Deflated Sharpe Ratio: Berapa Banyak 'Pemenang' Backtest Anda yang Selamat dari Multiple Testing?
Bagian dari seri "Backtests Without Illusions".
📄 Artikel ini berkembang menjadi paper riset. Setiap angka di bawah berasal dari satu skrip deterministik yang membangun ground truth terkontrol — pencarian noise murni, pencarian dengan edge yang ditanam, dan grid parameter berkorelasi nyata — lalu menjalankan Deflated Sharpe Ratio, haircut multiple-testing Harvey-Liu, dan Reality Check milik White / SPA milik Hansen terhadapnya, mengukur langsung false-discovery rate dan detection power setiap metode. Baca paper-nya online (versi interaktif + PDF) di deflated-sharpe.marketmaker.cc, kode dan data di github.com/suenot/deflated-sharpe-search.
Anda menjalankan parameter sweep. Enam belas fast length, empat puluh slow length, 640 kombinasi moving-average crossover. Grid selesai dan satu sel berpendar: Sharpe tahunan 3.9, p-value single-test sebesar . Dua belas angka nol signifikansi. Anda telah menemukan sesuatu.
Atau Anda tidak menemukan apa-apa, dan pencarian itu yang menemukannya untuk Anda.
Parameter search bukanlah uji. Ia adalah mesin untuk menemukan yang paling beruntung dari N percobaan, dan semakin banyak percobaan yang Anda berikan, semakin beruntung tampaknya pemenangnya — entah ada edge nyata di baliknya atau tidak. Sharpe best-of-N digelembungkan oleh seleksi dengan cara yang sama seperti orang tertinggi dari seribu orang acak itu tinggi: bukan karena ketinggian itu nyata, melainkan karena Anda mencarinya. Statistik single-test yang dicetak di sebelah pemenang — p-value-nya, t-stat-nya, "apakah ini signifikan?"-nya — dirancang untuk satu hipotesis yang telah didaftarkan sebelumnya (pre-registered). Berikan itu kepada yang selamat dari sebuah pencarian, dan ia akan berbohong, dengan percaya diri, setiap saat.
Artikel ini mengukur tepatnya seberapa parah kebohongan itu, lalu mengukur tiga alat yang memperbaikinya. Inti dari semuanya adalah ground truth terkontrol: kami menghasilkan return di mana kami tahu jawabannya — kadang noise murni dengan edge nol, kadang edge yang ditanam dengan kekuatan yang diketahui — sehingga "apakah metode ini benar?" menjadi fakta, bukan penilaian subjektif. Berikut ini headline-nya di depan. Pada pencarian known-null, di mana jawaban jujurnya selalu "tidak ada penemuan," beginilah seringnya setiap uji berteriak serigala (berteriak palsu):
| Uji | False-discovery rate pada pencarian known-null | Vonis |
|---|---|---|
| Naif "apakah Sharpe terbaik signifikan?" | 1.000 | menandai penemuan setiap saat, tanpa kecuali |
| Deflated Sharpe Ratio (DSR ≥ 0.95) | 0.001 | terkendali |
| Haircut Harvey-Liu — Bonferroni | 0.057 | ~terkendali |
| Haircut Harvey-Liu — Holm | 0.057 | ~terkendali |
| Haircut Harvey-Liu — BHY | 0.007 | terkendali |
| Reality Check milik White (bootstrap) | 0.022 | terkendali |
1,000 strategi per pencarian, 1,000 observasi masing-masing, 2,000 pencarian null independen, Sharpe sejati = 0 di mana-mana. Return Normal iid sintetis, seed 0, α = 0.05, 252 periode/tahun. False-discovery rate uji naif bukan sekadar tinggi — angkanya tepat satu.
Baca baris pertama sampai terasa menyakitkan. Uji yang seharusnya menyala 5% dari waktu pada noise murni, menyala 100% dari waktu — karena Anda tidak menunjukkan kepadanya noise murni, Anda menunjukkan kepadanya maksimum dari seribu tarikan noise murni, dan maksimum dari seribu pelempar koin selalu terlihat seperti jenius. Setiap baris lainnya adalah metode yang menyadari hal ini dan mengoreksinya. Inilah inti seluruh artikel: mengapa baris pertama bernilai 1.000, mengapa yang lain tidak, dan satu tempat (bagian terakhir) di mana bahkan metode-metode yang baik membutuhkan koreksi kedua agar tetap jujur.
Babak 1 — Jebakan: pencarian membuat Sharpe dari ketiadaan

Mulai dengan jebakan paling bersih yang mungkin. Bangkitkan strategi yang return-nya adalah noise standard-Normal independen — tanpa drift, tanpa skill, Sharpe sejati tepat nol untuk semuanya. Masing-masing memiliki observasi. Sekarang lakukan apa yang dilakukan setiap parameter search: simpan yang terbaik.
Sharpe per-observasi best-of-1000 rata-rata 0.1027, yang jika ditahunkan menjadi 1.63 (turunan: ). Itu bukan angka yang sederhana. Sharpe tahunan 1.63 adalah jenis hasil yang membuat sebuah strategi didanai, ditulis dalam laporan, dialokasikan modal. Angka itu berasal dari generator bilangan acak dengan drift yang disetel ke nol.
Sekarang serahkan pemenang itu kepada uji signifikansi naif — yang dicetak gratis oleh setiap library backtest. Konversikan Sharpe-nya menjadi statistik-t (), ambil p-value satu sisi, sebut itu penemuan jika :
Median p-value single-test dari para pemenang noise ini adalah 0.000686 — tiga angka nol "signifikansi" dari strategi tanpa edge sama sekali. Dan di antara 2,000 pencarian null independen, uji naif mendeklarasikan penemuan di setiap satu darinya: false-discovery rate sebesar 1.000. Bukan "terinflasi." Bukan "sedikit tinggi." Uji yang, menurut konstruksinya, benar paling banyak 5% dari waktu pada satu hipotesis null tunggal, ternyata salah 100% dari waktu pada pemenang sebuah pencarian.
Mekanismenya tidak lagi tersembunyi begitu dinamai. Uji naif bertanya, "bisakah Sharpe ini muncul secara kebetulan di bawah null?" — pertanyaan yang adil untuk strategi yang Anda pilih sebelum melihat data. Tetapi Anda memilih strategi ini karena ia memiliki Sharpe tertinggi dari seribu. Anda telah mengondisikan pada maksimum, dan distribusi sampling dari sebuah maksimum sama sekali tidak seperti distribusi sampling dari satu tarikan tunggal. Ini adalah penyakit yang sama yang didiagnosis oleh taksonomi look-ahead bias kami dari ujung yang berbeda — di sana, kebocoran satu bar membuat Sharpe 15 dari noise; di sini, sebuah pencarian membuat Sharpe 1.63 dari noise tanpa kebocoran sama sekali, murni melalui seleksi. Mekanisme berbeda, gejala identik: Sharpe yang tampak hebat namun tak berarti apa-apa.
Angka 1.63 adalah angka yang penting, jadi pegang erat-erat. Itu adalah plafon noise (noise ceiling) untuk pencarian ini: Sharpe yang seharusnya Anda perkirakan akan dicetak oleh strategi paling beruntung dari 1,000 strategi ber-edge nol. Uji jujur mana pun terhadap pemenang sebuah pencarian harus membandingkannya bukan dengan nol, melainkan dengan ini — dengan apa yang dihasilkan keberuntungan semata ketika Anda melihat seribu kali.
Babak 2 — Perangkat: tiga cara memberi harga pada pencarian

Tiga program riset, yang tiba secara independen, semuanya sampai pada perbaikan yang sama: berhenti membandingkan pemenang dengan nol, dan mulai membandingkannya dengan apa yang dihasilkan oleh keberuntungan dari pencarian seukuran ini. Mereka berbeda dalam cara membangun perbandingan tersebut.
PSR dan Deflated Sharpe Ratio (Bailey & López de Prado, 2012 / 2014)
Probabilistic Sharpe Ratio mengajukan pertanyaan yang lebih tajam daripada "apakah Sharpe-nya positif?" Ia bertanya: dengan panjang sampel dan bentuk return tertentu (skew, fat tail), berapa probabilitas Sharpe sejati melampaui benchmark ?
Di sini adalah CDF standard-Normal, adalah skew, dan adalah kurtosis dalam konvensi non-excess (Normal ⇒ ; substitusikan excess kurtosis di sini tanpa menambahkan 3 dan hasil deflasinya akan salah). Setel dan PSR hanyalah uji signifikansi finite-sample biasa. Keajaibannya ada pada memilih dengan baik.
Deflated Sharpe Ratio adalah PSR yang dievaluasi pada benchmark yang bukan nol melainkan ekspektasi Sharpe maksimum dari seluruh pencarian:
di mana adalah varians di seluruh N Sharpe trial (dispersi yang dihasilkan oleh pencarian itu sendiri), adalah konstanta Euler-Mascheroni, dan kedua suku inverse-Normal itu adalah aproksimasi Extreme-Value-Theory terhadap ekspektasi maksimum dari tarikan standard-Normal. Dalam kode, formulanya hampir terlalu singkat untuk terlihat mengesankan:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
Lalu DSR hanyalah PSR dengan batang deflasi tersebut:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR adalah sebuah probabilitas. Kami mendeklarasikan penemuan ketika : Sharpe sejati pemenang mengalahkan ekspektasi terbaik-karena-keberuntungan dengan keyakinan 95%. Perhatikan asumsi krusial (load-bearing) yang tertanam dalam : trial diperlakukan sebagai independen. Babak 5 seluruhnya membahas apa yang terjadi ketika asumsi itu tidak berlaku.
Haircut Harvey-Liu (2015)
Harvey dan Liu menyerang masalah yang sama melalui penyesuaian p-value multiple-testing — mesin klasik untuk "saya menjalankan M uji, jangan biarkan saya menipu diri sendiri." Urutkan p-value single-test dan inflasikan:
Bonferroni adalah instrumen tumpul (mengendalikan probabilitas satu pun false positive dengan mengalikan setiap p-value dengan ); Holm adalah sepupu step-down-nya yang secara seragam lebih powerful. Yang ketiga, Benjamini-Yekutieli (BHY), mengendalikan false-discovery rate — pecahan ekspektasi dari penolakan Anda yang salah — dan, yang krusial, melakukannya di bawah dependensi arbitrer di antara uji-uji tersebut, menggunakan normalizer harmonik pada pembilangnya:
itu adalah harga yang dibebankan BHY karena tidak mengasumsikan 1,000 trial Anda independen — ia menginflasikan ambang FDR dengan faktor yang tumbuh seperti . "Haircut" itu sendiri adalah metrik puncaknya: konversikan p-value yang sudah disesuaikan kembali menjadi Sharpe dan laporkan berapa banyak dari Sharpe asli yang harus dipangkas. Haircut 100% berarti pemenangnya sepenuhnya dijelaskan oleh multiple testing; 15% berarti sebagian besar edge-nya bertahan.
Reality Check milik White dan SPA milik Hansen (2000 / 2005)
Alat ketiga ini tidak membuat asumsi distribusional sama sekali. Reality Check milik White mengambil return aktual dari setiap aturan (rule), membentuk statistik max-over-rules, dan mem-bootstrap distribusi null-nya secara langsung:
di mana adalah performa rata-rata aturan di atas benchmark. Ia me-resample return dengan stationary bootstrap (Politis-Romano — blok berpanjang acak sehingga korelasi serial tetap bertahan melalui proses resampling), me-recenter setiap tarikan agar memenuhi null menurut konstruksinya, menghitung ulang maksimum pada setiap tarikan, dan melaporkan p-value sebagai pecahan dari maksimum bootstrap yang mengalahkan nilai yang teramati. SPA milik Hansen mempertajam RC dengan dua cara: studentisasi (membagi rata-rata setiap aturan dengan standard error-nya sendiri, sehingga satu aturan liar bervarians tinggi tidak bisa membajak maksimum) dan recentering null yang konsisten dan bergantung pada sampel. Implementasi kami menambahkan studentisasi tetapi tidak langkah consistent-recentering penuh — jadi di mana pun artikel ini melaporkan p-value bertipe-SPA, bacalah itu sebagai Reality Check terstudentisasi, bukan SPA Hansen yang lengkap. Di mana DSR bertanya "apakah pemenang ini istimewa di dalam pencarian ini?", Reality Check bertanya "apakah aturan terbaik mengalahkan cash setelah memperhitungkan secara jujur berapa banyak aturan yang saya coba?" — dan ia menangani aturan-aturan berkorelasi secara native, melalui bootstrap, tanpa pernah menghitung jumlah trial. Ingat perbedaan ini; bagian terakhir bergantung padanya.
Babak 3 — Kalibrasi adalah seluruh pembuktian
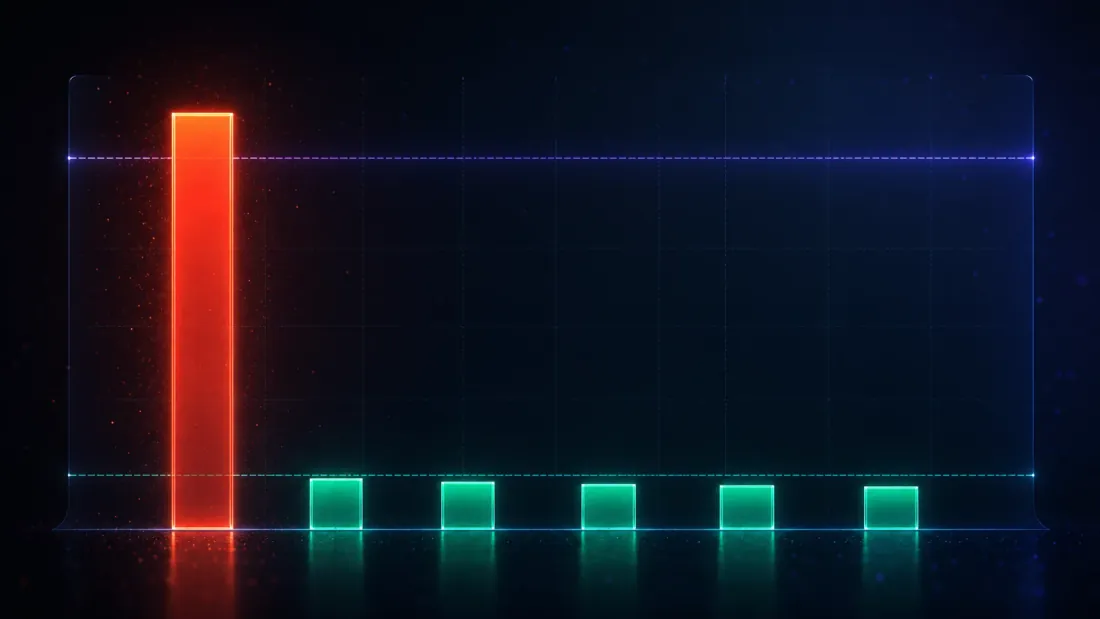
Metode yang tidak pernah menandai apa pun juga akan memiliki false-discovery rate nol — dan menjadi tidak berguna. Jadi satu-satunya uji yang bermakna untuk alat-alat ini bersifat dua sisi: pada data known-null mereka harus mengendalikan penemuan palsu pada atau di bawah , dan pada data known-edge (bagian berikutnya) mereka tetap harus menyala. Bagian ini adalah babak pertama dari dua babak itu.
Jalankan 2,000 pencarian independen, masing-masing atas 1,000 strategi ber-edge nol, dan hitung seberapa sering setiap metode mendeklarasikan penemuan. Hitungan itu, dibagi 2,000, adalah false-discovery rate — dan karena kebenarannya adalah tidak ada edge, setiap penemuan adalah palsu:
| Uji | False-discovery rate (α = 0.05) |
|---|---|
| Signifikansi naif | 1.000 |
| Deflated Sharpe Ratio | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| Reality Check milik White | 0.022 |
Setiap metode yang berprinsip mendarat pada atau dekat garis 5% — kedua haircut FWER sedikit di atasnya, DSR/BHY/RC di bawahnya — sementara uji naif duduk di 100. (Bonferroni dan Holm mencetak angka yang sama 0.057 di sini, dan bukan karena kebetulan: untuk satu-satunya strategi terbaik, langkah pertama Holm adalah , identik dengan Bonferroni menurut konstruksinya, jadi keduanya adalah satu konfirmasi, bukan dua.) Tetapi angka paling mendalam dalam seluruh studi ini tidak ada di tabel ini — melainkan benchmark deflasi yang menghasilkan kolom DSR. Dirata-ratakan di seluruh pencarian null, keluar pada per-observasi 0.1030, yang jika ditahunkan menjadi 1.63 (turunan: ) — angka 1.63 yang sama dengan yang dicetak rata-rata pemenang noise (1.63). Itu bukan kebetulan; itu adalah gagasan intinya yang sedang bekerja:
Batang deflasi terletak tepat di plafon noise. DSR tidak meminta pemenang sebuah pencarian untuk mengalahkan nol. Ia meminta pemenang untuk mengalahkan skor terbaik yang dihasilkan keberuntungan semata dari pencarian seukuran ini — 1.63 tahunan di sini. Pemenang yang sekadar menyamai plafon noise mencetak DSR ≈ 0.5 (lemparan koin), itulah sebabnya DSR null rata-rata adalah 0.495, bukan angka kecil. Untuk menjadi sebuah penemuan, pemenang harus melampaui 1.63 dan lebih lagi — cukup untuk mendorong PSR melewati 0.95.
Ini membingkai ulang seluruh eksperimen. Uji naif mengukur jarak dari nol; setiap pencarian melewati batang itu secara trivial, itulah sebabnya ia tidak berguna. DSR mengukur jarak dari plafon noise, dan melewati batang itu benar-benar sulit — sebagaimana seharusnya. Haircut Harvey-Liu dan Reality Check mencapai kendali yang sama melalui jalan yang berbeda (inflasi untuk BHY, distribusi-maksimum bootstrap untuk RC), dan mendarat di lingkungan yang sama: 0.001 hingga 0.057, pada atau dekat . Angka 0.057 Bonferroni/Holm sedikit di atas garis 5%, tetapi hanya sedikit: dengan 2,000 pencarian Monte-Carlo, standard error pada estimasi FDR dekat 0.05 adalah sekitar 0.005, jadi 0.057 berada kira-kira 1.4 standard error di atas — noise Monte-Carlo, bukan jaminan yang rusak. "Mengendalikan FWER" bagaimanapun juga adalah janji asimtotik, bukan yang tepat-bit pada .
Babak 4 — Power: apakah edge nyata tetap dipertahankan?
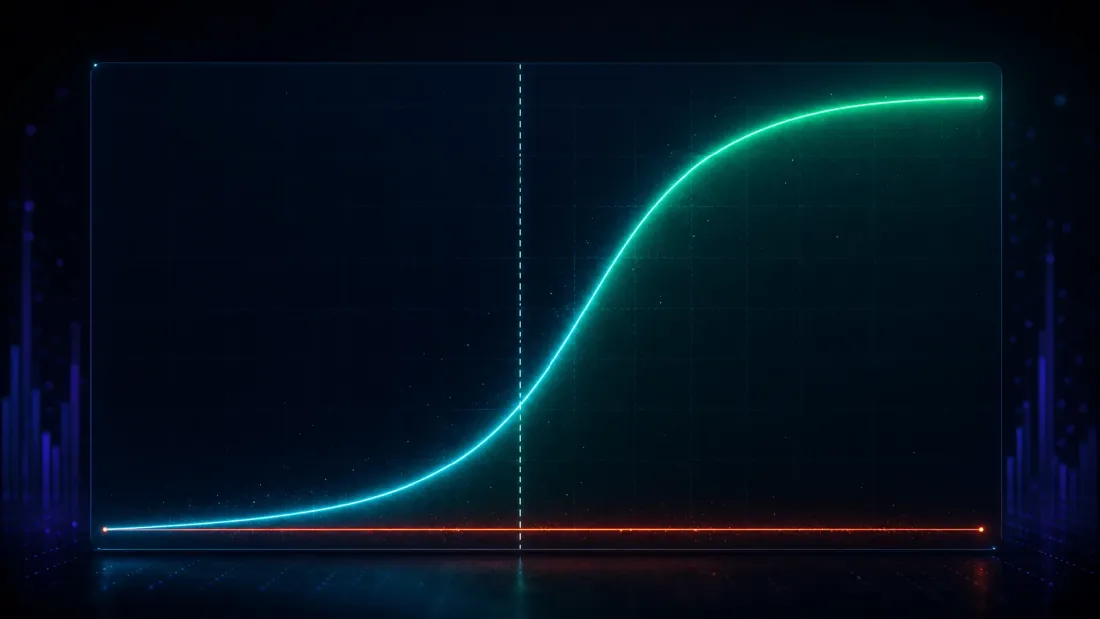
Mengendalikan penemuan palsu hanyalah separuh uji — metode paranoid yang menolak segalanya mencetak 0.000 sempurna dan tidak berguna. Separuh lainnya: ketika edge sejati memang ada, apakah DSR menemukannya?
Tanam satu. Dalam ladang 1,000 strategi, buat 25 di antaranya membawa edge nyata dengan kekuatan yang diketahui dan biarkan sisanya sebagai noise, lalu jalankan pencarian dan tanyakan apakah DSR menandai pemenangnya. Sapukan edge yang ditanam dari lemah ke kuat dan detection power menelusuri kurva-S yang bersih (false-positive rate dipertahankan pada ~0 sepanjang waktu):
| Sharpe sejati yang ditanam (tahunan) | DSR detection power | DSR false-positive rate |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
Lihat di mana kurva itu berbelok. Di bawah plafon noise — Sharpe tahunan sejati 0.79, jauh di bawah 1.63 — DSR menyala 0.5% dari waktu, dengan benar menolak untuk menyebutnya penemuan: edge selemah itu benar-benar tak terbedakan dari keberuntungan yang dihasilkan pencarian 1,000-trial, dan berpura-pura sebaliknya akan menjadi tidak jujur, bukan powerful. Tepat di sekitar plafon, kurva itu menanjak tajam (0.09 pada 1.27, 0.65 pada 1.90). Pada Sharpe tahunan 2.54, power-nya 0.998; pada 3.17, sempurna 1.000. Edge yang kuat dipertahankan pada hampir setiap kesempatan, false positive tetap tertancap di nol, dan titik potong power 50% berada pada Sharpe tahunan sekitar 1.73 (turunan melalui interpolasi antara baris 1.27 dan 1.90) — tepat di atas plafon noise 1.63, persis di tempat batang yang jujur seharusnya diletakkan: titik di mana sebuah edge mulai melampaui apa yang diciptakan oleh pencarian 1,000-trial.
Itulah properti yang sebenarnya Anda inginkan, dinyatakan sebagai kurva-S: edge di bawah plafon noise dengan benar disingkirkan sebagai keberuntungan; edge yang cukup jauh di atasnya dipertahankan dengan power mendekati satu. Uji naif, sebagai kontras, "mendeteksi" edge yang ditanam 67% dari waktu bahkan pada Sharpe sejati 0.79 — tetapi angka itu tidak berarti, karena kita sudah melihat ia mendeteksi edge yang tidak ada 100% dari waktu. Uji yang menyala pada segalanya tidak memiliki power; ia tidak memiliki daya diskriminasi. DSR mengorbankan sedikit sensitivitas terhadap edge marginal (baris 0.79 dan 1.27) demi hal yang benar-benar penting: penemuan-penemuannya nyata.
Babak 5 — Jebakan praktisi: grid berkorelasi
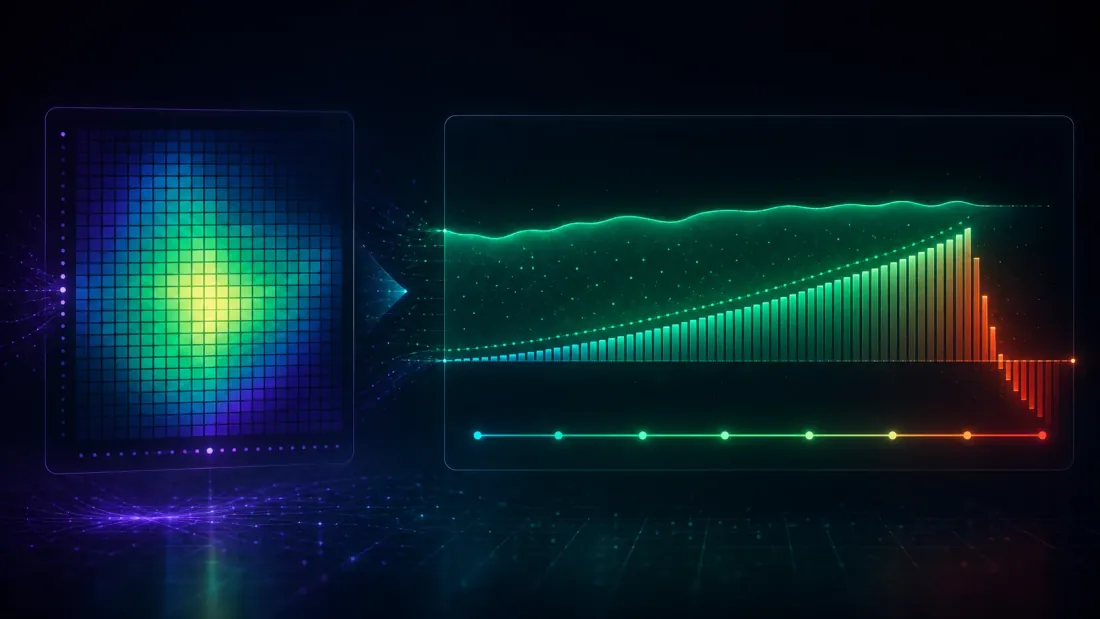
Semua yang sejauh ini menggunakan strategi independen — setting paling bersih yang mungkin, dan tempat di mana asumsi independensi DSR berlaku secara eksak. Grid parameter nyata tidak seperti itu, dan di sinilah sebuah alat yang digunakan secara naif menjadi cara baru untuk salah.
Ambil pencarian moving-average crossover yang jujur: 16 fast length 40 slow length trial, masing-masing 755 observasi. Grid seperti ini terendam dalam korelasi — fast=45/slow=120 dan fast=45/slow=125 hampir merupakan strategi yang sama, sehingga aliran return-nya bergerak bersama. Korelasi berpasangan rata-rata terukur di seluruh 640 trial: sekitar 0.61. Itu bukan 640 taruhan independen. Sama sekali bukan.
Kasus A — random walk (tanpa edge): setiap metode mematikannya, dengan benar
Jalankan grid pada random walk murni. Pemenangnya tampak menggoda: params fast=45/slow=120, Sharpe tahunan terbaik 0.81, p-value single-test 0.081. Setiap metode melihat tembus:
| Metode | Hasil | Vonis |
|---|---|---|
| DSR (raw K = 640) | 0.431 | tolak (< 0.95) |
| Reality Check p | 0.570 | tolak |
| p bertipe-SPA (RC terstudentisasi) | 0.569 | tolak |
| Haircut Harvey-Liu | 100% | tolak |
Mulai dengan tanda yang bahkan tidak memerlukan deflasi sama sekali: bahkan signifikansi finite-sample yang belum disesuaikan dari pemenang ini, -vs-nol, hanya 0.918 — sudah kurang dari 0.95 bahkan sebelum kita mengoreksi untuk satu pun dari 640 trial. Deflasi kemudian menguburnya: batangnya adalah per-observasi, tahunan ~0.91 (turunan: ) — di atas 0.81 milik pemenang. Strategi terbaik bahkan tidak mencapai plafon noise, DSR ≈ 0.43 (lebih buruk dari lemparan koin), dan Reality Check, uji bertipe-SPA, dan haircut 100% semuanya sepakat: tidak ada apa pun di sini. Sempurna. Ini adalah kasus yang mudah, dan berhasil — dan, seperti yang akan kita lihat, tetap tertolak pada setiap jumlah effective-trial yang kita coba.
Kasus B — edge rezim yang sejati: DSR mentah salah
Sekarang jalankan grid yang sama pada seri regime-switching yang membawa edge nyata dan dapat dieksploitasi. Pemenangnya tegas: params fast=3/slow=55, Sharpe tahunan terbaik 3.92 — ini adalah Sharpe in-sample, terseleksi, yang sendiri sudah tergelembung-seleksi oleh pencarian (bukan edge sejati atau out-of-sample), tetapi efek rezim yang mendasarinya nyata — dengan p-value single-test sebesar dan signifikansi belum-terdeflasi -vs-nol pada dasarnya 1.000. Ada edge nyata di sini dan pemenangnya menemukannya. Perhatikan DSR mentah menolaknya begitu saja:
| Metode | Hasil | Vonis |
|---|---|---|
| DSR (raw K = 640) | 0.748 | tolak (< 0.95) ✗ over-deflated |
| Reality Check p | 0.0024 | konfirmasi ✓ |
| p bertipe-SPA (RC terstudentisasi) | 0.0038 | konfirmasi ✓ |
| Haircut Harvey-Liu | 15% | konfirmasi ✓ |
DSR mentah 0.748 adalah penolakan palsu terhadap edge sejati. Alasannya adalah asumsi independensi, yang kini dilanggar keras: DSR membangun batang deflasinya dengan memperlakukan 640 trial berkorelasi sebagai 640 tarikan independen, yang menginflasikan ekspektasi-maksimum menjadi per-observasi 0.221 — tahunan ~3.51 (turunan: ). Terhadap batang 3.51, pemenang 3.92 hanya melewatinya secara tipis, dan DSR mendarat di 0.748 — kurang dari 0.95. Dua hal memompa batang itu naik: jumlah mentah (640 lirikan alih-alih segelintir yang efektif), dan dispersi skill sejati di antara trial — beberapa pasangan parameter memang lebih baik pada seri rezim, yang melebarkan dan mengangkat melampaui apa yang akan dihasilkan keberuntungan murni saja. Keduanya mendorong ke arah yang sama, dan batangnya berakhir terlalu tinggi karena pencarian ini tidak pernah benar-benar 640 lirikan independen; itu adalah segelintir taruhan independen, yang disampel 640 kali berulang.
Berikan DSR jumlah trial efektif sebagai gantinya. One-liner yang digunakan di atas adalah estimasi kasar dari korelasi berpasangan rata-rata:
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
Dengan dan , ini menciutkan grid menjadi trial efektif (turunan: ), dan DSR melompat ke 1.000. Tetapi berhentilah sebelum merayakan angka itu, karena itu adalah bukti paling lemah di seluruh bagian ini. Pada , batang deflasi menciut menjadi tahunan — pada dasarnya rata-rata trial, pada dasarnya nol. Deflasi di sana dimatikan: DSR pada hanyalah melaporkan ulang signifikansi finite-sample belum-terdeflasi milik pemenang (-vs-nol ). Vonis itu diwarisi dari signifikansi mentah, bukan dihasilkan oleh koreksi multiple-testing. Dan caveat cerminnya pada sisi random-walk: penolakannya pada hanya berlaku karena pemenang itu memang sudah marginal secara independen sejak awal (-vs-nol ). Jangkarkan seluruh argumen pada 1.6 dan seorang skeptis berhak mengangkat bahu: Anda mematikan koreksinya dan melaporkan apa pun yang ada di baliknya.
Jadi jangan menjangkarkan pada satu estimator. Langkah yang jujur — dan yang lebih kuat — adalah menghitung dengan lima cara standar yang berbeda dan membaca vonis di seluruh rentang. Berikut lima estimator yang diterapkan pada grid sinyal 640-trial yang sama, masing-masing dengan batang deflasi yang diimplikasikannya dan DSR yang dihasilkannya:
| Estimator effective-trial | Batang deflasi (tahunan) | DSR | Vonis | |
|---|---|---|---|---|
| Korelasi rata-rata | 1.6 | 0.25 | 1.000 | pertahankan |
| Participation ratio | 2.4 | 0.43 | 1.000 | pertahankan |
| PCA (95% varians) | 16 | 1.85 | 1.000 | pertahankan |
| Kaiser (eigenvalue > 1) | 21 | 2.00 | 0.999 | pertahankan |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | tolak |
| jumlah grid mentah (tanpa penyesuaian) | 640 | 3.51 | 0.748 | tolak |
Estimator: korelasi rata-rata adalah one-liner di atas; participation ratio dan hitungan PCA-95%/Kaiser membaca dimensionalitas efektif dari eigenvalue matriks korelasi; Cheverud-Nyholt adalah estimator variance-of-eigenvalues dari literatur genetika yang diketahui over-count di bawah near-equicorrelation.
Sekarang poinnya mendarat, dan itu bukan "penyesuaian apa pun menyelamatkan Anda." Lihat titik tengah yang dapat dipertahankan (defensible middle) — PCA-95% () dan Kaiser (). Ini bukan rezim deflasi-yang-dimatikan; keduanya mengenakan batang tahunan nyata sebesar 1.85 hingga 2.00 — haircut yang serius, jauh di atas noise, penalti multiple-testing yang sungguhan untuk 16-21 lirikan efektif. Dan edge 3.92 itu tetap melewatinya (DSR 1.000 dan 0.999). Sinyal ini bertahan dari DSR untuk setiap di bawah 144.8 (turunan dari titik potong); ia gagal hanya di bawah Cheverud-Nyholt , estimator yang terbukti over-count ketika trial mendekati equicorrelation — dan bahkan jumlah mentah tanpa penyesuaian sebesar 640 hanya mendorong DSR turun ke 0.748, bukan ke nol. Pemenang random-walk, dijalankan melalui lima estimator yang sama persis, ditolak pada setiap satu darinya (ia tidak bertahan pada mana pun di atas 1). Itulah hasil nyatanya: bukan satu angka keberuntungan, melainkan sebuah vonis yang stabil di seluruh rentang estimator effective-trial standar — yang merupakan bukti jauh lebih kuat daripada mempercayai salah satu dari mereka saja.
Satu caveat teknis pada estimator paling kasar, karena ini menjelaskan mengapa ia berada di ujung yang lemah: sebenarnya adalah faktor variance-reduction untuk rata-rata (mean) dari variabel berkorelasi (berapa banyak keuntungan yang diberikan pengambilan rata-rata di bawah korelasi ). Benchmark DSR adalah kuantitas extreme-value — ekspektasi maksimum dari trial — jadi menggunakan penciutan mean-variance sebagai jumlah trial-nya adalah ketidakcocokan fungsional: benar arahnya (berkorelasi ⇒ lebih sedikit trial efektif), tetapi bukan kuantitas yang sebenarnya menjadi dasar distribusi maksimum tersebut. Itulah tepatnya mengapa estimator berbasis eigenvalue di tengah rentang adalah bacaan yang lebih dapat dipercaya, dan mengapa rentangnya, bukan titiknya, yang menjadi hasil akhir (deliverable).
Pelajarannya: gunakan kedua alat, dan berikan DSR N yang benar

Dua hal muncul dari Kasus B, dan keduanya krusial (load-bearing):
- Ukuran grid mentah adalah N yang salah untuk DSR kapan pun trial berkorelasi — dan tidak ada satu pun effective-N tunggal yang benar juga. Memasukkan 640 ke dalam formula yang mengasumsikan independensi akan over-deflate: itu membuat plafon noise yang jauh lebih tinggi daripada yang sebenarnya dicapai pencarian dan mengubur edge nyata di bawahnya. DSR membutuhkan jumlah trial yang efektif — tetapi perbaikannya bukan mempercayai satu estimator (apalagi yang paling kasar, di mana koreksinya mati dekat ). Perbaikannya adalah membaca vonis di seluruh rentang estimator standar (di sini 1.6 hingga 370) dan melihat apakah stabil. Untuk edge ini, memang stabil: dipertahankan di mana pun deflasi benar-benar aktif (batang tahunan nyata 1.85-2.00 pada -), gagal hanya di bawah estimator yang over-count. Vonis yang stabil-di-seluruh-rentang jauh lebih kuat daripada satu angka tunggal mana pun.
- Pasangkan DSR dengan Reality Check. Perhatikan bahwa Reality Check dan sepupunya bertipe-SPA (terstudentisasi) mendapatkan Kasus B dengan benar tanpa operasi jumlah-trial sama sekali (p = 0.0024 dan 0.0038) — mereka menangani dependensi secara native, melalui stationary bootstrap, karena mereka me-resample aliran return berkorelasi yang sebenarnya alih-alih menghitung taruhan independen hipotetis. Itulah pemutus seri (tie-breaker) untuk seluruh kekacauan effective-N: RC tidak membutuhkan . DSR dan RC menjawab pertanyaan yang berbeda: DSR bertanya "apakah pemenang ini istimewa di dalam pencarian ini?" (dan perlu tahu berapa banyak lirikan efektif yang diambil pencarian); RC/bertipe-SPA bertanya "apakah aturan terbaik mengalahkan cash setelah data-snooping?" (dan membaca dependensi langsung dari data itu sendiri). Anda menginginkan keduanya. Ketika mereka tidak sepakat — seperti yang dilakukan DSR raw-count dan RC di sini — ketidaksepakatan itu bersifat diagnostik: biasanya berarti Anda salah.
Ini adalah peringatan struktural yang sama yang terus ditemui studi tangga kecepatan dan pajak IPC kami dari sisi engineering — pencarian cepat yang menjalankan grid berkorelasi yang raksasa tidak membelikan Anda sejumlah besar taruhan independen, dan memperlakukan ukuran grid sebagai jumlah trial menipu baik optimizer Anda maupun uji signifikansi Anda. Artikel pendamping yang akan datang tentang probability of backtest overfitting menyerang selection bias yang sama dari sisi resampling (CSCV), dan berpasangan secara alami dengan semua yang ada di sini: DSR memberi harga pada pemenang, PBO memberi harga pada prosedurnya.
Catatan kejujuran
Tiga caveat, dinyatakan secara terus terang, karena inti dari studi terkontrol adalah untuk tidak melebih-lebihkannya.
- Return-nya sintetis. Normal iid untuk eksperimen kalibrasi dan power, proses regime-switching untuk kasus edge-sejati — dipilih untuk ground truth terkontrol, bukan untuk realisme pasar. Return nyata bersifat fat-tailed, terautokorelasi, dan non-stasioner, dan suku skew/kurtosis PSR ada tepatnya untuk menangani yang pertama dari itu. Hasil akhir (deliverable) di sini adalah metode yang terkalibrasi, bukan sebuah strategi: kami hanya bisa membuktikan bahwa sebuah uji mengendalikan penemuan palsu dengan menjalankannya pada data di mana kami tahu tidak ada apa pun untuk ditemukan. Itu membutuhkan pembuatan ground truth.
- Tidak ada estimator effective-N yang kanonik — itulah sebabnya kami melaporkan lima. One-liner korelasi rata-rata mudah dipahami reviewer dan benar arahnya (lebih banyak korelasi ⇒ lebih sedikit trial efektif), tetapi ia adalah faktor variance-reduction untuk sebuah mean — ketidakcocokan fungsional dengan benchmark maksimum DSR — dan mendekati ia mematikan deflasi sepenuhnya. Estimator eigenvalue (participation ratio, PCA-95%, Kaiser) lebih cocok tetapi tetap heuristik, dan Cheverud-Nyholt over-count di bawah equicorrelation. Pendekatan yang lebih lengkap dan berprinsip adalah clustering trial (DSR Appendix 3 milik Bailey & López de Prado): kelompokkan trial berdasarkan struktur korelasi dan hitung cluster alih-alih menciutkan semuanya menjadi satu skalar. Kami melaporkan seluruh rentang tepatnya karena pilihannya belum terselesaikan — vonis yang stabil di seluruh lima estimator adalah klaim yang jujur; yang bergantung pada memilih satu estimator tunggal tidak akan begitu.
- Bootstrap-nya adalah Reality Check terstudentisasi, bukan SPA Hansen yang lengkap, dan jumlah resample berbeda per eksperimen. Di mana pun artikel ini mengatakan "bertipe-SPA," artinya adalah Reality Check milik White dengan studentisasi per-aturan; recentering konsisten dan bergantung-sampel penuh milik Hansen tidak diimplementasikan. False-discovery rate kalibrasi menggunakan 500 resample stationary-bootstrap per pencarian di seluruh 400 pencarian; dua p-value RC/bertipe-SPA studi kasus masing-masing menggunakan 5,000 resample. Panjang blok rata-rata 20 sepanjang studi (Politis-Romano), , 252 periode/tahun untuk penahunan. Ubah ini dan angka-angka desimal ketiga akan bergeser; ceritanya — naif 1.000 versus berprinsip 0.001-0.057, kurva-S yang mencapai power 50% tepat di atas plafon noise, dan jebakan grid-berkorelasi yang vonisnya harus dibaca di seluruh rentang effective-N — tidak berubah.
Poin-Poin Kunci
- Parameter search adalah mesin multiple-testing, dan uji signifikansi naif buta terhadapnya. Pada 1,000 strategi ber-edge nol, Sharpe tahunan terbaik rata-rata 1.63 dengan median p-value single-test 0.000686 — dan uji "apakah ini signifikan?" mendeklarasikan penemuan 100% dari waktu (false-discovery rate 1.000). Sharpe hebat dari ketiadaan, disertifikasi signifikan oleh uji yang tidak pernah menanyakan pertanyaan yang benar.
- Deflated Sharpe Ratio memindahkan gawang dari nol ke plafon noise. DSR membandingkan pemenang bukan dengan nol melainkan dengan , ekspektasi terbaik-karena-keberuntungan dari pencarian seukuran ini — yang untuk kasus null mendarat pada 1.63 tahunan, tepat di tempat rata-rata pemenang noise berada (turunan: ). False-discovery rate null-nya 0.001; haircut Harvey-Liu (Bonferroni/Holm 0.057, BHY 0.007) dan Reality Check milik White (0.022) mencapai kendali yang sama melalui jalan lain.
- Ia mempertahankan edge nyata. Detection power DSR menelusuri kurva-S yang mencapai power 50% pada Sharpe tahunan ~1.73 — tepat di atas plafon noise 1.63: 0.005 pada Sharpe tahunan sejati 0.79, 0.651 pada 1.90, 0.998 pada 2.54, 1.000 pada 3.17, false positive ~0 sepanjang waktu. Edge di bawah plafon dengan benar dinyatakan tak terbedakan dari keberuntungan; edge di atasnya dipertahankan dengan power mendekati satu.
- Grid berkorelasi merusak DSR mentah — dan tidak ada satu pun effective-N tunggal yang menyelamatkannya; rentangnya yang menyelamatkan. Pada MA crossover 640-sel (korelasi berpasangan rata-rata ~0.61), DSR raw-count secara palsu menolak edge sejati (in-sample terseleksi, tahunan 3.92) (0.748 < 0.95) karena 640 trial berkorelasi bukanlah 640 taruhan independen. Tetapi perbaikannya bukan satu ajaib — pada estimasi paling kasar () deflasinya pada dasarnya dimatikan (batang ~0.25 tahunan) dan DSR hanya menggemakan signifikansi mentah. Bukti nyatanya adalah bahwa edge itu dipertahankan di seluruh rentang estimator standar — DSR 1.000/1.000/1.000/0.999 pada 1.6/2.4/16/21, termasuk batang tahunan nyata 1.85-2.00 pada rentang-tengah PCA-95%/Kaiser yang dapat dipertahankan — bertahan untuk mana pun, dan gagal hanya di bawah 370 over-counting milik Cheverud-Nyholt. Random walk ditolak pada setiap estimator. Baca rentangnya, bukan satu titik.
- Pasangkan DSR dengan Reality Check, karena keduanya menjawab pertanyaan yang berbeda. Reality Check dan sepupunya bertipe-SPA (terstudentisasi) mengonfirmasi edge nyata (p = 0.0024 dan 0.0038) tanpa operasi jumlah-trial — mereka menangani dependensi secara native melalui stationary bootstrap, yang tepatnya menjadi tie-breaker ketika effective-N diperdebatkan. DSR bertanya "apakah pemenang ini istimewa di dalam pencarian ini?"; RC/bertipe-SPA bertanya "apakah yang terbaik mengalahkan cash setelah data-snooping?" Ketidaksepakatan di antara mereka adalah sinyal bahwa Anda salah. Jalankan keduanya.
Pemenang sebuah pencarian bersalah sampai terbukti tidak bersalah. P-value naif bukanlah bukti ketidakbersalahan — itu adalah kesaksian tergelembung milik pencarian itu sendiri, dan ia akan menjamin noise murni dengan dua belas angka nol keyakinan. Deflasikan benchmark-nya ke apa yang dihasilkan keberuntungan, hitung trial efektif Anda dengan jujur, dan bootstrap maksimumnya untuk pendapat kedua. Apa yang melewati ketiga batang itu mungkin benar-benar nyata. Apa yang hanya melewati batang naif adalah yang tertinggi dari seribu pelempar koin.
Eksperimen lengkapnya — harness kalibrasi-null, power sweep edge yang ditanam, pencarian grid berkorelasi, dan setiap angka dalam artikel ini yang dapat dibangkitkan ulang dari satu skrip deterministik — ada di paper pendamping di deflated-sharpe.marketmaker.cc, dengan kode dan data di github.com/suenot/deflated-sharpe-search.
Penulis

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Selengkapnya

Probability of Backtest Overfitting: Apakah Pencarian Anda Mengalahkan Lemparan Koin?

Objective-Function Design: Metrik yang Anda Optimalkan Diam-Diam Memilih Strategi Anda
