Deflated Sharpe Ratio: 'ผู้ชนะ' จาก Backtest ของคุณกี่ตัวที่รอดจาก Multiple Testing?
เป็นส่วนหนึ่งของซีรีส์ "Backtests Without Illusions"
📄 บทความนี้ขยายกลายเป็นเปเปอร์วิจัย ตัวเลขทุกตัวด้านล่างมาจากสคริปต์ deterministic ตัวเดียวที่สร้าง ground truth ที่ควบคุมได้ — การค้นหาบน pure noise, การค้นหาที่ปลูก edge ไว้ และ parameter grid ที่มี correlation จริง — แล้วรัน Deflated Sharpe Ratio, Harvey-Liu multiple-testing haircut และ White's Reality Check / Hansen's SPA กับมัน โดยวัด false-discovery rate และ detection power ของแต่ละวิธีโดยตรง อ่านเปเปอร์ฉบับเต็มออนไลน์ (เวอร์ชันอินเทอร์แอกทีฟ + PDF) ได้ที่ deflated-sharpe.marketmaker.cc โค้ดและข้อมูลอยู่ที่ github.com/suenot/deflated-sharpe-search
คุณรัน parameter sweep fast length สิบหกค่า, slow length สี่สิบค่า, moving-average crossover 640 combination grid รันเสร็จ แล้วมีหนึ่ง cell ที่เปล่งประกาย: Sharpe ต่อปีที่ 3.9, single-test p-value ที่ ศูนย์สิบสองตัวของความมีนัยสำคัญ คุณพบอะไรบางอย่างแล้ว
หรือคุณไม่ได้พบอะไรเลย และการค้นหาต่างหากที่ พบมัน ให้คุณ
parameter search ไม่ใช่การทดสอบ มันคือเครื่องจักรสำหรับหาตัวที่โชคดีที่สุดใน N ครั้ง และยิ่งคุณให้มันลองมากเท่าไหร่ ผู้ชนะของมันก็ยิ่งดูโชคดีมากขึ้นเท่านั้น — ไม่ว่าจะมี edge จริงอยู่ข้างใต้หรือไม่ก็ตาม best-of-N Sharpe ถูกพองขึ้นด้วยการ selection แบบเดียวกับที่คนสูงที่สุดในกลุ่มคนสุ่มพันคนดูสูง: ไม่ใช่เพราะความสูงนั้นเป็นจริง แต่เพราะคุณค้นหา สถิติแบบ single-test ที่พิมพ์ไว้ข้าง ๆ ผู้ชนะ — p-value ของมัน, t-stat ของมัน, "มันมีนัยสำคัญไหม?" ของมัน — ถูกออกแบบมาสำหรับสมมติฐานที่ pre-registered ไว้เพียงหนึ่งเดียว ป้อนมันด้วยผู้รอดชีวิตจากการค้นหา แล้วมันจะโกหก อย่างมั่นใจ ทุกครั้งไป
บทความนี้วัดอย่างแม่นยำว่ามันโกหกแย่แค่ไหน แล้ววัดเครื่องมือสามชนิดที่แก้ไขมัน ประเด็นทั้งหมดคือ controlled ground truth: เราสร้างผลตอบแทนที่เรา รู้ คำตอบอยู่แล้ว — บางครั้งเป็น pure noise ที่ไม่มี edge เลย บางครั้งเป็น edge ที่ปลูกไว้ด้วยความแรงที่รู้ค่า — ดังนั้นคำถาม "วิธีนี้ตอบถูกไหม?" จึงเป็นข้อเท็จจริง ไม่ใช่การตัดสินใจตามความรู้สึก นี่คือหัวข้อหลักก่อนอื่นเลย บนการค้นหาที่รู้ว่า null เป็นจริง (known-null) ซึ่งคำตอบที่ซื่อสัตย์คือ "ไม่มีการค้นพบ" เสมอ นี่คือความถี่ที่แต่ละ test ร้องหมาป่า:
| Test | False-discovery rate บนการค้นหาที่ known-null | คำตัดสิน |
|---|---|---|
| Naive "Sharpe ที่ดีที่สุดมีนัยสำคัญไหม?" | 1.000 | ฟันธงว่าพบการค้นพบ ทุกครั้งไม่มีเว้น |
| Deflated Sharpe Ratio (DSR ≥ 0.95) | 0.001 | ควบคุมได้ |
| Harvey-Liu haircut — Bonferroni | 0.057 | ~ควบคุมได้ |
| Harvey-Liu haircut — Holm | 0.057 | ~ควบคุมได้ |
| Harvey-Liu haircut — BHY | 0.007 | ควบคุมได้ |
| White's Reality Check (bootstrap) | 0.022 | ควบคุมได้ |
กลยุทธ์ 1,000 ตัวต่อการค้นหา, 1,000 observation ต่อตัว, 2,000 การค้นหา null ที่เป็นอิสระต่อกัน, true Sharpe = 0 ทุกที่ ผลตอบแทน synthetic iid Normal, seed 0, α = 0.05, 252 period/ปี false-discovery rate ของ naive test ไม่ใช่แค่สูง — มันคือ หนึ่งเป๊ะ
อ่านแถวแรกจนกว่ามันจะแสบ test ที่ ควร จะ fire 5% ของเวลาบน pure noise กลับ fire 100% ของเวลา — เพราะคุณไม่ได้แสดง pure noise ให้มันดู คุณกำลังแสดง ค่าสูงสุด ของการสุ่มพันครั้งจาก pure noise และค่าสูงสุดของคนโยนเหรียญพันคนย่อมดูเหมือนอัจฉริยะเสมอ ทุกแถวที่เหลือคือวิธีที่รู้เรื่องนี้และแก้ไขให้มัน นี่คือใจความทั้งหมดของบทความ: ทำไมแถวแรกถึงเป็น 1.000 ทำไมแถวอื่นถึงไม่เป็น และจุดเดียว (หัวข้อสุดท้าย) ที่แม้แต่วิธีที่ดีก็ยังต้องการการแก้ไขรอบที่สองเพื่อรักษาความซื่อสัตย์
Act 1 — กับดัก: การค้นหาผลิต Sharpe ขึ้นจากความว่างเปล่า

เริ่มจากกับดักที่สะอาดที่สุดเท่าที่จะเป็นไปได้ สร้างกลยุทธ์ ตัวที่ผลตอบแทนเป็น noise แบบ standard-Normal ที่เป็นอิสระต่อกัน — ไม่มี drift ไม่มีฝีมือ true Sharpe เท่ากับศูนย์เป๊ะสำหรับทุกตัว แต่ละตัวมี observation ทีนี้ทำในสิ่งที่ parameter search ทุกตัวทำ: เก็บตัวที่ดีที่สุดไว้
best-of-1000 per-observation Sharpe เฉลี่ยอยู่ที่ 0.1027 ซึ่งต่อปีแล้วได้ 1.63 (คำนวณ: ) นั่นไม่ใช่ตัวเลขเล็กน้อยเลย Sharpe ต่อปีที่ 1.63 คือผลลัพธ์แบบที่ทำให้กลยุทธ์ได้รับเงินทุน ถูกเขียนรายงาน ถูกจัดสรรเงินให้ มันมาจาก random-number generator ที่ตั้ง drift ไว้เป็นศูนย์
ทีนี้ส่งผู้ชนะให้กับ naive significance test — ตัวที่ backtest library ทุกตัวพิมพ์ให้ฟรี ๆ แปลง Sharpe ของมันเป็น t-statistic () เอา one-sided p-value มา แล้วเรียกมันว่าการค้นพบถ้า :
ค่ามัธยฐานของ single-test p-value ของผู้ชนะ noise เหล่านี้คือ 0.000686 — ศูนย์สามตัวของ "นัยสำคัญ" จากกลยุทธ์ที่ไม่มี edge เลย และตลอด 2,000 การค้นหา null ที่เป็นอิสระต่อกัน naive test ประกาศการค้นพบใน ทุก ๆ ครั้ง: false-discovery rate ที่ 1.000 ไม่ใช่ "พองขึ้น" ไม่ใช่ "สูงไปหน่อย" test ที่ถูกต้อง โดยการออกแบบ อย่างมากที่สุด 5% ของเวลาบน null hypothesis เดียว กลับผิด 100% ของเวลาบนผู้ชนะของการค้นหา
กลไกนี้ไม่ซับซ้อนเลยเมื่อเรียกชื่อมันออกมา naive test ถามว่า "Sharpe ตัวนี้เกิดขึ้นโดยบังเอิญภายใต้ null ได้ไหม?" — เป็นคำถามที่ยุติธรรมสำหรับกลยุทธ์ที่คุณเลือก ก่อน ดูข้อมูล แต่คุณเลือกตัวนี้ เพราะ มันมี Sharpe สูงที่สุดในพันตัว คุณได้ condition บนค่าสูงสุดแล้ว และ sampling distribution ของค่าสูงสุดนั้นไม่เหมือนกับ sampling distribution ของการสุ่มครั้งเดียวเลย นี่คือโรคเดียวกับที่ look-ahead bias taxonomy ของเราวินิจฉัยไว้จากอีกด้านหนึ่ง — ที่นั่น การรั่วไหลหนึ่งแท่งเทียนผลิต Sharpe 15 จาก noise; ที่นี่ การค้นหาผลิต Sharpe 1.63 จาก noise โดยไม่มีการรั่วไหลเลยแม้แต่นิดเดียว เกิดจาก selection ล้วน ๆ กลไกต่างกัน แต่อาการเหมือนกันเป๊ะ: Sharpe ที่ดูดีสุด ๆ แต่ไม่มีความหมายอะไรเลย
ตัวเลข 1.63 คือตัวสำคัญ จำมันไว้ให้ดี มันคือ noise ceiling ของการค้นหานี้: Sharpe ที่คุณควรคาดหวังว่ากลยุทธ์ zero-edge ที่โชคดีที่สุดใน 1,000 ตัวจะทำได้ test ที่ซื่อสัตย์ใด ๆ ต่อผู้ชนะของการค้นหาต้องเปรียบเทียบมันไม่ใช่กับศูนย์ แต่กับ สิ่งนี้ — กับสิ่งที่ความโชคดีล้วน ๆ ส่งมอบให้เมื่อคุณมองพันครั้ง
Act 2 — ชุดเครื่องมือ: สามวิธีตั้งราคาให้การค้นหา

งานวิจัยสามสาย มาถึงอย่างเป็นอิสระต่อกัน ต่างก็ได้ข้อแก้ไขเดียวกัน: หยุดเปรียบเทียบผู้ชนะกับศูนย์ แล้วเริ่มเปรียบเทียบมันกับสิ่งที่การค้นหาขนาดนี้ผลิตขึ้นด้วยความโชคดี พวกมันต่างกันตรงวิธีสร้างการเปรียบเทียบนั้น
PSR และ Deflated Sharpe Ratio (Bailey & López de Prado, 2012 / 2014)
Probabilistic Sharpe Ratio ถามคำถามที่คมกว่า "Sharpe เป็นบวกไหม?" มันถามว่า: จากความยาวของ sample และรูปร่างของผลตอบแทน (skew, fat tail) ความน่าจะเป็นที่ true Sharpe จะเกิน benchmark คือเท่าไหร่?
ในที่นี้ คือ standard-Normal CDF, คือ skew และ คือ kurtosis ใน non-excess convention (Normal ⇒ ; ถ้าแทนด้วย excess kurtosis ตรงนี้โดยไม่บวก 3 ผลลัพธ์ deflation จะผิด) ตั้ง แล้ว PSR ก็เป็นแค่ finite-sample significance test เวทมนตร์อยู่ที่การเลือก ให้ดี
Deflated Sharpe Ratio คือ PSR ที่ประเมินที่ benchmark ซึ่งไม่ใช่ศูนย์ แต่เป็น expected maximum Sharpe ของการค้นหาทั้งหมด:
โดยที่ คือ variance ข้าม Sharpe ของทุก trial ทั้ง N ตัว (การกระจายตัวที่การค้นหาเองผลิตขึ้น), คือ Euler-Mascheroni constant และเทอม inverse-Normal ทั้งสองคือค่าประมาณแบบ Extreme-Value-Theory ของค่าคาดหวังของค่าสูงสุดจากการสุ่ม standard-Normal จำนวน ครั้ง ในโค้ดมันสั้นเกินกว่าจะดูน่าประทับใจด้วยซ้ำ:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
จากนั้น DSR ก็เป็นแค่ PSR ที่มี bar แบบ deflated นั้น:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR คือความน่าจะเป็น เราประกาศการค้นพบเมื่อ : true Sharpe ของผู้ชนะเอาชนะ expected best-by-luck ด้วยความเชื่อมั่น 95% สังเกตข้อสมมติที่แบกรับน้ำหนักไว้ใน : trial ทั้ง ตัวถูกถือว่าเป็น อิสระต่อกัน Act 5 ทั้งหมดคือเรื่องของสิ่งที่เกิดขึ้นเมื่อมันไม่เป็นเช่นนั้น
Harvey-Liu haircut (2015)
Harvey และ Liu โจมตีปัญหาเดียวกันผ่านการปรับ p-value แบบ multiple-testing — เครื่องจักรคลาสสิกสำหรับ "ฉันรัน M test แล้ว อย่าให้ฉันหลอกตัวเอง" เรียงลำดับ single-test p-value ทั้ง ตัว แล้วพองมันขึ้น:
Bonferroni คือเครื่องมือแบบหยาบ ๆ (ควบคุมความน่าจะเป็นของ false positive ใด ๆ ด้วยการคูณทุก p-value ด้วย ); Holm คือญาติแบบ step-down ที่มี power มากกว่าอย่างสม่ำเสมอ ตัวที่สาม Benjamini-Yekutieli (BHY) ควบคุม false-discovery rate — สัดส่วนที่คาดหวังของการปฏิเสธของคุณที่ผิด — และที่สำคัญคือมันทำแบบนี้ได้ ภายใต้ dependence แบบใดก็ได้ ระหว่าง test โดยใช้ตัว normalizer แบบ harmonic ในตัวเศษ:
นั้นคือราคาที่ BHY เรียกเก็บจากการไม่สมมติว่า trial ทั้ง 1,000 ตัวของคุณเป็นอิสระต่อกัน — มันพอง threshold ของ FDR ขึ้นด้วยตัวคูณที่โตแบบ "haircut" เองคือเมตริกไฮไลต์: แปลง p-value ที่ปรับแล้วกลับเป็น Sharpe และรายงานว่าคุณต้องโกน Sharpe เดิมออกไปเท่าไหร่ haircut 100% หมายความว่าผู้ชนะถูกอธิบายได้ทั้งหมดด้วย multiple testing; 15% หมายความว่ามันรอดมาได้ส่วนใหญ่
White's Reality Check และ Hansen's SPA (2000 / 2005)
เครื่องมือตัวที่สามไม่ตั้งสมมติฐานเรื่อง distribution เลยแม้แต่น้อย White's Reality Check เอาผลตอบแทนจริงของทุก rule มาสร้างสถิติแบบ max-over-rules แล้ว bootstrap null distribution ของมันโดยตรง:
โดยที่ คือ performance เฉลี่ยของ rule ที่ เทียบกับ benchmark มัน resample ผลตอบแทนด้วย stationary bootstrap (Politis-Romano — block ที่มีความยาวสุ่มเพื่อให้ serial correlation รอดจากการ resample), recenter แต่ละการสุ่มให้สอดคล้องกับ null โดยการสร้าง, คำนวณค่าสูงสุดใหม่ในทุกการสุ่ม แล้วรายงาน p-value เป็นสัดส่วนของ bootstrap maxima ที่เอาชนะค่าที่สังเกตได้จริง Hansen's SPA ทำให้ RC คมขึ้นสองทาง: studentization (หารค่าเฉลี่ยของแต่ละ rule ด้วย standard error ของมันเอง เพื่อไม่ให้ rule ที่มี variance สูงตัวเดียวมา hijack ค่าสูงสุด) และการ recenter null แบบ consistent ที่ขึ้นกับ sample implementation ของเราเพิ่ม studentization เข้าไปแต่ไม่มีขั้นตอน consistent-recentering แบบเต็ม — ดังนั้นไม่ว่าบทความนี้จะรายงาน p-value แบบ SPA-type ตรงไหน ให้อ่านมันว่าเป็น studentized Reality Check ไม่ใช่ Hansen SPA แบบสมบูรณ์ ในขณะที่ DSR ถามว่า "ผู้ชนะพิเศษ ภายใน การค้นหานี้ไหม?" Reality Check ถามว่า "rule ที่ดีที่สุดเอาชนะเงินสดได้ไหม หลังจาก คำนึงถึงจำนวน rule ที่ฉันลองอย่างซื่อสัตย์แล้ว?" — และมันจัดการ rule ที่ correlated กันได้โดยธรรมชาติ ผ่าน bootstrap โดยไม่ต้องนับ trial เลย จำความแตกต่างนี้ไว้ให้ดี ส่วนสุดท้ายของบทความหมุนรอบมันอยู่
Act 3 — Calibration คือบทพิสูจน์ทั้งหมด
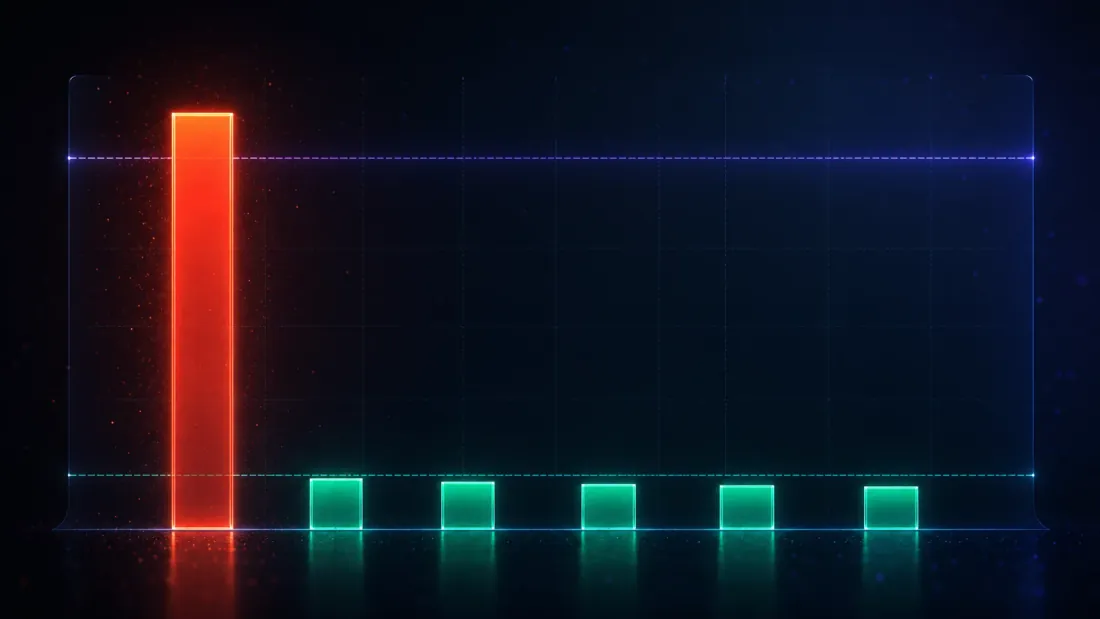
วิธีที่ไม่ flag อะไรเลยก็จะมี false-discovery rate เป็นศูนย์เหมือนกัน — และไร้ประโยชน์ ดังนั้น test ที่มีความหมายเพียงหนึ่งเดียวสำหรับเครื่องมือเหล่านี้คือ test แบบสองด้าน: บนข้อมูล known-null พวกมันต้องควบคุม false discovery ให้อยู่ที่หรือต่ำกว่า และบนข้อมูล known-edge (หัวข้อถัดไป) พวกมันต้องยังคง fire ได้อยู่ หัวข้อนี้คือครึ่งแรก
รันการค้นหาที่เป็นอิสระต่อกัน 2,000 ครั้ง แต่ละครั้งบนกลยุทธ์ zero-edge 1,000 ตัว แล้วนับว่าแต่ละวิธีประกาศการค้นพบบ่อยแค่ไหน จำนวนนั้นหารด้วย 2,000 คือ false-discovery rate — และเนื่องจากความจริงคือไม่มี edge เลย ทุกการค้นพบจึงเป็นเท็จ:
| Test | False-discovery rate (α = 0.05) |
|---|---|
| Naive significance | 1.000 |
| Deflated Sharpe Ratio | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| White's Reality Check | 0.022 |
ทุกวิธีที่มีหลักการลงเอยที่หรือใกล้เส้น 5% — FWER haircut ทั้งสองสูงกว่าเล็กน้อย DSR/BHY/RC ต่ำกว่า — ในขณะที่ naive test อยู่ที่ 100 (Bonferroni และ Holm พิมพ์ 0.057 เท่ากันตรงนี้ และไม่ใช่เรื่องบังเอิญ: สำหรับกลยุทธ์ที่ดีที่สุดตัวเดียว ขั้นแรกของ Holm คือ ซึ่งเหมือนกับ Bonferroni โดยการสร้าง ดังนั้นมันจึงเป็นการยืนยันหนึ่งครั้ง ไม่ใช่สอง) แต่ตัวเลขที่ลึกที่สุดในการศึกษาทั้งหมดไม่ได้อยู่ในตารางนี้ — มันคือ deflated benchmark ที่ผลิตคอลัมน์ DSR ขึ้นมา เมื่อเฉลี่ยข้ามการค้นหา null ทั้งหมด ออกมาเป็น per-observation 0.1030 ซึ่งต่อปีแล้วได้ 1.63 (คำนวณ: ) — ตัวเลข 1.63 เดียวกับที่ผู้ชนะ noise เฉลี่ยทำได้ (1.63) นั่นไม่ใช่เรื่องบังเอิญ มันคือแนวคิดทั้งหมดที่กำลังทำงาน:
deflated bar อยู่ เป๊ะ ที่ noise ceiling DSR ไม่ได้ขอให้ผู้ชนะการค้นหาเอาชนะศูนย์ มันขอให้ผู้ชนะเอาชนะ คะแนนที่ดีที่สุดที่ความโชคดีล้วน ๆ ผลิตได้จากการค้นหาขนาดนี้ — 1.63 ต่อปีในที่นี้ ผู้ชนะที่แค่เท่ากับ noise ceiling จะได้คะแนน DSR ≈ 0.5 (โยนเหรียญ) ซึ่งเป็นเหตุผลว่าทำไม null DSR เฉลี่ยจึงเป็น 0.495 ไม่ใช่อะไรที่เล็ก การจะเป็นการค้นพบ ผู้ชนะต้องข้าม 1.63 และมากกว่านั้นอีก — มากพอที่จะดัน PSR ให้เกิน 0.95
นี่คือการปรับกรอบทั้งหมดของการฝึกฝนนี้ naive test วัดระยะห่างจากศูนย์; ทุกการค้นหาข้าม bar นั้นได้อย่างง่ายดายไม่มีความหมาย นั่นคือเหตุผลว่าทำไมมันถึงไร้ประโยชน์ DSR วัดระยะห่างจาก noise ceiling และการข้าม bar นั้นยากจริง ๆ — ตามที่ควรจะเป็น Harvey-Liu haircut และ Reality Check ไปถึงการควบคุมแบบเดียวกันด้วยเส้นทางที่ต่างกัน (การพองตัวด้วย สำหรับ BHY, bootstrap max-distribution สำหรับ RC) และลงเอยในย่านเดียวกัน: 0.001 ถึง 0.057 ที่หรือใกล้ Bonferroni/Holm ที่ 0.057 สูงกว่าเส้น 5% นิดหน่อย แต่แค่นิดเดียว: ด้วยการค้นหา Monte-Carlo 2,000 ครั้ง standard error บนค่าประมาณ FDR ใกล้ 0.05 อยู่ที่ประมาณ 0.005 ดังนั้น 0.057 จึงอยู่ที่ประมาณ 1.4 standard error เหนือ — เป็น Monte-Carlo noise ไม่ใช่การรับประกันที่พัง "ควบคุม FWER" ก็เป็นแค่คำมั่นสัญญาแบบ asymptotic อยู่แล้ว ไม่ใช่คำมั่นที่แม่นยำระดับบิตที่
Act 4 — Power: มันยังเก็บ edge จริงไว้ได้ไหม?
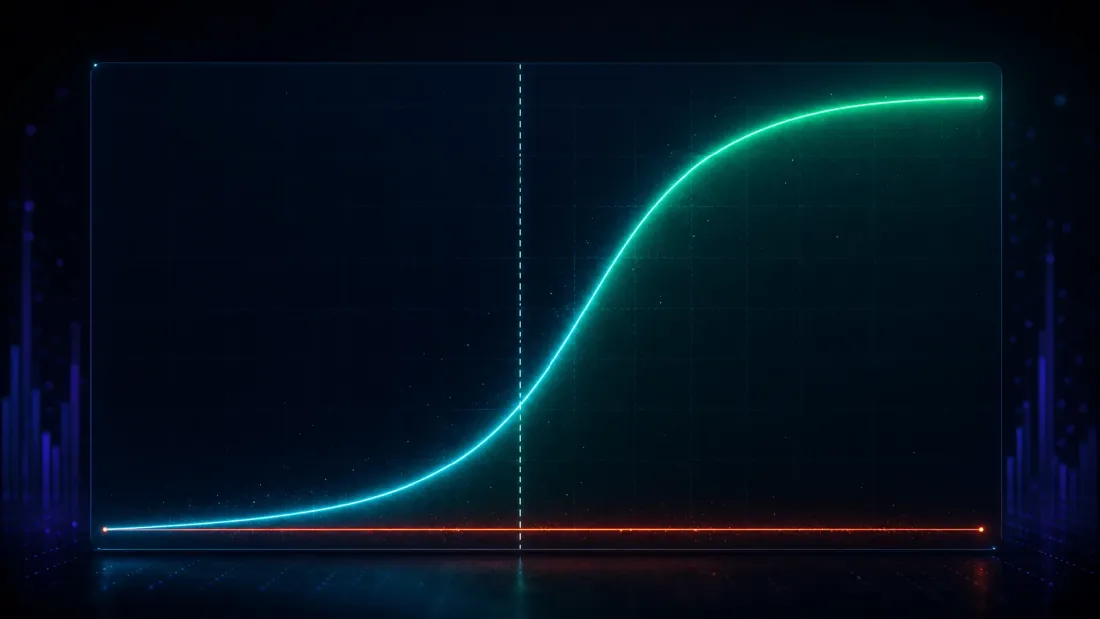
การควบคุม false discovery เป็นแค่ครึ่งหนึ่งของ test — วิธีที่หวาดระแวงจนปฏิเสธทุกอย่างจะได้คะแนนสมบูรณ์แบบ 0.000 และไร้ค่า อีกครึ่งหนึ่ง: เมื่อ edge จริงมีอยู่ DSR จะพบมันไหม?
ปลูกมันลงไป ในสนามของกลยุทธ์ 1,000 ตัว ให้ 25 ตัวมี edge จริงที่มีความแรงที่รู้ค่า และปล่อยที่เหลือให้เป็น noise แล้วรันการค้นหาและถามว่า DSR flag ผู้ชนะไหม ไล่ edge ที่ปลูกไว้จากอ่อนไปแรง แล้ว detection power จะลากเป็นเส้นโค้ง S ที่สะอาด (false-positive rate คงอยู่ที่ ~0 ตลอด):
| True Sharpe ที่ปลูกไว้ (ต่อปี) | DSR detection power | DSR false-positive rate |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
ดูว่าเส้นโค้งเลี้ยวตรงไหน ต่ำกว่า noise ceiling — true Sharpe ต่อปีที่ 0.79 ต่ำกว่า 1.63 มาก — DSR fire แค่ 0.5% ของเวลา ปฏิเสธที่จะเรียกมันอย่างถูกต้อง: edge ที่อ่อนขนาดนั้นแยกไม่ออกจากความโชคดีที่การค้นหา 1,000-trial สร้างขึ้นจริง ๆ และการแสร้งทำเป็นอย่างอื่นจะเป็นความไม่ซื่อสัตย์ ไม่ใช่ power รอบ ๆ ceiling เส้นโค้งไต่ขึ้นอย่างชัน (0.09 ที่ 1.27, 0.65 ที่ 1.90) เมื่อถึง Sharpe ต่อปีที่ 2.54 power อยู่ที่ 0.998; เมื่อถึง 3.17 มันเป็น 1.000 ที่สมบูรณ์แบบ edge ที่แข็งแรงถูกเก็บไว้แทบทุกครั้ง false positive ยังคงปักอยู่ที่ศูนย์ และจุดตัด 50%-power อยู่ที่ Sharpe ต่อปีประมาณ 1.73 (คำนวณโดย interpolation ระหว่างแถว 1.27 และ 1.90) — สูงกว่า noise ceiling ที่ 1.63 เล็กน้อย ตรงจุดที่ bar ที่ซื่อสัตย์ควรวางไว้พอดี: จุดที่ edge เริ่มวิ่งแซงหน้าสิ่งที่การค้นหา 1,000-trial ประดิษฐ์ขึ้นมา
นั่นคือคุณสมบัติที่คุณต้องการจริง ๆ กล่าวในรูปเส้นโค้ง S: edge ที่ต่ำกว่า noise ceiling ถูกตัดออกอย่างถูกต้องว่าเป็นความโชคดี; edge ที่สูงกว่ามันอย่างสบาย ๆ ถูกเก็บไว้ด้วย power ที่เข้าใกล้หนึ่ง naive test ในทางตรงกันข้าม "ตรวจพบ" edge ที่ปลูกไว้ 67% ของเวลาแม้ที่ true Sharpe เพียง 0.79 — แต่ตัวเลขนั้นไม่มีความหมายเลย เพราะเราเห็นแล้วว่ามันตรวจพบ edge ที่ไม่มีอยู่จริง 100% ของเวลา test ที่ fire กับทุกอย่างไม่มี power เลย มันไม่มีการแยกแยะ DSR แลก sensitivity เล็กน้อยต่อ edge ระดับขอบ (แถว 0.79 และ 1.27) เพื่อสิ่งที่สำคัญ: การค้นพบของมันเป็นของจริง
Act 5 — กับดักของนักปฏิบัติ: correlated grid
ทุกอย่างจนถึงตอนนี้ใช้กลยุทธ์ที่เป็นอิสระต่อกัน — การตั้งค่าที่สะอาดที่สุดเท่าที่จะเป็นไปได้ และเป็นกรณีที่ข้อสมมติเรื่องความเป็นอิสระของ DSR ใช้ได้เป๊ะ parameter grid จริงไม่ได้เป็นแบบนั้น และนี่คือจุดที่เครื่องมือที่ใช้อย่างไร้เดียงสากลายเป็นวิธีใหม่ในการผิดพลาด
ลองดูการค้นหา moving-average crossover ที่ตรงไปตรงมา: fast length 16 ค่า slow length 40 ค่า trial แต่ละตัวมี 755 observation grid แบบนี้เปียกโชกไปด้วย correlation — fast=45/slow=120 กับ fast=45/slow=125 แทบจะเป็นกลยุทธ์เดียวกัน ดังนั้น return stream ของมันจึงเคลื่อนไหวไปด้วยกัน average pairwise correlation ที่วัดได้ข้าม 640 trial: ประมาณ 0.61 นั่นไม่ใช่ 640 การเดิมพันที่เป็นอิสระต่อกัน ไม่ใกล้เคียงเลย
Case A — random walk (ไม่มี edge): ทุกวิธีฆ่ามันทิ้ง อย่างถูกต้อง
รัน grid บน pure random walk ผู้ชนะดูล่อตาล่อใจ: params fast=45/slow=120, best Sharpe ต่อปีที่ 0.81, single-test p-value 0.081 ทุกวิธีมองทะลุมันได้:
| Method | ผลลัพธ์ | คำตัดสิน |
|---|---|---|
| DSR (raw K = 640) | 0.431 | ปฏิเสธ (< 0.95) |
| Reality Check p | 0.570 | ปฏิเสธ |
| SPA-type p (studentized RC) | 0.569 | ปฏิเสธ |
| Harvey-Liu haircut | 100% | ปฏิเสธ |
เริ่มจากสัญญาณที่ไม่ต้องการ deflation เลยด้วยซ้ำ: แม้แต่ finite-sample significance ที่ไม่ได้ปรับของผู้ชนะตัวนี้ -vs-zero ก็อยู่ที่แค่ 0.918 — ต่ำกว่า 0.95 อยู่แล้วก่อนที่เราจะแก้ไขแม้แต่หนึ่งใน 640 trial ด้วยซ้ำ Deflation จึงฝังมันลงไปเลย: bar คือ per-observation ซึ่งต่อปีแล้วอยู่ที่ ~0.91 (คำนวณ: ) — สูงกว่า 0.81 ของผู้ชนะ กลยุทธ์ที่ดีที่สุดยังไปไม่ถึง noise ceiling ด้วยซ้ำ DSR ≈ 0.43 (แย่กว่าโยนเหรียญ) และ Reality Check, SPA-type test และ haircut 100% ต่างก็เห็นตรงกันหมด: ไม่มีอะไรที่นี่เลย สมบูรณ์แบบ นี่คือกรณีง่าย และมันได้ผล — และอย่างที่เราจะเห็น มันยังถูกปฏิเสธต่อไปที่ทุก effective-trial count ที่เราลอง
Case B — regime edge ที่แท้จริง: raw DSR ทำผิด
ทีนี้รัน grid เดียวกันบนอนุกรมที่มีการสลับ regime ที่มี edge จริงและใช้ประโยชน์ได้ ผู้ชนะดูชัดเจนมาก: params fast=3/slow=55, best Sharpe ต่อปีที่ 3.92 — นี่คือ Sharpe แบบ in-sample ที่ถูกเลือกมา ซึ่งตัวมันเองก็ถูก selection-inflate โดยการค้นหา (ไม่ใช่ edge ที่แท้จริงหรือ out-of-sample) แต่ผลของ regime ที่อยู่ข้างใต้นั้นเป็นของจริง — พร้อมกับ single-test p-value ที่ และ significance ที่ไม่ได้ deflate -vs-zero อยู่ที่เกือบ 1.000 มี edge จริงอยู่ตรงนี้และผู้ชนะพบมันแล้ว ดูว่า raw DSR ปฏิเสธมันได้ยังไง:
| Method | ผลลัพธ์ | คำตัดสิน |
|---|---|---|
| DSR (raw K = 640) | 0.748 | ปฏิเสธ (< 0.95) ✗ over-deflated |
| Reality Check p | 0.0024 | ยืนยัน ✓ |
| SPA-type p (studentized RC) | 0.0038 | ยืนยัน ✓ |
| Harvey-Liu haircut | 15% | ยืนยัน ✓ |
raw DSR ที่ 0.748 คือการปฏิเสธที่ผิดของ edge จริง เหตุผลคือข้อสมมติเรื่องความเป็นอิสระ ซึ่งถูกละเมิดอย่างหนักในตอนนี้: DSR สร้าง deflated bar ของมันโดยถือว่า 640 trial ที่ correlated กันเป็น 640 การสุ่มที่เป็นอิสระ ซึ่งทำให้ expected-maximum พองขึ้นเป็น per-observation 0.221 — ต่อปีแล้วเป็น ~3.51 (คำนวณ: ) เทียบกับ bar ที่ 3.51 ผู้ชนะที่ 3.92 ข้ามมันได้แค่เล็กน้อย และ DSR ลงเอยที่ 0.748 — ต่ำกว่า 0.95 มีสองสิ่งที่ปั๊ม bar นั้นขึ้น: จำนวนดิบ (640 looks แทนที่จะเป็นจำนวน effective ที่น้อยกว่ามาก) และ การกระจายตัวของฝีมือที่แท้จริงระหว่าง trial — พารามิเตอร์บางคู่ดีกว่าจริง ๆ บนอนุกรมแบบ regime ซึ่งทำให้ กว้างขึ้นและยก ให้สูงเกินกว่าที่ความโชคดีล้วน ๆ จะทำได้ ทั้งสองอย่างดันไปในทางเดียวกัน และ bar จบลงที่สูงเกินไป เพราะการค้นหานี้ไม่เคยเป็น 640 การมองที่เป็นอิสระจริง ๆ เลย มันคือการเดิมพันที่เป็นอิสระเพียงไม่กี่ตัว ที่ถูกสุ่มตัวอย่างซ้ำ 640 ครั้ง
ป้อน DSR ด้วยจำนวน trial แบบ effective แทน one-liner ที่ใช้ข้างต้นเป็นค่าประมาณแบบหยาบจาก average pairwise correlation:
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
ด้วย และ สิ่งนี้ยุบ grid ลงเป็น effective trial (คำนวณ: ) และ DSR กระโดดขึ้นไปที่ 1.000 แต่หยุดก่อนที่จะฉลองตัวเลขนั้น เพราะมันคือหลักฐานที่อ่อนที่สุดในหัวข้อนี้ทั้งหมด ที่ deflated bar ยุบลงเป็น ต่อปี — โดยพื้นฐานแล้วคือค่าเฉลี่ยของ trial แทบจะเป็นศูนย์ deflation ตรงนั้นถูกปิดไปเลย: DSR ที่ เป็นแค่การรายงาน significance แบบ finite-sample ที่ไม่ได้ deflate ของผู้ชนะซ้ำ (-vs-zero ) คำตัดสินสืบทอดมาจาก raw significance ไม่ได้ผลิตจากการแก้ไข multiple-testing และข้อควรระวังแบบภาพสะท้อนในกระจกสำหรับฝั่ง random walk: การปฏิเสธของมันที่ ใช้ได้ก็เพราะผู้ชนะตัวนั้นเป็น marginal อย่างเป็นอิสระอยู่แล้วตั้งแต่ต้น (-vs-zero ) ยึดข้อโต้แย้งทั้งหมดไว้ที่ 1.6 แล้วคนขี้สงสัยก็มีสิทธิ์ยักไหล่: คุณปิดการแก้ไขไปแล้วรายงานสิ่งที่อยู่ข้างใต้
ดังนั้นอย่ายึดกับ estimator ตัวเดียว ท่าที่ซื่อสัตย์ — และแข็งแรงกว่า — คือการคำนวณ ด้วยวิธีมาตรฐานที่ต่างกันห้าวิธี แล้วอ่านคำตัดสินข้าม band ทั้งหมด นี่คือ estimator ทั้งห้าที่ใช้กับ signal grid 640-trial เดียวกัน แต่ละตัวพร้อม deflated bar ที่มันบ่งบอกและ DSR ที่มันผลิตขึ้น:
| Effective-trial estimator | Deflated bar (annual) | DSR | คำตัดสิน | |
|---|---|---|---|---|
| Average correlation | 1.6 | 0.25 | 1.000 | คงไว้ |
| Participation ratio | 2.4 | 0.43 | 1.000 | คงไว้ |
| PCA (95% of variance) | 16 | 1.85 | 1.000 | คงไว้ |
| Kaiser (eigenvalues > 1) | 21 | 2.00 | 0.999 | คงไว้ |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | ปฏิเสธ |
| raw grid count (ไม่ปรับ) | 640 | 3.51 | 0.748 | ปฏิเสธ |
Estimator: average correlation คือ one-liner ข้างต้น; participation ratio และจำนวน PCA-95%/Kaiser อ่าน effective dimensionality จาก eigenvalue ของ correlation matrix; Cheverud-Nyholt คือ estimator แบบ variance-of-eigenvalue จากวรรณกรรมด้าน genetics ที่รู้กันว่า over-count ภายใต้ near-equicorrelation
ตอนนี้ประเด็นเข้าเป้าแล้ว และมันไม่ใช่ "การปรับแบบไหนก็ช่วยคุณได้" ดูที่ตรงกลางที่ป้องกันได้ — PCA-95% () และ Kaiser () นี่ไม่ใช่ regime ที่ deflation ถูกปิด พวกมันบังคับใช้ bar ต่อปีที่แท้จริงอยู่ที่ 1.85 ถึง 2.00 — haircut ที่จริงจัง สูงกว่า noise มาก บทลงโทษ multiple-testing ที่แท้จริงสำหรับ 16-21 effective look และ edge ที่ 3.92 ก็ยังข้ามมันได้ (DSR 1.000 และ 0.999) สัญญาณนี้รอด DSR สำหรับ ใด ๆ ที่ต่ำกว่า 144.8 (คำนวณจากจุดตัด) มันล้มเหลวเฉพาะภายใต้ Cheverud-Nyholt's ซึ่งเป็น estimator ที่พิสูจน์ได้ว่า over-count เมื่อ trial อยู่ใกล้ equicorrelation — และแม้แต่จำนวนดิบที่ไม่ปรับที่ 640 ก็ดัน DSR ลงมาแค่ 0.748 ไม่ใช่ศูนย์ ผู้ชนะของ random-walk เมื่อรันผ่าน estimator ทั้งห้าตัวเดียวกันเป๊ะ ถูกปฏิเสธที่ทุกตัว (มันไม่รอดที่ ใด ๆ ที่สูงกว่า 1 เลย) นั่นคือผลลัพธ์ที่แท้จริง: ไม่ใช่ตัวเลขโชคดีตัวเดียว แต่เป็นคำตัดสินที่เสถียรข้าม band ทั้งหมดของ effective-trial estimator มาตรฐาน — ซึ่งเป็นหลักฐานที่แข็งแรงกว่าการเชื่อ estimator ตัวใดตัวหนึ่งมาก
ข้อควรระวังทางเทคนิคหนึ่งข้อเกี่ยวกับ estimator ที่หยาบที่สุด เพราะมันอธิบายว่าทำไมมันถึงอยู่ที่ปลายด้านอ่อน: แท้จริงแล้วคือ variance-reduction factor สำหรับค่าเฉลี่ยของตัวแปรที่ correlated กัน (การเฉลี่ยซื้ออะไรให้คุณได้บ้างภายใต้ correlation ) benchmark ของ DSR เป็นปริมาณแบบ extreme-value — ค่าคาดหวังของค่าสูงสุดของ trial — ดังนั้นการใช้ mean-variance shrinkage เป็นจำนวน trial ของมันจึงเป็นความไม่เข้ากันเชิงฟังก์ชัน: ถูกทิศทาง (correlated ⇒ effective trial น้อยลง) แต่ไม่ใช่ปริมาณที่ distribution ของค่าสูงสุดขึ้นอยู่จริง ๆ นั่นคือเหตุผลที่แท้จริงว่าทำไม estimator แบบ eigenvalue ที่อยู่ตรงกลางของ band จึงเป็นการอ่านที่น่าเชื่อถือกว่า และทำไม band ไม่ใช่จุดเดียว จึงเป็นสิ่งที่ส่งมอบ
บทเรียน: ใช้เครื่องมือทั้งสองตัว และป้อน DSR ด้วย N ที่ถูกต้อง

สองสิ่งตกออกมาจาก Case B และทั้งคู่ต่างก็แบกรับน้ำหนักไว้:
- ขนาด grid แบบดิบคือ N ที่ผิดสำหรับ DSR เมื่อใดก็ตามที่ trial มี correlation กัน — และไม่มี effective-N ตัวเดียวที่ถูกต้องเช่นกัน การใส่ 640 ลงในสูตรที่สมมติความเป็นอิสระจะ over-deflate: มันผลิต noise ceiling ที่สูงกว่าที่การค้นหาไปถึงจริงมาก และฝัง edge จริงไว้ข้างใต้มัน DSR ต้องการจำนวน trial แบบ effective — แต่วิธีแก้ไม่ใช่การเชื่อ estimator ตัวเดียว (โดยเฉพาะตัวที่หยาบที่สุด ที่การแก้ไขถูกปิดใกล้ ) แต่คือการอ่านคำตัดสินข้าม band ทั้งหมดของ estimator มาตรฐาน (ในที่นี้ 1.6 ถึง 370) แล้วดูว่ามันเสถียรไหม สำหรับ edge นี้มันเสถียร: ถูกคงไว้ทุกที่ที่ deflation ทำงานจริง (annual bar จริงที่ 1.85-2.00 ที่ -) ล้มเหลวเฉพาะภายใต้ estimator ที่ over-count เท่านั้น คำตัดสินที่เสถียรข้าม band แข็งแรงกว่าตัวเลขเดียวใด ๆ มาก
- จับคู่ DSR กับ Reality Check สังเกตว่า Reality Check และญาติแบบ SPA-type (studentized) ของมันได้ Case B ถูกต้องโดยไม่ต้องผ่าตัดจำนวน trial เลย (p = 0.0024 และ 0.0038) — พวกมันจัดการ dependence ได้โดยธรรมชาติ ผ่าน stationary bootstrap เพราะพวกมัน resample return stream ที่ correlated จริง แทนที่จะนับการเดิมพันที่เป็นอิสระตามสมมติฐาน นั่นคือตัวชี้ขาดสำหรับความยุ่งเหยิงของ effective-N ทั้งหมด: RC ไม่ต้องการ เลย DSR และ RC ตอบคำถามที่ต่างกัน: DSR ถามว่า "ผู้ชนะพิเศษภายในการค้นหานี้ไหม?" (และต้องรู้ว่าการค้นหาใช้ effective look กี่ครั้ง); RC/SPA-type ถามว่า "rule ที่ดีที่สุดเอาชนะเงินสดได้ไหมหลัง data-snooping?" (และอ่าน dependence จากข้อมูลเอง) คุณต้องการทั้งคู่ เมื่อพวกมันไม่เห็นตรงกัน — อย่างที่ raw-count DSR และ RC ทำที่นี่ — ความไม่ตรงกันนั้นเป็นการวินิจฉัย: มันมักหมายความว่า ของคุณผิด
นี่คือคำเตือนเชิงโครงสร้างเดียวกับที่การศึกษา speed-ladder และ IPC-tax ของเราเจอซ้ำแล้วซ้ำเล่าจากฝั่ง engineering — การค้นหาที่เร็วซึ่งรัน correlated grid ขนาดใหญ่ไม่ได้ซื้อจำนวนการเดิมพันที่เป็นอิสระจำนวนมากให้คุณ และการถือว่าขนาด grid เป็นจำนวน trial หลอกทั้ง optimizer และ significance test ของคุณ บทความคู่หูที่กำลังจะมาถึงเกี่ยวกับ probability of backtest overfitting โจมตี selection bias เดียวกันจากฝั่ง resampling (CSCV) และจับคู่กับทุกอย่างที่นี่ได้อย่างเป็นธรรมชาติ: DSR ตั้งราคาให้ผู้ชนะ PBO ตั้งราคาให้กระบวนการ
หมายเหตุความซื่อสัตย์
ข้อควรระวังสามข้อ กล่าวอย่างตรงไปตรงมา เพราะประเด็นทั้งหมดของการศึกษาแบบควบคุมคือการไม่โอ้อวดมันเกินจริง
- ผลตอบแทนเป็นแบบ synthetic iid Normal สำหรับการทดลอง calibration และ power, regime-switching process สำหรับกรณี genuine-edge — เลือกมาเพื่อ controlled ground truth ไม่ใช่เพื่อความสมจริงของตลาด ผลตอบแทนจริงมี fat tail, autocorrelated และ non-stationary และเทอม skew/kurtosis ของ PSR มีอยู่ก็เพื่อจัดการกับข้อแรกนั้นโดยเฉพาะ สิ่งที่ส่งมอบที่นี่คือวิธีที่ผ่านการ calibrate ไม่ใช่กลยุทธ์: เราพิสูจน์ได้ว่า test ควบคุม false discovery ได้ก็ต่อเมื่อรันมันบนข้อมูลที่เรารู้ว่าไม่มีอะไรให้ค้นพบเท่านั้น สิ่งนั้นต้องการการสร้าง ground truth ขึ้นมา
- ไม่มี effective-N estimator ตัวไหนเป็น canonical — นั่นคือเหตุผลที่เรารายงานห้าตัว one-liner ของ average-correlation นั้นอ่านง่ายสำหรับ reviewer และถูกทิศทาง (correlation มากขึ้น ⇒ effective trial น้อยลง) แต่มันคือ variance-reduction factor สำหรับค่าเฉลี่ย — ความไม่เข้ากันเชิงฟังก์ชันกับ benchmark แบบค่าสูงสุดของ DSR — และใกล้ มันปิด deflation ไปเลยทั้งหมด eigenvalue estimator (participation ratio, PCA-95%, Kaiser) เข้ากันได้ดีกว่าแต่ก็ยังเป็น heuristic และ Cheverud-Nyholt over-count ภายใต้ equicorrelation แนวทางที่สมบูรณ์กว่าและมีหลักการคือ trial clustering (Bailey & López de Prado's DSR Appendix 3): จัดกลุ่ม trial ตามโครงสร้าง correlation แล้วนับ cluster แทนที่จะยุบทุกอย่างเป็น scalar เดียว เรารายงาน band ทั้งหมดก็เพราะทางเลือกยังไม่ได้ข้อสรุป — คำตัดสินที่เสถียรข้าม estimator ทั้งห้าตัวคือคำกล่าวอ้างที่ซื่อสัตย์; คำกล่าวอ้างที่ขึ้นอยู่กับการเลือก estimator ตัวเดียวจะไม่ใช่
- bootstrap คือ studentized Reality Check ไม่ใช่ Hansen SPA แบบเต็ม และจำนวน resample ต่างกันไปตามการทดลอง ไม่ว่าบทความนี้จะพูดว่า "SPA-type" ตรงไหน มันหมายถึง White's Reality Check ที่มี studentization แบบ per-rule; consistent recentering แบบ sample-dependent ของ Hansen แบบเต็มไม่ได้ถูก implement false-discovery rate ของ calibration ใช้ stationary-bootstrap resample 500 ครั้งต่อการค้นหา ข้าม 400 การค้นหา; p-value ของ RC/SPA-type ทั้งสองใน case study ใช้ 5,000 resample ต่อครั้ง ความยาว block เฉลี่ย 20 ตลอดทั้งบทความ (Politis-Romano), , 252 period/ปี สำหรับการแปลงเป็นรายปี เปลี่ยนสิ่งเหล่านี้แล้วตัวเลขทศนิยมตำแหน่งที่สามจะขยับ; แต่เรื่องราว — naive 1.000 เทียบกับ principled 0.001-0.057, เส้นโค้ง S ที่ไปถึง 50% power เหนือ noise ceiling เล็กน้อย และกับดัก correlated-grid ที่คำตัดสินต้องอ่านข้าม effective-N band — จะไม่เปลี่ยน
สรุปประเด็นสำคัญ
- parameter search คือเครื่องจักร multiple-testing และ naive significance test มองไม่เห็นมัน บนกลยุทธ์ zero-edge 1,000 ตัว best Sharpe ต่อปีเฉลี่ยอยู่ที่ 1.63 พร้อม single-test p-value มัธยฐานที่ 0.000686 — และ test "มันมีนัยสำคัญไหม?" ประกาศการค้นพบ 100% ของเวลา (false-discovery rate 1.000) Sharpe ที่ดีเยี่ยมจากความว่างเปล่า ได้รับการรับรองว่ามีนัยสำคัญโดย test ที่ไม่เคยถามคำถามที่ถูกต้องเลย
- Deflated Sharpe Ratio ย้ายเส้นประตูจากศูนย์ไปที่ noise ceiling DSR เปรียบเทียบผู้ชนะไม่ใช่กับศูนย์ แต่กับ ซึ่งคือ expected best-by-luck ของการค้นหาขนาดนี้ — ซึ่งสำหรับกรณี null ลงเอยที่ 1.63 ต่อปี ตรงจุดที่ผู้ชนะ noise เฉลี่ยอยู่พอดี (คำนวณ: ) null false-discovery rate ของมันคือ 0.001; Harvey-Liu haircut (Bonferroni/Holm 0.057, BHY 0.007) และ White's Reality Check (0.022) ไปถึงการควบคุมแบบเดียวกันด้วยเส้นทางอื่น
- มันเก็บ edge จริงไว้ได้ detection power ของ DSR ลากเป็นเส้นโค้ง S ที่ไปถึง 50% power ที่ Sharpe ต่อปี ~1.73 — เหนือ noise ceiling ที่ 1.63 เล็กน้อย: 0.005 ที่ true Sharpe ต่อปี 0.79, 0.651 ที่ 1.90, 0.998 ที่ 2.54, 1.000 ที่ 3.17, false positive ~0 ตลอด edge ที่ต่ำกว่า ceiling ถูกตัดสินอย่างถูกต้องว่าแยกไม่ออกจากความโชคดี; edge ที่สูงกว่ามันถูกเก็บไว้ด้วย power ที่เข้าใกล้หนึ่ง
- correlated grid ทำลาย raw DSR — และไม่มี effective-N ตัวเดียวช่วยมันได้ band เท่านั้นที่ช่วยได้ บน MA crossover 640-cell (average pairwise correlation ~0.61) raw-count DSR ปฏิเสธ edge จริง (in-sample selected, annual 3.92) อย่างผิดพลาด (0.748 < 0.95) เพราะ 640 trial ที่ correlated กันไม่ใช่ 640 การเดิมพันที่เป็นอิสระ แต่วิธีแก้ไม่ใช่ วิเศษตัวเดียว — ที่การประมาณแบบหยาบที่สุด () deflation ถูกปิดไปแทบทั้งหมด (bar ~annual 0.25) และ DSR ก็แค่สะท้อน raw significance หลักฐานที่แท้จริงคือ edge ถูกคงไว้ข้าง band ทั้งหมดของ estimator มาตรฐาน — DSR 1.000/1.000/1.000/0.999 ที่ 1.6/2.4/16/21 รวมถึง annual bar จริงที่ 1.85-2.00 ที่ PCA-95%/Kaiser mid-range ที่ป้องกันได้ — รอดสำหรับ ใด ๆ และล้มเหลวเฉพาะภายใต้ Cheverud-Nyholt ที่ over-count ที่ 370 random walk ถูกปฏิเสธที่ทุก estimator อ่าน band ไม่ใช่จุดเดียว
- จับคู่ DSR กับ Reality Check เพราะพวกมันตอบคำถามที่ต่างกัน Reality Check และญาติแบบ SPA-type (studentized) ของมันยืนยัน edge จริง (p = 0.0024 และ 0.0038) โดยไม่ต้องผ่าตัดจำนวน trial เลย — พวกมันจัดการ dependence ได้โดยธรรมชาติผ่าน stationary bootstrap ซึ่งเป็นตัวชี้ขาดพอดีเมื่อ effective-N ยังเป็นที่ถกเถียง DSR ถามว่า "ผู้ชนะพิเศษภายในการค้นหานี้ไหม?"; RC/SPA-type ถามว่า "ตัวที่ดีที่สุดเอาชนะเงินสดได้ไหมหลัง data-snooping?" ความไม่ตรงกันระหว่างพวกมันคือสัญญาณว่า ของคุณผิด รันทั้งคู่
ผู้ชนะของการค้นหามีความผิดจนกว่าจะพิสูจน์ได้ว่าบริสุทธิ์ naive p-value ไม่ใช่หลักฐานความบริสุทธิ์ — มันคือคำให้การที่พองขึ้นเองของการค้นหา และมันจะรับรอง pure noise ด้วยความเชื่อมั่นศูนย์สิบสองตัว Deflate benchmark ให้เป็นสิ่งที่ความโชคดีส่งมอบให้ นับ effective trial ของคุณอย่างซื่อสัตย์ และ bootstrap ค่าสูงสุดเพื่อขอความเห็นที่สอง สิ่งที่ข้าม bar ทั้งสามได้อาจจะเป็นของจริง สิ่งที่ข้ามได้แค่ bar แบบ naive คือคนที่สูงที่สุดในกลุ่มคนโยนเหรียญพันคน
การทดลองแบบเต็ม — harness สำหรับ null-calibration, การไล่ power ของ planted-edge, การค้นหา correlated-grid และตัวเลขทุกตัวในบทความนี้ที่สร้างซ้ำได้จากสคริปต์ deterministic ตัวเดียว — อยู่ในเปเปอร์คู่หูที่ deflated-sharpe.marketmaker.cc พร้อมโค้ดและข้อมูลที่ github.com/suenot/deflated-sharpe-search
ผู้เขียน

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
อ่านเพิ่มเติม

Probability of Backtest Overfitting: การค้นหาของคุณเอาชนะการโยนเหรียญหรือไม่?

การออกแบบ Objective Function: ตัวชี้วัดที่คุณ Optimize แอบเลือกกลยุทธ์ให้คุณ
