Дисклеймер: Информация в этой статье предоставлена исключительно в образовательных и ознакомительных целях и не является финансовым, инвестиционным или торговым советом. Торговля криптовалютами сопряжена с высоким риском убытков.
Подпишитесь на нашу рассылку, чтобы получать эксклюзивную аналитику по AI-трейдингу и обновления платформы.
Серия «Бэктесты без иллюзий», статья 9
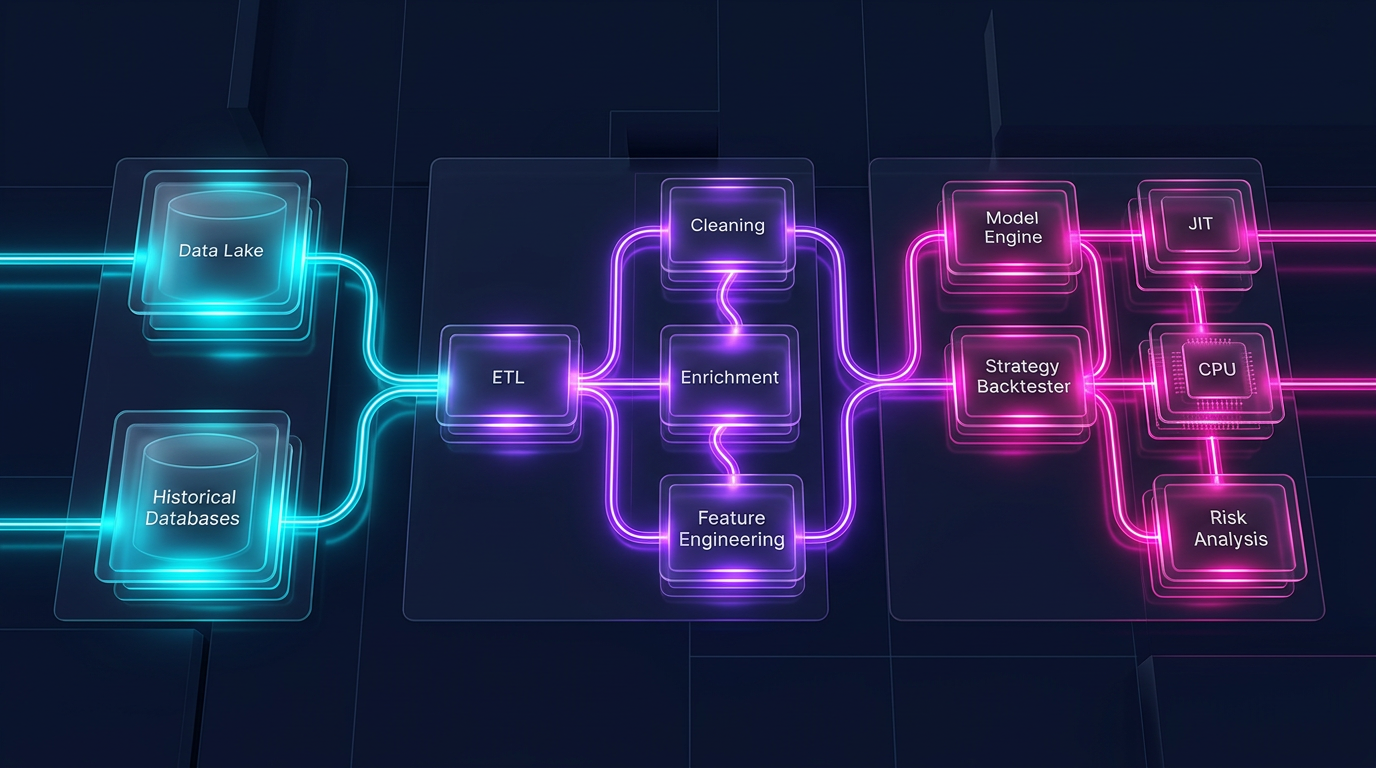
Бэктест стратегии — это не только логика сигналов и симуляция исполнения. Это ещё и data pipeline: загрузка миллионов свечей, пересчёт таймфреймов, вычисление индикаторов, фильтрация по условиям, группировка по инструментам. Когда pipeline работает 30 секунд вместо 3 — это не просто неудобство. Это в 10 раз меньше экспериментов за час, в 10 раз медленнее итерации, в 10 раз дольше путь от идеи до продакшена.
Pandas — де-факто стандарт для работы с табличными данными в Python. Но Pandas проектировался в 2008 году, когда ядра процессоров были медленнее, а датасеты — меньше. Pandas однопоточный, жадный до памяти и лишён оптимизатора запросов. Polars — библиотека нового поколения, написанная на Rust, с параллельным выполнением, Apache Arrow в основе и ленивым планировщиком запросов.
Вопрос: насколько Polars быстрее на реальных задачах алготрейдинга? Не на синтетических бенчмарках из README, а на фильтрации тиков, rolling-расчёте индикаторов, группировке по инструментам и загрузке из Parquet/QuestDB?
В этой статье — систематические бенчмарки с числами, кодом и практическими рекомендациями.
Методология бенчмарков
Прежде чем сравнивать — определим правила, чтобы результаты были воспроизводимыми и честными.
На 10K строк Pandas иногда быстрее на простых фильтрах — overhead вызова Polars-функции через PyO3 сопоставим со временем самой операции. Но на join уже видно преимущество: хэш-таблица Polars на Rust работает в 13 раз быстрее.
Medium datasets (1M строк)
Операция
Pandas (ms)
Polars (ms)
Speedup
Filter
12.4
7.8
1.6x
GroupBy
45.2
28.6
1.6x
Join
89.0
14.3
6.2x
Select
21.8
2.0
10.9x
На миллионе строк Polars стабильно быстрее в 1.6x на фильтрации и группировке. На select (выбор подмножества столбцов) — в 10.9x, потому что Arrow columnar format позволяет zero-copy slice.
Large datasets (10M+ строк)
Операция
Pandas (ms)
Polars (ms)
Speedup
Filter
185
50
3.7x
GroupBy
860
100
8.6x
Join
1450
120
12.1x
Select
240
40
6.0x
На больших данных преимущество Polars растёт нелинейно: параллельное выполнение на 8 ядрах и оптимизатор запросов дают кумулятивный эффект. GroupBy ускоряется в 8.6x — это разница между «ждать секунду» и «ждать 100 миллисекунд».
ETL на реальных данных (NYC Taxi, 12.7M строк)
Операция
Pandas (s)
Polars (s)
Speedup
Загрузка CSV
28.5
1.14
25.0x
Filter + GroupBy + Agg
3.8
0.42
9.0x
Multi-column transform
2.1
0.7
3.0x
Full ETL pipeline
34.4
2.26
15.2x
CSV I/O — самый драматичный результат: Polars читает CSV параллельно на Rust-движке, 25x быстрее. Это критично для первичной загрузки исторических данных.
Официальный PDS-H benchmark (май 2025)
PDS-H (Performance Data Science — Holistic) — стандартный benchmark для DataFrame-библиотек, аналог TPC-H для баз данных. Результаты мая 2025:
Pandas участвует только на масштабе SF-10 — однопоточный, без оптимизатора запросов, на два порядка медленнее лидеров
Polars и DuckDB — в своей лиге на SF-10 и SF-100
Новый streaming engine Polars даёт дополнительное ускорение 3-7x по сравнению с in-memory режимом — можно обрабатывать данные, которые не помещаются в RAM
Для алготрейдинга это означает: если ваш pipeline упирается в память при загрузке 100M+ строк тиковых данных — Polars streaming engine позволяет обработать их без увеличения RAM.
Rolling-расчёты для торговых сигналов: killer feature
Это самый важный бенчмарк для алготрейдинга. Типичная задача: у вас 100 инструментов, для каждого нужно рассчитать rolling mean, rolling std, z-score, и на их основе сгенерировать сигнал. В Pandas это — groupby().rolling(), в Polars — group_by().agg(col().rolling_mean()).
От 10x до 3500x ускорение на rolling-расчётах по группам. Это не опечатка. Pandas groupby().transform(lambda x: x.rolling().mean()) создаёт Python-цикл по каждой группе, каждый вызов — overhead интерпретатора. Polars выполняет всё на Rust, параллельно по группам, без промежуточных Python-объектов.
Для pipeline, где нужно рассчитать 10 индикаторов по 100 инструментам — это разница между 2 минутами и 0.3 секунды.
TTM Squeeze — это метод определения перехода рынка из состояния сжатия (низкая волатильность) в состояние расширения. Сигнал возникает, когда Bollinger Bands находятся внутри Keltner Channels:
squeeze=BBlower>KClower∧BBupper<KCupper
Бенчмарк технических индикаторов (1M строк, один тикер)
Индикатор
Pandas (ms)
Polars (ms)
Speedup
Bollinger Bands (20, 2)
8.4
1.2
7.0x
Keltner Channels (20, 1.5)
14.2
2.1
6.8x
TTM Squeeze (full)
28.6
4.1
7.0x
RSI (14)
6.8
1.1
6.2x
MACD (12, 26, 9)
5.2
0.8
6.5x
Стабильное ускорение ~7x на одном тикере. При расчёте по группам (100 тикеров) — ускорение возрастает до сотен раз из-за overhead Pandas groupby.
Нюанс: готовые пакеты индикаторов
Для Pandas существует pandas-ta — библиотека с 130+ индикаторами. Для Polars аналогичного пакета пока нет. Это означает, что при использовании Polars индикаторы придётся реализовывать самостоятельно. Однако базовые блоки (rolling_mean, rolling_std, ewm_mean, shift, арифметика столбцов) покрывают подавляющее большинство стандартных индикаторов, и реализация на Polars обычно короче, чем кажется.
I/O бенчмарки: CSV, Parquet, база данных
Data pipeline начинается с загрузки данных. Формат хранения и способ чтения определяют baseline скорости всего pipeline.
CSV: Polars до 25x быстрее — параллельный парсинг на Rust
Parquet read: Polars быстрее в 2.6x на полном чтении и в 4.5x при projection pushdown (чтение только нужных столбцов)
Parquet write: почти одинаково — оба используют PyArrow/Arrow backend
Lazy scan: Polars может применить фильтр на уровне row groups Parquet-файла, не загружая данные в память. Для Pandas это невозможно без ручного использования PyArrow
Для Parquet-кэша — нашего основного формата хранения предвычисленных таймфреймов и индикаторов — Polars с lazy evaluation даёт идеальную интеграцию: загрузка только нужных столбцов и периодов без полного чтения файла в память.
Потребление памяти и lazy evaluation
Eager vs Lazy
Pandas работает только в eager-режиме: каждая операция выполняется немедленно, промежуточные результаты материализуются в памяти.
df = pd.read_csv("big_file.csv") # весь файл в RAM
df = df[df["volume"] > 1000] # копия с фильтром
df = df[["timestamp", "close", "volume"]] # ещё одна копия
df["returns"] = df["close"].pct_change() # ещё одна копия
Polars поддерживает lazy evaluation — запросы строятся как граф, оптимизируются и выполняются за один проход:
Projection pushdown: читает только 3 столбца вместо всех
Predicate pushdown: применяет фильтр volume > 1000 при чтении, не загружая ненужные строки
Common subexpression elimination: не вычисляет одно и то же дважды
Потребление памяти (10M строк, 6 столбцов float64)
Сценарий
Pandas (GB)
Polars eager (GB)
Polars lazy (GB)
Загрузка CSV
0.92
0.46
0.46
Filter + Select 3 columns
1.38*
0.22
0.22
Pipeline из 5 трансформаций
2.76*
0.48
0.48
Загрузка Parquet (3 of 6 cols)
0.46
0.23
0.23
* Pandas создаёт промежуточные копии; inplace=True помогает частично, но не для всех операций.
Polars нативно использует Arrow columnar format: данные хранятся по столбцам, строки не дублируются, zero-copy операции там, где возможно. Для pipeline с несколькими трансформациями Polars потребляет в 2-6 раз меньше памяти.
Streaming engine: данные больше RAM
Для датасетов, которые не помещаются в оперативную память, Polars предлагает streaming engine:
Streaming engine обрабатывает данные чанками, не загружая весь датасет в память. По данным PDS-H benchmark, streaming mode в 3-7x быстрее in-memory на больших масштабах — за счёт лучшей cache locality и отсутствия давления на виртуальную память.
Гибридная архитектура: Polars + Numba
Бэктест состоит из двух принципиально разных частей:
Data pipeline — загрузка, трансформация, индикаторы, фильтрация. Это massively parallel, column-oriented, идеально ложится на Polars.
Portfolio simulation — заполнение ордеров, расчёт PnL, управление позициями. Это path-dependent: каждый шаг зависит от предыдущего состояния. Здесь нужен поэлементный проход по временному ряду.
Pandas плохо подходит для обеих частей. Polars отлично подходит для первой, но не для второй. Для path-dependent логики оптимальный инструмент — Numba (JIT-компилятор для Python) или нативный Rust/C++.
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # zero-copy из Arrow
signals = df["signal"].to_numpy() # zero-copy из Arrow@njitdefsimulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
Path-dependent симуляция: Numba компилирует в machine code.
1M итераций за 70-100ms.
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0for i inrange(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
Почему не vectorbt?
vectorbt — популярный фреймворк для бэктестов, обрабатывающий 1M ордеров за 70-100ms. Он построен на Pandas + NumPy + Numba. Проблема: Pandas является узким местом в data pipeline — медленный, однопоточный, жадный до памяти. vectorbt вынужден обходить ограничения Pandas через Numba для критичных частей, но загрузка данных и расчёт индикаторов всё равно идут через Pandas.
Гибридная архитектура Polars + Numba берёт лучшее из обоих миров:
Polars для data pipeline — в 5-350x быстрее Pandas на тех же операциях
Numba для portfolio simulation — та же скорость, что и в vectorbt
Нет промежуточного Pandas-слоя — данные идут из Arrow напрямую в NumPy через zero-copy
Миграция: ключевые паттерны из Pandas в Polars
Если ваш pipeline написан на Pandas, миграция не требует переписывания с нуля. Основные паттерны переносятся по шаблонам.
Чтение данных
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # ничего не читает до .collect()
Polars нативно работает с Apache Arrow — тем же форматом, который использует QuestDB для передачи данных. Это означает zero-copy при получении результатов запроса:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # zero-copy!
df_pd = arrow_table.to_pandas() # копирование + конвертация типов
Подробнее о работе с QuestDB для хранения и анализа торговых данных — в нашей серии статей по архитектуре данных.
Интеграция с Parquet-кэшем
В статье Агрегированный Parquet-кэш мы описали, как предвычислить таймфреймы и индикаторы один раз и сохранить в Parquet-файл. Polars делает этот подход ещё эффективнее:
При массовой оптимизации — когда нужно прогнать тысячи комбинаций параметров — чтение из Parquet-кэша через Polars scan_parquet с predicate pushdown позволяет загружать только нужные периоды и столбцы, не читая весь файл.
Связка с Adaptive drill-down: Polars lazy evaluation идеально подходит для двухуровневой загрузки — грубые данные для основного прохода, детальные данные (секунды, миллисекунды) только для fill-ambiguity зон.
Когда что использовать: практические рекомендации
Pandas оправдан, если:
Датасет до 1M строк и вы не делаете GroupBy по сотням групп — разница между Pandas 2.2 и Polars часто незначительна (1.5-2x)
Вам нужен pandas-ta или другие библиотеки с Pandas API — переписывание 130 индикаторов нецелесообразно для одноразового исследования
Прототипирование — Pandas API знакомее большинству, и для быстрой проверки гипотезы скорость не критична
Интеграция с legacy-кодом — существующий pipeline на Pandas работает и не требует оптимизации
Polars необходим, если:
Датасет от 10M строк — десятки и сотни миллионов строк тиковых данных, мультитаймфрейм-кэши
Rolling по группам — 100+ инструментов, индикаторы по каждому: ускорение 100-3500x
ETL pipeline — загрузка, очистка, трансформация больших объёмов данных
Ограниченная RAM — lazy evaluation и streaming engine позволяют обрабатывать данные, не помещающиеся в память
Маркетинговая цифра «30x быстрее» — это пиковое ускорение на специфических операциях. Реалистичное ускорение на типичных pipeline-операциях: 2-10x. На rolling по группам — значительно больше. На мелких датасетах — иногда Polars даже медленнее из-за overhead.
Наш опыт в marketmaker.cc
В marketmaker.cc мы используем гибридную архитектуру Polars + Numba для бэктест-движка. Весь data pipeline — загрузка из Parquet-кэша, расчёт индикаторов, фильтрация, feature engineering — работает на Polars. Portfolio simulation — на Numba.
Переход с Pandas на Polars в data pipeline дал ускорение pipeline подготовки данных в 6-8x на наших типичных датасетах (50-100M строк, 200+ инструментов). Расчёт rolling-индикаторов по группам — от минут до сотен миллисекунд. Это позволило увеличить количество итераций оптимизации с ~500 до ~4000 в час без изменения железа.
Ключевой момент: мы не мигрировали весь код за один день. Сначала перевели I/O (чтение Parquet), потом — расчёт индикаторов, потом — фильтрацию и feature engineering. Pandas остался только в интерфейсе с legacy-компонентами, которые ожидают pd.DataFrame. Конвертация df.to_pandas() / pl.from_pandas() занимает миллисекунды и не является узким местом.
Метрики, рассчитанные на этапе бэктеста — включая PnL по активному времени — вычисляются уже на Polars DataFrame, что упрощает pipeline и избавляет от промежуточных конвертаций.
Заключение
Polars — не замена Pandas в каждом сценарии. Это инструмент другого класса, который раскрывается на масштабах, типичных для серьёзного алготрейдинга: миллионы и сотни миллионов строк, десятки и сотни инструментов, непрерывная оптимизация параметров.
Ключевые числа:
Базовые операции: 2-10x ускорение на типичных pipeline-задачах
Rolling по группам: 10-3500x — главный killer feature для торговых pipeline
CSV I/O: до 25x — критично для первичной загрузки данных
Память: 2-6x экономия за счёт Arrow и lazy evaluation
Streaming: обработка данных, не помещающихся в RAM
Рекомендуемая архитектура для production-бэктест-движка:
Polars — весь data pipeline: загрузка, индикаторы, фильтрация, features
Numba/Rust — portfolio simulation: path-dependent логика ордеров и позиций
Arrow — формат данных на всех стыках: Parquet, QuestDB, Polars, NumPy
Никакого промежуточного Pandas-слоя. Данные текут из хранилища через Polars в NumPy-массивы и далее в Numba-движок — без лишних копирований, без GIL, без однопоточных bottleneck.