Deflated Sharpe Ratio: Berapa Banyak 'Pemenang' Backtest Anda Terselamat daripada Ujian Berganda?
Sebahagian daripada siri "Backtest Tanpa Ilusi".
📄 Artikel ini berkembang menjadi kertas penyelidikan. Setiap nombor di bawah datang daripada satu skrip deterministik tunggal yang membina ground truth terkawal — carian bunyi hingar tulen, carian kelebihan yang ditanam, dan satu grid parameter berkorelasi sebenar — kemudian menjalankan Deflated Sharpe Ratio, haircut ujian berganda Harvey-Liu, dan Reality Check White / SPA Hansen terhadapnya, mengukur kadar penemuan palsu dan kuasa pengesanan setiap kaedah secara langsung. Baca kertas kerja dalam talian (versi interaktif + PDF) di deflated-sharpe.marketmaker.cc, kod dan data di github.com/suenot/deflated-sharpe-search.
Anda menjalankan satu sapuan parameter (parameter sweep). Enam belas panjang pantas, empat puluh panjang perlahan, 640 kombinasi silangan purata bergerak (moving-average crossover). Grid itu selesai dan satu sel bersinar: Sharpe tahunan 3.9, p-value ujian tunggal . Dua belas sifar keertian. Anda telah menemui sesuatu.
Atau anda tidak menemui apa-apa, dan carian itu yang menemuinya untuk anda.
Satu carian parameter bukanlah satu ujian. Ia adalah mesin untuk mencari yang paling bertuah daripada N percubaan, dan semakin banyak percubaan yang anda berikan kepadanya, semakin bertuah pemenangnya kelihatan — dengan atau tanpa sebarang kelebihan sebenar di bawahnya. Sharpe terbaik-daripada-N digembungkan oleh pemilihan dengan cara yang sama seperti orang paling tinggi daripada seribu orang rawak adalah tinggi: bukan kerana ketinggian itu sebenar, tetapi kerana anda mencari. Statistik ujian tunggal yang dicetak di sebelah pemenang — p-value-nya, statistik-t-nya, "adakah ia signifikan?" — direka untuk satu hipotesis yang didaftarkan terlebih dahulu. Suapkan statistik itu kepada mangsa yang terselamat daripada satu carian dan ia akan berbohong, dengan yakin, setiap kali.
Artikel ini mengukur dengan tepat betapa buruknya ia berbohong, kemudian mengukur tiga alat yang membetulkannya. Keseluruhan intinya adalah ground truth terkawal: kami menjana pulangan di mana kami tahu jawapannya — kadangkala bunyi hingar tulen dengan kelebihan sifar, kadangkala kelebihan yang ditanam dengan kekuatan yang diketahui — supaya "adakah kaedah itu betul?" adalah satu fakta, bukan pertimbangan. Berikut adalah berita utama terlebih dahulu. Pada carian null yang diketahui, di mana jawapan jujur sentiasa "tiada penemuan", inilah kekerapan setiap ujian menangis serigala:
| Ujian | Kadar penemuan palsu pada carian null yang diketahui | Keputusan |
|---|---|---|
| Ujian naif "adakah Sharpe terbaik signifikan?" | 1.000 | menandakan penemuan setiap kali |
| Deflated Sharpe Ratio (DSR ≥ 0.95) | 0.001 | terkawal |
| Haircut Harvey-Liu — Bonferroni | 0.057 | ~terkawal |
| Haircut Harvey-Liu — Holm | 0.057 | ~terkawal |
| Haircut Harvey-Liu — BHY | 0.007 | terkawal |
| Reality Check White (bootstrap) | 0.022 | terkawal |
1,000 strategi setiap carian, 1,000 pemerhatian setiap satu, 2,000 carian null bebas, Sharpe sebenar = 0 di mana-mana. Pulangan Normal iid sintetik, seed 0, α = 0.05, 252 tempoh/tahun. Kadar penemuan palsu ujian naif bukan tinggi — ia tepat satu.
Baca baris pertama sehingga ia menyakitkan. Satu ujian yang sepatutnya menyala 5% daripada masa pada bunyi hingar tulen menyala 100% daripada masa — kerana anda tidak menunjukkan kepadanya bunyi hingar tulen, anda menunjukkan kepadanya maksimum daripada seribu cabutan bunyi hingar tulen, dan maksimum daripada seribu penyambit syiling sentiasa kelihatan seperti genius. Setiap baris lain adalah kaedah yang tahu akan hal ini dan membetulkannya. Inilah keseluruhan artikel: mengapa baris pertama adalah 1.000, mengapa yang lain tidak, dan satu tempat (bahagian terakhir) di mana walaupun kaedah yang baik memerlukan pembetulan kedua untuk kekal jujur.
Babak 1 — Perangkap: satu carian menghasilkan Sharpe daripada ketiadaan

Mulakan dengan perangkap paling bersih yang mungkin. Jana strategi yang pulangannya adalah bunyi hingar standard-Normal bebas — tiada drift, tiada kemahiran, Sharpe sebenar tepat sifar untuk kesemuanya. Setiap satu mempunyai pemerhatian. Sekarang lakukan apa yang dilakukan oleh setiap carian parameter: simpan yang terbaik.
Sharpe setiap-pemerhatian terbaik-daripada-1000 purata 0.1027, yang ditahunkan kepada 1.63 (terbitan: ). Itu bukan nombor yang sederhana. Sharpe tahunan 1.63 adalah jenis keputusan yang mendapat pembiayaan strategi, ditulis, diperuntukkan. Ia datang daripada penjana nombor rawak dengan drift ditetapkan kepada sifar.
Sekarang serahkan pemenang itu kepada ujian signifikan naif — yang dicetak percuma oleh setiap pustaka backtest. Tukarkan Sharpe-nya kepada statistik-t (), ambil p-value sehala, panggil ia penemuan jika :
P-value ujian tunggal median bagi pemenang bunyi hingar ini adalah 0.000686 — tiga sifar "keertian" daripada strategi tanpa kelebihan. Dan merentasi 2,000 carian null bebas, ujian naif mengisytiharkan penemuan dalam setiap satu daripadanya: kadar penemuan palsu 1.000. Bukan "digembungkan." Bukan "agak tinggi." Satu ujian yang betul, mengikut binaan, paling banyak 5% daripada masa pada satu hipotesis null tunggal adalah salah 100% daripada masa pada pemenang satu carian.
Mekanismenya tidak halus sebaik sahaja dinamakan. Ujian naif bertanya "bolehkah Sharpe ini timbul secara kebetulan di bawah null?" — soalan yang adil untuk strategi yang anda pilih sebelum melihat data. Tetapi anda memilih yang ini kerana ia mempunyai Sharpe tertinggi daripada seribu. Anda telah bersyarat pada maksimum, dan taburan persampelan bagi maksimum tidak sama sekali seperti taburan persampelan bagi satu cabutan tunggal. Ini adalah penyakit yang sama yang didiagnosis oleh taksonomi look-ahead bias kami daripada hujung yang lain — di sana, satu kebocoran satu-bar menghasilkan Sharpe 15 daripada bunyi hingar; di sini, satu carian menghasilkan Sharpe 1.63 daripada bunyi hingar tanpa sebarang kebocoran langsung, semata-mata melalui pemilihan. Mekanisme berbeza, gejala serupa: Sharpe yang kelihatan hebat tetapi tidak bermakna apa-apa.
Nombor 1.63 adalah yang penting, jadi berpegang padanya. Ia adalah siling bunyi hingar untuk carian ini: Sharpe yang sepatutnya anda jangkakan daripada yang paling bertuah antara 1,000 strategi kelebihan-sifar. Sebarang ujian jujur bagi pemenang carian perlu membandingkannya bukan dengan sifar, tetapi dengan ini — dengan apa yang nasib baik sahaja hasilkan apabila anda melihat seribu kali.
Babak 2 — Kit alat: tiga cara untuk menilai carian

Tiga program penyelidikan, tiba secara bebas, semuanya mencapai pembetulan yang sama: berhenti membandingkan pemenang dengan sifar, dan mula membandingkannya dengan apa yang dihasilkan oleh carian bersaiz ini secara kebetulan. Mereka berbeza dalam cara mereka membina perbandingan itu.
PSR dan Deflated Sharpe Ratio (Bailey & López de Prado, 2012 / 2014)
Probabilistic Sharpe Ratio bertanya soalan yang lebih tajam daripada "adakah Sharpe positif?" Ia bertanya: memandangkan panjang sampel dan bentuk pulangan (skew, ekor tebal), apakah kebarangkalian Sharpe sebenar melebihi penanda aras ?
Di sini ialah CDF standard-Normal, ialah skew, dan ialah kurtosis dalam konvensyen bukan-lebihan (Normal ⇒ ; gantikan kurtosis lebihan di sini tanpa menambah 3 dan deflasi itu akan tersalah). Tetapkan dan PSR hanyalah ujian keertian sampel-terhingga. Keajaibannya terletak pada memilih dengan baik.
Deflated Sharpe Ratio ialah PSR yang dinilai pada penanda aras yang bukan sifar tetapi Sharpe maksimum yang dijangka bagi keseluruhan carian:
di mana ialah varians merentasi kesemua N Sharpe percubaan (penyebaran yang dihasilkan oleh carian itu sendiri), ialah pemalar Euler-Mascheroni, dan dua terma inverse-Normal itu adalah penghampiran Extreme-Value Theory kepada maksimum yang dijangka bagi cabutan standard-Normal. Dalam kod ia hampir terlalu pendek untuk mengagumkan:
def expected_max_sharpe(sr_variance, N, mean_sr=0.0):
"""E[max of N independent SR estimates ~ N(mean_sr, sr_variance)]
(Bailey & LdP 2014)."""
g = EULER_MASCHERONI # 0.5772156649
a = norm.ppf(1.0 - 1.0 / N) # Z^{-1}(1 - 1/N)
b = norm.ppf(1.0 - 1.0 / (N * E)) # Z^{-1}(1 - 1/(N e))
return float(mean_sr + np.sqrt(sr_variance) * ((1.0 - g) * a + g * b))
Kemudian DSR hanyalah PSR dengan bar yang dideflasi itu:
def deflated_sharpe(sr_max, sr_estimates, T, skew=0.0, kurt=3.0, N=None):
"""DSR = PSR(sr_max, SR0). Returns (dsr, sr0)."""
v = float(np.asarray(sr_estimates).var(ddof=1)) # dispersion of the search
m = float(np.asarray(sr_estimates).mean())
if N is None:
N = len(sr_estimates)
sr0 = expected_max_sharpe(v, N, mean_sr=m)
return psr(sr_max, sr0, T, skew, kurt), sr0
DSR ialah satu kebarangkalian. Kami mengisytiharkan penemuan apabila : Sharpe sebenar pemenang mengatasi terbaik-secara-nasib-baik yang dijangka dengan keyakinan 95%. Perhatikan andaian galas-beban yang terkandung dalam : percubaan itu dianggap bebas. Babak 5 keseluruhannya tentang apa yang berlaku apabila ia tidak bebas.
Haircut Harvey-Liu (2015)
Harvey dan Liu menyerang masalah yang sama melalui pelarasan p-value ujian berganda — jentera klasik untuk "saya menjalankan M ujian, jangan biarkan saya menipu diri sendiri." Susun p-value ujian tunggal dan gembungkannya:
Bonferroni adalah instrumen kasar (kawal kebarangkalian sebarang positif palsu dengan mendarabkan setiap p-value dengan ); Holm adalah sepupu step-down yang lebih berkuasa secara seragam. Yang ketiga, Benjamini-Yekutieli (BHY), mengawal kadar penemuan-palsu — pecahan yang dijangka daripada penolakan anda yang salah — dan, secara kritikal, melakukannya di bawah kebergantungan sewenang-wenangnya antara ujian, menggunakan penormal harmonik dalam pengangka:
itu adalah harga yang dikenakan BHY kerana tidak menganggap 1,000 percubaan anda bebas — ia menggembungkan ambang FDR dengan faktor yang berkembang seperti . "Haircut" itu sendiri adalah metrik penutup: tukarkan p-value yang dilaraskan kembali kepada Sharpe dan laporkan berapa banyak Sharpe asal yang perlu anda cukur. Haircut 100% bermaksud pemenang sepenuhnya dijelaskan oleh ujian berganda; 15% bermaksud ia kekal sebahagian besarnya.
Reality Check White dan SPA Hansen (2000 / 2005)
Alat ketiga tidak membuat sebarang andaian taburan langsung. Reality Check White mengambil pulangan sebenar setiap peraturan, membentuk statistik maksimum-merentasi-peraturan, dan melakukan bootstrap ke atas taburan null-nya secara langsung:
di mana ialah prestasi purata peraturan berbanding penanda aras. Ia mensampel semula pulangan dengan stationary bootstrap (Politis-Romano — blok panjang rawak supaya korelasi bersiri terselamat daripada pensampelan semula), memusatkan semula setiap cabutan untuk memenuhi null mengikut binaan, mengira semula maksimum pada setiap cabutan, dan melaporkan p-value sebagai pecahan maksimum bootstrap yang mengatasi yang diperhatikan. SPA Hansen mempertajamkan RC dalam dua cara: studentization (bahagikan purata setiap peraturan dengan ralat piawainya sendiri, supaya satu peraturan varians-tinggi yang liar tidak dapat merampas maksimum itu) dan pemusatan semula yang konsisten dan bergantung-sampel bagi null. Pelaksanaan kami menambah studentization tetapi bukan langkah pemusatan-semula-konsisten yang penuh — jadi di mana sahaja artikel ini melaporkan p-value jenis-SPA, bacalah ia sebagai Reality Check yang di-studentize, bukan SPA Hansen yang lengkap. Di mana DSR bertanya "adakah pemenang istimewa dalam carian ini?", Reality Check bertanya "adakah peraturan terbaik mengatasi tunai selepas mengambil kira dengan jujur berapa banyak peraturan yang saya cuba?" — dan ia mengendalikan peraturan berkorelasi secara semula jadi, melalui bootstrap, tanpa pernah mengira percubaan. Simpan perbezaan itu; bahagian terakhir bergantung padanya.
Babak 3 — Penentukuran adalah keseluruhan bukti
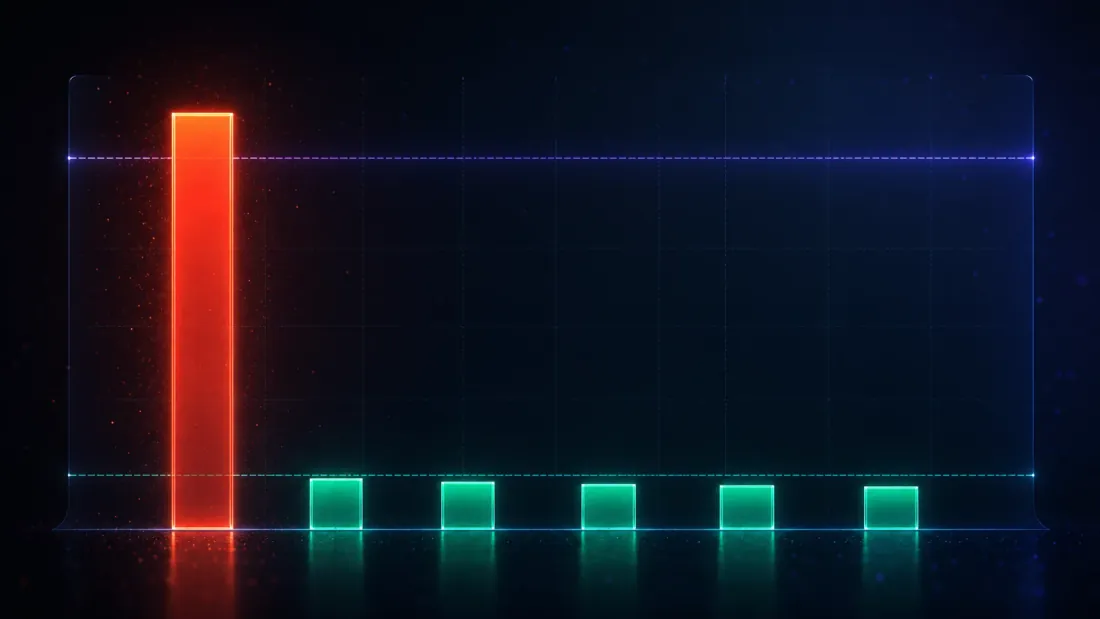
Kaedah yang tidak menandakan apa-apa juga akan mempunyai kadar penemuan palsu sifar — dan menjadi tidak berguna. Jadi satu-satunya ujian bermakna bagi alat ini adalah ujian dua hala: pada data null yang diketahui ia mesti mengawal penemuan palsu pada atau di bawah , dan pada data kelebihan yang diketahui (bahagian seterusnya) ia mesti masih menyala. Bahagian ini adalah separuh pertama.
Jalankan 2,000 carian bebas, setiap satu merentasi 1,000 strategi kelebihan-sifar, dan kira berapa kerap setiap kaedah mengisytiharkan penemuan. Kiraan itu, dibahagikan dengan 2,000, adalah kadar penemuan palsu — dan kerana kebenarannya tiada kelebihan, setiap penemuan adalah palsu:
| Ujian | Kadar penemuan palsu (α = 0.05) |
|---|---|
| Keertian naif | 1.000 |
| Deflated Sharpe Ratio | 0.001 |
| Harvey-Liu — Bonferroni | 0.057 |
| Harvey-Liu — Holm | 0.057 |
| Harvey-Liu — BHY | 0.007 |
| Reality Check White | 0.022 |
Setiap kaedah berprinsip mendarat pada atau berhampiran garis 5% — dua haircut FWER sedikit di atasnya, DSR/BHY/RC di bawahnya — manakala ujian naif duduk pada 100. (Bonferroni dan Holm mencetak 0.057 yang sama di sini, dan bukan secara kebetulan: untuk strategi terbaik tunggal, langkah pertama Holm ialah , sama dengan Bonferroni mengikut binaan, jadi ia adalah satu pengesahan, bukan dua.) Tetapi nombor paling mendalam dalam keseluruhan kajian ini tidak berada dalam jadual ini — ia adalah penanda aras yang dideflasi yang menghasilkan lajur DSR. Purata merentasi carian null, keluar pada setiap-pemerhatian 0.1030, yang ditahunkan kepada 1.63 (terbitan: ) — 1.63 yang sama yang dicetak oleh purata pemenang bunyi hingar (1.63). Itu bukan kebetulan; itu adalah keseluruhan idea itu berfungsi:
Bar yang dideflasi terletak tepat pada siling bunyi hingar. DSR tidak meminta pemenang carian mengatasi sifar. Ia meminta pemenang mengatasi skor terbaik yang dihasilkan oleh nasib baik sahaja daripada carian bersaiz ini — 1.63 ditahunkan di sini. Pemenang yang hanya menyamai siling bunyi hingar mendapat skor DSR ≈ 0.5 (lambungan syiling), itulah sebabnya DSR null purata adalah 0.495, bukan sesuatu yang kecil. Untuk menjadi penemuan, pemenang mesti mengatasi 1.63 dan lebih lagi — cukup untuk menolak PSR melepasi 0.95.
Ini membingkai semula keseluruhan latihan itu. Ujian naif mengukur jarak daripada sifar; setiap carian mengatasi bar itu dengan mudah, itulah sebabnya ia tidak berguna. DSR mengukur jarak daripada siling bunyi hingar, dan mengatasi bar itu benar-benar sukar — sepatutnya begitu. Haircut Harvey-Liu dan Reality Check mencapai kawalan yang sama melalui jalan berbeza (penggembungan untuk BHY, taburan-maksimum bootstrap untuk RC), dan mendarat di kawasan yang sama: 0.001 hingga 0.057, pada atau berhampiran . Bonferroni/Holm 0.057 sedikit melebihi garis 5%, tetapi hanya sedikit sahaja: dengan 2,000 carian Monte-Carlo, ralat piawai pada anggaran FDR berhampiran 0.05 adalah kira-kira 0.005, jadi 0.057 duduk kira-kira 1.4 ralat piawai di atas — bunyi hingar Monte-Carlo, bukan jaminan yang rosak. "Mengawal FWER" adalah janji asimptotik walau bagaimanapun, bukan janji tepat-bit pada .
Babak 4 — Kuasa: adakah ia masih mengekalkan kelebihan sebenar?
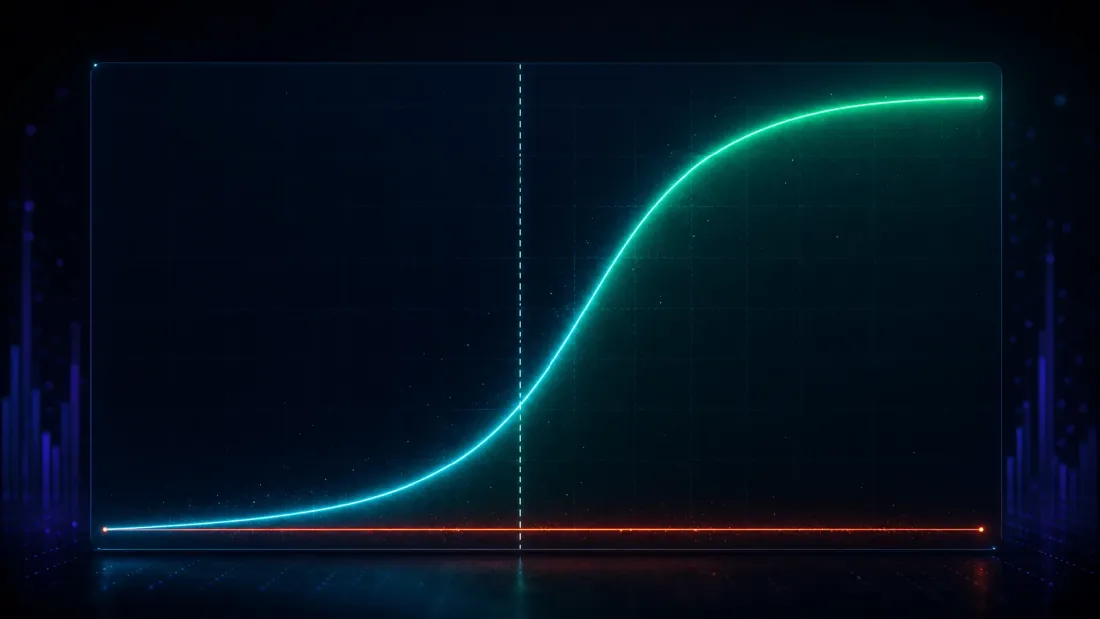
Mengawal penemuan palsu hanyalah separuh ujian — satu kaedah paranoid yang menolak segala-galanya mendapat skor sempurna 0.000 dan tidak berguna. Separuh lagi: apabila kelebihan sebenar memang ada, adakah DSR menemuinya?
Tanam satu. Dalam medan 1,000 strategi, jadikan 25 daripadanya membawa kelebihan sebenar dengan kekuatan yang diketahui dan biarkan selebihnya sebagai bunyi hingar, kemudian jalankan carian itu dan tanya sama ada DSR menandakan pemenang. Imbas kelebihan yang ditanam daripada lemah kepada kuat dan kuasa pengesanan mengesan keluk-S yang bersih (kadar positif-palsu ditahan pada ~0 sepanjang masa):
| Sharpe sebenar yang ditanam (tahunan) | Kuasa pengesanan DSR | Kadar positif-palsu DSR |
|---|---|---|
| 0.79 | 0.005 | 0.000 |
| 1.27 | 0.090 | 0.000 |
| 1.90 | 0.651 | 0.000 |
| 2.54 | 0.998 | 0.000 |
| 3.17 | 1.000 | 0.000 |
Lihat di mana keluk itu berbelok. Di bawah siling bunyi hingar — Sharpe tahunan sebenar 0.79, jauh di bawah 1.63 — DSR menyala 0.5% daripada masa, dengan betul enggan mengisytiharkannya: kelebihan yang selemah itu benar-benar tidak dapat dibezakan daripada nasib baik yang dihasilkan oleh carian 1,000-percubaan, dan berpura-pura sebaliknya adalah tidak jujur, bukan berkuasa. Betul-betul di sekitar siling itu, keluk itu meningkat curam (0.09 pada 1.27, 0.65 pada 1.90). Menjelang Sharpe tahunan 2.54, kuasa itu 0.998; menjelang 3.17 ia adalah 1.000 yang sempurna. Kelebihan yang kuat dikekalkan pada dasarnya setiap kali, positif palsu kekal tersemat pada sifar, dan persilangan kuasa 50% terletak pada Sharpe tahunan kira-kira 1.73 (terbitan melalui interpolasi antara baris 1.27 dan 1.90) — tepat di atas siling bunyi hingar 1.63, tepat di mana bar jujur sepatutnya meletakkannya: titik di mana kelebihan mula mengatasi apa yang direka oleh carian 1,000-percubaan.
Itulah sifat yang sebenarnya anda inginkan, dinyatakan sebagai keluk-S: kelebihan di bawah siling bunyi hingar dengan betul disingkirkan sebagai nasib baik; kelebihan yang jauh di atasnya dikekalkan dengan kuasa menghampiri satu. Ujian naif, sebagai perbandingan, "mengesan" kelebihan yang ditanam 67% daripada masa walaupun pada Sharpe sebenar 0.79 — tetapi nombor itu tidak bermakna, kerana kita sudah lihat ia mengesan kelebihan yang tidak wujud 100% daripada masa. Ujian yang menyala pada segala-galanya tidak mempunyai kuasa; ia tidak mempunyai diskriminasi. DSR menukar sedikit sensitiviti kepada kelebihan marginal (baris 0.79 dan 1.27) dengan perkara yang penting: penemuannya adalah sebenar.
Babak 5 — Perangkap pengamal: grid berkorelasi
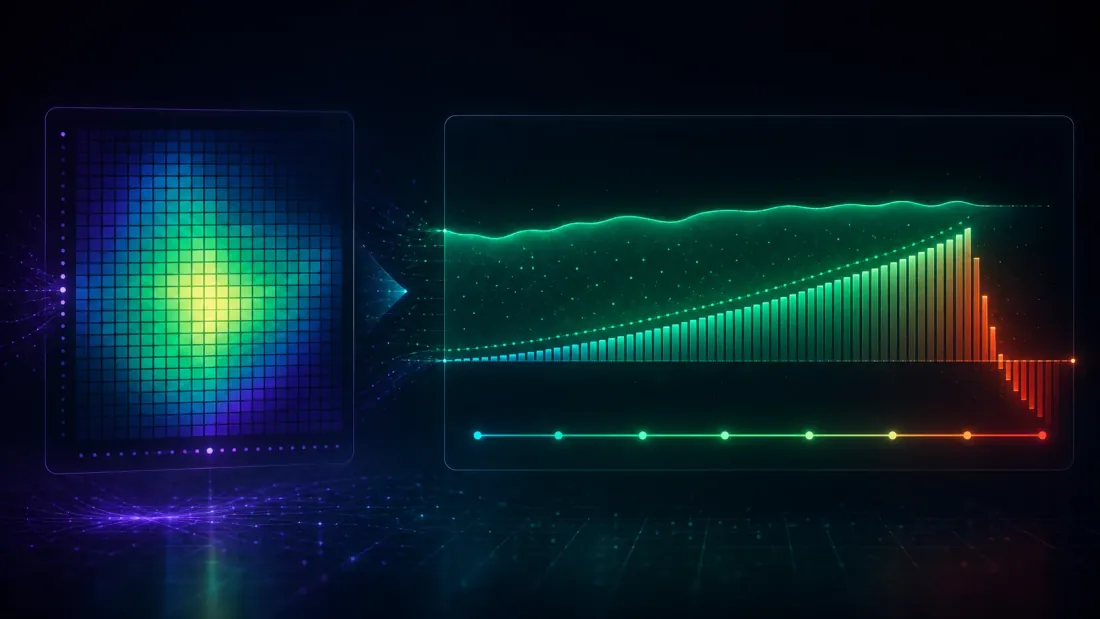
Segala-galanya setakat ini menggunakan strategi bebas — persekitaran paling bersih yang mungkin, dan yang mana andaian kebebasan DSR berpegang dengan tepat. Grid parameter sebenar tidak begitu, dan di sinilah satu alat yang digunakan secara naif menjadi satu cara baharu untuk salah.
Ambil satu carian silangan purata bergerak yang jujur: 16 panjang pantas 40 panjang perlahan percubaan, setiap satu 755 pemerhatian. Grid seperti ini dibasahi dengan korelasi — fast=45/slow=120 dan fast=45/slow=125 hampir strategi yang sama, jadi aliran pulangan mereka bergerak bersama. Korelasi berpasangan purata yang diukur merentasi 640 percubaan: kira-kira 0.61. Itu bukan 640 taruhan bebas. Langsung tidak.
Kes A — jalan rawak (tiada kelebihan): setiap kaedah membunuhnya, dengan betul
Jalankan grid itu pada jalan rawak tulen. Pemenang itu kelihatan menggoda: parameter fast=45/slow=120, Sharpe tahunan terbaik 0.81, p-value ujian tunggal 0.081. Setiap kaedah melihat menembusinya:
| Kaedah | Hasil | Keputusan |
|---|---|---|
| DSR (K mentah = 640) | 0.431 | tolak (< 0.95) |
| p Reality Check | 0.570 | tolak |
| p jenis-SPA (RC di-studentize) | 0.569 | tolak |
| Haircut Harvey-Liu | 100% | tolak |
Mulakan dengan tanda yang tidak memerlukan sebarang deflasi langsung: walaupun keertian sampel-terhingga yang tidak dilaraskan bagi pemenang ini, -berbanding-sifar, hanya 0.918 — sudah kurang daripada 0.95 sebelum kita membetulkan walaupun satu daripada 640 percubaan itu. Deflasi kemudian mengebumikannya: bar itu adalah setiap-pemerhatian 0.057, tahunan ~0.91 (terbitan: ) — di atas 0.81 pemenang itu. Strategi terbaik itu tidak pun mencapai siling bunyi hingar, DSR ≈ 0.43 (lebih teruk daripada lambungan syiling), dan Reality Check, ujian jenis-SPA, dan haircut 100% semuanya bersetuju: tiada apa-apa di sini. Sempurna. Ini adalah kes mudah, dan ia berfungsi — dan, seperti yang akan kita lihat, ia kekal ditolak pada setiap kiraan cubaan-berkesan yang kita cuba.
Kes B — kelebihan rejim sebenar: DSR mentah tersilap
Sekarang jalankan grid yang sama pada satu siri regime-switching yang membawa kelebihan sebenar yang boleh dieksploitasi. Pemenang itu tegas: parameter fast=3/slow=55, Sharpe tahunan terbaik 3.92 — ini adalah Sharpe in-sample, terpilih, yang sendiri digembungkan-pemilihan oleh carian itu (bukan kelebihan sebenar atau out-of-sample), tetapi kesan rejim yang mendasarinya adalah tulen — dengan p-value ujian tunggal dan keertian -berbanding-sifar yang tidak dilaraskan pada dasarnya 1.000. Terdapat kelebihan sebenar di sini dan pemenang itu menemuinya. Perhatikan DSR mentah menolaknya walaupun begitu:
| Kaedah | Hasil | Keputusan |
|---|---|---|
| DSR (K mentah = 640) | 0.748 | tolak (< 0.95) ✗ terlebih-deflasi |
| p Reality Check | 0.0024 | sahkan ✓ |
| p jenis-SPA (RC di-studentize) | 0.0038 | sahkan ✓ |
| Haircut Harvey-Liu | 15% | sahkan ✓ |
DSR mentah 0.748 adalah penolakan palsu bagi kelebihan sebenar. Sebabnya adalah andaian kebebasan, kini dilanggar dengan teruk: DSR membina bar dideflasinya dengan menganggap 640 percubaan berkorelasi sebagai 640 cabutan bebas, yang menggembungkan maksimum-yang-dijangka kepada 0.221 setiap-pemerhatian — tahunan ~3.51 (terbitan: ). Berbanding bar 3.51, pemenang 3.92 hanya mengatasinya secara sederhana, dan DSR mendarat pada 0.748 — kurang daripada 0.95. Dua perkara mengepam bar itu naik: kiraan mentah (640 pandangan dan bukan sekumpulan kecil yang berkesan), dan penyebaran kemahiran tulen antara percubaan — sesetengah pasangan parameter memang lebih baik pada siri rejim, yang meluaskan dan menaikkan melebihi apa yang nasib baik tulen sahaja akan hasilkan. Kedua-duanya menolak ke arah yang sama, dan bar itu berakhir terlalu tinggi kerana carian itu tidak pernah benar-benar 640 pandangan bebas; ia adalah beberapa taruhan bebas, disampel 640 kali.
Suapkan DSR dengan bilangan percubaan berkesan sebaliknya. One-liner yang digunakan di atas adalah anggaran kasar daripada korelasi berpasangan purata:
def effective_n_trials(returns_matrix):
"""N_eff = N / (1 + (N-1) * rho_bar), clipped to [1, N].
Correlated trials -> fewer independent bets."""
C = np.corrcoef(returns_matrix, rowvar=False)
rho_bar = max(np.nanmean(C[np.triu_indices(C.shape[0], k=1)]), 0.0)
N = returns_matrix.shape[1]
neff = N / (1.0 + (N - 1) * rho_bar)
return float(min(max(neff, 1.0), N))
Dengan dan , ini meruntuhkan grid itu kepada percubaan berkesan (terbitan: ), dan DSR melonjak kepada 1.000. Tetapi berhenti sebelum meraikan nombor itu, kerana ia adalah bukti paling lemah dalam keseluruhan bahagian ini. Pada , bar dideflasi itu runtuh kepada tahunan — pada dasarnya purata percubaan, pada dasarnya sifar. Deflasi di sana dimatikan: DSR pada hanya melaporkan semula keertian sampel-terhingga tidak dilaraskan bagi pemenang (-berbanding-sifar ). Keputusan itu diwarisi daripada keertian mentah, bukan dihasilkan oleh pembetulan ujian berganda. Dan amaran cermin-imej pada sisi jalan-rawak: penolakannya pada hanya berpegang kerana pemenang itu secara bebas marginal sejak awal (-berbanding-sifar ). Berpaut pada 1.6 sahaja untuk seluruh hujah dan seorang skeptik betul untuk mengangkat bahu: anda mematikan pembetulan itu dan melaporkan apa sahaja yang berada di bawahnya.
Jadi jangan berpaut pada satu penganggar. Langkah yang jujur — dan yang lebih kukuh — adalah mengira dengan lima cara standard berbeza dan membaca keputusan merentasi keseluruhan jalur. Berikut adalah lima penganggar yang digunakan pada grid isyarat 640-percubaan yang sama, setiap satu dengan bar dideflasi yang dibawanya dan DSR yang dihasilkannya:
| Penganggar percubaan berkesan | Bar dideflasi (tahunan) | DSR | Keputusan | |
|---|---|---|---|---|
| Korelasi purata | 1.6 | 0.25 | 1.000 | kekal |
| Nisbah penyertaan | 2.4 | 0.43 | 1.000 | kekal |
| PCA (95% varians) | 16 | 1.85 | 1.000 | kekal |
| Kaiser (nilai eigen > 1) | 21 | 2.00 | 0.999 | kekal |
| Cheverud-Nyholt | 370 | 3.31 | 0.845 | tolak |
| kiraan grid mentah (tiada pelarasan) | 640 | 3.51 | 0.748 | tolak |
Penganggar: korelasi purata adalah one-liner di atas; nisbah penyertaan dan kiraan PCA-95%/Kaiser membaca dimensi berkesan daripada nilai eigen matriks korelasi; Cheverud-Nyholt adalah penganggar varians-nilai-eigen daripada literatur genetik yang diketahui terlebih-kira di bawah kuasi-korelasi-sama.
Sekarang inti itu mendarat, dan ia bukan "sebarang pelarasan menyelamatkan anda." Lihat pertengahan yang boleh dipertahankan — PCA-95% () dan Kaiser (). Ini bukan rejim deflasi-dimatikan; ia mengenakan bar tahunan sebenar sebanyak 1.85 hingga 2.00 — satu haircut yang serius, jauh di atas bunyi hingar, satu penalti ujian berganda yang tulen untuk 16-21 pandangan berkesan. Dan kelebihan 3.92 itu masih mengatasinya (DSR 1.000 dan 0.999). Isyarat itu terselamat daripada DSR untuk sebarang di bawah 144.8 (terbitan daripada titik persilangan); ia gagal hanya di bawah Cheverud-Nyholt, satu penganggar yang terbukti terlebih-kira apabila percubaan hampir-kuasi-berkorelasi-sama — dan walaupun kiraan mentah, tidak dilaraskan sebanyak 640 hanya menolak DSR turun kepada 0.748, bukan kepada sifar. Pemenang jalan-rawak, dijalankan melalui lima penganggar yang sama tepat, ditolak pada setiap satu daripadanya (ia terselamat untuk tiada di atas 1). Itulah keputusan sebenar: bukan satu nombor bertuah tunggal, tetapi satu keputusan yang stabil merentasi keseluruhan jalur penganggar cubaan-berkesan standard — yang jauh lebih kukuh sebagai bukti daripada mempercayai mana-mana satu daripadanya.
Satu amaran teknikal pada penganggar paling kasar, kerana ia menjelaskan mengapa ia duduk di hujung yang lembut: sebenarnya adalah faktor pengurangan-varians bagi min pemboleh ubah berkorelasi (berapa banyak yang dibeli oleh purata di bawah korelasi ). Penanda aras DSR adalah kuantiti nilai-ekstrem — maksimum yang dijangka bagi percubaan — jadi menggunakan pengecilan min-varians sebagai kiraan percubaannya adalah ketidakpadanan fungsian: betul dari segi arah (berkorelasi ⇒ lebih sedikit percubaan berkesan), tetapi bukan kuantiti yang sebenarnya bergantung kepada taburan maksimum itu. Itulah sebabnya penganggar berasaskan nilai eigen di tengah-tengah jalur itu adalah bacaan yang lebih boleh dipercayai, dan mengapa jalur, bukan titik, adalah hasil yang perlu diserahkan.
Pengajaran: gunakan kedua-dua alat, dan suapkan DSR dengan N yang betul

Dua perkara timbul daripada Kes B, dan kedua-duanya galas-beban:
- Saiz grid mentah adalah N yang salah untuk DSR apabila percubaan berkorelasi — dan tiada N-berkesan tunggal yang betul juga. Memasukkan 640 ke dalam formula yang menganggap kebebasan terlebih-deflasi: ia menghasilkan siling bunyi hingar yang jauh lebih tinggi daripada yang benar-benar dicapai oleh carian itu dan mengebumikan kelebihan sebenar di bawahnya. DSR memerlukan kiraan percubaan berkesan — tetapi pembetulannya bukan mempercayai satu penganggar (apatah lagi yang paling kasar, di mana pembetulan itu terpadam berhampiran ). Ia adalah membaca keputusan merentasi keseluruhan jalur penganggar standard (di sini 1.6 hingga 370) dan melihat sama ada ia stabil. Untuk kelebihan ini, ia stabil: dikekalkan di mana-mana deflasi itu benar-benar aktif (bar tahunan sebenar 1.85-2.00 pada -), gagal hanya di bawah penganggar yang terlebih-kira. Satu keputusan yang stabil-merentasi-jalur jauh lebih kukuh daripada mana-mana nombor tunggal.
- Pasangkan DSR dengan Reality Check. Perhatikan bahawa Reality Check dan sepupu jenis-SPA-nya (di-studentize) betul pada Kes B tanpa sebarang pembedahan kiraan-percubaan langsung (p = 0.0024 dan 0.0038) — mereka mengendalikan kebergantungan secara semula jadi, melalui stationary bootstrap, kerana mereka mensampel semula aliran pulangan berkorelasi sebenar dan bukannya mengira taruhan bebas yang hipotetikal. Itulah pemecah-seri untuk keseluruhan kekacauan N-berkesan: RC tidak memerlukan . DSR dan RC menjawab soalan berbeza: DSR bertanya "adakah pemenang istimewa dalam carian ini?" (dan perlu tahu berapa banyak pandangan berkesan yang diambil oleh carian itu); RC/jenis-SPA bertanya "adakah peraturan terbaik mengatasi tunai selepas data-snooping?" (dan membaca kebergantungan itu terus daripada data). Anda mahukan kedua-duanya. Apabila mereka tidak bersetuju — seperti DSR kiraan-mentah dan RC lakukan di sini — ketidaksepakatan itu bersifat diagnostik: biasanya ia bermaksud anda salah.
Ini adalah amaran struktur yang sama yang kajian tangga kelajuan dan cukai IPC kami terus temui daripada sisi kejuruteraan — satu carian pantas yang menjalankan grid berkorelasi yang besar tidak membeli anda sejumlah besar taruhan bebas, dan menganggap saiz grid sebagai kiraan percubaan menipu kedua-dua pengoptimum dan ujian keertian anda. Kesinambungan yang akan datang tentang kebarangkalian overfitting backtest menyerang bias pemilihan yang sama daripada sisi pensampelan semula (CSCV), dan berpasangan secara semula jadi dengan segala-galanya di sini: DSR menilai pemenang, PBO menilai prosedur.
Nota kejujuran
Tiga amaran, dinyatakan dengan jelas, kerana keseluruhan intinya bagi satu kajian terkawal adalah untuk tidak menjualnya secara berlebihan.
- Pulangan itu sintetik. Normal iid untuk eksperimen penentukuran dan kuasa, satu proses regime-switching untuk kes kelebihan-sebenar — dipilih untuk ground truth terkawal, bukan untuk realisme pasaran. Pulangan sebenar berekor tebal, berkorelasi bersiri, dan tidak pegun, dan terma skew/kurtosis PSR wujud tepat untuk mengendalikan yang pertama daripadanya. Hasil di sini adalah kaedah yang ditentukur, bukan satu strategi: kami hanya dapat membuktikan satu ujian mengawal penemuan palsu dengan menjalankannya pada data di mana kami tahu tiada apa-apa untuk ditemui. Itu memerlukan menghasilkan ground truth itu.
- Tiada penganggar N-berkesan yang kanonik — itulah sebabnya kami melaporkan lima. One-liner korelasi-purata mudah difahami oleh pengulas dan betul dari segi arah (lebih banyak korelasi ⇒ lebih sedikit percubaan berkesan), tetapi ia adalah faktor pengurangan-varians untuk min — ketidakpadanan fungsian dengan penanda aras maksimum DSR — dan berhampiran ia memadamkan deflasi sepenuhnya. Penganggar nilai eigen (nisbah penyertaan, PCA-95%, Kaiser) lebih sepadan tetapi masih heuristik, dan Cheverud-Nyholt terlebih-kira di bawah kuasi-korelasi-sama. Pendekatan yang lebih penuh dan berprinsip adalah pengelompokan percubaan (Lampiran 3 DSR Bailey & López de Prado): kumpulkan percubaan mengikut struktur korelasi dan kira kelompok bukannya meruntuhkan segala-galanya kepada satu skalar. Kami melaporkan keseluruhan jalur tepat kerana pilihan itu belum ditetapkan — satu keputusan yang stabil merentasi kesemua lima penganggar adalah dakwaan yang jujur; satu yang bergantung pada memilih satu penganggar tunggal tidak akan begitu.
- Bootstrap itu adalah Reality Check di-studentize, bukan SPA Hansen yang lengkap, dan kiraan sampel semula berbeza mengikut eksperimen. Di mana sahaja artikel ini berkata "jenis-SPA," ia bermaksud Reality Check White dengan studentization setiap-peraturan; pemusatan-semula konsisten, bergantung-sampel Hansen yang lengkap tidak dilaksanakan. Kadar penemuan palsu penentukuran menggunakan 500 sampel semula stationary-bootstrap setiap carian merentasi 400 carian; dua p-value RC/jenis-SPA kajian kes menggunakan 5,000 sampel semula setiap satu. Panjang blok purata 20 sepanjang masa (Politis-Romano), , 252 tempoh/tahun untuk penahunan. Ubah ini dan nombor perpuluhan-ketiga bergerak; cerita itu — naif 1.000 berbanding berprinsip 0.001-0.057, satu keluk-S mencapai kuasa 50% tepat di atas siling bunyi hingar, dan satu perangkap grid-berkorelasi yang keputusannya mesti dibaca merentasi jalur N-berkesan — tidak berubah.
Kesimpulan Utama
- Satu carian parameter adalah mesin ujian berganda, dan ujian keertian naif buta terhadapnya. Pada 1,000 strategi kelebihan-sifar, Sharpe tahunan terbaik purata 1.63 dengan median p-value ujian tunggal 0.000686 — dan ujian "adakah ia signifikan?" mengisytiharkan penemuan 100% daripada masa (kadar penemuan palsu 1.000). Sharpe hebat daripada ketiadaan, disahkan signifikan oleh ujian yang tidak pernah bertanya soalan yang betul.
- Deflated Sharpe Ratio menganjak gol daripada sifar kepada siling bunyi hingar. DSR membandingkan pemenang bukan berbanding sifar tetapi berbanding , terbaik-secara-nasib-baik yang dijangka bagi carian bersaiz ini — yang untuk kes null mendarat pada 1.63 tahunan, tepat di mana purata pemenang bunyi hingar duduk (terbitan: ). Kadar penemuan palsu null-nya adalah 0.001; haircut Harvey-Liu (Bonferroni/Holm 0.057, BHY 0.007) dan Reality Check White (0.022) mencapai kawalan yang sama melalui jalan lain.
- Ia mengekalkan kelebihan sebenar. Kuasa pengesanan DSR mengesan keluk-S yang mencapai kuasa 50% pada Sharpe tahunan ~1.73 — tepat di atas siling bunyi hingar 1.63: 0.005 pada Sharpe sebenar tahunan 0.79, 0.651 pada 1.90, 0.998 pada 2.54, 1.000 pada 3.17, positif palsu ~0 sepanjang masa. Kelebihan di bawah siling itu dengan betul disingkirkan sebagai tidak dapat dibezakan daripada nasib baik; kelebihan di atasnya dikekalkan dengan kuasa menghampiri satu.
- Grid berkorelasi merosakkan DSR mentah — dan tiada N-berkesan tunggal menyelamatkannya; jalur itu yang menyelamatkan. Pada satu silangan MA 640-sel (korelasi berpasangan purata ~0.61), DSR kiraan-mentah dengan palsu menolak kelebihan sebenar (in-sample terpilih, tahunan 3.92) (0.748 < 0.95) kerana 640 percubaan berkorelasi bukan 640 taruhan bebas. Tetapi pembetulannya bukan satu ajaib — pada anggaran paling kasar () deflasi itu pada dasarnya terpadam (bar ~tahunan 0.25) dan DSR hanya menggemakan keertian mentah. Bukti sebenar adalah bahawa kelebihan itu dikekalkan merentasi keseluruhan jalur penganggar standard — DSR 1.000/1.000/1.000/0.999 pada 1.6/2.4/16/21, termasuk bar tahunan sebenar 1.85-2.00 pada pertengahan PCA-95%/Kaiser yang boleh dipertahankan — terselamat untuk sebarang , dan gagal hanya di bawah Cheverud-Nyholt 370 yang terlebih-kira. Jalan rawak itu ditolak pada setiap penganggar. Baca jalur itu, bukan satu titik.
- Pasangkan DSR dengan Reality Check, kerana mereka menjawab soalan berbeza. Reality Check dan sepupu jenis-SPA-nya (di-studentize) mengesahkan kelebihan sebenar itu (p = 0.0024 dan 0.0038) tanpa sebarang pembedahan kiraan-percubaan — mereka mengendalikan kebergantungan secara semula jadi melalui stationary bootstrap, itulah tepatnya pemecah-seri apabila N-berkesan dipertikaikan. DSR bertanya "adakah pemenang istimewa dalam carian ini?"; RC/jenis-SPA bertanya "adakah yang terbaik mengatasi tunai selepas data-snooping?" Ketidaksepakatan antara mereka adalah isyarat bahawa anda salah. Jalankan kedua-duanya.
Pemenang satu carian adalah bersalah sehingga terbukti tidak bersalah. P-value naif bukanlah bukti tidak bersalah — ia adalah kesaksian yang digembungkan sendiri oleh carian itu, dan ia akan menjamin bunyi hingar tulen dengan dua belas sifar keyakinan. Deflasikan penanda aras kepada apa yang nasib baik hasilkan, kira percubaan berkesan anda dengan jujur, dan bootstrap maksimum itu untuk pendapat kedua. Apa yang mengatasi ketiga-tiga bar itu mungkin sebenar. Apa yang hanya mengatasi bar naif adalah yang paling tinggi antara seribu penyambit syiling.
Eksperimen penuh — harness penentukuran-null, imbasan kuasa kelebihan-ditanam, carian grid-berkorelasi, dan setiap nombor dalam artikel ini boleh dihasilkan semula daripada satu skrip deterministik tunggal — terdapat dalam kertas kerja pengiring di deflated-sharpe.marketmaker.cc, dengan kod dan data di github.com/suenot/deflated-sharpe-search.
Pengarang

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Lagi

Probability of Backtest Overfitting: Adakah Carian Anda Mengatasi Lambungan Syiling?

Reka Bentuk Fungsi Objektif: Metrik yang Anda Optimumkan Secara Rahsia Memilih Strategi Anda
