàng năm ở đây. Một kẻ thắng cuộc chỉ khớp với trần nhiễu sẽ có điểm DSR ≈ 0.5 (một lần tung đồng xu), đó là lý do tại sao DSR null trung bình là 0.495, không phải một con số nhỏ. Để trở thành một phát hiện, kẻ thắng cuộc phải vượt qua 1.63 và hơn thế nữa — đủ để đẩy PSR vượt qua 0.95.
Điều này định khung lại toàn bộ bài tập. Bài kiểm định ngây thơ đo khoảng cách từ không; mọi tìm kiếm đều vượt qua thanh đó một cách tầm thường, đó là lý do tại sao nó vô dụng. DSR đo khoảng cách từ trần nhiễu, và vượt qua thanh đó thực sự khó — đúng như nó nên vậy. Haircut Harvey-Liu và Reality Check đạt được cùng sự kiểm soát đó bằng những con đường khác nhau (một sự thổi phồng cho BHY, một phân phối giá trị lớn nhất bootstrap cho RC), và rơi vào cùng một khu vực lân cận: 0.001 đến 0.057, ở mức hoặc gần . Con số 0.057 của Bonferroni/Holm nhỉnh hơn đường 5% một chút, nhưng chỉ vừa đủ: với 2,000 tìm kiếm Monte-Carlo, sai số chuẩn trên một ước lượng FDR gần 0.05 là khoảng 0.005, vì vậy 0.057 nằm khoảng 1.4 sai số chuẩn trên — nhiễu Monte-Carlo, không phải một sự bảo đảm bị phá vỡ. Dù sao thì "kiểm soát FWER" cũng là một lời hứa tiệm cận (asymptotic), không phải một sự chính xác từng bit tại .
Màn 4 — Sức mạnh phát hiện: nó có còn giữ lại các lợi thế thực không?
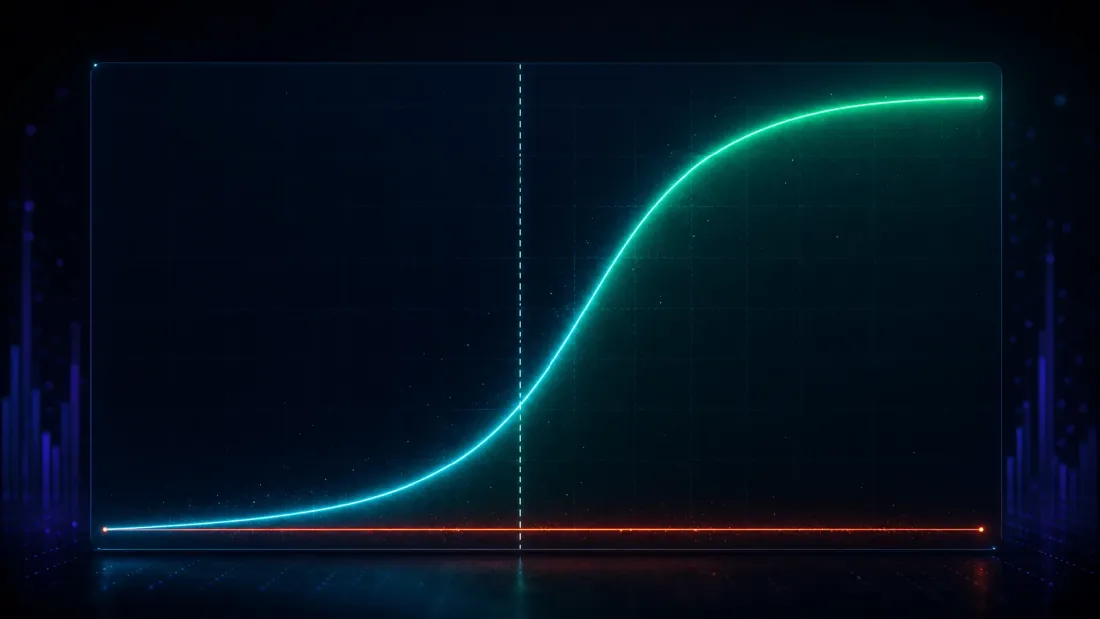
Kiểm soát phát hiện sai chỉ là một nửa bài kiểm định — một phương pháp hoang tưởng bác bỏ mọi thứ sẽ đạt điểm hoàn hảo 0.000 và vô giá trị. Nửa còn lại: khi một lợi thế thực sự có ở đó, DSR có tìm ra nó không?
Hãy cài một lợi thế vào. Trong một trường 1,000 chiến lược, làm cho 25 trong số đó mang một lợi thế thực với cường độ đã biết và để phần còn lại là nhiễu, sau đó chạy tìm kiếm và hỏi liệu DSR có báo hiệu kẻ thắng cuộc hay không. Quét lợi thế được cài đặt từ yếu đến mạnh và sức mạnh phát hiện vẽ ra một đường cong chữ S sạch (tỷ lệ dương tính giả được giữ ở mức ~0 xuyên suốt):
| Sharpe thực được cài đặt (hàng năm) | Sức mạnh phát hiện DSR | Tỷ lệ dương tính giả DSR |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
Hãy nhìn vào nơi đường cong chuyển hướng. Dưới trần nhiễu — một Sharpe thực hàng năm 0.79, thấp hơn nhiều so với 1.63 — DSR kích hoạt 0.5% số lần, đúng đắn từ chối gọi đó là phát hiện: một lợi thế yếu như vậy thực sự không thể phân biệt được với may mắn mà một tìm kiếm 1,000-lần-thử tạo ra, và giả vờ ngược lại sẽ là không trung thực, chứ không phải mạnh mẽ. Ngay quanh trần nhiễu, đường cong leo dốc (0.09 tại 1.27, 0.65 tại 1.90). Đến Sharpe hàng năm 2.54, sức mạnh đạt 0.998; đến 3.17 nó đạt mức hoàn hảo 1.000. Các lợi thế mạnh được giữ lại về cơ bản mọi lần, dương tính giả vẫn ghim ở mức không, và điểm giao cắt sức mạnh 50% nằm ở Sharpe hàng năm khoảng 1.73 (suy ra bằng nội suy giữa các hàng 1.27 và 1.90) — ngay trên trần nhiễu 1.63, chính xác nơi một thanh chuẩn trung thực nên đặt nó: điểm mà một lợi thế bắt đầu vượt qua những gì một tìm kiếm 1,000-lần-thử bịa ra.
Đó chính là thuộc tính bạn thực sự muốn, phát biểu dưới dạng một đường cong chữ S: các lợi thế dưới trần nhiễu được loại trừ đúng đắn như là may mắn; các lợi thế trên nó một cách thoải mái được giữ lại với sức mạnh tiến gần đến một. Ngược lại, bài kiểm định ngây thơ "phát hiện" lợi thế được cài đặt 67% số lần ngay cả ở một Sharpe thực 0.79 — nhưng con số đó vô nghĩa, bởi vì chúng ta đã thấy nó phát hiện một lợi thế không tồn tại 100% số lần. Một bài kiểm định kích hoạt trên mọi thứ thì không có sức mạnh; nó không có khả năng phân biệt. DSR đánh đổi một chút độ nhạy với các lợi thế biên (các hàng 0.79 và 1.27) để lấy điều quan trọng: các phát hiện của nó là thật.
Màn 5 — Cái bẫy của người thực hành: lưới tham số tương quan
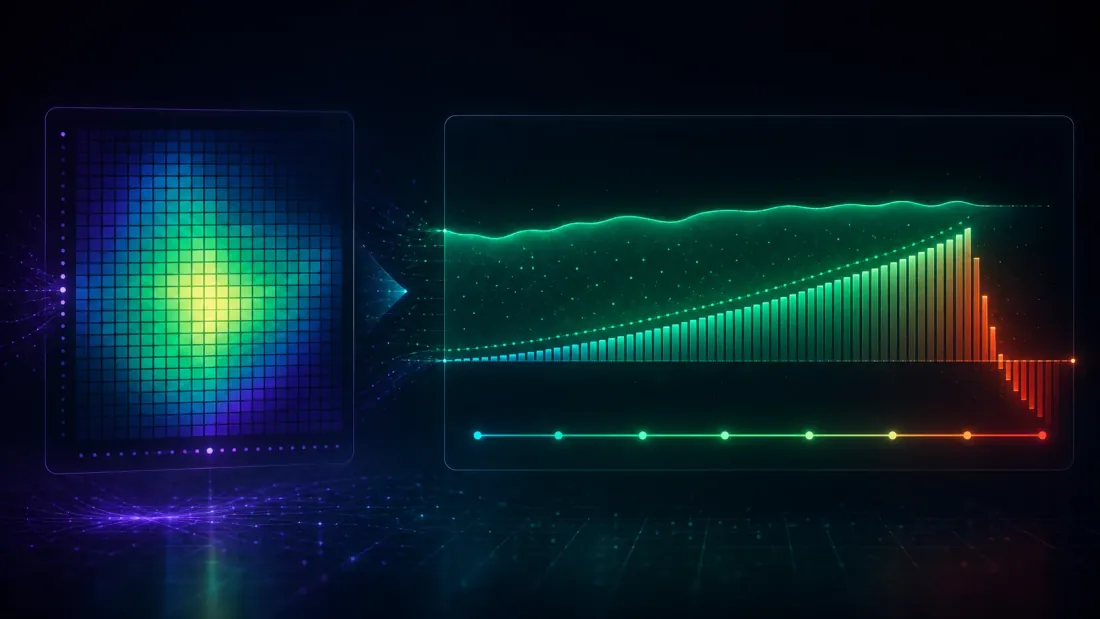
Mọi thứ cho đến giờ đều sử dụng các chiến lược độc lập — thiết lập sạch nhất có thể, và là thiết lập nơi giả định độc lập của DSR đúng một cách chính xác. Các lưới tham số thực tế không như vậy, và đây là nơi một công cụ được sử dụng một cách ngây thơ trở thành một cách mới để sai.
Hãy lấy một tìm kiếm giao cắt trung bình động trung thực: 16 độ dài fast 40 độ dài slow lần thử, mỗi lần 755 quan sát. Một lưới như thế này ngập tràn trong tương quan — fast=45/slow=120 và fast=45/slow=125 gần như là cùng một chiến lược, vì vậy các dòng lợi nhuận của chúng di chuyển cùng nhau. Tương quan cặp trung bình đo được trên 640 lần thử: khoảng 0.61. Đó không phải là 640 cược độc lập. Không hề gần với điều đó.
Trường hợp A — random walk (không có lợi thế): mọi phương pháp đều loại bỏ nó, đúng đắn
Chạy lưới trên một random walk thuần túy. Kẻ thắng cuộc trông hấp dẫn: tham số fast=45/slow=120, Sharpe hàng năm tốt nhất 0.81, p-value kiểm định đơn lẻ 0.081. Mọi phương pháp đều nhìn thấu nó:
| Phương pháp | Kết quả | Phán quyết |
|---|---|---|
| DSR (K thô = 640) | 0.431 | bác bỏ (< 0.95) |
| Reality Check p | 0.570 | bác bỏ |
| p kiểu-SPA (RC đã studentized) | 0.569 | bác bỏ |
| Haircut Harvey-Liu | 100% | bác bỏ |
Hãy bắt đầu với dấu hiệu không cần bất kỳ sự khử lạm phát nào cả: ngay cả ý nghĩa thống kê mẫu hữu hạn chưa điều chỉnh của kẻ thắng cuộc này, -so-với-không, cũng chỉ là 0.918 — đã thấp hơn 0.95 trước cả khi chúng ta điều chỉnh cho dù chỉ một trong 640 lần thử. Việc khử lạm phát sau đó chôn vùi nó: thanh chuẩn là một tính trên mỗi quan sát, hàng năm hóa ~0.91 (suy ra: ) — cao hơn mức 0.81 của kẻ thắng cuộc. Chiến lược tốt nhất thậm chí còn không đạt đến trần nhiễu, DSR ≈ 0.43 (tệ hơn một lần tung đồng xu), và Reality Check, bài kiểm định kiểu-SPA, và một haircut 100% đều đồng ý: chẳng có gì ở đây cả. Hoàn hảo. Đây là trường hợp dễ, và nó hoạt động — và, như chúng ta sẽ thấy, nó vẫn bị bác bỏ ở mọi số-lần-thử-hiệu-quả mà chúng ta thử.
Trường hợp B — một lợi thế chế độ thực sự: DSR thô hiểu sai
Bây giờ hãy chạy cùng một lưới trên một chuỗi chuyển đổi chế độ (regime-switching) mang một lợi thế thực, có thể khai thác được. Kẻ thắng cuộc rất dứt khoát: tham số fast=3/slow=55, Sharpe hàng năm tốt nhất 3.92 — đây là Sharpe in-sample, đã được chọn, tự nó đã bị thổi phồng-do-lựa-chọn bởi tìm kiếm (không phải một lợi thế thực hoặc out-of-sample), nhưng hiệu ứng chế độ bên dưới là có thật — với một p-value kiểm định đơn lẻ và ý nghĩa thống kê chưa khử lạm phát -so-với-không về cơ bản là 1.000. Có một lợi thế thực ở đây và kẻ thắng cuộc đã tìm ra nó. Hãy xem DSR thô bác bỏ nó dù vậy:
| Phương pháp | Kết quả | Phán quyết |
|---|---|---|
| DSR (K thô = 640) | 0.748 | bác bỏ (< 0.95) ✗ khử lạm phát quá mức |
| Reality Check p | 0.0024 | xác nhận ✓ |
| p kiểu-SPA (RC đã studentized) | 0.0038 | xác nhận ✓ |
| Haircut Harvey-Liu | 15% | xác nhận ✓ |
DSR thô 0.748 là một sự bác bỏ sai đối với một lợi thế thực sự. Lý do là giả định độc lập, giờ đây bị vi phạm nghiêm trọng: DSR xây dựng thanh chuẩn đã khử lạm phát của nó bằng cách xử lý 640 lần thử tương quan như 640 lần rút mẫu độc lập, điều này thổi phồng giá trị-lớn-nhất-kỳ-vọng lên mức 0.221 tính trên mỗi quan sát — hàng năm hóa ~3.51 (suy ra: ). So với một thanh chuẩn 3.51, một kẻ thắng cuộc 3.92 chỉ vượt qua nó một cách khiêm tốn, và DSR rơi vào mức 0.748 — thấp hơn 0.95. Có hai thứ bơm thanh chuẩn đó lên cao: số đếm thô (640 lượt nhìn thay vì một vài lượt hiệu quả), và sự phân tán kỹ năng thực sự giữa các lần thử — một số cặp tham số thực sự tốt hơn trên một chuỗi chế độ, điều này mở rộng và nâng vượt quá những gì may mắn thuần túy đơn thuần sẽ tạo ra. Cả hai đều đẩy theo cùng một hướng, và thanh chuẩn cuối cùng trở nên quá cao bởi vì tìm kiếm này chưa bao giờ thực sự là 640 lượt nhìn độc lập; nó là một vài cược độc lập, được lấy mẫu 640 lần.
Thay vào đó, hãy đưa cho DSR số lần thử hiệu quả. Công thức một dòng được dùng ở trên là một ước lượng thô từ tương quan cặp trung bình:
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
Với và , điều này thu gọn lưới xuống còn lần thử hiệu quả (suy ra: ), và DSR nhảy vọt lên 1.000. Nhưng hãy dừng lại trước khi bạn ăn mừng con số đó, bởi vì đó là bằng chứng yếu nhất trong toàn bộ phần này. Tại , thanh chuẩn đã khử lạm phát sụp đổ xuống một hàng năm — về cơ bản là trung bình của các lần thử, về cơ bản bằng không. Việc khử lạm phát ở đó bị tắt đi: DSR tại chỉ đơn giản là báo cáo lại ý nghĩa thống kê mẫu hữu hạn chưa khử lạm phát của kẻ thắng cuộc (-so-với-không ). Phán quyết được kế thừa từ ý nghĩa thống kê thô, không phải được tạo ra bởi điều chỉnh multiple-testing. Và một lưu ý đối xứng ở phía random walk: sự bác bỏ của nó tại chỉ đúng bởi vì kẻ thắng cuộc đó vốn đã cận biên một cách độc lập ngay từ đầu (-so-với-không ). Neo toàn bộ lập luận vào con số 1.6 và một người hoài nghi có lý do để nhún vai: bạn đã tắt điều chỉnh và báo cáo bất cứ thứ gì nằm bên dưới nó.
Vì vậy đừng neo vào một ước lượng duy nhất. Nước đi trung thực — và mạnh mẽ hơn — là tính theo năm cách chuẩn khác nhau và đọc phán quyết trên toàn bộ dải. Dưới đây là năm ước lượng được áp dụng cho cùng lưới tín hiệu 640-lần-thử, mỗi cái với thanh chuẩn đã khử lạm phát mà nó ngụ ý và DSR mà nó tạo ra:
| Ước lượng số-lần-thử-hiệu-quả | Thanh chuẩn khử lạm phát (hàng năm) | DSR | Phán quyết | |
|---|---|---|---|---|
| Tương quan trung bình | 1.6 | 0.25 | 1.000 | giữ lại |
| Participation ratio | 2.4 | 0.43 | 1.000 | giữ lại |
| PCA (95% phương sai) | 16 | 1.85 | 1.000 | giữ lại |
| Kaiser (eigenvalue > 1) | 21 | 2.00 | 0.999 | giữ lại |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | bác bỏ |
| số đếm lưới thô (không điều chỉnh) | 640 | 3.51 | 0.748 | bác bỏ |
Các ước lượng: tương quan trung bình là công thức một dòng ở trên; participation ratio và số đếm PCA-95%/Kaiser đọc chiều hiệu quả từ các eigenvalue của ma trận tương quan; Cheverud-Nyholt là một ước lượng phương-sai-của-eigenvalue từ tài liệu di truyền học được biết là đếm-quá-mức dưới điều kiện gần-đồng-tương-quan (near-equicorrelation).
Bây giờ luận điểm mới thực sự chạm đích, và nó không phải là "bất kỳ điều chỉnh nào cũng cứu được bạn." Hãy nhìn vào khu vực giữa có thể bảo vệ được — PCA-95% () và Kaiser (). Đây không phải là chế độ khử-lạm-phát-bị-tắt; chúng áp đặt một thanh chuẩn hàng năm thực sự ở mức 1.85 đến 2.00 — một haircut nghiêm túc, cao hơn nhiều so với nhiễu, một sự phạt multiple-testing chính đáng cho 16-21 lượt nhìn hiệu quả. Và lợi thế 3.92 vẫn vượt qua nó (DSR 1.000 và 0.999). Tín hiệu sống sót qua DSR cho bất kỳ nào dưới 144.8 (suy ra từ điểm giao cắt); nó chỉ thất bại dưới của Cheverud-Nyholt, một ước lượng đã được chứng minh là đếm-quá-mức khi các lần thử gần-đồng-tương-quan — và ngay cả số đếm thô, chưa điều chỉnh 640 cũng chỉ đẩy DSR xuống mức 0.748, không phải xuống không. Kẻ thắng cuộc random-walk, khi chạy qua chính xác cùng năm ước lượng đó, bị bác bỏ ở mọi ước lượng (nó không sống sót ở bất kỳ nào trên 1). Đó chính là kết quả thực sự: không phải một con số may mắn đơn lẻ, mà là một phán quyết ổn định trên toàn bộ dải các ước lượng số-lần-thử-hiệu-quả chuẩn — đó là bằng chứng mạnh mẽ hơn nhiều so với việc tin tưởng vào bất kỳ một ước lượng nào trong số đó.
Một lưu ý kỹ thuật về ước lượng thô nhất, bởi vì nó giải thích tại sao ước lượng đó nằm ở đầu mềm yếu: thực chất là hệ số giảm-phương-sai cho trung bình của các biến tương quan (việc lấy trung bình mang lại cho bạn bao nhiêu dưới tương quan ). Chuẩn của DSR là một đại lượng extreme-value — giá trị lớn nhất kỳ vọng của các lần thử — vì vậy việc sử dụng một sự co rút phương-sai-trung-bình làm số-lần-thử của nó là một sự không khớp về mặt hàm số: đúng hướng (tương quan ⇒ ít lần thử hiệu quả hơn), nhưng không phải là đại lượng mà phân phối của giá trị lớn nhất thực sự phụ thuộc vào. Đó chính xác là lý do tại sao các ước lượng dựa-trên-eigenvalue ở giữa dải là cách đọc đáng tin cậy hơn, và tại sao dải, chứ không phải điểm, mới là thứ được giao.
Bài học: sử dụng cả hai công cụ, và đưa cho DSR đúng N

Hai điều rút ra từ Trường hợp B, và cả hai đều mang tính nền tảng:
- Kích thước lưới thô là N sai cho DSR bất cứ khi nào các lần thử tương quan với nhau — và cũng không có một N-hiệu-quả duy nhất nào là đúng cả. Đưa 640 vào một công thức giả định độc lập sẽ khử lạm phát quá mức: nó sản xuất ra một trần nhiễu cao hơn nhiều so với những gì tìm kiếm thực sự đạt được và chôn vùi các lợi thế thực bên dưới nó. DSR cần số-lần-thử hiệu quả — nhưng cách khắc phục không phải là tin tưởng vào một ước lượng duy nhất (ít nhất là ước lượng thô nhất, nơi sự điều chỉnh tắt đi gần ). Đó là đọc phán quyết trên toàn bộ dải các ước lượng chuẩn (ở đây từ 1.6 đến 370) và xem liệu nó có ổn định hay không. Đối với lợi thế này thì có: được giữ lại ở mọi nơi mà sự khử lạm phát thực sự đang hoạt động (một thanh chuẩn hàng năm thực 1.85-2.00 tại -), chỉ thất bại dưới một ước lượng đếm-quá-mức. Một phán quyết ổn định-trên-toàn-dải mạnh hơn nhiều so với bất kỳ con số đơn lẻ nào.
- Kết hợp DSR với một Reality Check. Hãy chú ý rằng Reality Check và người anh em kiểu-SPA (đã studentized) của nó đã hiểu đúng Trường hợp B mà không cần bất kỳ sự can thiệp số-lần-thử nào cả (p = 0.0024 và 0.0038) — chúng xử lý sự phụ thuộc một cách tự nhiên, thông qua stationary bootstrap, bởi vì chúng lấy mẫu lại các dòng lợi nhuận tương quan thực tế thay vì đếm các cược độc lập giả định. Đó chính là yếu tố phân định cho toàn bộ mớ hỗn độn N-hiệu-quả: RC không cần . DSR và RC trả lời những câu hỏi khác nhau: DSR hỏi "kẻ thắng cuộc có đặc biệt trong tìm kiếm này không?" (và cần biết tìm kiếm đã thực hiện bao nhiêu lượt nhìn hiệu quả); RC/kiểu-SPA hỏi "quy tắc tốt nhất có đánh bại tiền mặt sau data-snooping không?" (và đọc sự phụ thuộc trực tiếp từ dữ liệu). Bạn muốn cả hai. Khi chúng bất đồng — như DSR-đếm-thô và RC đã làm ở đây — sự bất đồng đó mang tính chẩn đoán: nó thường có nghĩa là của bạn sai.
Đây chính là lời cảnh báo mang tính cấu trúc tương tự mà các nghiên cứu speed-ladder và IPC-tax của chúng tôi liên tục gặp phải từ phía kỹ thuật — một tìm kiếm nhanh chạy trên một lưới tương quan khổng lồ không mang lại cho bạn một số lượng cược độc lập khổng lồ, và việc coi kích thước lưới là số-lần-thử đánh lừa cả bộ tối ưu hóa lẫn bài kiểm định ý nghĩa của bạn. Bài viết đồng hành sắp tới về xác suất backtest overfitting tấn công cùng một sự thiên lệch lựa chọn từ phía lấy mẫu lại (CSCV), và kết hợp một cách tự nhiên với mọi thứ ở đây: DSR định giá kẻ thắng cuộc, PBO định giá quy trình.
Ghi Chú Trung Thực
Ba lưu ý, được nói thẳng thắn, bởi vì toàn bộ trọng tâm của một nghiên cứu có kiểm soát là không thổi phồng nó quá mức.
- Các lợi nhuận là tổng hợp (synthetic). iid Normal cho các thí nghiệm hiệu chuẩn và sức mạnh phát hiện, một quá trình chuyển đổi chế độ cho trường hợp lợi thế thực — được chọn vì ground truth có kiểm soát, không phải vì tính thực tế của thị trường. Lợi nhuận thực có đuôi béo, tự tương quan, và non-stationary, và các số hạng skew/kurtosis của PSR tồn tại chính xác để xử lý điều đầu tiên trong số đó. Điều được giao ở đây là phương pháp đã hiệu chuẩn, không phải một chiến lược: chúng ta chỉ có thể chứng minh một bài kiểm định kiểm soát phát hiện sai bằng cách chạy nó trên dữ liệu nơi chúng ta biết không có gì để phát hiện cả. Điều đó đòi hỏi phải tạo ra ground truth.
- Không có ước lượng N-hiệu-quả nào là chuẩn mực — đó là lý do tại sao chúng tôi báo cáo năm ước lượng. Công thức một dòng tương-quan-trung-bình dễ hiểu đối với người phản biện và đúng về mặt hướng (nhiều tương quan hơn ⇒ ít lần thử hiệu quả hơn), nhưng nó là hệ số giảm-phương-sai cho một trung bình — một sự không khớp về mặt hàm số với chuẩn giá trị lớn nhất của DSR — và gần nó tắt hoàn toàn việc khử lạm phát. Các ước lượng dựa-trên-eigenvalue (participation ratio, PCA-95%, Kaiser) khớp tốt hơn nhưng vẫn mang tính heuristic, và Cheverud-Nyholt đếm-quá-mức dưới điều kiện đồng-tương-quan. Cách tiếp cận đầy đủ hơn, có nguyên tắc hơn là phân cụm các lần thử (Phụ lục 3 của DSR, Bailey & López de Prado): nhóm các lần thử theo cấu trúc tương quan và đếm số cụm thay vì thu gọn mọi thứ về một scalar. Chúng tôi báo cáo toàn bộ dải chính xác là vì lựa chọn này chưa được giải quyết dứt điểm — một phán quyết ổn định trên cả năm ước lượng là tuyên bố trung thực; một phán quyết phụ thuộc vào việc chọn một ước lượng duy nhất thì không phải vậy.
- Bootstrap là một Reality Check đã studentized, không phải Hansen SPA đầy đủ, và số lần lấy mẫu lại khác nhau theo từng thí nghiệm. Bất cứ khi nào bài viết này nói "kiểu-SPA," nó có nghĩa là Reality Check của White với studentization theo từng quy tắc; sự tái căn giữa nhất quán, phụ thuộc mẫu đầy đủ của Hansen không được triển khai. Các tỷ lệ phát hiện sai trong hiệu chuẩn sử dụng 500 lần lấy mẫu lại stationary-bootstrap mỗi tìm kiếm trên 400 tìm kiếm; hai p-value RC/kiểu-SPA trong nghiên cứu tình huống sử dụng 5,000 lần lấy mẫu lại mỗi cái. Độ dài khối trung bình 20 xuyên suốt (Politis-Romano), , 252 chu kỳ/năm cho việc hàng năm hóa. Thay đổi những điều này và các con số ở chữ số thập phân thứ ba sẽ dịch chuyển; câu chuyện — ngây thơ 1.000 so với có nguyên tắc 0.001-0.057, một đường cong chữ S đạt sức mạnh 50% ngay trên trần nhiễu, và một cái bẫy lưới tương quan mà phán quyết của nó phải được đọc trên dải N-hiệu-quả — thì không.
Điểm Chính
- Một tìm kiếm tham số là một cỗ máy multiple-testing, và bài kiểm định ý nghĩa ngây thơ không nhìn thấy điều đó. Trên 1,000 chiến lược không-lợi-thế, Sharpe hàng năm tốt nhất trung bình là 1.63 với p-value kiểm định đơn lẻ trung vị 0.000686 — và bài kiểm định "nó có ý nghĩa không?" tuyên bố một phát hiện 100% số lần (tỷ lệ phát hiện sai 1.000). Một Sharpe tuyệt vời từ hư không, được chứng nhận là có ý nghĩa thống kê bởi một bài kiểm định chưa bao giờ hỏi đúng câu hỏi.
- Deflated Sharpe Ratio dịch chuyển cột mốc từ không sang trần nhiễu. DSR so sánh kẻ thắng cuộc không phải với không mà với , cái tốt nhất-do-may-mắn kỳ vọng của một tìm kiếm với kích thước này — đối với trường hợp null thì rơi vào mức 1.63 hàng năm, chính xác nơi kẻ thắng cuộc nhiễu trung bình nằm (suy ra: ). Tỷ lệ phát hiện sai null của nó là 0.001; haircut Harvey-Liu (Bonferroni/Holm 0.057, BHY 0.007) và White's Reality Check (0.022) đạt được cùng sự kiểm soát đó bằng những con đường khác.
- Nó giữ lại các lợi thế thực. Sức mạnh phát hiện của DSR vẽ ra một đường cong chữ S đạt sức mạnh 50% ở một Sharpe hàng năm ~1.73 — ngay trên trần nhiễu 1.63: 0.005 tại một Sharpe thực hàng năm 0.79, 0.651 tại 1.90, 0.998 tại 2.54, 1.000 tại 3.17, dương tính giả ~0 xuyên suốt. Các lợi thế dưới trần nhiễu được kết luận đúng đắn là không thể phân biệt được với may mắn; các lợi thế trên nó được giữ lại với sức mạnh tiến gần đến một.
- Lưới tương quan phá vỡ DSR thô — và không có N-hiệu-quả đơn lẻ nào cứu được nó; dải mới cứu được. Trên một MA crossover 640-ô (tương quan cặp trung bình ~0.61), DSR-đếm-thô đã bác bỏ sai một lợi thế thực sự (in-sample đã chọn, hàng năm 3.92) (0.748 < 0.95) bởi vì 640 lần thử tương quan không phải là 640 cược độc lập. Nhưng cách khắc phục không phải là một diệu kỳ duy nhất — ở ước lượng thô nhất () sự khử lạm phát về cơ bản bị tắt (thanh chuẩn ~0.25 hàng năm) và DSR chỉ đơn thuần vọng lại ý nghĩa thống kê thô. Bằng chứng thực sự là lợi thế được giữ lại trên toàn bộ dải các ước lượng chuẩn — DSR 1.000/1.000/1.000/0.999 tại 1.6/2.4/16/21, bao gồm một thanh chuẩn hàng năm thực 1.85-2.00 tại khoảng giữa PCA-95%/Kaiser có thể bảo vệ được — sống sót cho bất kỳ nào, và chỉ thất bại dưới con số 370 đếm-quá-mức của Cheverud-Nyholt. Random walk bị bác bỏ ở mọi ước lượng. Hãy đọc dải, không phải một điểm.
- Kết hợp DSR với một Reality Check, bởi vì chúng trả lời những câu hỏi khác nhau. Reality Check và người anh em kiểu-SPA (đã studentized) của nó đã xác nhận lợi thế thực (p = 0.0024 và 0.0038) mà không cần bất kỳ can thiệp số-lần-thử nào — chúng xử lý sự phụ thuộc một cách tự nhiên thông qua stationary bootstrap, đó chính xác là yếu tố phân định khi N-hiệu-quả đang bị tranh cãi. DSR hỏi "kẻ thắng cuộc có đặc biệt trong tìm kiếm này không?"; RC/kiểu-SPA hỏi "cái tốt nhất có đánh bại tiền mặt sau data-snooping không?" Một sự bất đồng giữa chúng là một tín hiệu cho thấy của bạn sai. Hãy chạy cả hai.
Kẻ thắng cuộc của một tìm kiếm có tội cho đến khi được chứng minh vô tội. P-value ngây thơ không phải là bằng chứng vô tội — đó là lời khai bị thổi phồng của chính tìm kiếm, và nó sẽ đảm bảo cho nhiễu thuần túy với mười hai số không của sự tự tin. Hãy khử lạm phát chuẩn xuống mức mà may mắn mang lại, đếm số lần thử hiệu quả của bạn một cách trung thực, và bootstrap giá trị lớn nhất để lấy ý kiến thứ hai. Cái vượt qua cả ba thanh chuẩn có thể thực sự là thật. Cái chỉ vượt qua thanh ngây thơ là người cao nhất trong một nghìn người tung đồng xu.
Thí nghiệm đầy đủ — bộ khung hiệu chuẩn null, việc quét sức mạnh phát hiện lợi thế được cài đặt, các tìm kiếm lưới tương quan, và mọi con số trong bài viết này có thể tái tạo được từ một script tất định duy nhất — nằm trong bài báo đồng hành tại deflated-sharpe.marketmaker.cc, với mã nguồn và dữ liệu tại github.com/suenot/deflated-sharpe-search.
Tác Giả

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Đọc Thêm

Probability of Backtest Overfitting: Tìm Kiếm Của Bạn Có Đánh Bại Được Một Lần Tung Đồng Xu?

Thiết Kế Hàm Mục Tiêu: Chỉ Số Bạn Tối Ưu Hóa Âm Thầm Chọn Chiến Lược Của Bạn
