免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
你对一个策略进行了回测。得到了PnL +42%,Sharpe 1.8,MaxDD -12%。结果看起来非常好。你把机器人部署到生产环境,一个月后发现回撤已经到了-28%,PnL正趋向于零。
出了什么问题?不是程序bug,也不是"市场变了"。问题在于你基于一个数字做出了决策——一个单点估计。你知道策略显示了+42%,但你不知道你能在多大程度上信任这个数字。
在历史数据上的回测只是对一个特定市场事件序列的单次运行。结果取决于交易的顺序:同一个策略的同样交易,但顺序不同,可能显示出完全不同的最大回撤。
想象491笔交易。每笔交易都是一个具有特定收益分布的随机事件。历史回测只展示了这个过程的一次实现。这就像掷一次骰子就断定骰子永远会掷出四点。
我们真正需要的是:
这正是蒙特卡洛自助法的用途。
自助法是Bradley Efron在1979年提出的重采样方法。思路很优雅:如果我们有一个数据样本,我们可以通过从原始数据中有放回地随机抽取元素来生成数千个"新"样本。
在回测的场景中,它是这样工作的:
每次迭代都是一个"替代场景":如果交易的顺序和组合略有不同,可能会发生什么。
以下是完整的可运行实现:
import numpy as np
def max_drawdown(equity_curve):
"""计算权益曲线的最大回撤。"""
peak = np.maximum.accumulate(equity_curve)
drawdown = (equity_curve - peak) / peak
return drawdown.min()
trade_returns = [...] # 491个值,例如 [0.012, -0.005, 0.008, ...]
n_simulations = 10000
results = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
"sharpe": np.mean(sampled) / np.std(sampled) * np.sqrt(252)
})
执行时间:在普通笔记本电脑上约2秒。10,000个你的策略的替代历史。
现在我们有的不是一个数字,而是一个分布。以下是如何从中提取有用信息:
import pandas as pd
df = pd.DataFrame(results)
pnl_5 = np.percentile(df['final_pnl'], 5)
pnl_50 = np.percentile(df['final_pnl'], 50)
pnl_95 = np.percentile(df['final_pnl'], 95)
dd_5 = np.percentile(df['max_dd'], 5) # 第5百分位——最差情况
dd_50 = np.percentile(df['max_dd'], 50)
dd_95 = np.percentile(df['max_dd'], 95) # 第95百分位——最佳情况
print(f"PnL: {pnl_5:.1%} | {pnl_50:.1%} | {pnl_95:.1%}")
print(f"MaxDD: {dd_5:.1%} | {dd_50:.1%} | {dd_95:.1%}")
print(f"Sharpe: {np.percentile(df['sharpe'], 5):.2f} — {np.percentile(df['sharpe'], 95):.2f}")
一个真实策略的输出示例:
| 指标 | 第5百分位(最差) | 中位数 | 第95百分位(最佳) |
|---|---|---|---|
| PnL | +18.3% | +41.7% | +72.1% |
| MaxDD | -23.4% | -12.8% | -5.1% |
| Sharpe | 1.12 | 1.76 | 2.41 |
现在差异显而易见:
**第5百分位是你的"现实最坏情况"。**如果策略在第5百分位就不再盈利,那么将其部署到生产环境是有风险的。
蒙特卡洛自助法自然地可视化为扇形图——权益曲线的扇形展开:
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
ax = axes[0]
for i in range(min(500, n_simulations)):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
ax.plot(equity, alpha=0.02, color='#4FC3F7')
all_equities = []
for _ in range(n_simulations):
sampled = np.random.choice(trade_returns, size=len(trade_returns), replace=True)
equity = np.cumprod(1 + sampled)
all_equities.append(equity)
all_equities = np.array(all_equities)
p5 = np.percentile(all_equities, 5, axis=0)
p50 = np.percentile(all_equities, 50, axis=0)
p95 = np.percentile(all_equities, 95, axis=0)
ax.fill_between(range(len(p5)), p5, p95, alpha=0.3, color='#7C4DFF', label='90% CI')
ax.plot(p50, color='#E040FB', linewidth=2, label='中位数')
ax.set_title('蒙特卡洛自助法:权益曲线')
ax.legend()
ax = axes[1]
ax.hist(df['final_pnl'] * 100, bins=80, color='#4FC3F7', alpha=0.7, edgecolor='#1A237E')
ax.axvline(pnl_5 * 100, color='#FF5252', linestyle='--', label=f'第5百分位: {pnl_5:.1%}')
ax.axvline(pnl_50 * 100, color='#E040FB', linestyle='--', label=f'中位数: {pnl_50:.1%}')
ax.axvline(pnl_95 * 100, color='#69F0AE', linestyle='--', label=f'第95百分位: {pnl_95:.1%}')
ax.set_title('最终PnL分布')
ax.set_xlabel('PnL, %')
ax.legend()
plt.tight_layout()
plt.savefig('monte_carlo_fan_chart.png', dpi=150)
plt.show()
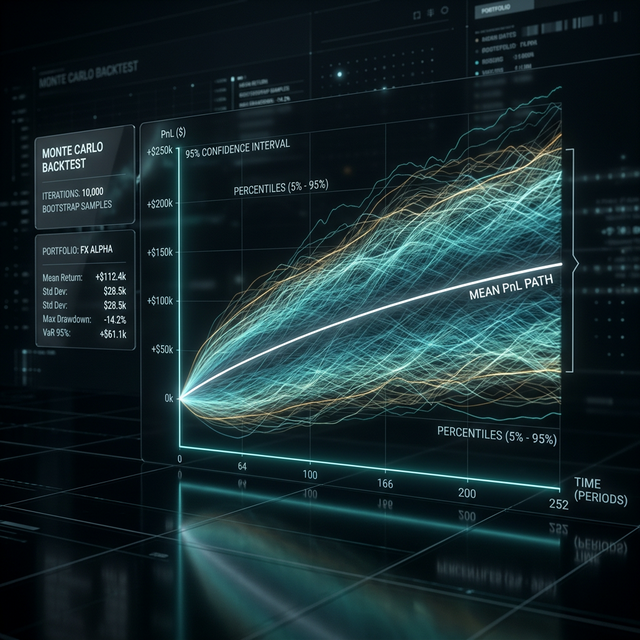
扇形图直观地展示了可能结果的离散程度。扇形窄表示策略稳定。扇形宽表示结果很大程度上取决于交易序列的"运气"。
 扇形图(左)显示了可能的权益轨迹范围,直方图(右)显示了最终收益的概率密度分布,标注了置信区间(5%、50%、95%)。
扇形图(左)显示了可能的权益轨迹范围,直方图(右)显示了最终收益的概率密度分布,标注了置信区间(5%、50%、95%)。
自助法允许你回答一个关键问题:策略亏损X%资金的概率是多少?
ruin_threshold = -0.20
prob_ruin = (df['max_dd'] < ruin_threshold).mean()
print(f"P(MaxDD < -20%) = {prob_ruin:.1%}")
prob_loss = (df['final_pnl'] < 0).mean()
print(f"P(PnL < 0) = {prob_loss:.1%}")
worst_5pct = df['final_pnl'].quantile(0.05)
cvar = df[df['final_pnl'] <= worst_5pct]['final_pnl'].mean()
print(f"CVaR(5%) = {cvar:.1%}")
这些指标不可能从单次回测运行中获得。而它们对于做出策略上线决策至关重要。
关于深度回撤为何在数学上是危险的以及收益不对称性如何运作的更多内容,请阅读我们的文章亏损与利润的不对称性。
该方法有一些需要了解的局限性。
经典自助法假设交易是独立的。现实中往往并非如此——策略可能存在连续盈利和连续亏损的序列(streak)。如果自相关性显著,请使用分块自助法:
def block_bootstrap(returns, block_size=10, n_simulations=10000):
"""保留局部依赖结构的自助法。"""
n = len(returns)
results = []
for _ in range(n_simulations):
starts = np.random.randint(0, n - block_size + 1, size=n // block_size + 1)
sampled = np.concatenate([returns[s:s+block_size] for s in starts])[:n]
equity = np.cumprod(1 + sampled)
results.append({
"final_pnl": equity[-1] - 1,
"max_dd": max_drawdown(equity),
})
return pd.DataFrame(results)
分块自助法保留了连续交易之间的局部依赖性,为MaxDD提供了更真实的置信区间。
自助法使用原始交易分布。如果市场发生了结构性变化(例如波动率下降或流动性变化),历史交易可能不具代表性。为此可以:
自助法在交易数 n > 30 时是可靠的。如果你只有10笔交易——再多的重采样也无济于事。491笔交易是优秀的样本,结果值得信赖。
| 方法 | 提供什么 | 复杂度 | 时间 | 何时使用 |
|---|---|---|---|---|
| 单次回测 | 一个点估计 | 最低 | 秒级 | 绝不作为最终结果 |
| 前推分析 | 样本外指标 | 中等 | 分钟级 | 检查过拟合 |
| 蒙特卡洛自助法 | 置信区间 | 最低 | 约2秒 | 上线前必做 |
| 蒙特卡洛路径 | 新价格路径 | 高 | 分钟到小时 | 压力测试 |
| 交叉验证 | 各折的平均指标 | 中等 | 分钟级 | 参数调优 |
蒙特卡洛自助法是唯一能在最短时间内提供完整风险全景的方法。
以下是我们推荐的蒙特卡洛自助法结果解读方式:
可以部署到生产环境,如果:
需要改进,如果:
不要部署,如果:
在marketmaker.cc,我们开发了自己的回测引擎,蒙特卡洛自助法是我们流程中不可或缺的一部分。每个策略在获准进行实盘交易之前都会自动经过自助法分析。
我们将自助法直接集成到回测引擎中:运行结束后,你得到的不仅是最终PnL,而是包含置信区间、扇形图、破产概率以及分块自助法与标准自助法对比的完整报告。这额外花费2-3秒——为了理解真实风险,这是微不足道的代价。
根据我们的经验:大约30%的策略在单点估计下看起来很有吸引力,但在蒙特卡洛自助法后被筛除。它们的第5百分位PnL变为负数,或MaxDD不可接受。如果没有自助法,这些策略就会进入生产环境,很可能会造成亏损。
蒙特卡洛自助法只需约10行代码和约2秒计算时间。它将回测中的单个数字转化为带有置信区间的完整分布。这可能是所有量化分析工具中投资回报率最高的:
如果你还没有使用自助法——今天就把它加入你的流程。这是了解你能在多大程度上信任回测结果的唯一方法。
@software{soloviov2026montecarlobootstrap, author = {Soloviov, Eugen}, title = {蒙特卡洛自助法:如何用10行代码获取回测的置信区间}, year = {2026}, url = {https://marketmaker.cc/ru/blog/post/monte-carlo-bootstrap-backtest}, version = {0.1.0}, description = {为什么回测的单点估计是一种危险的幻觉。蒙特卡洛自助法如何在2秒内计算出PnL和MaxDD的95\%置信区间,以及为什么这是策略上线前的必要步骤。} }