免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
多时间框架策略同时使用多个时间框架:日线确定趋势方向,小时线确定入场点,5分钟线确定执行时机。每个时间框架需要自己的指标:移动平均线、振荡器、支撑阻力位。
单次回测很简单——从分钟数据重新计算时间框架,计算指标,运行策略。但在大规模优化时——需要测试数千种参数组合——每次迭代重新计算时间框架和指标就成了瓶颈。对两年的分钟数据进行一次遍历意味着处理超过一百万根K线,重复一千次是极其浪费的。
解决方案:一次预计算所有内容并缓存到 parquet 文件中。
典型的多时间框架回测流水线如下:
for params in parameter_grid:
df_1m = load_candles("ETHUSDT", "1m", start, end)
df_5m = resample_ohlcv(df_1m, "5m")
df_1h = resample_ohlcv(df_1m, "1h")
df_4h = resample_ohlcv(df_1m, "4h")
df_1d = resample_ohlcv(df_1m, "D")
ma_1h = compute_ma(df_1h["close"], length=params["ma_1h_len"])
ma_4h = compute_ma(df_4h["close"], length=params["ma_4h_len"])
ma_1d = compute_ma(df_1d["close"], length=params["ma_1d_len"])
result = run_strategy(df_1m, ma_1h, ma_4h, ma_1d, params)
每次迭代都会重新计算第1-3步,尽管数据完全相同。只有策略的阈值参数会改变(第4步)。这就好比每次只想换个墙壁颜色,却要把整栋房子重建一遍。
关键观察:时间框架和指标仅取决于分钟数据和指标参数,而非策略参数。如果我们固定所需指标的集合,就可以一次计算并保存。
方案:
第1步(一次性):
分钟级K线 → 时间框架重采样 → 指标计算 → Parquet 文件
第2步(多次):
Parquet 文件 → 使用不同参数的策略 → 结果
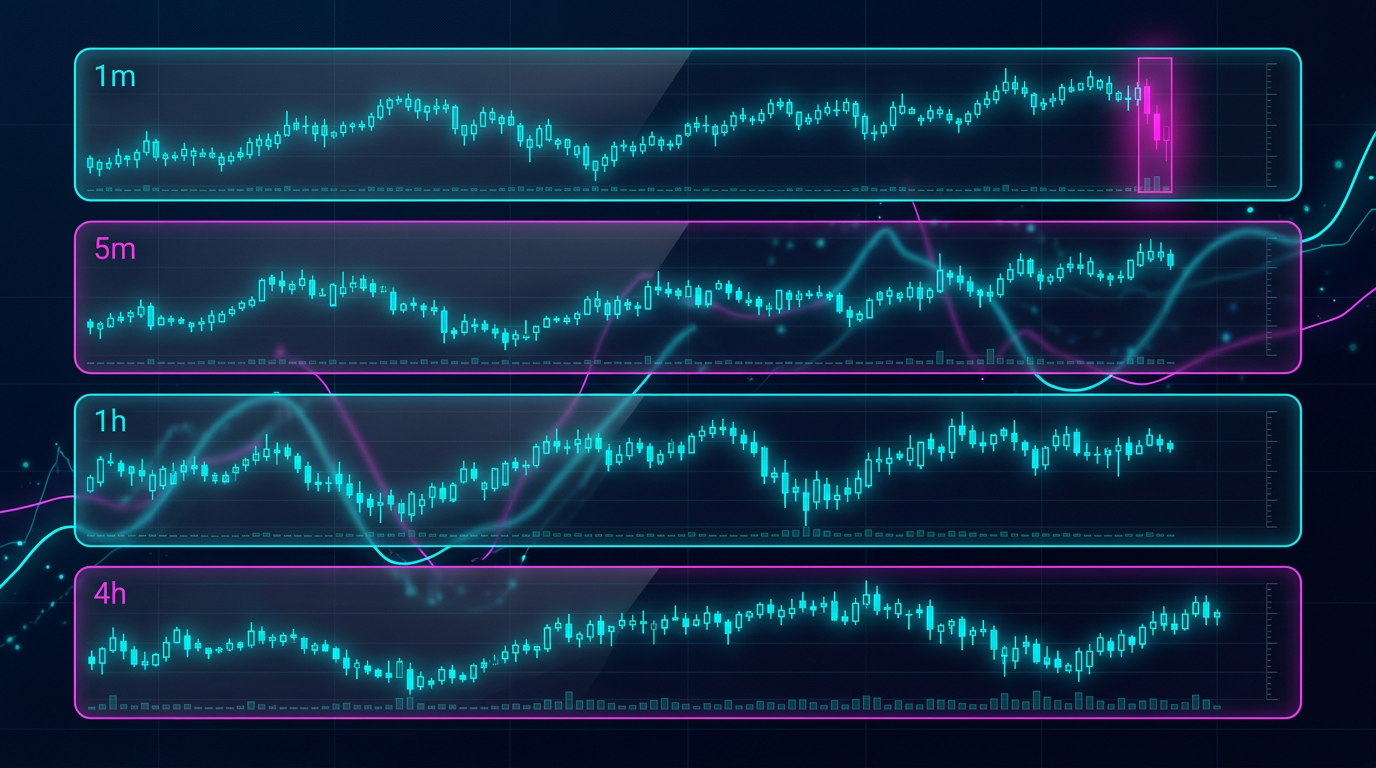
我们拥有完整的分钟级K线存档。从中可以精确重现任何更高时间框架。但有一个细节:使用标准 resample 时,每个周期只得到一行(每小时一行,每4小时一行等)。这不适用于逐分钟回测——我们需要知道每分钟的指标值。
因此,我们为每根分钟K线模拟更高时间框架的值,模拟机器人在实时环境中看到的数据:
这种方法保证回测看到的数据与机器人实时看到的完全一致。不会窥探未来——每根分钟K线严格按照该时刻可用的数据进行处理。
class RunningCandleBuffer:
"""
使用1分钟K线模拟更高时间框架K线的实时更新。
"""
def __init__(self, period_seconds: int):
self.period = period_seconds # 日线为86400,1小时为3600
self.closed_bars = []
self.current_bar = None
def update(self, timestamp, open_, high, low, close, volume):
bar_start = self._align_to_period(timestamp)
if self.current_bar is None or bar_start != self.current_bar['start']:
if self.current_bar is not None:
self.closed_bars.append(self.current_bar)
self.current_bar = {
'start': bar_start,
'open': open_, 'high': high,
'low': low, 'close': close,
'volume': volume,
}
else:
self.current_bar['high'] = max(self.current_bar['high'], high)
self.current_bar['low'] = min(self.current_bar['low'], low)
self.current_bar['close'] = close
self.current_bar['volume'] += volume
return self.closed_bars + [self.current_bar]
为每个更高时间框架创建单独的 RunningCandleBuffer。每收到一根分钟K线,所有缓冲区都会更新,我们就能获得每个时间框架的当前状态——就像机器人在实时运行一样。
预计算的结果是一个 parquet 文件,其中每行对应一根分钟K线,列包含:
timestamp — 分钟K线时间戳
open, high, low, — 分钟K线 OHLCV
close, volume
close_5m — 该时刻模拟的5分钟K线收盘价
close_1h — 模拟的1小时K线收盘价
close_4h — 模拟的4小时K线收盘价
close_1d — 模拟的日线收盘价
ma_20_1h — 1小时的 MA(20),在该分钟重新计算
ma_50_1h — 1小时的 MA(50)
ma_20_4h — 4小时的 MA(20)
ma_50_4h — 4小时的 MA(50)
ma_6_1d — 日线的 MA(6)
ma_12_1d — 日线的 MA(12)
cross_ma_1h — 1小时 MA 交叉信号('buy'/'sell'/None)
cross_ma_4h — 4小时 MA 交叉信号
cross_ma_1d — 日线 MA 交叉信号
separation_1h — 1小时 MA 偏离度(百分比)
separation_4h — 4小时 MA 偏离度(百分比)
separation_1d — 日线 MA 偏离度(百分比)
每个值反映了对应分钟K线时刻指标的真实状态——考虑了更高时间框架的未收盘K线。
def precompute_cache(
df_1m: pd.DataFrame,
timeframes: dict[str, int], # {"5m": 300, "1h": 3600, "4h": 14400, "D": 86400}
indicators: dict, # {"ma_20": 20, "ma_50": 50}
) -> pd.DataFrame:
"""
一次遍历所有分钟K线。
返回包含模拟时间框架和指标的 DataFrame。
"""
buffers = {tf: RunningCandleBuffer(secs) for tf, secs in timeframes.items()}
n = len(df_1m)
result = {}
for tf_name, buf in buffers.items():
closes = np.zeros(n)
ma_values = {name: np.full(n, np.nan) for name in indicators}
for i in range(n):
row = df_1m.iloc[i]
bars = buf.update(
df_1m.index[i],
row['open'], row['high'], row['low'], row['close'], row['volume']
)
all_closes = [b['close'] for b in bars]
closes[i] = all_closes[-1]
for ind_name, length in indicators.items():
if len(all_closes) >= length:
ma_values[ind_name][i] = np.mean(all_closes[-length:])
result[f'close_{tf_name}'] = closes
for ind_name in indicators:
result[f'{ind_name}_{tf_name}'] = ma_values[ind_name]
cache_df = pd.DataFrame(result, index=df_1m.index)
cache_df = pd.concat([df_1m[['open', 'high', 'low', 'close', 'volume']], cache_df], axis=1)
return cache_df
cache = precompute_cache(
df_1m,
timeframes={"5m": 300, "1h": 3600, "4h": 14400, "D": 86400},
indicators={"ma_20": 20, "ma_50": 50, "ma_6": 6, "ma_12": 12},
)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
现在优化变成了这样:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
for params in parameter_grid:
result = run_strategy(cache, params)
策略直接使用预构建的列——无需重复遍历百万根K线,无需重新计算MA,无需模拟时间框架。只需从 DataFrame 读取数据并检查入场/出场条件。
Parquet 是一种列式数据存储格式,非常适合此任务:
ma_20_4h 和 ma_50_4h,parquet 只读取这些列,跳过其余列。如果策略需要新指标(RSI、MACD、布林带),只需:
cache = pd.read_parquet("cache_ETHUSDT_2024_2026.parquet")
rsi_cols = compute_rsi_for_timeframes(df_1m, timeframes, length=14)
cache = pd.concat([cache, rsi_cols], axis=1)
cache.to_parquet("cache_ETHUSDT_2024_2026.parquet")
| 朴素方法 | 聚合缓存 | |
|---|---|---|
| 时间框架重采样 | 每次迭代 | 一次 |
| 指标计算 | 每次迭代 | 一次 |
| 单次迭代时间 | 数分钟 | 不到一秒 |
| 1000次迭代 | 数天 | 数分钟 |
| 内存消耗 | 加载1分钟数据 + 重新计算 | 单个 DataFrame |
| 回测-实盘一致性 | 取决于实现 | 有保证(模拟 = 实时) |
聚合 parquet 缓存方法同时解决了两个问题:
正确性。 通过 RunningCandleBuffer 从分钟K线模拟时间框架,保证回测看到的数据与机器人实时看到的一致——不会窥探未来,也不会有人为延迟。
速度。 预计算的时间框架和指标使得在数分钟内测试数千种参数组合成为可能,而非数天。
思路很简单:一次计算——多次使用。分钟K线是源数据。其他一切都是衍生数据,可以预先计算并缓存。Parquet 使这个缓存紧凑、快速且便于使用。
关于如何通过从分钟到秒和毫秒的自适应下钻来提高成交模拟精度,请参阅文章 自适应下钻:从分钟到毫秒的可变粒度回测。
@article{soloviov2026parquetcache, author = {Soloviov, Eugen}, title = {Aggregated Parquet Cache: How to Speed Up Multi-Timeframe Backtests by Hundreds of Times}, year = {2026}, url = {https://marketmaker.cc/ru/blog/post/parquet-cache-multitimeframe-backtest}, description = {如何从分钟级K线预计算时间框架和指标,保存为 parquet 文件,并在大规模策略测试中使用,避免重复计算。} }