免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
这是"回测无幻觉"系列的第五篇文章。在之前的文章中,我们讨论了亏损与盈利的不对称性、Monte Carlo自举法、资金费率的影响和Parquet缓存加速回测。现在让我们讨论寻找最优策略参数的过程——这是一个直觉最常失效的任务。
你有一个包含12个参数的策略。每个参数有约9个取值。你想找到在限定回撤下最大化PnL的组合。你怎么做?
如果你的答案是"遍历所有组合"——你有一个问题。如果你的答案是"一次修改一个参数"——你有另一个问题。本文讨论每种方法背后隐藏的问题以及如何解决它们。
穷举搜索(网格搜索)测试每个参数的每个值的所有组合。对于2个参数各9个值,即 次运行——完全可行。对于3个:——还可以接受。
但对于有12个参数的实际策略:
两千八百二十四亿次运行。即使单次回测只需1秒(这已经是乐观估计),穷举搜索将需要:
这是指数增长:每增加一个新参数,搜索空间就乘以9。增加第13个参数——从9000年变成80000年。
import math
def grid_search_cost(n_params: int, values_per_param: int, seconds_per_trial: float) -> dict:
"""估算穷举搜索的成本。"""
total_trials = values_per_param ** n_params
total_seconds = total_trials * seconds_per_trial
return {
"total_trials": total_trials,
"total_hours": total_seconds / 3600,
"total_years": total_seconds / (3600 * 24 * 365),
}
cost = grid_search_cost(12, 9, 1.0)
print(f"Trials: {cost['total_trials']:,.0f}") # 282,429,536,481
print(f"Years: {cost['total_years']:,.0f}") # 8,950
在关于Parquet缓存的文章中,我们展示了预计算时间框架和指标如何将单次回测加速到约1秒。但即使每次运行0.1秒,12个参数的穷举搜索仍需895年。预计算有所帮助,但无法解决指数增长的根本问题。
我们需要比穷举搜索更智能地探索参数空间的方法。
有两种相关方法——都是一次优化一个参数,但在遍历次数上有所不同:
OAT(One-at-a-Time)扫描 ——对所有参数进行单次遍历。遍历第一个参数的值,固定最佳值,转到第二个——依此类推。只做一次。快速且廉价。
坐标下降法(Coordinate Descent) ——多次遍历。优化完最后一个参数后,回到第一个检查最优值是否改变(因为上下文变了——其他参数值已经不同)。重复轮次直到收敛。更昂贵,但更精确——每轮都可以细化结果。
在实践中,回测更常使用OAT:对12个参数进行单次遍历——96次运行。3-5轮的坐标下降——300-500次运行,已经与Optuna相当,但没有其优势。
对于12个参数,每个约8个取值:
与网格搜索的 相比。OAT是线性的: 而非 。这既是它的主要优势,也是它的主要问题。
def oat_sweep(
param_grid: dict[str, list],
run_backtest_fn,
initial_params: dict,
metric: str = "effective_score",
) -> dict:
"""
OAT扫描:单次遍历,一次优化一个参数。
param_grid: {"htf_entry_sell": [0.0, 0.005, ..., 0.05], ...}
initial_params: 所有参数的初始值
metric: 优化指标(推荐effective_score——
按活跃时间计算的PnL,年化外推)
"""
best_params = initial_params.copy()
best_score = run_backtest_fn(**best_params)[metric]
for param_name, values in param_grid.items():
param_best_val = best_params[param_name]
param_best_score = best_score
for val in values:
candidate = best_params.copy()
candidate[param_name] = val
result = run_backtest_fn(**candidate)
score = result[metric]
if score > param_best_score:
param_best_score = score
param_best_val = val
best_params[param_name] = param_best_val
best_score = param_best_score
print(f"{param_name}: best={param_best_val}, score={param_best_score:.4f}")
return best_params
优化应该选择哪个指标? 建议不要使用原始PnL或PnL@MaxLev,而是使用effective score——按活跃时间计算的PnL并年化外推。该指标考虑了持仓时间,允许正确比较不同交易频率的策略。
OAT假设每个参数的影响是可加的——即一个参数的最优值不依赖于其他参数的值。这个假设对某些参数成立,但对耦合参数则不成立。
在优化之前,对参数进行分类是有用的:
可加(独立)参数 ——一个的最优值不依赖于另一个。可以廉价地逐个优化:
htf_entry_sell 和 htf_entry_buy ——同一时间框架上不同方向(卖/买)的入场阈值。卖出阈值过滤做空信号,买入阈值过滤做多信号。它们作用于不重叠的交易子集。tp_target 和 be_trigger ——止盈和保本,如果它们不产生冲突的退出条件。耦合(交互)参数 ——一个的最优值依赖于另一个。需要联合优化:
htf_entry_sell 和 mtf_entry_sell ——同一方向(卖出)在不同时间框架上的阈值。HTF决定哪些信号到达MTF,MTF阈值决定过滤效果。当MTF变化时,HTF最优值会偏移。ltf_entry_sell、mtf_entry_sell、htf_entry_sell ——一个方向的整个阈值链。partial_frac 和 tp_target ——部分平仓大小取决于TP水平。实用方法: 首先通过OAT廉价优化可加参数。然后通过Optuna优化耦合组。这减少了预算:不是在Optuna中放入12个参数,而是只放入6-8个耦合参数,其余已经固定。
考虑两个耦合阈值:
htf_entry_sell ——高时间框架上的阈值(卖出方向)mtf_entry_sell ——中时间框架上的阈值(卖出方向)OAT固定 mtf_entry_sell = 0.01(初始值)并遍历 htf_entry_sell。找到最佳值:htf_entry_sell = 0.02。固定它并转到下一个参数——不再返回。
这是OAT遗漏的:
htf_entry_sell | mtf_entry_sell | PnL |
|---|---|---|
| 0.02 | 0.01 | +42% |
| 0.02 | 0.02 | +38% |
| 0.03 | 0.02 | +51% |
| 0.03 | 0.01 | +35% |
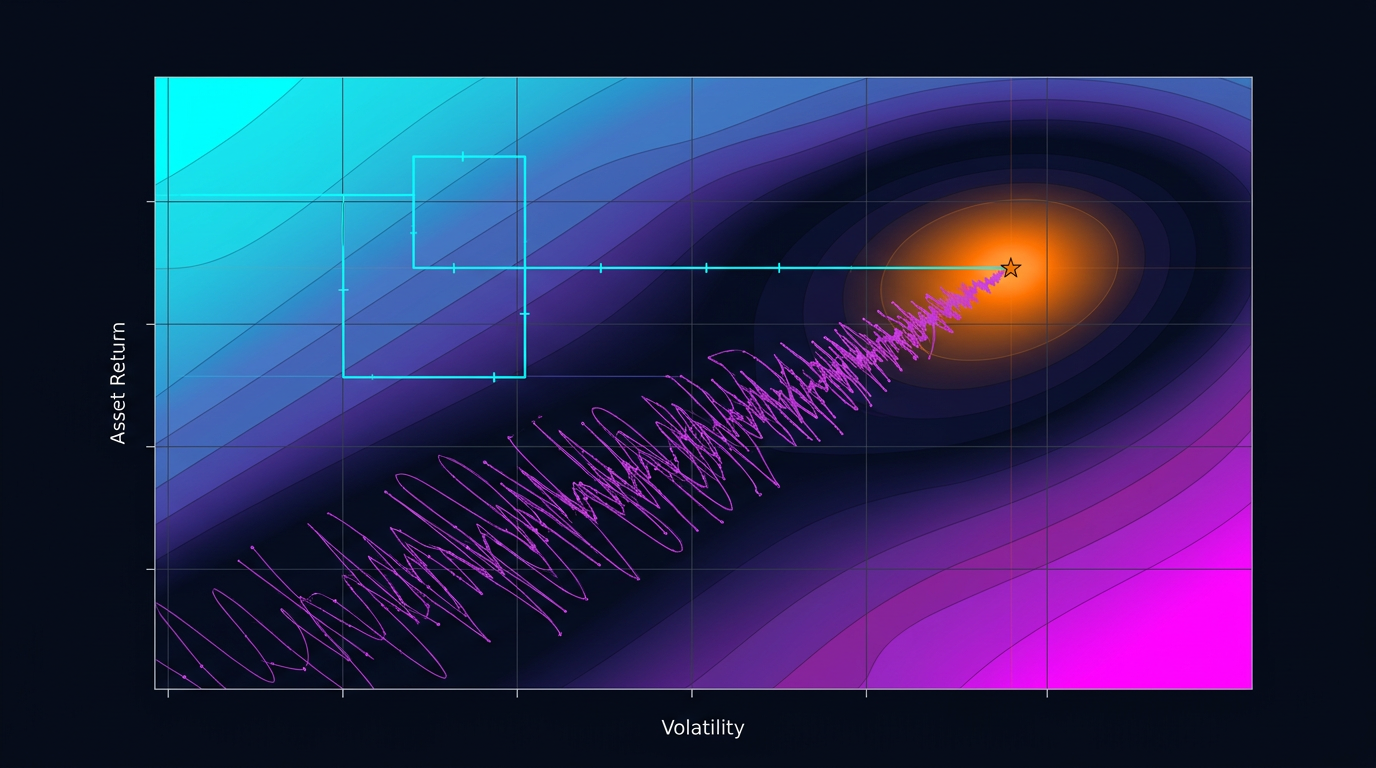
组合 (0.03, 0.02) 产生PnL +51%,但OAT永远不会考虑它,因为在固定 mtf_entry_sell = 0.01 时,值 htf_entry_sell = 0.03 只产生+35%。OAT"卡在"了局部最优 (0.02, 0.01),看不到全局最优 (0.03, 0.02)。
这是一个经典问题:如果目标函数的景观包含对角山脊(当一个参数的最优值随另一个参数变化而偏移时),OAT会遗漏它们。
设 为目标函数(PnL)。OAT找到的点满足:
但这是全局最优的必要条件,而非充分条件。如果Hessian矩阵 有显著的非对角元素——OAT不考虑交叉导数 ( 时)。
对于耦合参数(同一方向跨多个时间框架的阈值)——交互作用是常态而非例外。高时间框架的入场阈值决定哪些信号到达中时间框架,中时间框架的阈值决定低时间框架的过滤效果。对于可加参数(不同方向、独立过滤器),交叉导数接近零——OAT表现良好。
贝叶斯优化不是盲目枚举或贪心搜索,而是构建目标函数的代理模型,在每一步选择期望改进最大的点。
算法:
与OAT的关键区别:贝叶斯优化同时考虑所有参数,可以探索参数空间中的对角山脊。
TPE是Optuna的默认采样器。TPE不直接建模 ,而是建模两个分布:
TPE的采集函数——比率:
TPE选择 大(参数类似于"好的")且 小(参数不类似于"差的")的点。
为什么TPE适合回测:
TPE的替代方案——高斯过程。GP将 建模为多元正态过程,不仅提供值的预测,还提供每个点的不确定性。
其中 是均值, 是协方差函数(核函数)。
GP在以下情况下表现良好:
对于使用预计算Parquet缓存的回测,单次运行约1秒,通常更推荐TPE:它构建模型更快,在500+次迭代上扩展性更好。
import optuna
from optuna.samplers import TPESampler
import numpy as np
def run_backtest(htf_pre, mtf_pre, ltf_pre, **params) -> dict:
"""
使用给定参数运行回测。
返回包含指标的dict:pnl, max_dd, n_trades, trading_time, sharpe。
使用预计算的Parquet缓存——每次运行约1秒。
"""
pass
def objective(trial: optuna.Trial) -> float:
"""Optuna的目标函数。"""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
study = optuna.create_study(
sampler=TPESampler(seed=42),
study_name="strategy_optimization",
direction="minimize",
)
study.optimize(objective, n_trials=500, show_progress_bar=True)
print(f"Best PnL: {-study.best_value:.2f}%")
print(f"Best params: {study.best_params}")
print(f"Total trials: {len(study.trials)}")
以每次回测约1秒的速度(使用预计算缓存):
8分钟对比穷举搜索的8950年。而且TPE在500次迭代中能找到OAT在96次中遗漏的组合,因为它同时探索参数空间,而不是逐轴搜索。
import optuna
study = optuna.create_study(
storage="sqlite:///optuna_study.db",
study_name="strategy_v2",
sampler=TPESampler(seed=42),
direction="minimize",
load_if_exists=True, # 如果研究已存在则继续
)
study.optimize(objective, n_trials=300)
study.optimize(objective, n_trials=200)
并非所有参数组合都有效。例如,退出阈值不应大于入场阈值:
def objective_with_constraints(trial: optuna.Trial) -> float:
htf_entry = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
htf_exit = trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005)
if htf_exit > htf_entry:
raise optuna.TrialPruned()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
return -result["pnl_at_max_lev"]
Optuna支持多种采样器。每种都有其优势。
sampler = optuna.samplers.TPESampler(
n_startup_trials=20, # 开始建模前的随机试验次数
seed=42,
)
sampler = optuna.samplers.CmaEsSampler(seed=42)
sampler = optuna.samplers.GPSampler(seed=42)
sampler = optuna.samplers.RandomSampler(seed=42)
sampler = optuna.samplers.QMCSampler(seed=42)
| 采样器 | 类型 | 交互作用 | 类别型 | 最佳预算 |
|---|---|---|---|---|
| TPE | 贝叶斯 | 部分 | 是 | 100-1000 |
| CmaEs | 进化 | 是 | 否 | 200-2000 |
| GP | 贝叶斯 | 是 | 有限 | 50-200 |
| Random | 随机 | 否 | 是 | 任意(基准线) |
| QMC | 准随机 | 否 | 否 | 50-500 |
import optuna
import time
def benchmark_sampler(sampler, n_trials=300):
"""在同一任务上比较采样器。"""
study = optuna.create_study(sampler=sampler, direction="minimize")
start = time.time()
study.optimize(objective, n_trials=n_trials, show_progress_bar=False)
elapsed = time.time() - start
return {
"best_value": -study.best_value,
"elapsed_sec": elapsed,
"best_trial": study.best_trial.number,
}
samplers = {
"TPE": optuna.samplers.TPESampler(seed=42),
"CmaEs": optuna.samplers.CmaEsSampler(seed=42),
"GP": optuna.samplers.GPSampler(seed=42),
"Random": optuna.samplers.RandomSampler(seed=42),
"QMC": optuna.samplers.QMCSampler(seed=42),
}
for name, sampler in samplers.items():
result = benchmark_sampler(sampler, n_trials=300)
print(f"{name:8s}: best PnL={result['best_value']:.2f}%, "
f"found at trial #{result['best_trial']}, "
f"time={result['elapsed_sec']:.1f}s")
12参数策略的典型结果:
| 采样器 | 最佳PnL | 发现于第几次迭代 | 采样器开销 |
|---|---|---|---|
| TPE | ~51% | ~180 | 低 |
| CmaEs | ~49% | ~250 | 中 |
| GP | ~48% | ~90 | 时高 |
| Random | ~42% | ~270 | 最小 |
| QMC | ~43% | ~200 | 最小 |
TPE和CmaEs在最终PnL上始终比随机搜索高出15-20%。GP能更早找到好的结果,但在迭代次数多时会遇到计算瓶颈。
在没有回撤限制的情况下最大化PnL是一条通往灾难的路。由于亏损与盈利的不对称性,PnL +80%且MaxDD -30%的策略比PnL +50%且MaxDD -5%的策略风险大得多。
优化问题实际上是多目标的:
这些目标相互冲突:激进的参数同时增加PnL和回撤。解决方案不是单一的点,而是帕累托前沿:一组解,在其中无法改善一个指标而不恶化另一个。
import optuna
def multi_objective(trial: optuna.Trial) -> tuple[float, float]:
"""多目标函数:(PnL, MaxDD)。"""
params = {
"htf_entry_sell": trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005),
"htf_entry_buy": trial.suggest_float("htf_entry_buy", 0.0, 0.05, step=0.005),
"mtf_entry_sell": trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005),
"mtf_entry_buy": trial.suggest_float("mtf_entry_buy", 0.0, 0.05, step=0.005),
"ltf_entry_sell": trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005),
"ltf_entry_buy": trial.suggest_float("ltf_entry_buy", 0.0, 0.05, step=0.005),
"htf_exit_sell": trial.suggest_float("htf_exit_sell", 0.0, 0.03, step=0.005),
"htf_exit_buy": trial.suggest_float("htf_exit_buy", 0.0, 0.03, step=0.005),
"mtf_exit_sell": trial.suggest_float("mtf_exit_sell", 0.0, 0.03, step=0.005),
"mtf_exit_buy": trial.suggest_float("mtf_exit_buy", 0.0, 0.03, step=0.005),
"min_hold_bars": trial.suggest_int("min_hold_bars", 1, 20),
"trail_pct": trial.suggest_float("trail_pct", 0.001, 0.02, step=0.001),
}
result = run_backtest(htf_pre, mtf_pre, ltf_pre, **params)
pnl = result["pnl"] # 最大化
max_dd = result["max_dd"] # 最小化(已经是负数)
return pnl, max_dd # Optuna:两个方向在create_study中设置
study = optuna.create_study(
directions=["maximize", "minimize"],
sampler=optuna.samplers.NSGAIIISampler(seed=42),
study_name="multi_objective_strategy",
)
study.optimize(multi_objective, n_trials=500)
pareto_trials = study.best_trials
print(f"Pareto front: {len(pareto_trials)} solutions")
for t in pareto_trials[:5]:
print(f" PnL={t.values[0]:.2f}%, MaxDD={t.values[1]:.2f}%")
帕累托前沿给出多个解。如何选择一个?
def select_from_pareto(
pareto_trials: list,
max_dd_limit: float = -5.0,
min_pnl: float = 20.0,
) -> list:
"""
按约束过滤帕累托前沿。
max_dd_limit: 最大可接受回撤(例如 -5%)
min_pnl: 最小可接受PnL(%)
"""
filtered = []
for trial in pareto_trials:
pnl, max_dd = trial.values
if max_dd >= max_dd_limit and pnl >= min_pnl:
max_lev = min(50 / abs(max_dd), 100) if max_dd != 0 else 100
pnl_at_max_lev = pnl * max_lev
filtered.append({
"trial": trial,
"pnl": pnl,
"max_dd": max_dd,
"max_lev": max_lev,
"pnl_at_max_lev": pnl_at_max_lev,
})
filtered.sort(key=lambda x: x["pnl_at_max_lev"], reverse=True)
return filtered
注意:计算最大杠杆下的PnL时,必须考虑资金费率,否则理论上高杠杆在实际市场中会变成亏损。此外,最终PnL是单点估计,要评估结果的稳定性需要Monte Carlo自举法。
| 策略 | PnL | MaxDD | MaxLev | PnL@MaxLev | 交易时间 |
|---|---|---|---|---|---|
| 策略A | ~55% | ~0.9% | ~55x | ~3025% | ~15% |
| 策略B | ~25% | ~0.75% | ~66x | ~1650% | ~5% |
| 策略C | ~300% | ~17% | ~3x | ~900% | ~45% |
PnL +300%的策略C看起来令人印象深刻,但由于高回撤,其PnL@MaxLev最低。策略A在杠杆净收益方面领先,但考虑按活跃时间计算的PnL,策略B可能更可取——95%的空闲时间可以用于其他策略。
优化之后是可视化。Optuna提供内置工具:
import optuna.visualization as vis
fig_contour = vis.plot_contour(
study,
params=["htf_entry_sell", "mtf_entry_sell"],
)
fig_contour.show()
fig_importance = vis.plot_param_importances(study)
fig_importance.show()
fig_history = vis.plot_optimization_history(study)
fig_history.show()
fig_parallel = vis.plot_parallel_coordinate(
study,
params=["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell"],
)
fig_parallel.show()
fig_slice = vis.plot_slice(study)
fig_slice.show()
等高线图构建目标函数对一对参数的二维截面。如果等高线平行于某一轴——参数之间没有交互作用,OAT会找到相同的最优值。如果等高线是对角的——存在交互作用,OAT会遗漏。
key_params = ["htf_entry_sell", "mtf_entry_sell", "ltf_entry_sell",
"htf_entry_buy", "mtf_entry_buy", "ltf_entry_buy"]
for i, p1 in enumerate(key_params):
for p2 in key_params[i+1:]:
fig = vis.plot_contour(study, params=[p1, p2])
fig.write_image(f"contour_{p1}_vs_{p2}.png")
如果等高线图显示平台——目标函数变化很小的区域——这是一个好迹象。平台意味着结果对参数的小偏差是稳健的。关于平台分析及其与过拟合的关系的更多内容——在即将发表的文章平台分析中。
importance = optuna.importance.get_param_importances(study)
for param, imp in importance.items():
print(f"{param:20s}: {imp:.4f}")
典型输出:
htf_entry_sell : 0.2841
mtf_entry_sell : 0.2103
ltf_entry_sell : 0.1567
trail_pct : 0.1204
htf_entry_buy : 0.0892
...
重要性 < 0.01的参数可以固定在默认值——这降低了问题的维度并加速优化。但要小心:低重要性也可能意味着该参数仅在与其他参数交互时才重要。通过等高线图验证。
单次回测的速度决定了你能负担得起哪种优化方法。
| 回测时间 | 96次OAT | 500次TPE | 2000次CmaEs |
|---|---|---|---|
| 60秒 | 1.6小时 | 8.3小时 | 33小时 |
| 10秒 | 16分钟 | 83分钟 | 5.5小时 |
| 1秒 | 1.5分钟 | 8分钟 | 33分钟 |
| 0.1秒 | 10秒 | 50秒 | 3.3分钟 |
每次回测60秒时,500次TPE迭代需要8小时。已经可以忍受,但迭代(修改目标函数、重新启动)成本高。1秒时——8分钟,一天可以运行数十个实验。
这正是为什么预计算到Parquet缓存不仅仅是速度优化,而是扩展了可用方法的空间。没有缓存,你只能用OAT或100次GP迭代。有了缓存——你可以负担得起2000次CmaEs迭代或完整的多目标NSGA-III。
import pyarrow.parquet as pq
import time
t0 = time.time()
htf_pre = pq.read_table("cache/htf_indicators.parquet").to_pandas()
mtf_pre = pq.read_table("cache/mtf_indicators.parquet").to_pandas()
ltf_pre = pq.read_table("cache/ltf_indicators.parquet").to_pandas()
print(f"Cache loaded in {time.time() - t0:.2f}s") # ~0.3s
t1 = time.time()
result = run_backtest(htf_pre, mtf_pre, ltf_pre, htf_entry_sell=0.02, ...)
print(f"Backtest in {time.time() - t1:.2f}s") # ~1.0s
OAT在以下情况下是合理的:
探索性分析。 你刚开始探索一个策略,想了解哪些参数对结果有影响。96次运行1.5分钟——一个出色的起点。
可加参数。 对于在不重叠交易子集上运行的参数(卖/买方向、不同工具),OAT能更快给出正确结果。
非常昂贵的回测。 如果单次运行需要10+分钟且无法加速,96次OAT运行(16小时)优于500次TPE迭代(3.5天)。
Optuna在大多数情况下更可取:
超过3个参数。 交互作用几乎是必然的——OAT会遗漏最优值。
多时间框架策略。 不同时间框架上的阈值几乎总是相互关联的。
最终优化。 当策略通过了Monte Carlo自举法且你对其稳健性有信心——Optuna会找到最佳参数。
多目标问题。 PnL vs MaxDD vs 交易时间——OAT原则上无法解决此问题。
不必在OAT和Optuna之间选择——最好结合使用:
分类参数。 分为可加(独立)和耦合(交互)。12个分离参数的示例:
htf_entry_sell <-> htf_entry_buy、mtf_entry_sell <-> mtf_entry_buy、ltf_entry_sell <-> ltf_entry_buy(卖/买——不同方向,作用于不重叠的交易)htf_entry_sell、mtf_entry_sell、ltf_entry_sell(过滤链:HTF -> MTF -> LTF用于卖出信号)htf_entry_buy、mtf_entry_buy、ltf_entry_buyOAT用于可加参数。 独立优化卖出和买入组。如果卖出参数不影响买入交易——OAT在几分钟内给出正确结果。
Optuna用于耦合参数。 在每个组内(sell:6个入场+出场参数)使用TPE。6个参数而非12个——预算减半。
sell_params = oat_sweep(sell_param_grid, run_backtest, initial_params)
def objective_sell(trial):
params = sell_params.copy()
params["htf_entry_sell"] = trial.suggest_float("htf_entry_sell", 0.0, 0.05, step=0.005)
params["mtf_entry_sell"] = trial.suggest_float("mtf_entry_sell", 0.0, 0.05, step=0.005)
params["ltf_entry_sell"] = trial.suggest_float("ltf_entry_sell", 0.0, 0.05, step=0.005)
params["htf_exit_sell"] = trial.suggest_float("htf_exit_sell", 0.0, 0.02, step=0.001)
params["mtf_exit_sell"] = trial.suggest_float("mtf_exit_sell", 0.0, 0.02, step=0.001)
params["ltf_exit_sell"] = trial.suggest_float("ltf_exit_sell", 0.0, 0.02, step=0.001)
return -run_backtest(**params)["effective_score"]
study = optuna.create_study(sampler=optuna.samplers.TPESampler())
study.optimize(objective_sell, n_trials=300) # 6个参数 → 300次足够
1. 预计算Parquet缓存(一次)
2. 分类参数:可加 vs 耦合
3. OAT用于可加参数(~50次运行,~1分钟)→ 固定
4. Optuna TPE用于耦合组(300次迭代 × 2组,~10分钟)
5. Optuna NSGA-III用于元参数(500次迭代,~8分钟)→ 帕累托前沿
6. 等高线图 → 可视化交互作用
7. Monte Carlo自举法用于最佳点 → 置信区间
8. Walk-Forward → 样本外验证
第8步——Walk-Forward优化——对于防止过拟合至关重要。更多内容请参见即将发表的文章Walk-Forward。
过拟合。 参数越多、优化越精确——将策略拟合到历史数据的风险就越高。500次Optuna迭代处理12个参数会找到一个在训练集上完美运行但在新数据上毫无用处的组合。
防护措施:
多重比较问题。 如果你测试500种组合,随机找到"好"结果的概率会增加。Bonferroni校正或FDR(假发现率)控制有所帮助,但更简单的方法是样本外验证。
预算不足。 12个参数的TPE只用50次迭代太少了。前20次迭代是随机的(启动),只剩30次用于建模。最低预算: 次迭代(12个参数),推荐:。
Freqtrade——流行的算法交易框架之一——通过Hyperopt模块在底层使用Optuna。其经验验证了我们的建议:
Freqtrade生态系统的关键经验:内置损失函数覆盖了典型场景,但对于严肃的优化,你需要一个自定义目标函数,考虑你的策略特性——活跃时间、资金费用、用于精确成交模拟的自适应下钻。
坐标下降法(OAT)是一种快速且直觉上易于理解的方法。对于12个参数,它只需96次运行,一分半钟即可完成。但它对参数交互作用视而不见——而在多时间框架策略中,交互作用几乎总是存在的。
通过Optuna的贝叶斯优化(TPE、GP、CmaEs)整体探索参数空间。使用预计算的Parquet缓存,500次迭代8分钟——能找到OAT看不到的组合。
多目标优化(NSGA-III)将"最大化PnL"的问题转化为"构建PnL vs MaxDD的帕累托前沿"——提供一组具有不同风险收益平衡的解。
但优化只是流程的一部分。找到的参数需要通过Monte Carlo自举法验证,根据资金费率校正,考虑活跃时间重新计算,并通过Walk-Forward验证。更多内容将在系列后续文章中介绍。
@article{soloviov2026optuna, author = {Soloviov, Eugen}, title = {Coordinate Descent vs Bayesian Optimization: Which Finds Better Parameters}, year = {2026}, url = {https://marketmaker.cc/zh/blog/post/optuna-vs-coordinate-descent}, description = {为什么穷举搜索对12个以上参数不可行,坐标下降法如何遗漏交互作用,以及Optuna的TPE采样器如何在500次迭代中找到OAT在96次中无法找到的结果。} }