免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
"回测无幻觉"系列第6篇
你运行了 study.optimize(),Optuna找到了PnL +87%的参数组合。你很兴奋,准备将策略投入生产。两周实盘交易后,PnL接近零。发生了什么?
优化器在参数空间中找到了一根针尖。参数完美地拟合了历史交易序列——但市场条件的最微小偏差就会摧毁整个结构。这是经典的过拟合,本可以在启动之前就被发现。
在上一篇文章中,我们比较了坐标下降法和贝叶斯优化,展示了为什么Optuna能更高效地找到最优值。今天是下一步:如何确保找到的最优值是稳健的,而不是对噪声的拟合结果。
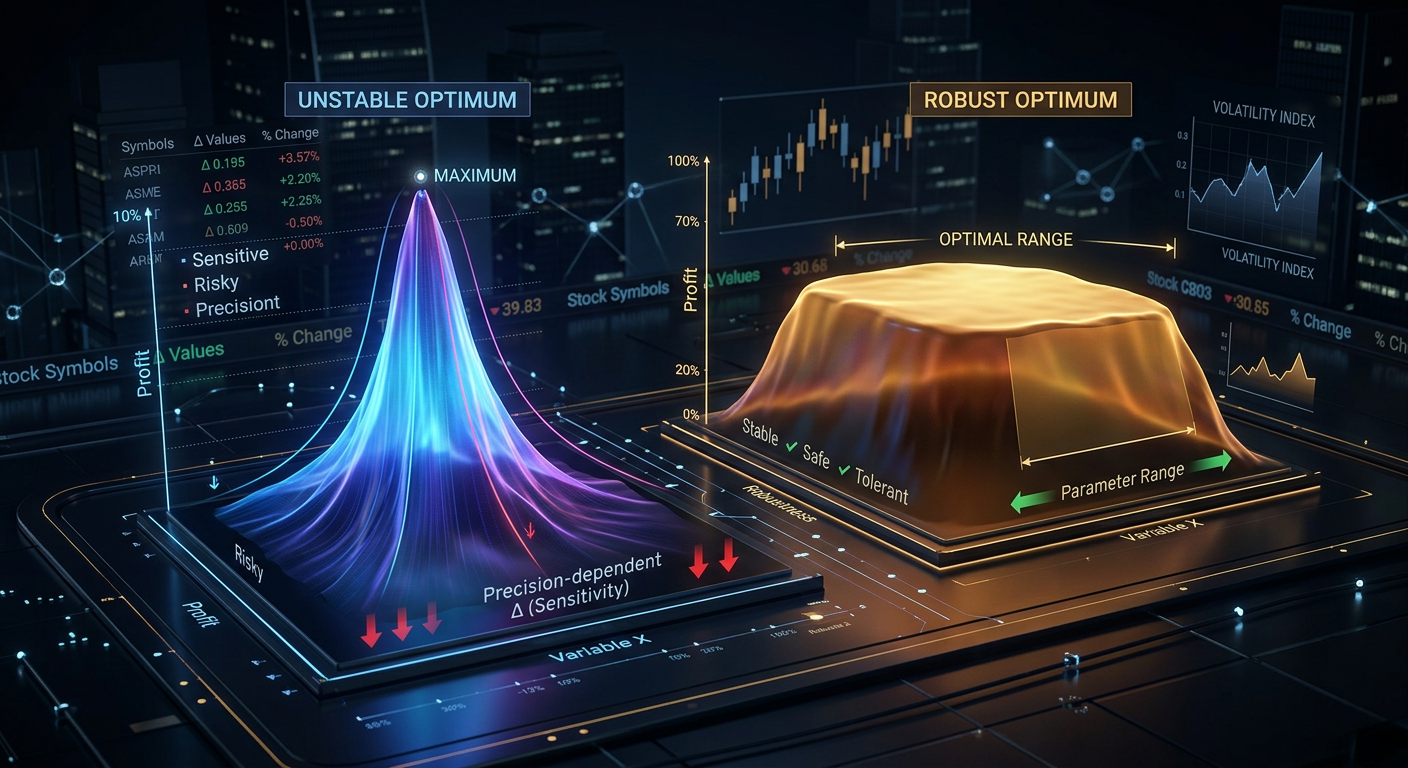
策略参数优化是在多维空间中寻找最大值。问题在于最大值有两种类型:
平台(plateau) ——宽阔平坦的区域,PnL在参数变化时始终保持较高。即使市场条件将有效参数偏移10-20%,策略仍将继续盈利。
尖峰(sharp peak) ——狭窄的顶点,只有在精确的参数值下PnL才高。偏移一步就会使盈利崩溃。这几乎可以确定是过拟合:优化器找到了历史数据的伪像,而非稳定的规律。
登山比喻:平台是一个可以安全行走的山地高原。尖峰是一根只能在上面保持平衡的针尖。
想象一张等高线图,两轴是策略的两个参数,颜色代表PnL。两种模式在视觉上很容易区分:
平台(稳健最优):
想象一张热力图:中心是一个约占整个图三分之一大小的明亮黄色矩形。颜色逐渐过渡到橙色,然后向边缘变为红色。最优值不是一个点,而是一个区域。
尖峰(过拟合):
想象同样的热力图,但中心只有一个微小的黄色点,立即被蓝色和紫色包围。唯一"正确"的参数组合。
最简单的方法——固定除一个外的所有参数,观察PnL如何依赖于该参数的值。Optuna为此提供了 plot_slice:
import optuna
from optuna.visualization import plot_slice
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=500)
fig = plot_slice(study, params=["htf_entry_sell", "ltf_momentum", "stop_loss_pct"])
fig.show()
在切片图上看什么:
等高线图同时显示两个参数的交互作用。这是平台分析的关键工具,因为参数很少独立作用——入场和退出阈值、时间框架和仓位大小是相互关联的。
from optuna.visualization import plot_contour
fig = plot_contour(study, params=["htf_entry_sell", "htf_exit_buy"])
fig.show()
稳健参数对的等高线图看起来像丘陵平原的地形图:平滑宽阔的等高线,大面积同色区域。脆弱参数对的等高线图——像火山锥的地图:围绕单一点的紧密同心环。
对于有12个分离参数的策略,这给出 个成对等高线图。不必全部研究——从Optuna评为最重要的参数开始。
Optuna可以估算每个参数对目标函数的贡献:
from optuna.visualization import plot_param_importances
fig = plot_param_importances(study)
fig.show()
参数重要性图是一个水平直方图。参数按其对PnL方差的贡献降序排列。前3-4个参数通常解释了70-80%的方差。
规则: 如果一个参数解释的PnL方差不到2%,其值对结果几乎无关紧要——它天然是稳健的。将平台分析聚焦在最重要的前5个参数上。
import optuna
from optuna.visualization import plot_slice
fig = plot_slice(study, params=[
"htf_entry_sell", "htf_entry_buy",
"ltf_momentum_threshold", "stop_loss_pct",
"take_profit_pct", "trailing_stop_pct"
])
fig.update_layout(height=800, title="Parameter Slice Plots")
fig.show()
结果是一个散点图网格。每个子图显示目标函数值(PnL,Y轴)与单个参数值(X轴)的关系。点是各个trial。对于稳健参数,最佳点(最高PnL)分布在X的宽范围内。对于脆弱参数——聚集在狭窄的列中。
from optuna.visualization import plot_contour
important_pairs = [
["htf_entry_sell", "htf_entry_buy"],
["htf_entry_sell", "stop_loss_pct"],
["ltf_momentum_threshold", "take_profit_pct"],
]
for params in important_pairs:
fig = plot_contour(study, params=params)
fig.update_layout(title=f"Contour: {params[0]} vs {params[1]}")
fig.show()
每个等高线图是一张以两个参数为轴的热力图。颜色编码参数空间给定区域的平均PnL。黄色/绿色——高PnL,蓝色/紫色——低PnL。等高线连接PnL相同的点。
from optuna.visualization import plot_param_importances
fig = plot_param_importances(
study,
evaluator=optuna.importance.FanovaImportanceEvaluator()
)
fig.show()
fANOVA(函数方差分析)将目标函数的方差分解到各参数及其交互作用上。这比简单相关更强大,因为它考虑了非线性效应。
视觉评估是主观的。我们需要数字。以下三个指标将"平台"概念形式化。
PnL变化与参数变化的比率:
其中 是参数 偏离最优值 时的PnL下降。
解读:
参数区域的宽度,在该区域内PnL保持在最优值的 以内:
相对平台宽度:
其中分母是参数的完整搜索范围。
解读:
所有参数的综合指标:
其中 是来自fANOVA的参数 的归一化重要性()。
加权宽度的乘积是一个严格的指标:如果任何一个重要参数有狭窄的平台, 就会很低。不重要的参数( 很小)几乎没有影响。
解读:
import numpy as np
import optuna
from optuna.importance import FanovaImportanceEvaluator
from typing import Dict, List, Tuple
def compute_sensitivity_ratio(
study: optuna.Study,
param_name: str,
n_steps: int = 20,
) -> float:
"""
计算单个参数的敏感度比率。
将所有参数固定在最佳值,变化param_name,
通过trial插值估计PnL下降。
"""
best_trial = study.best_trial
best_value = best_trial.values[0]
best_param = best_trial.params[param_name]
all_trials = [t for t in study.trials if t.state == optuna.trial.TrialState.COMPLETE]
all_trials.sort(key=lambda t: t.values[0], reverse=True)
top_trials = all_trials[:max(10, len(all_trials) // 5)]
param_values = np.array([t.params[param_name] for t in top_trials])
pnl_values = np.array([t.values[0] for t in top_trials])
if best_param == 0 or best_value == 0:
return float('inf')
from numpy.polynomial import polynomial as P
coeffs = np.polyfit(param_values, pnl_values, deg=2)
dpnl_dparam = 2 * coeffs[0] * best_param + coeffs[1]
sensitivity = abs(dpnl_dparam * best_param / best_value)
return sensitivity
def compute_plateau_width(
study: optuna.Study,
param_name: str,
threshold_pct: float = 10.0,
) -> Tuple[float, float]:
"""
计算绝对和相对平台宽度。
Returns:
(absolute_width, relative_width)
"""
best_value = study.best_value
threshold = best_value * (1 - threshold_pct / 100)
trials = [t for t in study.trials if t.state == optuna.trial.TrialState.COMPLETE]
good_trials = [t for t in trials if t.values[0] >= threshold]
if not good_trials:
return 0.0, 0.0
good_params = [t.params[param_name] for t in good_trials]
all_params = [t.params[param_name] for t in trials]
plateau_min = min(good_params)
plateau_max = max(good_params)
absolute_width = plateau_max - plateau_min
search_range = max(all_params) - min(all_params)
relative_width = absolute_width / search_range if search_range > 0 else 0
return absolute_width, relative_width
def compute_robustness_score(
study: optuna.Study,
threshold_pct: float = 10.0,
) -> Dict:
"""
计算综合稳健性得分。
Returns:
包含逐参数指标和最终得分的dict
"""
evaluator = FanovaImportanceEvaluator()
importances = optuna.importance.get_param_importances(
study, evaluator=evaluator
)
results = {}
total_importance = sum(importances.values())
for param_name, importance in importances.items():
sensitivity = compute_sensitivity_ratio(study, param_name)
abs_width, rel_width = compute_plateau_width(
study, param_name, threshold_pct
)
weight = importance / total_importance
results[param_name] = {
"importance": importance,
"weight": weight,
"sensitivity_ratio": sensitivity,
"plateau_width_abs": abs_width,
"plateau_width_rel": rel_width,
}
log_score = sum(
r["weight"] * np.log(max(r["plateau_width_rel"], 1e-10))
for r in results.values()
)
robustness_score = np.exp(log_score)
return {
"robustness_score": robustness_score,
"parameters": results,
"verdict": (
"robust" if robustness_score > 0.1
else "check" if robustness_score > 0.01
else "overfitting"
),
}
report = compute_robustness_score(study, threshold_pct=10.0)
print(f"Robustness score: {report['robustness_score']:.4f}")
print(f"Verdict: {report['verdict']}")
print()
for name, metrics in report["parameters"].items():
print(f" {name}:")
print(f" Importance: {metrics['importance']:.3f}")
print(f" Sensitivity: {metrics['sensitivity_ratio']:.2f}")
print(f" Plateau width: {metrics['plateau_width_rel']:.1%}")
print()
示例输出:
Robustness score: 0.1482
Verdict: robust
htf_entry_sell:
Importance: 0.312
Sensitivity: 0.38
Plateau width: 42.5%
htf_entry_buy:
Importance: 0.251
Sensitivity: 0.45
Plateau width: 38.1%
ltf_momentum_threshold:
Importance: 0.187
Sensitivity: 1.21
Plateau width: 22.3%
stop_loss_pct:
Importance: 0.098
Sensitivity: 0.67
Plateau width: 31.0%
take_profit_pct:
Importance: 0.072
Sensitivity: 0.89
Plateau width: 28.4%
trailing_delta:
Importance: 0.031
Sensitivity: 0.22
Plateau width: 55.2%
让我们检查三个具有12个分离参数的策略。每个策略都经过了500次trial的Optuna优化。
策略A的参数形成了一个宽阔的平台。以关键参数 htf_entry_sell 为例:
如果将其想象为一维图(X轴——htf_entry_sell 值,Y轴——PnL),你会看到一条平顶的平缓抛物线。范围0.010-0.030是平台,PnL保持在最优值的±25%以内。
敏感度比率: ——稳健。
10%阈值下的平台宽度:从0.013到0.027,。
策略B在少量交易上进行了优化。参数 htf_entry_sell:
在图上——一条不对称的陡峭曲线。平台仅存在于0.015-0.020的狭窄范围内。最优值右侧是悬崖。
敏感度比率: ——中等敏感度,但在40笔交易下这是一个红色警报。小样本+窄平台=过拟合概率高。
10%阈值下的平台宽度:从0.016到0.020,。
策略C展示了惊人的PnL,但平台分析揭示了问题:
htf_entry_sell 最优值:0.022在图上——特征性的"针":0.022处非常高的峰值,各方向急剧下降。等高线图会显示一个立即被冷色包围的亮点。
敏感度比率: ——脆弱。尽管有400笔交易,策略过度依赖单个参数的精确值。
10%阈值下的平台宽度:从0.021到0.023,。
| 策略 | PnL | 交易数 | 敏感度 | 平台宽度 | 稳健性得分 | 判定 |
|---|---|---|---|---|---|---|
| 策略A | +55% | ~500 | 0.44 | 35% | 0.148 | 稳健 |
| 策略B | +25% | ~40 | 1.64 | 10% | 0.032 | 需检查(小样本) |
| 策略C | +300% | ~400 | 3.79 | 5% | 0.008 | 过拟合 |
悖论: PnL +300%的策略C具有最差的稳健性得分。"谦虚"的+55%策略A是最稳健的。这是平台分析的典型结果:亮眼的数字往往掩盖了脆弱性。
每个策略的置信区间可以通过Monte Carlo自举法进一步验证——它会显示重新采样交易时PnL的分散程度。
对于最重要的参数对,构建3D曲面和热力图是有用的。这提供了对景观形状的直观理解。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
def plot_parameter_landscape(
study: "optuna.Study",
param_x: str,
param_y: str,
grid_size: int = 50,
):
"""
为一对参数构建3D曲面图和热力图。
"""
trials = [t for t in study.trials
if t.state == optuna.trial.TrialState.COMPLETE]
x_vals = np.array([t.params[param_x] for t in trials])
y_vals = np.array([t.params[param_y] for t in trials])
z_vals = np.array([t.values[0] for t in trials])
from scipy.interpolate import griddata
xi = np.linspace(x_vals.min(), x_vals.max(), grid_size)
yi = np.linspace(y_vals.min(), y_vals.max(), grid_size)
Xi, Yi = np.meshgrid(xi, yi)
Zi = griddata((x_vals, y_vals), z_vals, (Xi, Yi), method='cubic')
fig = plt.figure(figsize=(18, 7))
ax1 = fig.add_subplot(121, projection='3d')
surf = ax1.plot_surface(Xi, Yi, Zi, cmap=cm.viridis, alpha=0.85,
edgecolor='none')
ax1.set_xlabel(param_x)
ax1.set_ylabel(param_y)
ax1.set_zlabel('PnL, %')
ax1.set_title('3D Parameter Landscape')
fig.colorbar(surf, ax=ax1, shrink=0.5)
ax2 = fig.add_subplot(122)
hm = ax2.pcolormesh(Xi, Yi, Zi, cmap=cm.viridis, shading='auto')
contours = ax2.contour(Xi, Yi, Zi, levels=10, colors='white',
linewidths=0.8, alpha=0.7)
ax2.clabel(contours, inline=True, fontsize=8, fmt='%.0f%%')
best = study.best_trial
ax2.scatter(best.params[param_x], best.params[param_y],
color='red', s=100, marker='*', zorder=5, label='Optimum')
ax2.set_xlabel(param_x)
ax2.set_ylabel(param_y)
ax2.set_title('Contour Heatmap')
ax2.legend()
fig.colorbar(hm, ax=ax2)
plt.tight_layout()
plt.savefig(f'landscape_{param_x}_vs_{param_y}.png', dpi=150)
plt.show()
稳健策略的3D曲面图类似于桌山——平坦的顶部和平缓的斜坡。脆弱策略的——像马特洪峰一样的尖顶。热力图补充了3D视图,以俯视投影显示相同信息并带有等高线。
八个迹象表明优化找到的是过拟合而非真实规律:
如果10%的参数偏移导致PnL下降超过20%——最优值是脆弱的。
如果"好"的区域占探索范围的不到10%——优化器很可能找到了伪像。
如果最佳trial是相对于其余trial的异常值而非"山顶"——这不是平台。
top_3_mean = np.mean(sorted([t.values[0] for t in study.trials
if t.state == optuna.trial.TrialState.COMPLETE],
reverse=True)[:3])
median_pnl = np.median([t.values[0] for t in study.trials
if t.state == optuna.trial.TrialState.COMPLETE])
outlier_ratio = top_3_mean / median_pnl
if outlier_ratio > 2.5:
print(f"WARNING: Top trials are {outlier_ratio:.1f}x above median — possible overfitting")
小样本+高PnL=估计的高方差。40笔交易的平台分析本身就不可靠。对于这类策略,Monte Carlo自举法至关重要。
如果等高线图在灰色背景上显示单一亮点——这不是策略,这是拟合到数据的组合。
对于12个参数每个10个值,搜索空间包含 种组合。Optuna探索约500种。在如此大的空间中随机找到"好"的伪像的概率很高。参数越多,平台分析应越严格。
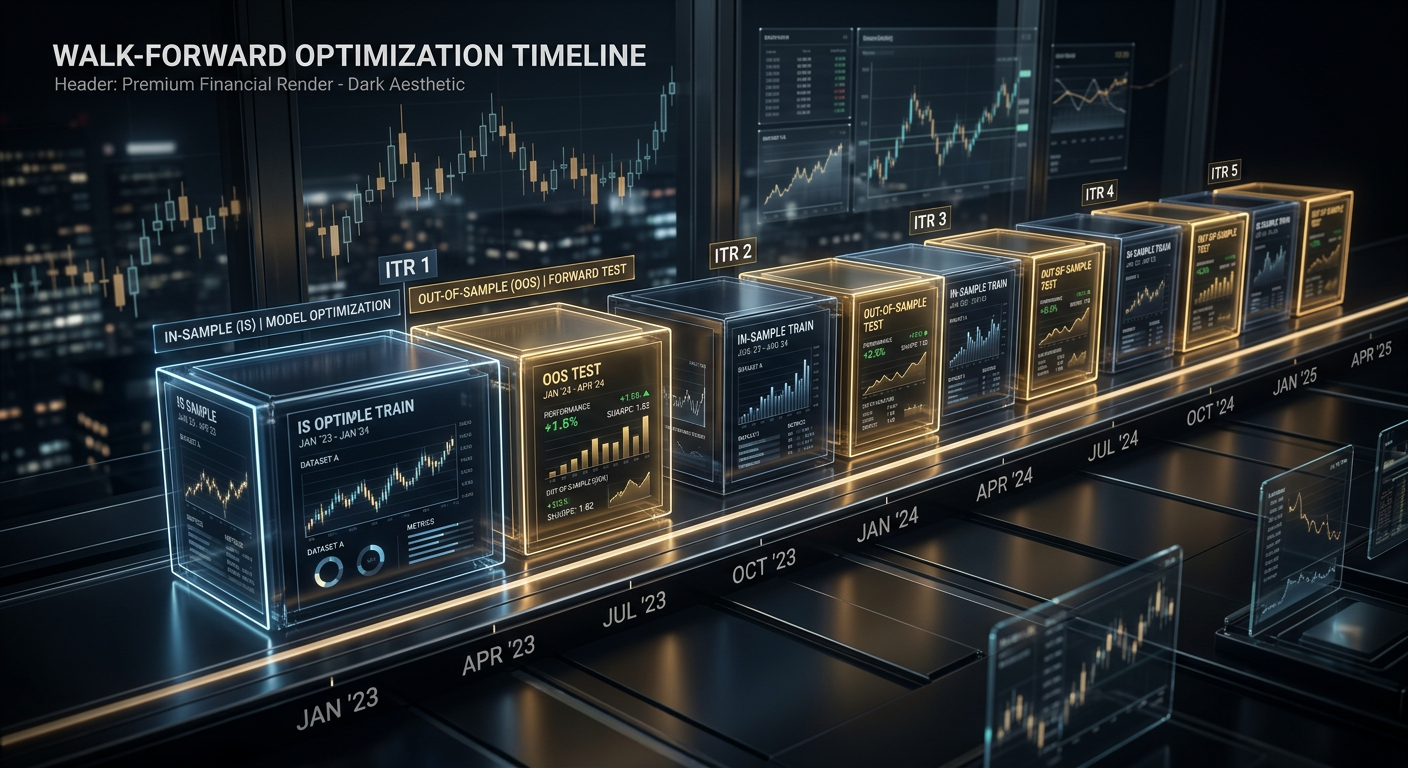
如果样本内PnL为+87%而Walk-Forward显示+12%——优化将参数拟合到了训练期。更多内容请参见Walk-Forward优化文章。
如果最优值与搜索网格边界重合——最优值可能在范围之外。扩大范围并重新运行优化。
将所有内容整合到每次优化后生成的单一报告中:
import json
from datetime import datetime
def generate_plateau_report(
study: "optuna.Study",
strategy_name: str,
n_trades: int,
threshold_pct: float = 10.0,
) -> dict:
"""
生成完整的平台分析报告。
"""
robustness = compute_robustness_score(study, threshold_pct)
red_flags = []
sorted_params = sorted(
robustness["parameters"].items(),
key=lambda x: x[1]["importance"],
reverse=True
)
for name, metrics in sorted_params[:3]:
if metrics["sensitivity_ratio"] > 2.0:
red_flags.append(
f"High sensitivity for {name}: "
f"S={metrics['sensitivity_ratio']:.2f}"
)
for name, metrics in robustness["parameters"].items():
if metrics["plateau_width_rel"] < 0.05:
red_flags.append(
f"Narrow plateau for {name}: "
f"W={metrics['plateau_width_rel']:.1%}"
)
all_values = sorted(
[t.values[0] for t in study.trials
if t.state == optuna.trial.TrialState.COMPLETE],
reverse=True
)
if len(all_values) > 10:
top3 = np.mean(all_values[:3])
med = np.median(all_values)
if med > 0 and top3 / med > 2.5:
red_flags.append(
f"Top trials are outliers: "
f"{top3:.1f} vs median {med:.1f} "
f"({top3/med:.1f}x)"
)
if n_trades < 50:
red_flags.append(f"Low trade count: {n_trades}")
report = {
"strategy": strategy_name,
"timestamp": datetime.now().isoformat(),
"best_pnl": study.best_value,
"n_trials": len(study.trials),
"n_trades": n_trades,
"robustness_score": robustness["robustness_score"],
"verdict": robustness["verdict"],
"red_flags": red_flags,
"parameters": robustness["parameters"],
}
return report
report = generate_plateau_report(
study, strategy_name="Strategy A", n_trades=491
)
print(json.dumps(report, indent=2, default=str))
示例输出:
{
"strategy": "Strategy A",
"best_pnl": 55.2,
"n_trials": 500,
"n_trades": 491,
"robustness_score": 0.1482,
"verdict": "robust",
"red_flags": [],
"parameters": {
"htf_entry_sell": {
"importance": 0.312,
"sensitivity_ratio": 0.44,
"plateau_width_rel": 0.35
}
}
}
平台分析和Walk-Forward验证(WFO)是互补的方法:
一个策略可能通过平台分析(宽平台)但未通过Walk-Forward(市场机制改变)。反之亦然——它可能在固定参数上通过Walk-Forward,但具有脆弱的最优值。
建议: 始终使用两种方法。如果策略通过了平台分析()并且 Walk-Forward()——这是稳健性的强信号。更多详情请参见Walk-Forward优化文章。
要评估每个阶段的PnL置信区间,请应用Monte Carlo自举法。要正确比较具有不同活跃时间的策略,请使用按活跃时间计算的PnL指标。
限制参数数量。 参数越少——平台越可靠。5-7个参数是合理的上限。12个已经需要更加谨慎。
设置有意义的范围。 如果实际范围是0.005到0.05,不要将 htf_entry_sell 设置为0.001到1.0。不必要的宽范围会创造平台的幻觉。
使用足够的trial。 对于12个参数,至少300-500次trial。对于可靠的平台分析——1000+次。
关注收敛性。 如果Optuna在400次trial后仍在找到明显更好的解——过程尚未收敛,平台分析将不可靠。
谨慎使用剪枝。 激进的剪枝(MedianPruner)可能会裁剪掉在早期步骤中看起来较差但对构建完整景观图很重要的trial。
自动生成平台报告。 将 generate_plateau_report() 集成到优化流程中。不要依赖视觉评估——使用数字。
检查前5个参数。 如果fANOVA显示3个参数解释了80%的方差——其余9个可以检查得不那么仔细。
与基线策略比较。 如果使用默认参数(未优化)的策略显示+30%,优化后+55%——差距只有25个百分点,平台很可能是宽的。如果默认显示0%,优化后+300%——所有盈利都依赖于精确的参数拟合。
最终检查——Walk-Forward。 平台分析是稳健性的必要但非充分条件。务必进行样本外验证。
参数优化是一个强大的工具,但没有平台分析就像玩轮盘赌。你不知道自己是找到了稳定的规律还是将模型拟合到了噪声。
平台分析的三条规则:
计算稳健性得分。 加权平台宽度的乘积给出一个总结所有参数稳健性的单一数字。 ——绿灯。
关键参数的敏感度比率 < 1。 如果10%的参数偏移导致不到10%的PnL下降——参数是稳健的。如果更多——要谨慎。
可视化等高线图。 没有任何指标能替代对景观形状的理解。平坦的桌山——好。尖锐的针——差。
平台分析在优化后只需5分钟,可以节省数周的亏损实盘交易。这是 study.optimize() 和启动机器人之间的必要步骤。
@article{soloviov2026plateauanalysis, author = {Soloviov, Eugen}, title = {Plateau Analysis: How to Distinguish a Robust Optimum from Overfitting}, year = {2026}, url = {https://marketmaker.cc/zh/blog/post/plateau-analysis-overfitting}, version = {0.1.0}, description = {为什么找到最佳策略参数只是工作的一半。如何从视觉和定量两方面区分稳定的平台与脆弱的尖峰,以及为什么Optuna等高线图是将优化后的策略投入生产前的必要步骤。} }