免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
你用回测跑了一个策略。夏普比率 2.1,最大回撤 -8%,PnL +67%。你启动了机器人。一个月后对比:相同的信号,相同的时间段 — 但实盘 PnL 低了40%。回撤深了一倍半。十笔交易中有两笔根本没有执行。
这不是 bug。这是 回测-实盘差异(backtest-live divergence) — 回测结果与真实交易之间的系统性偏差。每个人都有这个问题。唯一的问题是你是否知道它的存在,以及你能否控制它。
本文提供差异的完整分类、最小化差异的架构模式,以及在生产环境中监控一致性的实用清单。
每个算法交易者都会经历这个循环:
问题不在于市场。问题在于回测和机器人是两个不同的软件产品,它们以不同的方式建模同一个现实。差异是不可避免的,但可以被系统化和最小化。

所有差异来源分为四类。每一类都有严重程度评级(1到5)和对 PnL 差异的典型贡献。
回测看到的数据和机器人实时看到的数据不是同一回事。
时间戳。 交易所以不同的规则为K线分配时间戳。一个交易所用周期开始时间标记K线,另一个用结束时间。REST API 可能在实际收盘后延迟1-3秒才返回K线。回测使用历史文件中的"理想"时间戳。
OHLCV 聚合。 历史数据通常由数据提供商以不同于交易所实时聚合的方式进行聚合。差异在最后一位 — 但对于阈值信号(MA 交叉、突破水平),这决定了策略是否建仓。
缺口和缺失数据。 历史数据通常是干净的 — 缺失的K线通过插值填充。在实时环境中,WebSocket 可能断开,机器人错过30秒的数据。
对 PnL 差异的典型贡献:年度 PnL 的 2-5%。
最危险的差异类别。回测完美模拟执行 — 现实远非理想。
滑点。 回测以收盘价(或信号价)成交订单。在现实中,市价单以最佳买卖价加上滑点执行,滑点取决于交易量和流动性。对于中等流动性山寨币上的$10K仓位,滑点可能为0.05-0.3%。
笔交易的累积滑点公式:
其中 是第 笔交易的滑点,取决于订单簿深度:
延迟。 从信号生成到订单执行之间有时间:信号计算(1-50 ms)、请求发送(10-200 ms)、交易所撮合(1-10 ms)。在回测中,延迟 = 0。在实盘中 — 价格可能已经变动。
部分成交。 回测假设100%的订单立即成交。在现实中,限价单可能部分成交 — 或者如果价格反转则完全未成交。对于流动性差的市场上的市价单,订单"滑过"订单簿的多个价格层级。
队列优先级。 以最佳买价挂出的限价单不会立即成交 — 它排在该价位所有先前挂出的订单之后。认为"价格触及 = 订单成交"的回测系统性地高估了成交率。
对 PnL 差异的典型贡献:年度 PnL 的 10-30%。
这是回测和机器人之间策略代码本身的差异。
独立的代码库。 经典的反模式:backtests/strategy_a.py 和 bot/strategy_a.py — 两个"做同样事情"的独立文件。经过三个月的修改,它们不可避免地出现分歧。有人在回测中添加了过滤器,忘了在机器人中复制。或者相反 — 在机器人中修复了一个 bug,但回测中仍然存在。
不同的框架。 回测使用 pandas 的向量化操作,机器人使用 asyncio 的事件驱动逻辑。即使策略相同,边界情况的处理也不同:舍入、条件检查顺序、NaN 处理。
状态管理。 回测通常是无状态的 — 遍历数据数组。机器人是有状态的 — 存储仓位、余额、订单历史。机器人重启、状态丢失、与交易所不同步 — 所有这些都是差异的来源。
对 PnL 差异的典型贡献:年度 PnL 的 5-20%。
交易成本建模中的差异。
资金费率。 大多数永续合约回测根本不考虑资金费率。在10倍杠杆和平均每8小时0.01%的费率下,这是 每年 — 超过大多数策略的 PnL。详细分析见文章资金费率扼杀你的杠杆。
佣金。 Maker/taker 佣金通常会被建模,但往往使用错误的费率。VIP 等级、BNB 折扣、返佣 — 所有这些都影响最终结果。
价差。 基于K线的回测看不到买卖价差。在分钟K线上,收盘价 = 3000,但实际上买价 = 2999.5,卖价 = 3000.5。每笔交易"花费"半个价差。
对 PnL 差异的典型贡献:年度 PnL 的 5-15%。
所有四个类别同时作用,并且通常朝一个方向 — 对交易者不利:
对于设计不完善的系统,回测 PnL 的20-50%总差异是正常的。使用杠杆时,效应会被放大。
思路:将策略核心 — 信号生成和执行逻辑 — 提取到一个独立模块中,供回测和机器人共同使用。只有周围的基础设施不同:数据源和订单提交机制。
┌─────────────────────────────────────┐
│ strategy_core.py │
│ ┌─────────────┐ ┌───────────────┐ │
│ │ SignalEngine │ │ OrderManager │ │
│ └──────┬──────┘ └──────┬────────┘ │
│ │ │ │
│ generate_signal() create_order()│
└─────────┬───────────────┬───────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ 回测 │ │ 实盘 │
│ DataFeed │ │ DataFeed │
│ FillModel │ │ Exchange │
└────────────┘ └────────────┘
from dataclasses import dataclass
from typing import Optional
import numpy as np
@dataclass
class Signal:
side: str # 'long' | 'short'
entry_price: float
sl_price: float
tp_price: float
size: float
timestamp: int
@dataclass
class OrderRequest:
side: str
order_type: str # 'market' | 'limit'
price: float
size: float
class StrategyCore:
"""
策略核心。回测和实盘使用相同的代码。
只依赖数据,不依赖基础设施。
"""
def __init__(self, params: dict):
self.fast_period = params.get('fast_ma', 20)
self.slow_period = params.get('slow_ma', 50)
self.sl_pct = params.get('sl_pct', 0.02)
self.tp_pct = params.get('tp_pct', 0.04)
self.position: Optional[Signal] = None
self._closes: list[float] = []
def on_candle(self, timestamp: int, o: float, h: float,
l: float, c: float, v: float) -> Optional[OrderRequest]:
"""
处理新K线。返回 OrderRequest 或 None。
此方法在回测和机器人中以相同方式调用。
"""
self._closes.append(c)
if len(self._closes) < self.slow_period:
return None
fast_ma = np.mean(self._closes[-self.fast_period:])
slow_ma = np.mean(self._closes[-self.slow_period:])
if self.position is not None:
exit_order = self._check_exit(h, l, c)
if exit_order:
self.position = None
return exit_order
if self.position is None:
if fast_ma > slow_ma and self._prev_fast_ma <= self._prev_slow_ma:
self.position = Signal(
side='long', entry_price=c,
sl_price=c * (1 - self.sl_pct),
tp_price=c * (1 + self.tp_pct),
size=1.0, timestamp=timestamp,
)
return OrderRequest('buy', 'market', c, 1.0)
self._prev_fast_ma = fast_ma
self._prev_slow_ma = slow_ma
return None
def _check_exit(self, high: float, low: float,
close: float) -> Optional[OrderRequest]:
pos = self.position
if pos.side == 'long':
if low <= pos.sl_price:
return OrderRequest('sell', 'market', pos.sl_price, pos.size)
if high >= pos.tp_price:
return OrderRequest('sell', 'market', pos.tp_price, pos.size)
return None
现在回测和机器人使用同一个 StrategyCore:
from strategy_core import StrategyCore
def run_backtest(candles, params, fill_model):
core = StrategyCore(params)
trades = []
for candle in candles:
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
fill_price = fill_model.simulate_fill(order, candle)
trades.append({'price': fill_price, 'side': order.side})
return trades
from strategy_core import StrategyCore
async def run_live(exchange, symbol, params):
core = StrategyCore(params)
async for candle in exchange.stream_candles(symbol, '1m'):
order = core.on_candle(
candle['timestamp'], candle['open'], candle['high'],
candle['low'], candle['close'], candle['volume'],
)
if order:
await exchange.place_order(symbol, order.side,
order.order_type, order.size)
关键规则:StrategyCore 不知道数据来自哪里,也不知道订单发送到哪里。它接收 OHLCV 并返回 OrderRequest。其他一切都是基础设施层的职责。
NautilusTrader 通过统一的 NautilusKernel 实现一致性 — 一个 Rust 原生引擎,具有确定性的事件驱动核心和纳秒级分辨率。同一策略实现在回测和实盘交易中都能工作。
架构基于端口和适配器模式(六角架构):
┌──────────────────────────────────┐
│ NautilusKernel │
│ ┌───────────┐ ┌─────────────┐ │
│ │ Strategy │ │ RiskEngine │ │
│ │ (Python) │ │ (Rust) │ │
│ └─────┬─────┘ └──────┬──────┘ │
│ │ │ │
│ ┌─────┴───────────────┴──────┐ │
│ │ Message Bus (Rust) │ │
│ └─────┬───────────────┬──────┘ │
└────────┼───────────────┼─────────┘
│ │
┌─────┴─────┐ ┌─────┴──────┐
│ 回测 │ │ 实盘 │
│ Adapter │ │ Adapter │
│ FillModel │ │ Exchange │
│ (L2 book) │ │ Gateway │
└────────────┘ └────────────┘
优势:
Freqtrade 使用统一的 IStrategy 接口:同一个策略类在回测和实盘中都能工作。唯一的区别是持久化层。
class IStrategy:
"""统一接口 — 实现不知道这是回测还是实盘。"""
def populate_indicators(self, dataframe, metadata):
"""计算指标。"""
dataframe['fast_ma'] = dataframe['close'].rolling(20).mean()
dataframe['slow_ma'] = dataframe['close'].rolling(50).mean()
return dataframe
def populate_entry_trend(self, dataframe, metadata):
"""确定入场信号。"""
dataframe.loc[
(dataframe['fast_ma'] > dataframe['slow_ma']) &
(dataframe['fast_ma'].shift(1) <= dataframe['slow_ma'].shift(1)),
'enter_long'
] = 1
return dataframe
def populate_exit_trend(self, dataframe, metadata):
"""确定出场信号。"""
dataframe.loc[
(dataframe['fast_ma'] < dataframe['slow_ma']),
'exit_long'
] = 1
return dataframe
Freqtrade 还提供:
--timeframe-detail — 深入更细的时间框架以优化成交(类似于自适应逐层细化)| 共享核心 | 事件驱动(NautilusTrader) | 策略接口(Freqtrade) | |
|---|---|---|---|
| 实施复杂度 | 低 | 高 | 中 |
| 一致性水平 | 中 | 最高 | 高 |
| 成交模拟 | 独立的 FillModel | L2 订单簿 | --timeframe-detail |
| 核心语言 | Python | Rust + Python | Python |
| 适用于 | 自建引擎 | 机构交易 | 快速起步 |
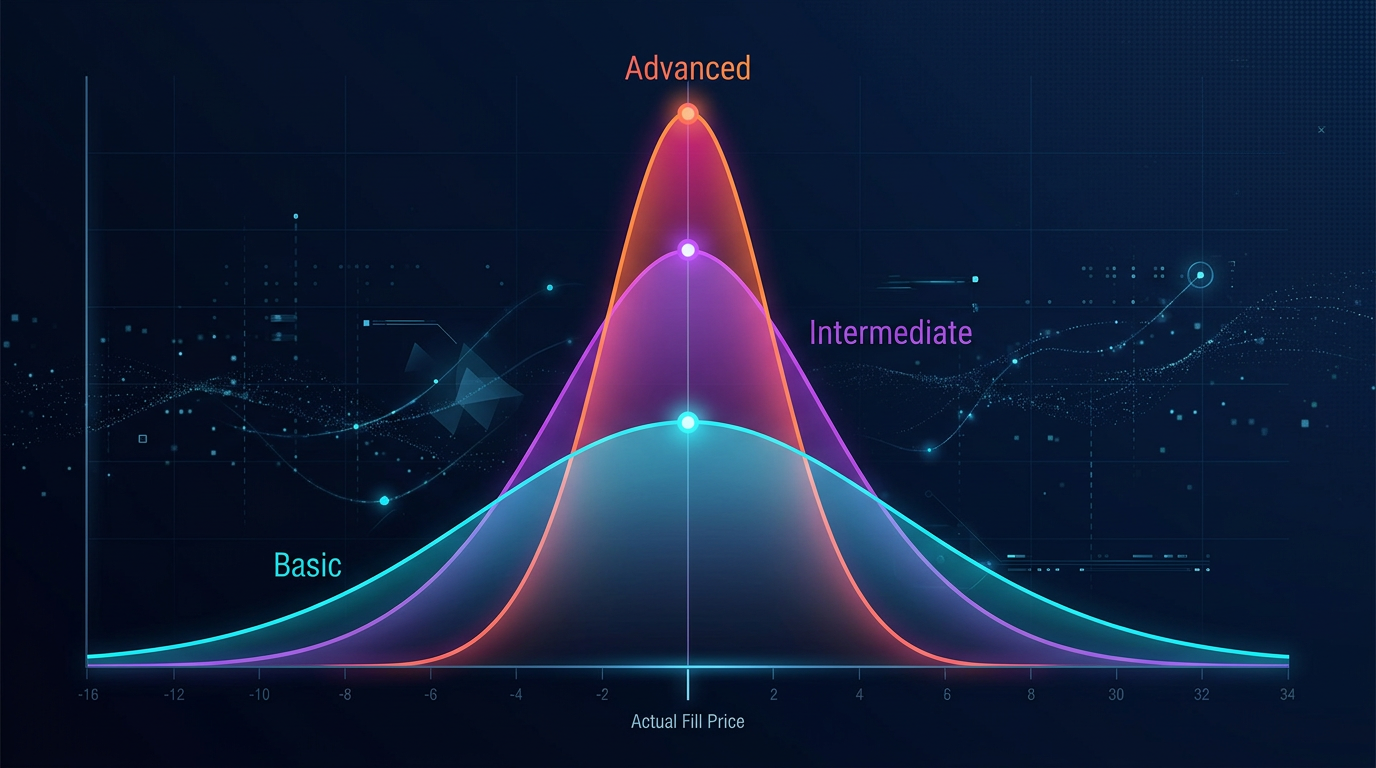
成交模拟是执行差异的主要来源。三个精度级别:
fill_price = candle['close']
误差: 不考虑滑点、价差、部分成交。系统性地高估 PnL。
def simulate_fill(order, candle, slippage_bps=5):
"""带滑点的成交。"""
base_price = candle['close']
slip = base_price * slippage_bps / 10000
if order.side == 'buy':
return base_price + slip # 以更高价格买入
else:
return base_price - slip # 以更低价格卖出
误差: 固定滑点不考虑流动性和订单大小。比简单模式好,但仍然是粗糙的模型。
最佳方案:使用真实的细粒度数据精确确定止损/止盈的成交顺序。详细描述见文章自适应逐层细化:可变粒度回测。
class RealisticFillModel:
"""
组合成交模型:滑点 + 价差 + 交易量冲击。
"""
def __init__(self, avg_spread_bps=3, impact_coeff=0.1):
self.avg_spread_bps = avg_spread_bps
self.impact_coeff = impact_coeff
def simulate_fill(self, order, candle, order_size_usd):
base_price = candle['close']
spread_cost = base_price * self.avg_spread_bps / 20000
candle_volume_usd = candle['volume'] * candle['close']
participation_rate = order_size_usd / max(candle_volume_usd, 1)
impact = base_price * self.impact_coeff * np.sqrt(participation_rate)
if order.side == 'buy':
return base_price + spread_cost + impact
else:
return base_price - spread_cost - impact
市场冲击公式(简化的 Almgren-Chriss 模型):
其中 是波动率, 是冲击系数, 是订单量, 是该时间段的市场成交量。
在实盘启动机器人之前,检查每一项:
代码:
数据:
执行:
成本:
基础设施:
一致性不是一次性检查,而是一个持续的过程。启动机器人后,必须实时跟踪差异。
在相同数据上并行运行机器人和回测。机器人生成信号但不发送订单 — 只记录日志。同时回测处理相同的数据。比较:
class DivergenceMonitor:
"""
实时比较回测和实盘机器人的信号。
"""
def __init__(self, tolerance_pct=0.5):
self.tolerance = tolerance_pct / 100
self.divergences = []
def compare_signal(self, backtest_signal, live_signal, timestamp):
"""比较回测和实盘信号。"""
if backtest_signal is None and live_signal is None:
return # 两者都沉默 — OK
if (backtest_signal is None) != (live_signal is None):
self.divergences.append({
'timestamp': timestamp,
'type': 'signal_mismatch',
'backtest': backtest_signal,
'live': live_signal,
'severity': 'HIGH',
})
return
price_diff = abs(
backtest_signal.entry_price - live_signal.entry_price
) / backtest_signal.entry_price
if price_diff > self.tolerance:
self.divergences.append({
'timestamp': timestamp,
'type': 'price_divergence',
'diff_pct': price_diff * 100,
'severity': 'MEDIUM',
})
def compare_fill(self, backtest_fill, live_fill, timestamp):
"""比较执行情况。"""
if backtest_fill and live_fill:
slippage = (live_fill['price'] - backtest_fill['price']
) / backtest_fill['price']
self.divergences.append({
'timestamp': timestamp,
'type': 'fill_divergence',
'slippage_bps': slippage * 10000,
'severity': 'LOW' if abs(slippage) < 0.001 else 'MEDIUM',
})
def report(self):
"""每周差异报告。"""
from collections import Counter
severity_counts = Counter(d['severity'] for d in self.divergences)
return {
'total_divergences': len(self.divergences),
'by_severity': dict(severity_counts),
'avg_slippage_bps': np.mean([
d['slippage_bps'] for d in self.divergences
if d['type'] == 'fill_divergence'
]) if any(d['type'] == 'fill_divergence'
for d in self.divergences) else 0,
}
| 指标 | 公式 | 告警阈值 |
|---|---|---|
| 信号匹配率 | < 95% | |
| 平均滑点 | (bps) | > 10 bps |
| 成交率 | < 90% | |
| PnL 差异 | > 20% | |
| 延迟 p99 | 信号到成交的第99百分位 | > 500 ms |
积累2-4周的数据后,可以根据真实数据校准回测滑点模型:
def calibrate_slippage(live_fills: list[dict]) -> dict:
"""
使用真实成交数据校准滑点模型。
live_fills: [{'expected_price': ..., 'actual_price': ..., 'size_usd': ..., 'volume_usd': ...}]
"""
slippages = []
participation_rates = []
for fill in live_fills:
slip = abs(fill['actual_price'] - fill['expected_price']
) / fill['expected_price']
part = fill['size_usd'] / max(fill['volume_usd'], 1)
slippages.append(slip)
participation_rates.append(part)
slippages = np.array(slippages)
participation_rates = np.array(participation_rates)
from scipy.optimize import curve_fit
def model(x, k, base):
return k * np.sqrt(x) + base
popt, _ = curve_fit(model, participation_rates, slippages,
p0=[0.1, 0.0001])
return {
'impact_coeff': popt[0],
'base_slippage': popt[1],
'mean_slippage_bps': np.mean(slippages) * 10000,
'p95_slippage_bps': np.percentile(slippages, 95) * 10000,
}
回测-实盘一致性不是一个孤立的任务。它与"回测无幻觉"系列中的其他工具交叉:
共享核心是必须的。 信号生成使用单一代码库是一致性的最低要求。两个包含相同逻辑的文件保证在一个月内出现差异。
校准成交模型。 固定5 bps的滑点比没有好。根据真实数据校准的滑点模型则好得多。
前2-4周使用影子模式。 在信号匹配率达到95%+之前不要用真钱交易。
建模资金费率。 对于永续合约,这不是可选的 — 是必须的。资金费率在杠杆 > 5倍时可以吃掉所有 PnL。
记录一切。 每个信号、每个订单、每笔成交 — 带时间戳。没有日志,事后分析就不可能。
自动化比较。 DivergenceMonitor 的每周报告应自动到达。不要等到 PnL 变为负数。
默认悲观回测。 在回测中低估预期并在实盘中得到惊喜,比反过来好。滑点模型应该是保守的。
回测-实盘一致性不是系统的属性,而是一个过程。完美的一致性不存在:回测从定义上就是现实的模型,而模型总是简化的。但"模型差异5%"和"模型差异50%"之间的区别取决于架构。
三个成熟度级别:
你的任务是确定你处于哪个级别,并理解对于你的仓位规模和杠杆,什么程度的差异是可接受的。
@article{soloviov2026backtestliveparity, author = {Soloviov, Eugen}, title = {Backtest-live parity: why your bot trades differently from the backtest}, year = {2026}, url = {https://marketmaker.cc/ru/blog/post/backtest-live-parity}, description = {回测与实盘交易之间差异的完整分类:从滑点和部分成交到代码库不同步。实现一致性的架构模式和生产环境监控清单。} }