نسبة Sharpe المخفّضة: كم عدد "الفائزين" في اختبارك الرجعي ينجون من الاختبار المتعدد؟
مقال من سلسلة "اختبارات رجعية بلا أوهام".
📄 تطورت هذه المقالة إلى ورقة بحثية. كل رقم أدناه يأتي من سكريبت حتمي واحد يبني حقيقة أساسية مضبوطة — عمليات بحث بضوضاء خالصة، وعمليات بحث بميزة مزروعة، وشبكة معلمات حقيقية مترابطة — ثم يُشغّل عليها نسبة Sharpe المخفّضة، وتشذيب Harvey-Liu للاختبار المتعدد، وReality Check لـWhite / SPA لـHansen، قايساً معدل الاكتشاف الكاذب وقوة الاكتشاف لكل طريقة مباشرة. اقرأ الورقة على الإنترنت (نسخة تفاعلية + PDF) على deflated-sharpe.marketmaker.cc، والكود والبيانات على github.com/suenot/deflated-sharpe-search.
تُشغّل مسحاً للمعلمات. ستة عشر طولاً سريعاً، وأربعون طولاً بطيئاً، 640 توليفة لتقاطع متوسط متحرك. تنتهي الشبكة وتتوهج خلية واحدة: Sharpe سنوية قدرها 3.9، وقيمة p لاختبار واحد تبلغ . اثنا عشر صفراً من الدلالة. لقد وجدت شيئاً.
أو أنك لم تجد شيئاً، والبحث هو من وجده من أجلك.
بحث المعلمات ليس اختباراً. إنه آلة لإيجاد الأوفر حظاً من بين N محاولة، وكلما زوّدتها بمحاولات أكثر، بدا فائزها أوفر حظاً — بوجود أو بغياب أي ميزة حقيقية تحته. تُضخَّم Sharpe الأفضل-من-N بالانتقاء بنفس الطريقة التي يكون بها الأطول من بين ألف شخص عشوائي طويلاً: ليس لأن الطول حقيقي، بل لأنك بحثت. إحصاءات الاختبار الواحد المطبوعة بجانب الفائز — قيمة p الخاصة به، وإحصائية t، و"هل هو ذو دلالة؟" — صُمِّمت لفرضية واحدة مُسجَّلة مسبقاً. أعطها الناجي من عملية بحث وستكذب، بثقة، في كل مرة.
تقيس هذه المقالة بالضبط مدى فداحة كذبها، ثم تقيس ثلاث أدوات تُصلح ذلك. بيت القصيد كله هو حقيقة أساسية مضبوطة: نولّد عوائد نعرف فيها الإجابة — أحياناً ضوضاء خالصة بلا ميزة، وأحياناً ميزة مزروعة بقوة معروفة — بحيث يكون "هل أصابت الطريقة؟" حقيقة، لا حكماً تقديرياً. إليك العنوان الرئيسي أولاً. في عمليات البحث ذات الحالة الصفرية المعروفة، حيث الإجابة الصادقة هي دائماً "لا اكتشاف"، إليك عدد مرات صراخ كل اختبار "الذئب قادم":
| الاختبار | معدل الاكتشاف الكاذب في عمليات بحث ذات حالة صفرية معروفة | الحكم |
|---|---|---|
| الاختبار الساذج "هل أفضل Sharpe ذو دلالة؟" | 1.000 | يُبلغ عن اكتشاف في كل مرة دون استثناء |
| نسبة Sharpe المخفّضة (DSR ≥ 0.95) | 0.001 | مضبوط |
| تشذيب Harvey-Liu — Bonferroni | 0.057 | ~مضبوط |
| تشذيب Harvey-Liu — Holm | 0.057 | ~مضبوط |
| تشذيب Harvey-Liu — BHY | 0.007 | مضبوط |
| Reality Check لـWhite (بوتستراب) | 0.022 | مضبوط |
1,000 استراتيجية لكل بحث، 1,000 مشاهدة لكل منها، 2,000 عملية بحث صفرية مستقلة، Sharpe الحقيقية = 0 في كل مكان. عوائد Normal اصطناعية iid، البذرة (seed) 0، α = 0.05، 252 فترة/سنة. معدل الاكتشاف الكاذب للاختبار الساذج ليس مرتفعاً — إنه واحد بالضبط.
اقرأ الصف الأول حتى يؤلمك. اختبار من المفترض أن يُطلق 5% من الوقت على الضوضاء الخالصة يُطلق 100% من الوقت — لأنك لا تُريه ضوضاء خالصة، بل تُريه أقصى قيمة من ألف سحبة من الضوضاء الخالصة، وأقصى قيمة من بين ألف رامي عملة يبدو دائماً كعبقري. كل صف آخر هو طريقة تعرف هذا وتصحّحه. هذه هي المقالة كاملة: لماذا الصف الأول هو 1.000، ولماذا الصفوف الأخرى ليست كذلك، والمكان الوحيد (القسم الأخير) الذي تحتاج فيه حتى الطرق الجيدة إلى تصحيح ثانٍ لتبقى صادقة.
الفصل 1 — الفخ: البحث يُصنّع Sharpe من العدم

ابدأ بأنظف فخ ممكن. وَلِّد استراتيجية عوائدها ضوضاء Normal قياسية مستقلة — بلا انجراف، بلا مهارة، Sharpe الحقيقية صفر تماماً لجميعها. كل واحدة لديها مشاهدة. والآن افعل ما يفعله كل بحث معلمات: احتفظ بالأفضل.
يبلغ متوسط Sharpe لكل مشاهدة للأفضل-من-1000 0.1027، والتي تُسنَّن سنوياً إلى 1.63 (مُشتق: ). هذا ليس رقماً متواضعاً. Sharpe سنوية قدرها 1.63 هي من نوع النتائج التي تجعل استراتيجية ما تُموَّل، ويُكتب عنها، ويُخصَّص لها رأس مال. جاءت من مولّد أرقام عشوائية بانجراف مضبوط على صفر.
الآن سلِّم الفائز إلى اختبار الدلالة الساذج — ذلك الذي تطبعه كل مكتبة اختبار رجعي مجاناً. حوِّل Sharpe الخاصة به إلى إحصائية t ()، خذ قيمة p أحادية الجانب، وسمّها اكتشافاً إذا كان :
الوسيط لقيمة p للاختبار الواحد لهؤلاء الفائزين بالضوضاء هو 0.000686 — ثلاثة أصفار من "الدلالة" لاستراتيجية بلا ميزة. وعبر 2,000 عملية بحث صفرية مستقلة، يُعلن الاختبار الساذج عن اكتشاف في كل واحدة منها: معدل اكتشاف كاذب قدره 1.000. ليس "مُضخَّماً". ليس "مرتفعاً بعض الشيء". اختبار صحيح، ببنائه، بنسبة 5% كحد أقصى من الوقت على فرضية عدم واحدة، يكون خاطئاً بنسبة 100% من الوقت على فائز بحث.
الآلية ليست دقيقة الخفاء بمجرد تسميتها. يسأل الاختبار الساذج: "هل يمكن أن تنشأ هذه الـSharpe بالصدفة تحت فرضية العدم؟" — سؤال عادل لاستراتيجية اخترتها قبل النظر إلى البيانات. لكنك اخترت هذه لأنها كانت صاحبة أعلى Sharpe من بين ألف. لقد اشترطت على القيمة القصوى، وتوزيع المعاينة للقيمة القصوى لا يشبه إطلاقاً توزيع المعاينة لسحبة واحدة. هذا هو نفس الداء الذي شخّصه تصنيف تحيز النظر المستقبلي لدينا من الطرف الآخر — هناك، صنّع تسرب بفارق شمعة واحدة Sharpe قدرها 15 من الضوضاء؛ هنا، بحث يُصنّع Sharpe قدرها 1.63 من الضوضاء بلا أي تسرب على الإطلاق، بالانتقاء وحده. آلية مختلفة، عرَض مطابق: Sharpe تبدو رائعة لكنها لا تعني شيئاً.
الرقم 1.63 هو المهم، فتشبّث به. إنه سقف الضوضاء لهذا البحث: Sharpe التي يجب أن تتوقعها من الأوفر حظاً بين 1,000 استراتيجية بلا ميزة. أي اختبار صادق لفائز بحث يجب أن يقارنه ليس بالصفر، بل بـهذا — بما يُقدّمه الحظ وحده حين تنظر ألف مرة.
الفصل 2 — عدة الأدوات: ثلاث طرق لتسعير البحث

ثلاثة برامج بحثية، وصلت باستقلالية، تصل جميعها إلى نفس الحل: توقف عن مقارنة الفائز بالصفر، وابدأ بمقارنته بما ينتجه بحث بهذا الحجم بالحظ. تختلف في كيفية بنائها لتلك المقارنة.
PSR ونسبة Sharpe المخفّضة (Bailey & López de Prado، 2012 / 2014)
تطرح نسبة Sharpe الاحتمالية (PSR) سؤالاً أكثر حدة من "هل Sharpe موجبة؟" إنها تسأل: بالنظر إلى طول العينة وشكل العوائد (الالتواء، الذيول السمينة)، ما هو احتمال أن تتجاوز Sharpe الحقيقية معياراً ؟
هنا هي دالة التوزيع التراكمي لـNormal القياسية، و هي الالتواء، و هي التفلطح باصطلاح غير الزائد (non-excess) (Normal ⇒ ؛ استبدل التفلطح الزائد هنا دون إضافة 3 وسيخرج التخفيض خاطئاً). اضبط وتصبح PSR مجرد اختبار دلالة لعينة محدودة. السحر يكمن في اختيار جيداً.
نسبة Sharpe المخفّضة (DSR) هي PSR مُقيَّمة عند معيار ليس صفراً بل أقصى Sharpe متوقعة للبحث كاملاً:
حيث هو التباين عبر كل Sharpe التجارب الـN (التشتت الذي أنتجه البحث نفسه)، و هو ثابت أويلر-ماشيروني، والحدّان معكوسا-Normal هما تقريب نظرية القيم القصوى للقيمة القصوى المتوقعة لـ سحبة Normal قياسية. في الكود، الأمر أقصر من أن يكون مثيراً للإعجاب:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
بعدها تكون DSR ببساطة PSR بذلك الشريط المخفَّض:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR احتمال. نُعلن اكتشافاً عندما تكون : أي أن Sharpe الحقيقية للفائز تتفوق على أفضل-بالحظ المتوقع بثقة 95%. لاحظ الافتراض الحامل المُدمَج في : تُعامَل التجارب الـ على أنها مستقلة. الفصل 5 كله عن ما يحدث حين لا تكون كذلك.
تشذيب Harvey-Liu (2015)
يهاجم Harvey وLiu نفس المشكلة عبر تعديلات قيم p للاختبار المتعدد — الآلية الكلاسيكية لـ"شغّلت M اختبار، لا تدعني أخدع نفسي." رتِّب قيم p للاختبار الواحد وضخِّمها:
Bonferroni هو الأداة الفظّة (تتحكم في احتمال أي إيجابية كاذبة بضرب كل قيمة p في )؛ وHolm هو ابن عمها الأكثر قوة بشكل منتظم من نوع الخطوة-النازلة (step-down). الثالث، Benjamini-Yekutieli (BHY)، يتحكم في معدل الاكتشاف الكاذب — الجزء المتوقع من رفوضاتك الخاطئة — والأهم أنه يفعل ذلك تحت اعتماد اعتباطي بين الاختبارات، مستخدماً المُطبِّع التوافقي في البسط:
ذلك هو الثمن الذي يفرضه BHY مقابل عدم افتراض أن تجاربك الـ1,000 مستقلة — إنه يُضخِّم عتبة FDR بعامل ينمو مثل . "التشذيب" نفسه هو المقياس الحاسم: حوِّل قيمة p المُعدَّلة مرة أخرى إلى Sharpe وأبلغ عن مقدار ما اضطررت لتشذيبه من Sharpe الأصلية. تشذيب بنسبة 100% يعني أن الفائز يُفسَّر بالكامل بالاختبار المتعدد؛ و15% يعني أنه ينجو في معظمه.
Reality Check لـWhite وSPA لـHansen (2000 / 2005)
الأداة الثالثة لا تضع أي افتراض توزيعي على الإطلاق. يأخذ Reality Check لـWhite العوائد الفعلية لكل قاعدة، ويكوّن إحصائية القيمة القصوى-عبر-القواعد، ويطبّق البوتستراب على توزيعها الصفري مباشرة:
حيث هو متوسط أداء القاعدة فوق المعيار. إنه يعيد أخذ عينات من العوائد بـالبوتستراب الثابت (stationary bootstrap) (Politis-Romano — كتل بطول عشوائي بحيث ينجو الارتباط التسلسلي من إعادة أخذ العينات)، ويُعيد توسيط كل سحبة لتحقيق فرضية العدم ببنائها، ويُعيد حساب القيمة القصوى في كل سحبة، ويُبلغ عن قيمة p كنسبة أقصى قيم البوتستراب التي تتفوق على القيمة المُلاحَظة. يشحذ SPA لـHansen، RC، بطريقتين: التطليب (studentization) (قسمة متوسط كل قاعدة على خطئها المعياري الخاص، بحيث لا يمكن لقاعدة واحدة جامحة عالية التباين أن تخطف القيمة القصوى) وإعادة توسيط متسقة تعتمد على العينة لفرضية العدم. تطبيقنا يضيف التطليب لكنه لا يضيف خطوة إعادة التوسيط المتسقة الكاملة — لذا أينما أبلغت هذه المقالة عن قيمة p من نوع SPA، اقرأها على أنها Reality Check مُطلَّبة (studentized)، وليست SPA لـHansen الكاملة. حيث تسأل DSR "هل الفائز مميز داخل هذا البحث؟"، يسأل Reality Check "هل تتفوق أفضل قاعدة على النقد بعد احتساب صادق لعدد القواعد التي جربتها؟" — وهو يتعامل مع القواعد المترابطة أصلياً، عبر البوتستراب، دون عدّ التجارب أبداً. احتفظ بهذا التمييز؛ فالقسم الأخير يدور حوله.
الفصل 3 — المعايرة هي البرهان كله
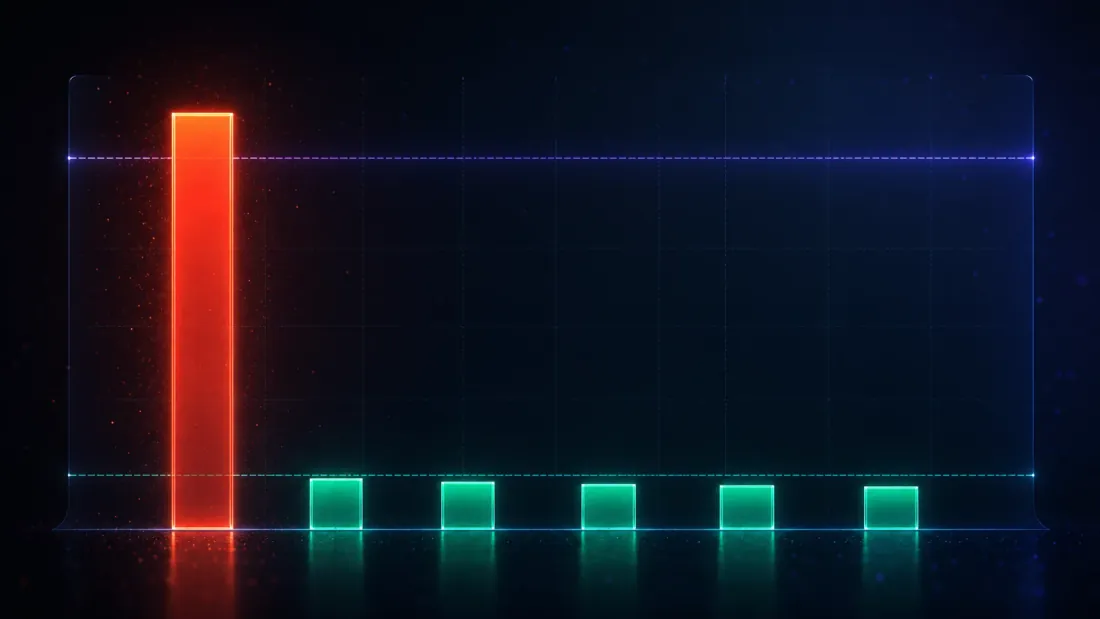
طريقة لا تُبلغ عن شيء سيكون لها أيضاً معدل اكتشاف كاذب يساوي صفراً — وستكون عديمة الفائدة. لذا فإن الاختبار الوحيد ذا المعنى لهذه الأدوات هو اختبار ذو وجهين: على بيانات ذات حالة صفرية معروفة يجب أن تضبط الاكتشافات الكاذبة عند أو أقل، وعلى بيانات ذات ميزة معروفة (القسم التالي) يجب أن تُطلق مع ذلك. هذا القسم هو النصف الأول.
شغِّل 2,000 عملية بحث مستقلة، كل واحدة على 1,000 استراتيجية بلا ميزة، واحسب عدد مرات إعلان كل طريقة عن اكتشاف. ذلك العدد، مقسوماً على 2,000، هو معدل الاكتشاف الكاذب — ولأن الحقيقة هي لا ميزة، فكل اكتشاف كاذب:
| الاختبار | معدل الاكتشاف الكاذب (α = 0.05) |
|---|---|
| الدلالة الساذجة | 1.000 |
| نسبة Sharpe المخفّضة | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| Reality Check لـWhite | 0.022 |
كل طريقة مبدئية تهبط عند خط الـ5% أو قربه — تشذيبا FWER أعلى منه بقليل، وDSR/BHY/RC أدناه — بينما يستقر الاختبار الساذج عند 100. (يطبع Bonferroni وHolm نفس القيمة 0.057 هنا، وليس بالصدفة: للاستراتيجية الوحيدة الأفضل فإن الخطوة الأولى لـHolm هي ، مطابقة لـBonferroni بالبناء، لذا هما تأكيد واحد، وليسا اثنين.) لكن أعمق رقم في الدراسة كلها ليس في هذا الجدول — إنه المعيار المخفَّض الذي يُنتج عمود DSR. بالمتوسط عبر عمليات البحث الصفرية، تخرج عند 0.1030 لكل مشاهدة، والتي تُسنَّن سنوياً إلى 1.63 (مُشتق: ) — نفس الـ1.63 التي يُسجّلها فائز الضوضاء المتوسط (1.63). هذه ليست صدفة؛ إنها الفكرة كاملة وهي تعمل:
الشريط المخفَّض يقف بالضبط عند سقف الضوضاء. لا تطلب DSR من فائز بحث أن يتفوق على الصفر. إنها تطلب من الفائز أن يتفوق على أفضل نتيجة ينتجها الحظ وحده من بحث بهذا الحجم — 1.63 سنوياً هنا. فائز يُطابق سقف الضوضاء فقط يُسجِّل DSR ≈ 0.5 (رمية عملة)، ولهذا فإن DSR الصفرية المتوسطة هي 0.495، وليست شيئاً صغيراً. ليكون اكتشافاً، يجب على الفائز أن يتجاوز 1.63 وأكثر — بما يكفي لدفع PSR فوق 0.95.
هذا يُعيد صياغة التمرين كله. يقيس الاختبار الساذج المسافة من الصفر؛ كل بحث يتجاوز ذلك الشريط بتفاهة، ولهذا فهو عديم الفائدة. تقيس DSR المسافة من سقف الضوضاء، وتجاوز ذلك الشريط صعب حقاً — كما ينبغي أن يكون. يصل تشذيب Harvey-Liu وReality Check إلى نفس الضبط بطرق مختلفة (تضخيم لـBHY، وتوزيع قيمة قصوى بالبوتستراب لـRC)، ويهبطان في نفس الجوار: من 0.001 إلى 0.057، عند أو قربه. القيمة 0.057 لـBonferroni/Holm هي أعلى بقليل فوق خط الـ5%، لكن بالكاد: مع 2,000 بحث مونت كارلو، يبلغ الخطأ المعياري لتقدير FDR قرب 0.05 حوالي 0.005، لذا تقف 0.057 على بعد 1.4 خطأ معياري تقريباً فوق — ضوضاء مونت كارلو، وليست ضماناً معطوباً. "ضبط FWER" هو أصلاً وعد مقارب، وليس دقيقاً حتى آخر رقم عند .
الفصل 4 — القوة: هل يحتفظ الاختبار بالميزات الحقيقية؟
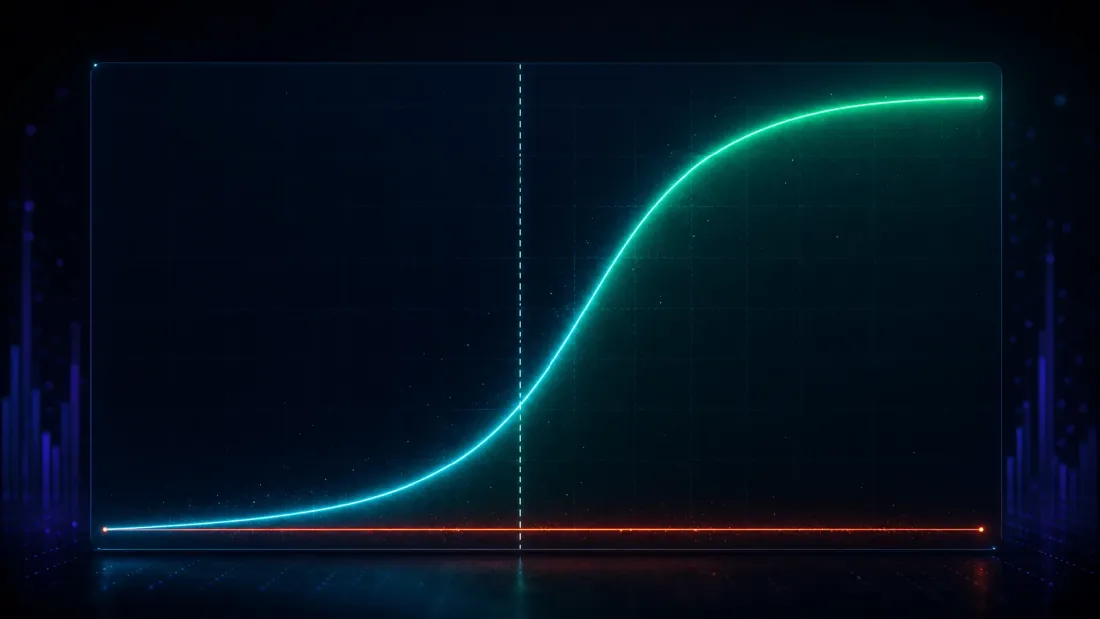
ضبط الاكتشافات الكاذبة نصف الاختبار فقط — طريقة مذعورة ترفض كل شيء تُسجِّل 0.000 مثالية وتكون عديمة القيمة. النصف الآخر: عندما تكون هناك ميزة حقيقية فعلاً، هل تجدها DSR؟
ازرع واحدة. في حقل من 1,000 استراتيجية، اجعل 25 منها تحمل ميزة حقيقية بقوة معروفة واترك الباقي كضوضاء، ثم شغِّل البحث واسأل هل تُبلغ DSR عن الفائز. امسح الميزة المزروعة من ضعيفة إلى قوية وسيرسم منحنى القوة منحنى S نظيفاً (يبقى معدل الإيجابيات الكاذبة عند ~0 طوال الوقت):
| Sharpe الحقيقية المزروعة (سنوية) | قوة اكتشاف DSR | معدل الإيجابيات الكاذبة لـDSR |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
انظر إلى أين ينعطف المنحنى. تحت سقف الضوضاء — Sharpe حقيقية سنوية 0.79، أدنى بكثير من 1.63 — تُطلق DSR 0.5% من الوقت، رافضة بصواب أن تُسمِّيه: ميزة بهذا الضعف لا يمكن تمييزها حقاً عن الحظ الذي يولّده بحث بـ1,000 تجربة، والتظاهر بغير ذلك سيكون كذباً، لا قوة. حول السقف مباشرة يتسلق المنحنى بحدة (0.09 عند 1.27، 0.65 عند 1.90). عند Sharpe سنوية قدرها 2.54 تبلغ القوة 0.998؛ وعند 3.17 تكون 1.000 مثالية. تُحفظ الميزات القوية في كل مرة تقريباً، وتبقى الإيجابيات الكاذبة مثبَّتة عند الصفر، ونقطة تقاطع قوة الـ50% تقع عند Sharpe سنوية تبلغ حوالي 1.73 (مُشتقة بالاستيفاء بين صفَّي 1.27 و1.90) — فوق سقف الضوضاء 1.63 مباشرة، تماماً حيث ينبغي لشريط صادق أن يضعها: النقطة التي تبدأ فيها الميزة بتجاوز ما يخترعه بحث بـ1,000 تجربة.
هذه هي الخاصية التي تريدها فعلاً، معبَّراً عنها كمنحنى S: تُستبعد الميزات تحت سقف الضوضاء بصواب باعتبارها حظاً؛ وتُحفظ الميزات الأعلى منه بارتياح بقوة تقترب من واحد. الاختبار الساذج، في المقابل، "يكتشف" الميزة المزروعة 67% من الوقت حتى عند Sharpe حقيقية تبلغ 0.79 — لكن ذلك الرقم عديم المعنى، لأننا رأينا بالفعل أنه يكتشف ميزة غير موجودة 100% من الوقت. اختبار يُطلق على كل شيء لا يملك قوة؛ لا يملك تمييزاً. تُضحّي DSR بقليل من الحساسية تجاه الميزات الهامشية (صفَّا 0.79 و1.27) مقابل الشيء المهم: اكتشافاتها حقيقية.
الفصل 5 — فخ الممارس: الشبكات المترابطة
كل ما سبق استخدم استراتيجيات مستقلة — أنظف إعداد ممكن، والإعداد الذي يصمد فيه افتراض الاستقلالية لـDSR تماماً. شبكات المعلمات الحقيقية ليست كذلك، وهنا تصبح أداة مُستخدَمة بسذاجة طريقة جديدة لتكون مخطئاً.
خذ بحث تقاطع متوسط متحرك صادقاً: 16 طولاً سريعاً 40 طولاً بطيئاً تجربة، كل واحدة 755 مشاهدة. شبكة كهذه مغموسة بالارتباط — fast=45/slow=120 وfast=45/slow=125 هما تقريباً نفس الاستراتيجية، لذا تتحرك سلاسل عوائدهما معاً. متوسط الارتباط الثنائي المقاس عبر الـ640 تجربة: حوالي 0.61. هذه ليست 640 رهاناً مستقلاً. ليست كذلك بأي حال.
الحالة أ — مسير عشوائي (بلا ميزة): كل طريقة تقتلها، بصواب
شغِّل الشبكة على مسير عشوائي خالص. يبدو الفائز مغرياً: المعلمات fast=45/slow=120، أفضل Sharpe سنوية 0.81، قيمة p للاختبار الواحد 0.081. كل طريقة ترى عبره:
| الطريقة | النتيجة | الحكم |
|---|---|---|
| DSR (K خام = 640) | 0.431 | رفض (< 0.95) |
| قيمة p لـReality Check | 0.570 | رفض |
| قيمة p من نوع SPA (RC مُطلَّبة) | 0.569 | رفض |
| تشذيب Harvey-Liu | 100% | رفض |
ابدأ بالدليل الذي لا يحتاج إلى أي تخفيض على الإطلاق: حتى الدلالة غير المُعدَّلة لعينة محدودة لهذا الفائز، -مقابل-صفر، هي فقط 0.918 — أقل من 0.95 بالفعل قبل أن نصحح لأي واحدة من الـ640 تجربة. ثم يدفنها التخفيض: الشريط هو لكل مشاهدة، أي ~0.91 سنوياً (مُشتق: ) — أعلى من 0.81 الخاصة بالفائز. أفضل استراتيجية لا تصل حتى إلى سقف الضوضاء، DSR ≈ 0.43 (أسوأ من رمية عملة)، ويتفق Reality Check واختبار نوع SPA وتشذيب بنسبة 100% جميعها: لا شيء هنا. مثالي. هذه هي الحالة السهلة، وهي تعمل — وكما سنرى، تبقى مرفوضة عند كل عدد تجارب فعّال نجرّبه.
الحالة ب — ميزة نظام حقيقية: DSR الخام يُخطئها
الآن شغِّل نفس الشبكة على سلسلة متبدّلة الأنظمة تحمل ميزة حقيقية قابلة للاستغلال. الفائز حاسم: المعلمات fast=3/slow=55، أفضل Sharpe سنوية 3.92 — هذه هي Sharpe داخل العينة، المُنتقاة، وهي نفسها مُضخَّمة بالانتقاء بفعل البحث (ليست ميزة حقيقية أو خارج العينة)، لكن أثر النظام الكامن حقيقي — بقيمة p للاختبار الواحد ودلالة -مقابل-صفر غير مخفَّضة تبلغ عملياً 1.000. توجد ميزة حقيقية هنا ووجدها الفائز. راقب DSR الخام يرفضها مع ذلك:
| الطريقة | النتيجة | الحكم |
|---|---|---|
| DSR (K خام = 640) | 0.748 | رفض (< 0.95) ✗ تخفيض مُفرط |
| قيمة p لـReality Check | 0.0024 | تأكيد ✓ |
| قيمة p من نوع SPA (RC مُطلَّبة) | 0.0038 | تأكيد ✓ |
| تشذيب Harvey-Liu | 15% | تأكيد ✓ |
DSR الخام البالغة 0.748 هي رفض كاذب لميزة حقيقية. السبب هو افتراض الاستقلالية، المنتهَك بشدة الآن: بنت DSR شريطها المخفَّض بمعاملة 640 تجربة مترابطة كـ640 سحبة مستقلة، مما يُضخِّم أقصى-متوقع إلى 0.221 لكل مشاهدة — أي ~3.51 سنوياً (مُشتق: ). مقابل شريط قدره 3.51، يتجاوزه فائز بـ3.92 بتواضع فقط، وتهبط DSR عند 0.748 — أقل من 0.95. شيئان يضخّمان ذلك الشريط: العدد الخام (640 نظرة بدلاً من حفنة فعّالة منها)، وتشتت مهارة حقيقي بين التجارب — بعض أزواج المعلمات أفضل فعلاً على سلسلة نظام، ما يوسّع ويرفع إلى ما هو أبعد مما يفعله الحظ الخالص وحده. كلاهما يدفع في نفس الاتجاه، وينتهي الشريط مرتفعاً جداً لأن البحث لم يكن أبداً حقاً 640 نظرة مستقلة؛ كان بضعة رهانات مستقلة، أُخذت عينات منها 640 مرة.
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
بـ و، هذا يُقلِّص الشبكة إلى تجربة فعّالة (مُشتق: )، وتقفز DSR إلى 1.000. لكن توقف قبل أن تحتفل بذلك الرقم، لأنه أضعف دليل في هذا القسم كله. عند ينهار الشريط المخفَّض إلى سنوياً — وهو أساساً متوسط التجارب، أي أساساً صفر. التخفيض هناك مُطفَأ: DSR عند هي مجرد إعادة إبلاغ عن دلالة الفائز غير المخفَّضة لعينة محدودة (-مقابل-صفر ). الحكم موروث من الدلالة الخام، وليس مُنتَجاً بتصحيح الاختبار المتعدد. والتحذير المرآوي في جانب المسير العشوائي: رفضه عند يصمد فقط لأن ذلك الفائز كان هامشياً باستقلالية منذ البداية (-مقابل-صفر ). ارسِ الحجة كلها على 1.6 ومن حق المتشكك أن يهزّ كتفيه: لقد أطفأت التصحيح وأبلغت عن أياً كان الموجود تحته.
لذا لا تُرسِ على مقدِّر واحد. الخطوة الصادقة — والأقوى — هي حساب بـخمس طرق قياسية مختلفة وقراءة الحكم عبر النطاق كله. إليك خمسة مقدِّرات مُطبَّقة على نفس شبكة الإشارة ذات الـ640 تجربة، كل واحد بالشريط المخفَّض الذي يتضمنه وDSR التي يُنتجها:
| مقدِّر التجارب الفعّال | الشريط المخفَّض (سنوي) | DSR | الحكم | |
|---|---|---|---|---|
| متوسط الارتباط | 1.6 | 0.25 | 1.000 | إبقاء |
| نسبة المشاركة | 2.4 | 0.43 | 1.000 | إبقاء |
| PCA (95% من التباين) | 16 | 1.85 | 1.000 | إبقاء |
| Kaiser (قيم ذاتية > 1) | 21 | 2.00 | 0.999 | إبقاء |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | رفض |
| عدد الشبكة الخام (بلا تعديل) | 640 | 3.51 | 0.748 | رفض |
المقدِّرات: متوسط الارتباط هو سطر الواحد أعلاه؛ تقرأ نسبة المشاركة وعدّا PCA-95%/Kaiser الأبعاد الفعّالة من القيم الذاتية لمصفوفة الارتباط؛ وCheverud-Nyholt هو مقدِّر تباين-القيم-الذاتية من أدبيات علم الوراثة معروف بأنه يُفرط في العدّ تحت شبه تساوي الارتباط.
الآن تصل الفكرة، وهي ليست "أي تعديل يُنقذك". انظر إلى الوسط القابل للدفاع عنه — PCA-95% () وKaiser (). هذان ليسا نظام إطفاء-التخفيض؛ إنهما يفرضان شريط سنوياً حقيقياً من 1.85 إلى 2.00 — تشذيب جدّي، أعلى بكثير من الضوضاء، عقوبة اختبار متعدد حقيقية لـ16-21 نظرة فعّالة. والميزة 3.92 لا تزال تتجاوزه (DSR بـ1.000 و0.999). تصمد الإشارة أمام DSR لـأي أدنى من 144.8 (مُشتقة من نقطة التقاطع)؛ وتفشل فقط تحت لـCheverud-Nyholt، وهو مقدِّر يُفرط بشكل مُثبَت في العدّ عندما تكون التجارب شبه متساوية الارتباط — وحتى العدد الخام غير المُعدَّل البالغ 640 لا يدفع DSR إلا إلى 0.748، لا إلى الصفر. فائز المسير العشوائي، عند تشغيله عبر نفس المقدِّرات الخمسة بالضبط، مرفوض عند كل واحد منها (لا يصمد لأي أعلى من 1). هذه هي النتيجة الحقيقية: ليست رقماً واحداً محظوظاً، بل حكم مستقر عبر النطاق الكامل لمقدِّرات التجارب الفعّالة القياسية — وهو دليل أقوى بكثير من الوثوق بأي واحد منها.
تحذير تقني واحد على أخشن مقدِّر، لأنه يُفسّر لماذا يقف عند الطرف الليّن: هو في الحقيقة عامل تخفيض-التباين لـمتوسط متغيرات مترابطة (كم يشتري لك المتوسط تحت الارتباط ). معيار DSR كمية من نوع القيمة القصوى — أقصى متوقع للتجارب — لذا فإن استخدام انكماش تباين-المتوسط كعدد تجاربها هو عدم تطابق وظيفي: صحيح في الاتجاه (مترابط ⇐ تجارب فعّالة أقل)، لكنه ليست الكمية التي يعتمد عليها فعلاً توزيع القيمة القصوى. هذا بالضبط سبب كون المقدِّرات المبنية على القيم الذاتية في منتصف النطاق هي القراءة الأجدر بالثقة، وسبب كون النطاق، وليس النقطة، هو المُنتَج المطلوب.
الدرس: استخدم كلتا الأداتين، وأعطِ DSR الـN الصحيح

ينتج عن الحالة ب أمران، وكلاهما حامل:
- حجم الشبكة الخام هو الـN الخاطئ لـDSR كلما كانت التجارب مترابطة — ولا يوجد N فعّال واحد صحيح أيضاً. إدخال 640 في صيغة تفترض الاستقلالية يُفرط في التخفيض: يُصنّع سقف ضوضاء أطول بكثير مما بلغه البحث فعلاً ويدفن ميزات حقيقية تحته. تحتاج DSR إلى عدد التجارب الفعّال — لكن الإصلاح ليس الوثوق بمقدِّر واحد (ولا سيما أخشنها، حيث يُطفأ التصحيح قرب ). الإصلاح هو قراءة الحكم عبر النطاق الكامل للمقدِّرات القياسية (هنا من 1.6 إلى 370) ورؤية ما إذا كان مستقراً. لهذه الميزة كان كذلك: مُبقى عليها في كل مكان يكون فيه التخفيض نشطاً حقاً (شريط سنوي حقيقي من 1.85-2.00 عند -)، فاشلاً فقط تحت مقدِّر يُفرط في العدّ. حكم مستقر عبر النطاق أقوى بكثير من أي رقم واحد.
- اقرن DSR بـReality Check. لاحظ أن Reality Check وابن عمه من نوع SPA (المُطلَّب) أصابا الحالة ب دون أي جراحة على عدد التجارب على الإطلاق (p = 0.0024 و0.0038) — إنهما يتعاملان مع الاعتماد أصلياً، عبر البوتستراب الثابت، لأنهما يُعيدان أخذ عينات من سلاسل العوائد المترابطة الفعلية بدلاً من عدّ رهانات مستقلة افتراضية. هذا هو الفيصل في فوضى الـN الفعّال كلها: RC لا يحتاج إلى . تُجيب DSR وRC عن سؤالين مختلفين: تسأل DSR "هل الفائز مميز داخل هذا البحث؟" (وتحتاج إلى معرفة عدد النظرات الفعّالة التي أخذها البحث)؛ يسأل RC/نوع SPA "هل تتفوق أفضل قاعدة على النقد بعد التنقيب في البيانات؟" (ويقرآن الاعتماد من البيانات نفسها). تريد كليهما. عندما يختلفان — كما فعلت DSR بالعدد الخام وRC هنا — يكون الاختلاف تشخيصياً: عادة ما يعني أن الخاص بك خاطئ.
هذا هو نفس التحذير البنيوي الذي ظلت دراستا سلم السرعة وضريبة IPC لدينا تصطدمان به من الجانب الهندسي — بحث سريع يُشغِّل شبكة ضخمة مترابطة لا يشتري لك عدداً هائلاً من الرهانات المستقلة، ومعاملة حجم الشبكة كعدد تجارب يخدع كلاً من مُحسِّنك واختبار الدلالة الخاص بك. المقالة المرافقة القادمة عن احتمال الإفراط في تخصيص الاختبار الرجعي تهاجم نفس تحيز الانتقاء من جانب إعادة أخذ العينات (CSCV)، وتقترن طبيعياً بكل ما هنا: DSR تُسعِّر الفائز، وPBO تُسعِّر الإجراء.
ملاحظات الصدق
ثلاثة تحذيرات، مذكورة بوضوح، لأن بيت القصيد كله من دراسة مضبوطة هو عدم المبالغة في تسويقها.
- العوائد اصطناعية. Normal iid لتجارب المعايرة والقوة، وعملية متبدّلة الأنظمة لحالة الميزة الحقيقية — اختيرت من أجل حقيقة أساسية مضبوطة، لا من أجل واقعية السوق. العوائد الحقيقية ذوات ذيول سمينة، ومترابطة ذاتياً، وغير مستقرة، وحدود الالتواء/التفلطح في PSR موجودة تحديداً لمعالجة الأولى من هذه. المُنتَج المُسلَّم هنا هو الطريقة المُعايَرة، لا استراتيجية: لا يمكننا إثبات أن اختباراً يضبط الاكتشافات الكاذبة إلا بتشغيله على بيانات نعرف فيها أنه لا يوجد شيء لاكتشافه. هذا يتطلب تصنيع الحقيقة الأساسية.
- لا يوجد مقدِّر N فعّال معياري — لهذا أبلغنا عن خمسة. سطر متوسط الارتباط الواحد مقروء للمراجع وصحيح اتجاهياً (ارتباط أكثر ⇐ تجارب فعّالة أقل)، لكنه عامل تخفيض-التباين لـمتوسط — عدم تطابق وظيفي مع معيار DSR ذي القيمة القصوى — وقرب يُطفئ التخفيض تماماً. مقدِّرات القيم الذاتية (نسبة المشاركة، PCA-95%، Kaiser) أفضل تطابقاً لكنها لا تزال استكشافية، ويُفرط Cheverud-Nyholt في العدّ تحت تساوي الارتباط. النهج الأكمل والأكثر مبدئية هو تجميع (clustering) التجارب (الملحق 3 لـDSR عند Bailey وLópez de Prado): تجميع التجارب حسب بنية الارتباط وعدّ المجموعات بدلاً من طيّ كل شيء إلى عدد قياسي واحد. نُبلغ عن النطاق كله بالضبط لأن الاختيار غير محسوم — حكم مستقر عبر المقدِّرات الخمسة كلها هو الادعاء الصادق؛ أما ما يعتمد على اختيار مقدِّر واحد فلن يكون كذلك.
- البوتستراب هو Reality Check مُطلَّبة، لا SPA الكاملة لـHansen، وأعداد إعادة أخذ العينات تختلف حسب التجربة. أينما تقول هذه المقالة "نوع SPA"، فإنها تعني Reality Check لـWhite مع تطليب لكل قاعدة؛ إعادة التوسيط المتسقة الكاملة المعتمدة على العينة لـHansen غير مُطبَّقة. تستخدم معدلات الاكتشاف الكاذب للمعايرة 500 إعادة أخذ عينات بالبوتستراب الثابت لكل بحث عبر 400 بحث؛ وتستخدم قيمتا p لـRC/نوع SPA في دراسة الحالة 5,000 إعادة أخذ عينات لكل منهما. متوسط طول الكتلة 20 طوال الوقت (Politis-Romano)، ، 252 فترة/سنة للتسنين السنوي. غيِّر هذه وستتحرك الأرقام عند الرقم العشري الثالث؛ لكن القصة — الساذج 1.000 مقابل المبدئي 0.001-0.057، ومنحنى S يبلغ قوة 50% فوق سقف الضوضاء مباشرة، وفخ شبكة مترابطة يجب قراءة حكمه عبر نطاق N الفعّال — لا تتحرك.
الخلاصات
- بحث المعلمات آلة اختبار متعدد، والاختبار الساذج للدلالة أعمى عنها. على 1,000 استراتيجية بلا ميزة، يبلغ متوسط أفضل Sharpe سنوية 1.63 مع وسيط قيمة p لاختبار واحد يبلغ 0.000686 — ويُعلن اختبار "هل هو ذو دلالة؟" عن اكتشاف 100% من الوقت (معدل اكتشاف كاذب 1.000). Sharpe رائعة من العدم، مُصدَّق عليها كذات دلالة بواسطة اختبار لم يطرح السؤال الصحيح قط.
- نسبة Sharpe المخفّضة تنقل مرمى الهدف من الصفر إلى سقف الضوضاء. تقارن DSR الفائز ليس بالصفر بل بـ، أفضل-بالحظ المتوقع لبحث بهذا الحجم — والذي يهبط للحالة الصفرية عند 1.63 سنوياً، بالضبط حيث يقف فائز الضوضاء المتوسط (مُشتق: ). معدل الاكتشاف الكاذب الصفري لها هو 0.001؛ ويصل تشذيب Harvey-Liu (Bonferroni/Holm بـ0.057، BHY بـ0.007) وReality Check لـWhite (0.022) إلى نفس الضبط بطرق أخرى.
- إنها تحتفظ بالميزات الحقيقية. يرسم منحنى قوة اكتشاف DSR منحنى S يبلغ قوة 50% عند Sharpe سنوية ~1.73 — فوق سقف الضوضاء 1.63 مباشرة: 0.005 عند Sharpe حقيقية سنوية 0.79، 0.651 عند 1.90، 0.998 عند 2.54، 1.000 عند 3.17، والإيجابيات الكاذبة ~0 طوال الوقت. تُستبعد بصواب الميزات تحت السقف باعتبارها لا تُميَّز عن الحظ؛ وتُحفظ الميزات فوقه بقوة تقترب من واحد.
- الشبكات المترابطة تكسر DSR الخام — ولا يُنقذها N فعّال واحد؛ النطاق هو من يفعل. على تقاطع MA بـ640 خلية (متوسط ارتباط ثنائي ~0.61)، رفضت DSR بالعدد الخام بشكل كاذب ميزة حقيقية (مُنتقاة داخل العينة، 3.92 سنوياً) (0.748 < 0.95) لأن 640 تجربة مترابطة ليست 640 رهاناً مستقلاً. لكن الإصلاح ليس سحرياً واحداً — عند أخشن تقدير () يُطفأ التخفيض أساساً (شريط ~0.25 سنوياً) وتُردِّد DSR ببساطة الدلالة الخام. الدليل الحقيقي هو أن الميزة مُبقى عليها عبر النطاق كله من المقدِّرات القياسية — DSR بـ1.000/1.000/1.000/0.999 عند 1.6/2.4/16/21، بما في ذلك شريط سنوي حقيقي من 1.85-2.00 عند المدى الوسيط القابل للدفاع عنه PCA-95%/Kaiser — تصمد لأي ، وتفشل فقط تحت 370 المُفرِط في العدّ لـCheverud-Nyholt. المسير العشوائي مرفوض عند كل مقدِّر. اقرأ النطاق، لا نقطة واحدة.
- اقرن DSR بـReality Check، لأنهما يُجيبان عن سؤالين مختلفين. أكد Reality Check وابن عمه من نوع SPA (المُطلَّب) الميزة الحقيقية (p = 0.0024 و0.0038) دون أي جراحة على عدد التجارب — يتعاملان مع الاعتماد أصلياً عبر البوتستراب الثابت، وهو بالضبط الفيصل عندما يكون N الفعّال محل نزاع. تسأل DSR "هل الفائز مميز داخل هذا البحث؟"؛ ويسأل RC/نوع SPA "هل يتفوق الأفضل على النقد بعد التنقيب في البيانات؟" اختلافهما إشارة إلى أن الخاص بك خاطئ. شغِّل كليهما.
فائز البحث مذنب حتى تثبت براءته. قيمة p الساذجة ليست إثبات براءة — إنها شهادة البحث المُضخَّمة الخاصة به، وستشهد للضوضاء الخالصة بثقة اثني عشر صفراً. خفِّض المعيار إلى ما يُقدّمه الحظ، واحسب تجاربك الفعّالة بصدق، وطبِّق البوتستراب على القيمة القصوى لرأي ثانٍ. ما يتجاوز الأشرطة الثلاثة كلها قد يكون حقيقياً فعلاً. وما يتجاوز الساذج وحده هو الأطول من بين ألف رامي عملة.
التجربة الكاملة — إطار عمل معايرة الحالة الصفرية، ومسح قوة الميزة المزروعة، وعمليات بحث الشبكة المترابطة، وكل رقم في هذه المقالة قابل لإعادة التوليد من سكريبت حتمي واحد — موجودة في الورقة المرافقة على deflated-sharpe.marketmaker.cc، مع الكود والبيانات على github.com/suenot/deflated-sharpe-search.
Authors

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Read More

احتمال الإفراط في تخصيص الاختبار الرجعي: هل تغلب بحثك على رمية عملة؟

تصميم دالة الهدف: المقياس الذي تُحسّنه يختار استراتيجيتك سراً
