Внутри нашего «фирменного» алгоритма: HRP + long/short + CVaR по Халлу–Уайту
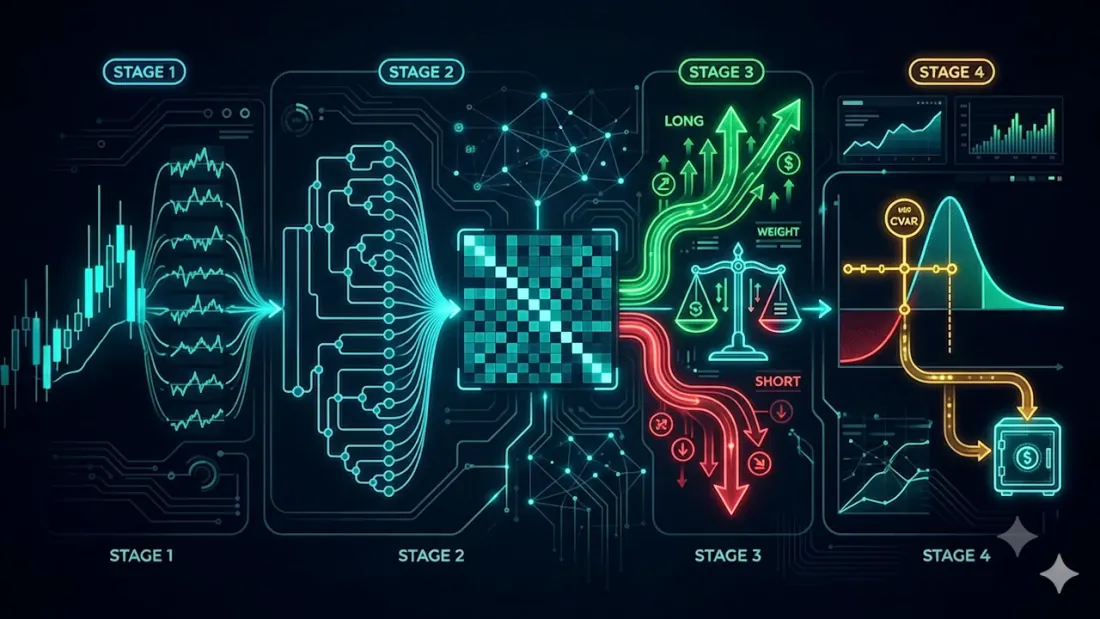
В обзоре «12 алгоритмов оптимизации портфеля» мы прогнали дюжину методов аллокации бок о бок. Одиннадцать из них — классика из литературы. Двенадцатый, Pipeline, — наш собственный, и в обзоре ему досталась всего одна строчка. Эта статья — подробный разбор: что у него внутри, откуда берётся каждая формула и как спецификация превращается в код на Rust.
Pipeline не изобретает новый способ считать веса. Он берёт самый устойчивый из известных приёмов — Hierarchical Risk Parity (HRP) — и оборачивает его двумя слоями, которые нужны на реальном торговом счёте, но которых нет в чистом HRP: направленностью (long/short по сигналам стратегии) и жёстким бюджетом риска (CVaR с поправкой на текущий режим волатильности). Получается четыре стадии.
Четыре стадии
- I — лог-доходности всех активов.
- II — базовые веса по HRP.
- III — разбиение на long/short по сигналам агента, с долями риска по уверенности.
- IV — коррекция через CVaR с волатильностью по Халлу–Уайту; излишек риска уходит в кэш.
Разберём по порядку.
Стадия I. Лог-доходности
Всё начинается с перехода от цен к логарифмическим доходностям:
где — актив, — момент времени. Лог-ретёрны складываются во времени и симметричнее обычных процентных изменений — стандартный вход для любой ковариационной математики.
Стадия II. HRP как фундамент
HRP, предложенный Маркосом Лопесом де Прадо в 2016 году, обходит главную болезнь Mean-Variance Optimization — обращение плохо обусловленной ковариационной матрицы. Он вообще её не обращает. Вместо этого работает со структурой корреляций.
Ковариация и корреляция
Из доходностей строим ковариационную матрицу и нормируем её до корреляционной :
Матрица расстояний
Корреляцию превращаем в метрику расстояния — так, чтобы сильно скоррелированные активы оказались «близко»:
Чем ближе к 1, тем ближе к 0 — и тем вероятнее активы попадут в один кластер.
Дендрограмма и порядок листьев
По матрице расстояний строим иерархию кластеров через average linkage и снимаем с дендрограммы порядок листьев — перестановку активов, в которой похожие стоят рядом.
Опциональный шаг: оптимальное число кластеров можно подбирать по коэффициенту силуэта , где — среднее расстояние внутри кластера, — до ближайшего соседнего. В базовом проходе он не нужен — рекурсивное деление само уважает иерархию.
Квазидиагонализация
Переставляем строки и столбцы в порядке , собирая большие значения вдоль диагонали:
Рекурсивное деление
Дальше — рекурсия сверху вниз. На каждом шаге кластер делится пополам на и , и капитал между половинами распределяется обратно пропорционально их дисперсиям:
Дисперсия кластера считается на его подматрице ковариаций как . Спуск продолжается, пока в каждом узле не останется один актив. Веса только длинные, неотрицательные, в сумме 1.0.
В нашей реализации это функция hrp_from_cov(cov) -> Vec<f64>: корреляция → расстояние → average linkage → порядок листьев → квазидиагонализация → рекурсивное деление. Именно её Pipeline вызывает как базу — и она же является публичным optimize() для случая без сигналов.
Стадия III. Long/short-оверлей
Чистый HRP — портфель «только купить». Но стратегия часто говорит не только сколько, но и в какую сторону. Стадия III принимает от агента сигналы (Long/Short) по каждому активу и строит два подпортфеля.
- Активы делятся на long- и short-корзины по сигналам.
- Внутри каждой корзины веса считаются тем же HRP (на подматрице ковариаций соответствующих активов), сумма по корзине — 1.
- Если агент выдаёт ещё и уверенность , доли риска между сторонами задаются суммарной уверенностью:
Без уверенности доли падают обратно на количество активов в каждой корзине. Итоговый знаковый вес: для long и для short, после чего вся валовая экспозиция нормируется к 1.
Честная пометка о коде. В исходной спецификации фигурируют поправочные коэффициенты , — но там же стоит вопрос «нужен ли этот шаг?». В реализации мы их не применяем: стороны комбинируются напрямую через доли риска , что держит валовую экспозицию ровно на 1 и не создаёт скрытого плеча. Это сознательное упрощение спеки, а не недосмотр.
Стадия IV. CVaR с поправкой Халла–Уайта
HRP балансирует риск структурно, но ничего не знает про абсолютный уровень риска в деньгах. Последняя стадия ставит жёсткий потолок на хвостовой риск — и делает его чувствительным к смене рыночного режима.
Доходность портфеля и EWMA-волатильность
Сначала сворачиваем веса в доходность портфеля и оцениваем условную волатильность по EWMA:
с (классическое значение RiskMetrics). EWMA даёт «сегодняшнюю» волатильность, а не усреднённую по всей истории.
Перешкалирование по Халлу–Уайту
Ключевая идея: прошлые доходности нельзя брать как есть — они получены при другой волатильности. Метод Халла–Уайта масштабирует каждую прошлую доходность к текущему уровню:
Спокойный месяц «растягивается», бурный — «сжимается», и распределение приводится к текущему режиму.
VaR и CVaR
По перешкалированному распределению берём квантиль убытков и средний убыток в хвосте:
CVaR (он же Expected Shortfall) отвечает не «насколько плохо в типичный плохой день», а «насколько плохо в среднем по худшим процентам» — то есть видит толщину хвоста, а не только его край.
Бюджет риска и кэш
Если CVaR превышает допустимый порог, все рискованные позиции ужимаются одним коэффициентом, а высвободившийся капитал уходит в кэш:
Так портфель сам себя «обналичивает» при росте хвостового риска и снова входит в рынок, когда тот успокаивается.
От спецификации к коду
Весь алгоритм живёт в одном Rust-крейте portfolio-pipeline и подчиняется общему контракту воркспейса:
pub fn optimize(prices: &[Vec<f64>]) -> Vec<f64>
Это long-only-проекция (стадии I, II, IV без сигналов) — ровно тот же интерфейс цены -> веса, что и у остальных одиннадцати алгоритмов, поэтому Pipeline взаимозаменяем с ними в любом коде. Полная версия со всеми стадиями — отдельная функция:
pub fn run(
prices: &[Vec<f64>],
signals: Option<&[Side]>, // Long / Short по каждому активу
confidence: Option<&[f64]>, // уверенность агента → доли риска λ
cfg: &PipelineConfig, // параметры CVaR/Hull-White
) -> PipelineResult // знаковые веса + cash + cvar + σ
Параметры оверлея по умолчанию: хвост cvar_alpha = 0.05, бюджет cvar_max = 0.05, EWMA ewma_lambda = 0.94, окно Халла–Уайта hw_window = 0 (вся история). Реализация без внешних зависимостей и сознательно «защищённая»: на коротких историях (менее 4 точек цен) она отдаёт равные веса, а CVaR-оверлей включается только при ≥8 наблюдениях доходности — иначе хвост оценивать не на чем.
Почему Rust: единый детерминированный код для бэктеста и для продакшена, без расхождения «питон в ресёрче — что-то другое в бою», и достаточно быстрый, чтобы гонять все двенадцать алгоритмов на одном запросе через бэкенд сравнения.
Сколько это стоит по времени
Насколько быстрый — это «достаточно быстрый»? Мы вынесли ядро HRP (лог-ретёрны → ковариация → average linkage → квазидиагонализация → рекурсивные веса) в отдельный бенчмарк и прогнали ровно одну и ту же математику на семи языках — C, C++, Rust, Zig, Python, Node.js и Bun — в одинаковых условиях: Apple Silicon, один поток, 365 дневных наблюдений на актив, синтетические цены, число активов от 10 до 10 000.
Пара слов о сложности — она задаёт всю картину. Учебная версия average linkage на каждом слиянии заново сканирует всю матрицу расстояний в поисках ближайшей пары — это , и на нескольких тысячах активов именно она становится узким местом. В бенчмарке вместо этого используется алгоритм ближайшего соседа по цепочке (nearest-neighbour-chain) со сложностью (Müllner 2011) — тот же, что стоит за linkage(method='average') в SciPy. С ним кластеризация перестаёт быть доминирующей стадией: на это ~15 мс из ~0,5 с всего прохода. Теперь цену задаёт ковариационная матрица, — единственная стадия, которой не избежать ни одному методу в стиле HRP.
Что показывают прогоны (полные таблицы по каждому языку и скрипт воспроизведения одной командой лежат в репозитории проекта):
- На реалистичных портфелях это бесплатно. Криптокорзина — это десятки активов, редко больше сотни. На полный проход HRP занимает единицы миллисекунд даже в Node и микросекунды в Rust/C. Пересчитывать веса хоть на каждом тике — не проблема.
- Rust в пределах ~1,0–1,3× от C — тот же порядок, оба компилируемые, а на тысячах активов они фактически вровень. C чуть быстрее на «голой» арифметике, но Rust даёт ту же предсказуемость без сборщика мусора и без UB.
- Масштабируется на тысячи активов. С линкеджем полный проход занимает ~0,5 с на и несколько секунд на в компилируемых языках; даже интерпретируемый Node проходит менее чем за две секунды. Потолок теперь задаёт стадия ковариации, а не кластеризация.
Вывод прагматичный: при наших размерах портфеля выбор Rust — это не про «обогнать C» (C тут чуть быстрее), а про один детерминированный код для ресёрча и продакшена, без GC-пауз и с запасом по скорости на годы вперёд. Полный бенчмарк на семи языках, с результатами и скриптом воспроизведения, открыт в репозитории проекта.
Где Pipeline в общем зачёте
В нашем сравнении на одной (намеренно «подстроенной») корзине Pipeline вёл себя как HRP — потому что через long-only-вход optimize() он и есть HRP с CVaR-надстройкой. Его направленная машинерия оживает только тогда, когда его кормят сигналами стратегии. Это и есть главная мысль: Pipeline — не «ещё один оптимизатор для бэктеста весов», а исполнительный слой между сигналами стратегии и реальными ордерами: он берёт ваши «купить/продать», раскладывает капитал по HRP внутри каждой стороны, балансирует стороны по уверенности и обрезает хвостовой риск до заданного бюджета.
Полный контекст — какие ещё одиннадцать методов существуют и чем они отличаются — в обзорной статье «12 алгоритмов оптимизации портфеля». А пощупать всё вживую можно на portfolio-optimizer.marketmaker.cc.
Источники
- López de Prado, M. (2016). Building Diversified Portfolios that Outperform Out of Sample. The Journal of Portfolio Management.
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
- Hull, J., & White, A. (1998). Incorporating Volatility Updating into the Historical Simulation Method for Value at Risk. Journal of Risk.
- Rockafellar, R. T., & Uryasev, S. (2000). Optimization of Conditional Value-at-Risk. Journal of Risk.
- RiskMetrics Group (1996). RiskMetrics — Technical Document. J.P. Morgan.
- Marketmaker.cc: marketmaker.cc
Citation
@article{soloviov2026pipeline,
author = {Soloviov, Eugen and Zhuravleva, Marina and Kiselev, Kirill},
title = {Inside Our House Algorithm: HRP + Long/Short + CVaR with Hull-White Adjustment},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/portfolio-pipeline-hrp-cvar},
description = {A deep dive into Pipeline, a composite portfolio allocation algorithm built on Hierarchical Risk Parity with a signal-driven long/short overlay and a Hull-White CVaR risk-budget correction, with the full specification and its Rust implementation.}
}
Авторы

Инженер торговых систем
Разработка торговых ботов с 2017 года: межбиржевой арбитраж (подключал до 30 бирж), парный арбитраж на коинтеграции между спотом и фьючерсами, скальпинг, фронтраннинг, торговля по новостям, сентиментный анализ, трендовые алгоритмы, а также алгоритмы управления и балансировки портфелей. Делает выставление ордеров до 1 мс, warehouse для big data, бэктестинг-движки, AI-агентов и интерфейсы для ботов (в т.ч. open-source profitmaker.cc). Стек: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, архитектура.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(86%2C%2071%25%2C%2066%25)%22%2F%3E%3C%2Fsvg%3E)
Финансовая математика
Студентка 5 курса МГТУ им. Баумана (направление «системы автоматического управления»), развивает финансовую математику. Занималась калибровкой моделей стохастической волатильности (Хестон) и локальной волатильности (Дюпир), справедливой оценкой опционов (в том числе экзотических) как методами Монте-Карло, так и аналитическими формулами, устранением ошибки хеджирования, соприкасалась с LSV.
%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%2260%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22120%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22180%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22180%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22240%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%2260%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22120%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22240%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3Crect%20x%3D%22300%22%20y%3D%22300%22%20width%3D%2260%22%20height%3D%2260%22%20fill%3D%22hsl(133%2C%2058%25%2C%2068%25)%22%2F%3E%3C%2Fsvg%3E)
Портфельная оптимизация
Студент 4 курса мехмата НГУ; диплом по калибровке модели Хестона и дельта-хеджированию в этой же модели. Занимался портфельной оптимизацией.
Читайте также

12 алгоритмов оптимизации портфеля: HRP, Black-Litterman, NCO и другие

Портфельная теория Марковица для криптовалют: от нуля до героя
