Deflate Edilmiş Sharpe Oranı: Backtest 'Kazananlarınızın' Kaçı Çoklu Teste Dayanıyor?
"Yanılsamasız Backtestler" serisinin bir parçası.
📄 Bu makale bir araştırma makalesine dönüştü. Aşağıdaki her sayı, kontrollü bir referans gerçeklik kuran — saf-gürültü aramaları, yerleştirilmiş-avantaj aramaları ve gerçek bir korelasyonlu parametre ızgarası — ve ardından bunlara karşı Deflate Edilmiş Sharpe Oranı'nı, Harvey-Liu çoklu-test kesintisini ve White'ın Reality Check'ini / Hansen'ın SPA'sını çalıştırarak her yöntemin yanlış-keşif oranını ve tespit gücünü doğrudan ölçen tek bir deterministik betikten geliyor. Makaleyi çevrimiçi olarak (interaktif sürüm + PDF) deflated-sharpe.marketmaker.cc adresinde, kod ve veriyi ise github.com/suenot/deflated-sharpe-search adresinde okuyabilirsiniz.
Bir parametre taraması çalıştırıyorsunuz. On altı hızlı uzunluk, kırk yavaş uzunluk, bir hareketli-ortalama kesişiminin 640 kombinasyonu. Izgara bitiyor ve bir hücre parlıyor: yıllıklandırılmış 3.9 Sharpe, 'lik tek-test p-değeri. On iki sıfırlık anlamlılık. Bir şey buldunuz.
Ya da hiçbir şey bulmadınız ve arama onu sizin için buldu.
Bir parametre araması bir test değildir. N denemenin en şanslısını bulan bir makinedir ve ona ne kadar çok deneme verirseniz, kazananı — altında gerçek bir avantaj olsun ya da olmasın — o kadar şanslı görünür. En-iyi-N-arasından Sharpe, tıpkı bin rastgele insanın en uzununun uzun olması gibi seçilim tarafından şişirilir: uzun boyluluk gerçek olduğu için değil, aradığınız için. Kazananın yanına basılan tek-test istatistikleri — p-değeri, t-istatistiği, "anlamlı mı?" — tek bir önceden-kaydedilmiş hipotez için tasarlanmıştı. Onlara bir aramanın hayatta kalanını besleyin, her seferinde güvenle yalan söylerler.
Bu makale, ne kadar kötü yalan söylediklerini tam olarak ölçüyor ve ardından bunu düzelten üç aracı ölçüyor. Bütün mesele kontrollü referans gerçeklik: cevabı bildiğimiz getiriler üretiyoruz — bazen sıfır avantajlı saf gürültü, bazen bilinen güçte yerleştirilmiş bir avantaj — böylece "yöntem doğru mu bildi?" bir yargı çağrısı değil, bir gerçek olur. İşte önce manşet. Dürüst cevabın her zaman "hayır, keşif yok" olduğu bilinen-null aramalarda, her testin ne sıklıkla yalan söylediği:
| Test | Bilinen-null aramalarda yanlış keşif oranı | Yargı |
|---|---|---|
| Naif "en iyi Sharpe anlamlı mı?" testi | 1.000 | her seferinde bir keşif işaretliyor |
| Deflate Edilmiş Sharpe Oranı (DSR ≥ 0.95) | 0.001 | kontrollü |
| Harvey-Liu kesintisi — Bonferroni | 0.057 | ~kontrollü |
| Harvey-Liu kesintisi — Holm | 0.057 | ~kontrollü |
| Harvey-Liu kesintisi — BHY | 0.007 | kontrollü |
| White'ın Reality Check'i (bootstrap) | 0.022 | kontrollü |
Arama başına 1,000 strateji, her biri 1,000 gözlem, 2,000 bağımsız null arama, her yerde gerçek Sharpe = 0. Sentetik iid Normal getiriler, seed 0, α = 0.05, yılda 252 periyot. Naif testin yanlış keşif oranı yüksek değil — tam olarak bir.
İlk satırı acıtana kadar okuyun. Saf gürültüde zamanın %5'inde ateşlemesi gereken bir test, zamanın %100'ünde ateşliyor — çünkü ona saf gürültü göstermiyorsunuz, ona bin saf-gürültü çekilişinin maksimumunu gösteriyorsunuz ve bin yazı-tura atıcısının maksimumu her zaman bir dahi gibi görünür. Diğer her satır, bunu bilen ve buna göre düzelten bir yöntemdir. Makalenin tamamı bu: ilk satırın neden 1.000 olduğu, diğerlerinin neden olmadığı ve iyi yöntemlerin bile dürüst kalmak için ikinci bir düzeltmeye ihtiyaç duyduğu tek yer (son bölüm).
Perde 1 — Tuzak: bir arama hiçlikten Sharpe üretir

Mümkün olan en temiz tuzakla başlayın. Getirileri bağımsız standart-Normal gürültü olan strateji üretin — sürüklenme yok, beceri yok, hepsi için gerçek Sharpe tam olarak sıfır. Her birinin gözlemi var. Şimdi her parametre aramasının yaptığını yapın: en iyisini tutun.
1000'in en iyisinin gözlem başına Sharpe'ı ortalama 0.1027 çıkar, bu da yıllıklandırıldığında 1.63 olur (türetilmiş: ). Bu mütevazı bir sayı değil. Yıllıklandırılmış 1.63 Sharpe, bir stratejiye fon sağlanmasına, yazılıp yayınlanmasına, tahsis yapılmasına neden olacak türden bir sonuçtur. Bu sayı, sürüklenmesi sıfıra ayarlanmış bir rastgele sayı üretecinden geldi.
Şimdi kazananı naif anlamlılık testine teslim edin — her backtest kütüphanesinin bedavaya bastığı test. Sharpe'ını bir t-istatistiğine dönüştürün (), tek taraflı p-değerini alın, ise buna keşif deyin:
Bu gürültü kazananlarının medyan tek-test p-değeri 0.000686 — avantajı olmayan bir stratejiden gelen üç sıfırlık bir "anlamlılık". Ve 2,000 bağımsız null arama boyunca, naif test her birinde bir keşif ilan ediyor: 1.000'lik bir yanlış keşif oranı. "Şişirilmiş" değil. "Biraz yüksek" değil. Kurgusu gereği tek bir null hipotezde en fazla %5 oranında haklı olan bir test, bir aramanın kazananında %100 oranında yanılıyor.
Mekanizma, bir kez adlandırıldığında pek de ince değil. Naif test şunu sorar: "bu Sharpe, null altında şans eseri ortaya çıkabilir miydi?" — veriye bakmadan önce seçtiğiniz bir strateji için adil bir soru. Ama siz bu stratejiyi bin tanenin en yüksek Sharpe'ına sahip olduğu için seçtiniz. Maksimum üzerinde koşullandınız ve bir maksimumun örnekleme dağılımı, tek bir çekilişin örnekleme dağılımına hiç benzemez. Bu, look-ahead bias taksonomisi makalemizin diğer uçtan teşhis ettiği aynı hastalık — orada, tek barlık bir sızıntı gürültüden 15'lik bir Sharpe üretiyordu; burada, hiçbir sızıntı olmadan, tamamen seçilim yoluyla bir arama gürültüden 1.63'lük bir Sharpe üretiyor. Farklı mekanizma, aynı belirti: hiçbir anlama gelmeyen, harika görünen bir Sharpe.
Önemli olan sayı 1.63, onu aklınızda tutun. Bu arama için gürültü tavanı: 1,000 sıfır-avantajlı stratejinin en şanslısının kaydetmesini beklemeniz gereken Sharpe. Bir arama kazananının dürüst herhangi bir testi, onu sıfıra karşı değil, buna karşı — bin kez baktığınızda yalnızca şansın verdiğine karşı — karşılaştırmalıdır.
Perde 2 — Araç seti: aramayı fiyatlandırmanın üç yolu

Birbirinden bağımsız olarak ortaya çıkan üç araştırma programı, hepsi aynı çözüme varıyor: kazananı sıfırla karşılaştırmayı bırakın, bu boyuttaki bir aramanın şans eseri ürettiğiyle karşılaştırmaya başlayın. Aralarındaki fark, bu karşılaştırmayı nasıl kurduklarında.
PSR ve Deflate Edilmiş Sharpe Oranı (Bailey & López de Prado, 2012 / 2014)
Olasılıksal Sharpe Oranı (PSR), "Sharpe pozitif mi?" sorusundan daha keskin bir soru sorar. Şunu sorar: örneklem uzunluğu ve getirilerin şekli (çarpıklık, kalın kuyruklar) göz önüne alındığında, gerçek Sharpe'ın bir kıstasını aşma olasılığı nedir?
Burada standart-Normal CDF'dir, çarpıklık, ve fazla-olmayan (non-excess) kural içindeki basıklıktır (Normal ⇒ ; buraya 3 eklemeden fazla basıklığı koyarsanız deflasyon yanlış çıkar). ayarlarsanız, PSR sadece sonlu-örneklem bir anlamlılık testi olur. Sihir, 'ı iyi seçmekte yatıyor.
Deflate Edilmiş Sharpe Oranı (DSR), sıfır değil de tüm aramanın beklenen maksimum Sharpe'ı olan bir kıstasta değerlendirilen PSR'dir:
burada , N deneme Sharpe'ının tamamı arasındaki varyanstır (aramanın kendisinin ürettiği dağılım), Euler-Mascheroni sabitidir ve iki ters-Normal terim, standart-Normal çekilişin beklenen maksimumuna Uç Değer Teorisi (Extreme-Value Theory) yaklaşımıdır. Kodda etkileyici sayılamayacak kadar kısa:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
O halde DSR, basitçe bu deflate edilmiş kıstasla PSR'dir:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR bir olasılıktır. olduğunda bir keşif ilan ederiz: kazananın gerçek Sharpe'ı, %95 güvenle şansla-elde-edilebilecek-en-iyiyi geçiyor. 'ın içine gömülü, taşıyıcı varsayıma dikkat edin: deneme bağımsız olarak ele alınır. Perde 5, bunlar bağımsız olmadığında ne olduğuyla ilgili.
Harvey-Liu kesintisi (2015)
Harvey ve Liu aynı probleme çoklu-test p-değeri düzeltmeleri üzerinden saldırır — "M test çalıştırdım, kendimi kandırmama izin verme" için klasik makine. tek-test p-değerini şeklinde sıralayın ve şişirin:
Bonferroni kaba bir alettir (her p-değerini ile çarparak herhangi bir yanlış pozitif olasılığını kontrol eder); Holm ise onun tekdüze-daha-güçlü, kademeli-aşağı kuzenidir. Üçüncüsü, Benjamini-Yekutieli (BHY), yanlış keşif oranını — reddedişlerinizin yanlış olan beklenen kesrini — kontrol eder ve, en önemlisi, bunu testler arasında rastgele bağımlılık altında yapar, pay kısmında harmonik normalize edici kullanarak:
Bu , BHY'nin, 1,000 denemenizin bağımsız olduğunu varsaymamak için ödediği bedeldir — FDR eşiğini gibi büyüyen bir faktörle şişirir. "Kesinti"nin kendisi vurucu metriktir: düzeltilmiş p-değerini tekrar bir Sharpe'a dönüştürün ve orijinal Sharpe'ın ne kadarını kırpmak zorunda kaldığınızı bildirin. %100'lük bir kesinti, kazananın tamamen çoklu test tarafından açıklandığı anlamına gelir; %15 ise çoğunlukla hayatta kaldığı anlamına gelir.
White'ın Reality Check'i ve Hansen'ın SPA'sı (2000 / 2005)
Üçüncü araç hiçbir dağılım varsayımı yapmaz. White'ın Reality Check'i her kuralın gerçek getirilerini alır, kurallar-üzerinden-maksimum istatistiğini oluşturur ve null dağılımını doğrudan bootstrap'lar:
burada , kuralının kıstasa göre ortalama performansıdır. Getirileri durağan bootstrap ile (Politis-Romano — rastgele uzunlukta bloklar, böylece seri korelasyon yeniden örneklemeden sağ çıkar) yeniden örnekler, her çekilişi kurgusu gereği null'u sağlayacak şekilde yeniden merkezler, her çekilişte maksimumu yeniden hesaplar ve p-değerini gözlemlenen değeri geçen bootstrap maksimumlarının kesri olarak bildirir. Hansen'ın SPA'sı RC'yi iki şekilde keskinleştirir: stüdentizasyon (her kuralın ortalamasını kendi standart hatasına böl, böylece yüksek varyanslı vahşi bir kural maksimumu ele geçiremez) ve null'un tutarlı, örnekleme-bağımlı yeniden merkezlenmesi. Bizim uygulamamız stüdentizasyonu ekliyor ama tam tutarlı-yeniden-merkezleme adımını eklemiyor — bu yüzden bu makalenin SPA-tipi bir p-değeri bildirdiği her yerde, bunu tam Hansen SPA'sı değil, stüdentize edilmiş bir Reality Check olarak okuyun. DSR "kazanan bu arama içinde özel mi?" diye sorarken, Reality Check "en iyi kural, kaç kural denediğimi dürüstçe hesaba kattıktan sonra nakiti geçiyor mu?" diye sorar — ve denemeleri hiç saymadan, bootstrap aracılığıyla korelasyonlu kuralları doğal olarak ele alır. Bu ayrımı aklınızda tutun; son bölüm buna dayanıyor.
Perde 3 — Kalibrasyon kanıtın tamamıdır
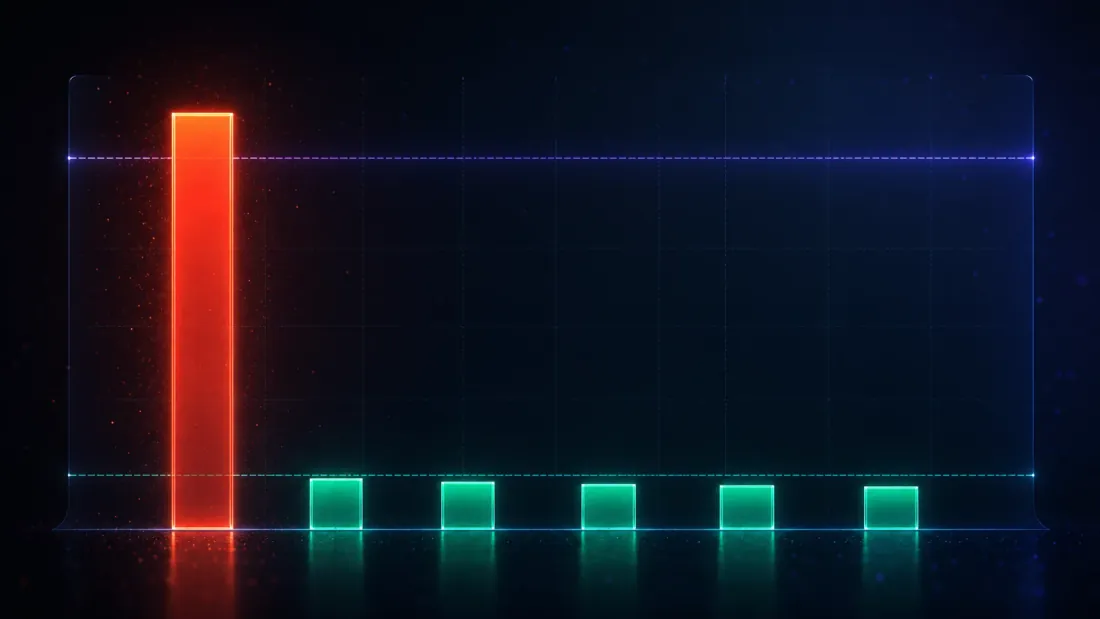
Hiçbir şey işaretlemeyen bir yöntemin de yanlış keşif oranı sıfır olurdu — ve işe yaramaz olurdu. Yani bu araçların tek anlamlı testi iki taraflı bir testtir: bilinen-null veri üzerinde yanlış keşifleri 'da veya altında kontrol etmeliler, ve bilinen-avantaj veri üzerinde (sonraki bölüm) yine de ateşlemeliler. Bu bölüm ilk yarısı.
Her biri 1,000 sıfır-avantajlı strateji üzerinde 2,000 bağımsız arama çalıştırın ve her yöntemin ne sıklıkla bir keşif ilan ettiğini sayın. Bu sayı, 2,000'e bölündüğünde, yanlış keşif oranıdır — ve gerçek avantaj yok olduğundan, her keşif yanlıştır:
| Test | Yanlış keşif oranı (α = 0.05) |
|---|---|
| Naif anlamlılık | 1.000 |
| Deflate Edilmiş Sharpe Oranı | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| White'ın Reality Check'i | 0.022 |
Her ilkeli yöntem %5 çizgisinde ya da yakınında iniyor — iki FWER kesintisi biraz üstünde, DSR/BHY/RC altında — naif test ise 100'de duruyor. (Bonferroni ve Holm burada aynı 0.057'yi basıyor, şans eseri değil: tek en iyi strateji için Holm'ün ilk adımı 'dir, kurgusu gereği Bonferroni ile aynıdır, yani bu iki değil tek bir doğrulamadır.) Ama tüm çalışmadaki en derin sayı bu tabloda değil — DSR sütununu üreten deflate edilmiş kıstas. Null aramalar boyunca ortalandığında, gözlem başına 0.1030 çıkıyor, bu da yıllıklandırıldığında 1.63 oluyor (türetilmiş: ) — ortalama gürültü kazananının kaydettiği aynı 1.63 (1.63). Bu bir tesadüf değil; fikrin tamamının işleyişi bu:
Deflate edilmiş çubuk tam olarak gürültü tavanında oturuyor. DSR bir arama kazananından sıfırı geçmesini istemez. Kazanandan, yalnızca şansın bu boyuttaki bir aramadan ürettiği en iyi skoru geçmesini ister — burada yıllıklandırılmış 1.63. Yalnızca gürültü tavanını tutturan bir kazanan DSR ≈ 0.5 alır (yazı-tura), bu yüzden ortalama null DSR küçük bir şey değil, 0.495'tir. Bir keşif olmak için, kazanan 1.63'ü ve fazlasını geçmelidir — PSR'ı 0.95'in ötesine itmeye yetecek kadar.
Bu, tüm egzersizi yeniden çerçeveler. Naif test sıfırdan uzaklığı ölçer; her arama bu çubuğu önemsizce geçer, bu yüzden işe yaramazdır. DSR gürültü tavanından uzaklığı ölçer ve bu çubuğu geçmek gerçekten zordur — olması gerektiği gibi. Harvey-Liu kesintisi ve Reality Check, farklı yollardan aynı kontrole ulaşır (BHY için şişirmesi, RC için bir bootstrap maksimum-dağılımı) ve aynı mahallede iniyorlar: 0.001'den 0.057'ye, 'da veya yakınında. Bonferroni/Holm'ün 0.057'si %5 çizgisinin biraz üzerinde, ama sadece biraz: 2,000 Monte-Carlo arama ile 0.05 yakınındaki bir FDR tahmininin standart hatası yaklaşık 0.005'tir, yani 0.057, 'nın yaklaşık 1.4 standart hata üzerinde duruyor — bozuk bir garanti değil, Monte-Carlo gürültüsü. "FWER'ı kontrol eder" zaten 'de bit-tam değil, asimptotik bir vaattir.
Perde 4 — Güç: gerçek avantajları hâlâ koruyor mu?
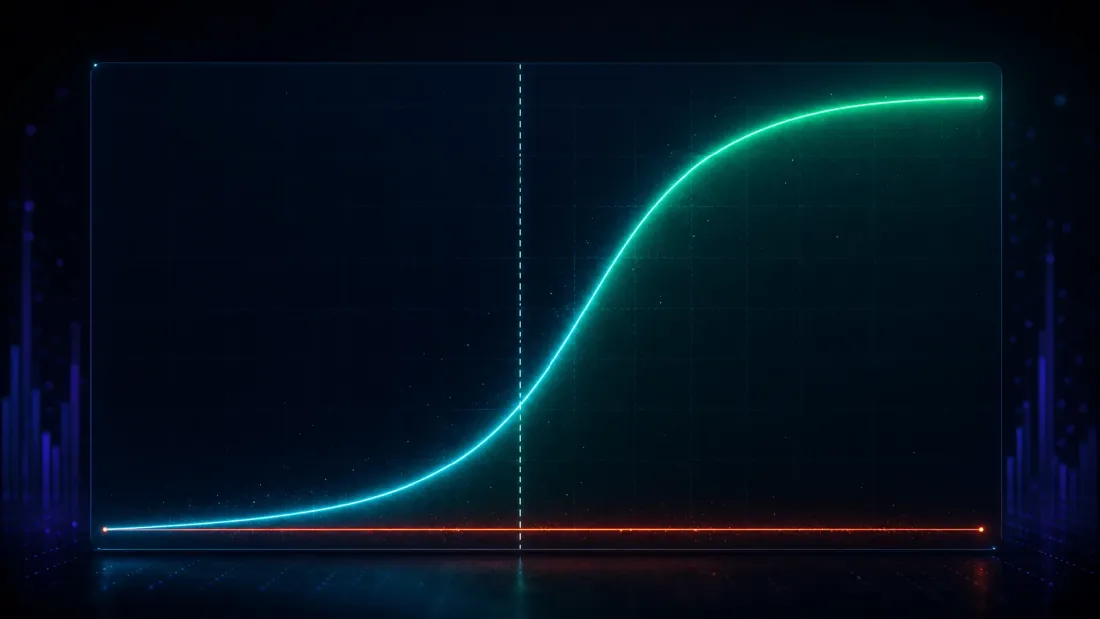
Yanlış keşifleri kontrol etmek testin yalnızca yarısıdır — her şeyi reddeden paranoyak bir yöntem kusursuz bir 0.000 alır ve değersizdir. Diğer yarısı: gerçek bir avantaj varsa, DSR onu buluyor mu?
Bir tane yerleştirin. 1,000 stratejilik bir alanda, 25 tanesinin bilinen güçte gerçek bir avantaj taşımasını sağlayın ve geri kalanını gürültü olarak bırakın, ardından aramayı çalıştırın ve DSR'nin kazananı işaretleyip işaretlemediğini sorun. Yerleştirilen avantajı zayıftan güçlüye tarayın ve tespit gücü temiz bir S-eğrisi çizer (yanlış-pozitif oranı boyunca ~0'da tutulur):
| Yerleştirilen gerçek Sharpe (yıllıklandırılmış) | DSR tespit gücü | DSR yanlış-pozitif oranı |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
Eğrinin nerede döndüğüne bakın. Gürültü tavanının altında — 1.63'ün çok altında, yıllıklandırılmış 0.79'luk gerçek bir Sharpe — DSR zamanın %0.5'inde ateşliyor, bunu doğru bir şekilde reddederek: bu kadar zayıf bir avantaj, 1,000 denemelik bir aramanın ürettiği şanstan gerçekten ayırt edilemez ve aksini iddia etmek güçlü değil, dürüst olmayan bir şey olurdu. Tavanın hemen etrafında eğri dik biçimde yükseliyor (1.27'de 0.09, 1.90'da 0.65). Yıllıklandırılmış 2.54 Sharpe'a gelindiğinde güç 0.998; 3.17'de ise kusursuz bir 1.000. Güçlü avantajlar hemen her seferinde korunuyor, yanlış pozitifler sıfıra sabitli kalıyor ve %50-güç geçiş noktası yaklaşık yıllıklandırılmış 1.73 Sharpe'ta oturuyor (1.27 ve 1.90 satırları arasında enterpolasyonla türetilmiş) — 1.63 gürültü tavanının hemen üzerinde, dürüst bir çubuğun tam olarak koyması gereken yerde: bir avantajın, 1,000 denemelik bir aramanın icat ettiğini geride bırakmaya başladığı nokta.
Aslında istediğiniz özellik bu, bir S-eğrisi olarak ifade edilirse: gürültü tavanının altındaki avantajlar doğru şekilde şans olarak elenir; rahatça üzerindeki avantajlar bire yaklaşan bir güçle korunur. Buna karşın naif test, 0.79'luk gerçek bir Sharpe'ta bile yerleştirilen avantajı zamanın %67'sinde "tespit ediyor" — ama bu sayı anlamsız, çünkü zaten var olmayan bir avantajı zamanın %100'ünde tespit ettiğini gördük. Her şeyde ateşleyen bir testin gücü yoktur; ayırt ediciliği yoktur. DSR, önemli olan şey için sınırdaki avantajlara (0.79 ve 1.27 satırları) karşı biraz duyarlılıktan vazgeçer: keşifleri gerçektir.
Perde 5 — Uygulayıcının tuzağı: korelasyonlu ızgaralar
Şimdiye kadar her şey bağımsız stratejiler kullandı — mümkün olan en temiz kurgu ve DSR'nin bağımsızlık varsayımının tam olarak geçerli olduğu kurgu. Gerçek parametre ızgaraları böyle değildir ve naif kullanılan bir aracın yeni bir yanılma yolu haline geldiği yer burasıdır.
Dürüst bir hareketli-ortalama kesişim araması alın: 16 hızlı uzunluk 40 yavaş uzunluk deneme, her biri 755 gözlem. Böyle bir ızgara korelasyona batmış durumdadır — fast=45/slow=120 ve fast=45/slow=125 neredeyse aynı stratejidir, bu yüzden getiri akışları birlikte hareket eder. 640 deneme boyunca ölçülen ortalama ikili korelasyon: yaklaşık 0.61. Bunlar 640 bağımsız bahis değil. Hiç değil.
Durum A — rastgele yürüyüş (avantaj yok): her yöntem onu doğru şekilde öldürür
Izgarayı saf bir rastgele yürüyüş üzerinde çalıştırın. Kazanan ayartıcı görünüyor: parametreler fast=45/slow=120, en iyi yıllıklandırılmış Sharpe 0.81, tek-test p-değeri 0.081. Her yöntem bunun içini görüyor:
| Yöntem | Sonuç | Yargı |
|---|---|---|
| DSR (ham K = 640) | 0.431 | reddet (< 0.95) |
| Reality Check p | 0.570 | reddet |
| SPA-tipi p (stüdentize edilmiş RC) | 0.569 | reddet |
| Harvey-Liu kesintisi | %100 | reddet |
Hiç deflasyon gerektirmeyen ipucuyla başlayın: bu kazananın düzeltilmemiş sonlu-örneklem anlamlılığı bile, -sıfıra-karşı, sadece 0.918 — 640 denemenin tek birini bile düzeltmeden önce zaten 0.95'in altında. Deflasyon ise bunu gömer: çubuk, gözlem başına , yıllıklandırılmış ~0.91 (türetilmiş: ) — kazananın 0.81'inin üzerinde. En iyi strateji gürültü tavanına bile ulaşmıyor, DSR ≈ 0.43 (yazı-turadan daha kötü), ve Reality Check, SPA-tipi test ve %100'lük bir kesinti hepsi aynı fikirde: burada hiçbir şey yok. Kusursuz. Bu kolay durum ve işe yarıyor — ve göreceğimiz gibi, denediğimiz her etkin-deneme sayısında reddedilmiş kalıyor.
Durum B — gerçek bir rejim avantajı: ham DSR bunu yanlış alır
Şimdi aynı ızgarayı gerçek, kullanılabilir bir avantaj taşıyan bir rejim-değişimi serisi üzerinde çalıştırın. Kazanan kesin: parametreler fast=3/slow=55, en iyi yıllıklandırılmış Sharpe 3.92 — bu örnek-içi, seçilmiş Sharpe'tır, aramanın kendisi tarafından seçilim-şişirilmiş (gerçek ya da örnek-dışı bir avantaj değil), ama altta yatan rejim etkisi gerçek — 'lik bir tek-test p-değeri ve esasen 1.000 olan deflate edilmemiş -sıfıra-karşı anlamlılığıyla. Burada gerçek bir avantaj var ve kazanan onu buldu. Ham DSR'nin yine de onu reddetmesini izleyin:
| Yöntem | Sonuç | Yargı |
|---|---|---|
| DSR (ham K = 640) | 0.748 | reddet (< 0.95) ✗ aşırı-deflate edilmiş |
| Reality Check p | 0.0024 | doğrula ✓ |
| SPA-tipi p (stüdentize edilmiş RC) | 0.0038 | doğrula ✓ |
| Harvey-Liu kesintisi | %15 | doğrula ✓ |
0.748'lik ham DSR, gerçek bir avantajın yanlış reddidir. Sebep, şimdi ağır biçimde ihlal edilen bağımsızlık varsayımıdır: DSR, deflate edilmiş çubuğunu 640 korelasyonlu denemeyi 640 bağımsız çekiliş gibi ele alarak kurdu, bu da beklenen-maksimum 'ı gözlem başına 0.221'e — yıllıklandırılmış ~3.51'e (türetilmiş: ) — şişiriyor. 3.51'lik bir çubuğa karşı, 3.92'lik bir kazanan onu ancak ölçülü biçimde geçiyor ve DSR 0.748'de kalıyor — 0.95'in altında. Bu çubuğu iki şey şişiriyor: ham sayım (bir avuç etkin olan yerine 640 bakış), ve denemeler arasındaki gerçek beceri dağılımı — bazı parametre çiftleri bir rejim serisinde gerçekten daha iyidir, bu da 'i genişletir ve 'ı yalnızca saf şansın kaldıracağından daha da yükseltir. İkisi de aynı yönde itiyor ve çubuk sonunda çok yüksek çıkıyor çünkü arama hiçbir zaman gerçekten 640 bağımsız bakış değildi; birkaç bağımsız bahisin 640 kez örneklenmesiydi.
Bunun yerine DSR'ye etkin deneme sayısını verin. Yukarıda kullanılan tek satırlık formül, ortalama ikili korelasyondan yapılan kaba bir tahmindir:
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
ve ile, bu ızgarayı etkin denemeye çöktürür (türetilmiş: ) ve DSR 1.000'e sıçrar. Ama bu sayıyı kutlamadan önce durun, çünkü bu tüm bölümdeki en zayıf kanıt. 'da deflate edilmiş çubuk, yıllıklandırılmış 'e çöker — esasen deneme ortalaması, esasen sıfır. Deflasyon orada kapatılmıştır: 'daki DSR, kazananın deflate edilmemiş sonlu-örneklem anlamlılığını (-sıfıra-karşı ) yeniden bildirmekten ibarettir. Yargı, çoklu-test düzeltmesi tarafından üretilmiyor, ham anlamlılıktan devralınıyor. Ve rastgele-yürüyüş tarafındaki ayna-görüntüsü uyarısı: onun 'daki reddi yalnızca o kazananın başından beri bağımsız olarak sınırda olması (-sıfıra-karşı ) sayesinde geçerlidir. Tüm argümanı 1.6'ya bağlayın ve bir şüpheci omuz silkmekte haklı olur: düzeltmeyi kapattınız ve altında ne varsa onu bildirdiniz.
Öyleyse tek bir tahminciye bağlanmayın. Dürüst hamle — ve daha güçlü olanı — 'i beş farklı standart yolla hesaplamak ve yargıyı tüm bant boyunca okumaktır. İşte aynı 640-denemelik sinyal ızgarasına uygulanan beş tahminci, her biri ima ettiği deflate edilmiş çubuk ve ürettiği DSR ile:
| Etkin-deneme tahmincisi | Deflate edilmiş çubuk (yıllık) | DSR | Yargı | |
|---|---|---|---|---|
| Ortalama korelasyon | 1.6 | 0.25 | 1.000 | koru |
| Katılım oranı | 2.4 | 0.43 | 1.000 | koru |
| PCA (varyansın %95'i) | 16 | 1.85 | 1.000 | koru |
| Kaiser (özdeğerler > 1) | 21 | 2.00 | 0.999 | koru |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | reddet |
| ham ızgara sayımı (düzeltmesiz) | 640 | 3.51 | 0.748 | reddet |
Tahminciler: ortalama korelasyon, yukarıdaki tek-satırlık formülüdür; katılım oranı ve PCA-%95/Kaiser sayımları etkin boyutsallığı korelasyon matrisinin özdeğerlerinden okur; Cheverud-Nyholt, neredeyse-eş-korelasyon altında fazla saydığı bilinen, genetik literatüründen bir özdeğer-varyansı tahmincisidir.
Şimdi mesele oturuyor ve bu "herhangi bir düzeltme sizi kurtarır" değil. Savunulabilir ortaya bakın — PCA-%95 () ve Kaiser (). Bunlar deflasyonun-kapalı-olduğu rejim değil; 1.85'ten 2.00'a kadar gerçek bir yıllıklandırılmış çubuğu dayatıyorlar — gürültünün oldukça üzerinde, ciddi bir kesinti, 16-21 etkin bakış için gerçek bir çoklu-test cezası. Ve 3.92'lik avantaj hâlâ bunu geçiyor (DSR 1.000 ve 0.999). Sinyal, 144.8'in (kesişim noktasından türetilmiş) altındaki her için DSR'de hayatta kalıyor; yalnızca denemeler neredeyse-eş-korelasyonlu olduğunda kanıtlanabilir biçimde fazla sayan bir tahminci olan Cheverud-Nyholt'ün 'i altında başarısız oluyor — ve hatta 640'ın ham, düzeltilmemiş sayımı bile DSR'yi yalnızca 0.748'e indiriyor, sıfıra değil. Aynı beş tahminciden geçirilen rastgele-yürüyüş kazananı ise her birinde reddediliyor (1'in üzerinde hiçbir için hayatta kalmıyor). Gerçek sonuç bu: tek bir şanslı sayı değil, standart etkin-deneme tahmincilerinin tüm bandı boyunca kararlı bir yargı — bu, bunlardan herhangi birine güvenmekten çok daha güçlü bir kanıt.
En kaba tahminci üzerine teknik bir uyarı, çünkü bu, onun neden yumuşak uçta oturduğunu açıklıyor: aslında korelasyonlu değişkenlerin ortalaması için varyans-azaltma faktörüdür ( korelasyonu altında ortalama almanın size ne kazandırdığı). DSR'nin kıstası bir uç-değer niceliğidir — denemelerin beklenen maksimumu — bu yüzden deneme sayısı olarak bir ortalama-varyans küçültmesi kullanmak işlevsel bir uyumsuzluktur: yönü doğru (korelasyonlu ⇒ daha az etkin deneme), ama maksimumun dağılımının gerçekten bağlı olduğu nicelik değil. Bandın ortasındaki özdeğer-tabanlı tahmincilerin daha güvenilir bir okuma olmasının ve teslim edilecek şeyin nokta değil bant olmasının tam sebebi bu.
Ders: her iki aracı da kullanın ve DSR'ye doğru N'i verin

Durum B'den iki şey çıkıyor ve ikisi de taşıyıcı:
- Denemeler korelasyonlu olduğunda ham ızgara boyutu DSR için yanlış N'dir — ve tek bir etkin-N de doğrusu değildir. 640'ı bağımsızlığı varsayan bir formüle sokmak aşırı-deflasyona yol açar: aramanın gerçekte ulaştığından çok daha yüksek bir gürültü tavanı üretir ve gerçek avantajları altında gömer. DSR'nin etkin deneme sayısına ihtiyacı var — ama çözüm tek bir tahminciye güvenmek değildir (en azından düzeltmenin yakınında kapandığı en kaba olanına). Çözüm, yargıyı standart tahmincilerin tüm bandı boyunca (burada 1.6'dan 370'e) okumak ve kararlı olup olmadığına bakmaktır. Bu avantaj için öyleydi: deflasyonun gerçekten etkin olduğu her yerde korundu (-'de gerçek bir 1.85-2.00 yıllık çubuk), yalnızca fazla sayan bir tahminci altında başarısız oldu. Bant boyunca kararlı bir yargı, tek bir sayıdan çok daha güçlüdür.
- DSR'yi bir Reality Check ile eşleştirin. Reality Check'in ve SPA-tipi (stüdentize edilmiş) kuzeninin, Durum B'yi hiçbir deneme-sayısı ameliyatı olmadan doğru aldığını (p = 0.0024 ve 0.0038) fark edin — bağımlılığı, durağan bootstrap aracılığıyla, doğal olarak ele alırlar, çünkü varsayımsal bağımsız bahisleri saymak yerine gerçek korelasyonlu getiri akışlarını yeniden örneklerler. Tüm etkin-N karmaşasının karar belirleyicisi bu: RC'nin 'e ihtiyacı yok. DSR ve RC farklı sorulara cevap verir: DSR "kazanan bu arama içinde özel mi?" diye sorar (ve aramanın kaç etkin bakış aldığını bilmesi gerekir); RC/SPA-tipi "en iyi kural veri-kurcalamadan sonra nakiti geçiyor mu?" diye sorar (ve bağımlılığı verinin kendisinden okur). İkisini de istersiniz. Aralarında anlaşmazlık olduğunda — burada ham-sayım DSR ve RC'nin yaptığı gibi — bu anlaşmazlık teşhis edicidir: genellikle 'inizin yanlış olduğu anlamına gelir.
Bu, hız-merdiveni ve IPC-vergisi çalışmalarımızın mühendislik tarafından sürekli çarptığı aynı yapısal uyarı — devasa korelasyonlu bir ızgarayı çalıştıran hızlı bir arama, size çok sayıda bağımsız bahis satın almaz ve ızgara boyutunu deneme sayısı olarak ele almak hem optimize edicinizi hem de anlamlılık testinizi kandırır. Backtest aşırı uyumunun olasılığı üzerine yakında gelecek olan tamamlayıcı makale, aynı seçilim yanlılığına yeniden-örnekleme tarafından (CSCV) saldırır ve buradaki her şeyle doğal olarak eşleşir: DSR kazananı fiyatlandırır, PBO süreci fiyatlandırır.
Dürüstlük notları
Üç uyarı, açıkça ifade edilmiş, çünkü kontrollü bir çalışmanın tüm amacı onu fazla pazarlamamaktır.
- Getiriler sentetiktir. Kalibrasyon ve güç deneyleri için iid Normal, gerçek-avantaj durumu için bir rejim-değişimi süreci — piyasa gerçekçiliği için değil, kontrollü bir referans gerçeklik için seçildi. Gerçek getiriler kalın kuyrukludur, otokorelasyonludur ve durağan değildir, ve PSR'nin çarpıklık/basıklık terimleri tam olarak bunlardan ilkini ele almak için vardır. Buradaki teslim edilecek şey kalibre edilmiş yöntemdir, bir strateji değil: bir testin yanlış keşifleri kontrol ettiğini yalnızca, keşfedilecek hiçbir şey olmadığını bildiğimiz veri üzerinde çalıştırarak kanıtlayabiliriz. Bu da referans gerçekliği üretmeyi gerektirir.
- Hiçbir etkin-N tahmincisi kanonik değildir — bu yüzden beşini de bildirdik. Ortalama-korelasyon tek-satırlığı , hakem tarafından okunabilir ve yön olarak doğrudur (daha fazla korelasyon ⇒ daha az etkin deneme), ama bu bir ortalama için varyans-azaltma faktörüdür — DSR'nin maksimum kıstasıyla işlevsel bir uyumsuzluk — ve yakınında deflasyonu tamamen kapatır. Özdeğer tahmincileri (katılım oranı, PCA-%95, Kaiser) daha iyi eşleşir ama yine de sezgiseldir, ve Cheverud-Nyholt eş-korelasyon altında fazla sayar. Daha eksiksiz, ilkeli yaklaşım deneme kümelemesidir (Bailey & López de Prado'nun DSR Ek 3'ü): her şeyi tek bir skalere çökertmek yerine, denemeleri korelasyon yapısına göre gruplayın ve kümeleri sayın. Tüm bandı tam olarak seçimin kesinleşmemiş olması nedeniyle bildiriyoruz — beş tahmincinin hepsinde kararlı bir yargı dürüst bir iddiadır; tek bir tahminci seçmeye bağlı olan bir yargı öyle olmazdı.
- Bootstrap, tam Hansen SPA'sı değil, stüdentize edilmiş bir Reality Check'tir ve yeniden-örnekleme sayıları deneye göre değişir. Bu makalenin "SPA-tipi" dediği her yerde, kural-başına stüdentizasyonlu White'ın Reality Check'i kastedilir; Hansen'ın tam tutarlı, örnekleme-bağımlı yeniden-merkezlemesi uygulanmamıştır. Kalibrasyon yanlış keşif oranları, 400 arama boyunca arama başına 500 durağan-bootstrap yeniden örneklemesi kullanır; iki vaka-çalışması RC/SPA-tipi p-değeri her biri 5,000 yeniden örnekleme kullanır. Boyunca ortalama blok uzunluğu 20'dir (Politis-Romano), , yıllıklandırma için yılda 252 periyot. Bunları değiştirin ve üçüncü ondalık basamaktaki sayılar kayar; hikaye — ilkeli 0.001-0.057'ye karşı naif 1.000, gürültü tavanının hemen üzerinde %50 güce ulaşan bir S-eğrisi ve yargısı etkin-N bandı boyunca okunması gereken korelasyonlu-ızgara tuzağı — kaymaz.
Çıkarımlar
- Bir parametre araması bir çoklu-test makinesidir ve naif anlamlılık testi buna karşı kördür. 1,000 sıfır-avantajlı stratejide en iyi yıllıklandırılmış Sharpe ortalama 1.63 çıkıyor, medyan tek-test p-değeri 0.000686 ile — ve "anlamlı mı?" testi zamanın %100'ünde bir keşif ilan ediyor (yanlış keşif oranı 1.000). Hiçlikten gelen harika bir Sharpe, hiçbir zaman doğru soruyu sormamış bir test tarafından anlamlı olarak onaylanmış.
- Deflate Edilmiş Sharpe Oranı, kaleyi sıfırdan gürültü tavanına taşır. DSR, kazananı sıfıra karşı değil, bu boyuttaki bir aramanın şansla-elde-edilebilecek-en-iyisi olan 'a karşı karşılaştırır — null durum için bu, ortalama gürültü kazananının tam olarak oturduğu yerde, yıllıklandırılmış 1.63'te iner (türetilmiş: ). Null yanlış keşif oranı 0.001'dir; Harvey-Liu kesintisi (Bonferroni/Holm 0.057, BHY 0.007) ve White'ın Reality Check'i (0.022) başka yollardan aynı kontrole ulaşır.
- Gerçek avantajları korur. DSR'nin tespit gücü, yıllıklandırılmış ~1.73 Sharpe'ta — 1.63 gürültü tavanının hemen üzerinde — %50 güce ulaşan bir S-eğrisi çiziyor: yıllıklandırılmış gerçek Sharpe 0.79'da 0.005, 1.90'da 0.651, 2.54'te 0.998, 3.17'de 1.000, boyunca yanlış pozitifler ~0. Tavanın altındaki avantajlar doğru şekilde şanstan ayırt edilemez sayılır; üzerindeki avantajlar bire yaklaşan bir güçle korunur.
- Korelasyonlu ızgaralar ham DSR'yi bozar — ve tek bir etkin-N onu kurtarmaz; bant kurtarır. 640-hücreli bir MA kesişiminde (ortalama ikili korelasyon ~0.61), ham-sayım DSR, gerçek (örnek-içi seçilmiş, yıllık 3.92) bir avantajı yanlışlıkla reddetti (0.748 < 0.95), çünkü 640 korelasyonlu deneme 640 bağımsız bahis değildir. Ama çözüm tek bir sihirli değildir — en kaba tahminde () deflasyon esasen kapalıdır (çubuk ~yıllık 0.25) ve DSR yalnızca ham anlamlılığı yankılar. Gerçek kanıt, avantajın standart tahmincilerin tüm bandı boyunca korunmasıdır — savunulabilir PCA-%95/Kaiser orta-aralığındaki gerçek 1.85-2.00 yıllık çubuk dahil, 1.6/2.4/16/21'de DSR 1.000/1.000/1.000/0.999 — herhangi bir için hayatta kalıyor ve yalnızca Cheverud-Nyholt'ün fazla sayan 370'i altında başarısız oluyor. Rastgele yürüyüş ise her tahminci altında reddediliyor. Bir noktayı değil, bandı okuyun.
- DSR'yi bir Reality Check ile eşleştirin, çünkü farklı sorulara cevap veriyorlar. Reality Check ve SPA-tipi (stüdentize edilmiş) kuzeni, gerçek avantajı hiçbir deneme-sayısı ameliyatı olmadan doğruladı (p = 0.0024 ve 0.0038) — bağımlılığı durağan bootstrap aracılığıyla doğal olarak ele alırlar, ki bu tam olarak etkin-N tartışmalı olduğunda karar belirleyicidir. DSR "kazanan bu arama içinde özel mi?" diye sorar; RC/SPA-tipi "en iyisi veri-kurcalamadan sonra nakiti geçiyor mu?" diye sorar. Aralarındaki bir anlaşmazlık, 'inizin yanlış olduğunun bir işaretidir. İkisini de çalıştırın.
Bir aramanın kazananı, suçsuzluğu kanıtlanana kadar suçludur. Naif p-değeri suçsuzluğun kanıtı değildir — aramanın kendi şişirilmiş tanıklığıdır ve saf gürültüye on iki sıfırlık güvenle kefil olacaktır. Kıstası şansın verdiğine göre deflate edin, etkin denemelerinizi dürüstçe sayın ve ikinci bir görüş için maksimumu bootstrap'layın. Her üç çubuğu da geçen şey gerçekten gerçek olabilir. Yalnızca naif olanı geçen şey, bin yazı-tura atıcısının en uzun boylusudur.
Tam deney — null-kalibrasyon aracı, yerleştirilmiş-avantaj güç taraması, korelasyonlu-ızgara aramaları ve bu makaledeki her sayının tek bir deterministik betikten yeniden üretilebilmesi — deflated-sharpe.marketmaker.cc adresindeki tamamlayıcı makalede, kod ve veri ise github.com/suenot/deflated-sharpe-search adresinde.
Yazarlar

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Daha Fazla Oku

Backtest Aşırı Uyum Olasılığı: Aramanız Yazı Turayı Yendi mi?

Objektif Fonksiyon Tasarımı: Optimize Ettiğiniz Metrik Stratejinizi Gizlice Seçer
