Backtesting Without Fooling Yourself
A step-by-step path from what your backtest really optimizes to proving an edge survives overfitting, multiple testing, and live execution. Read top to bottom — each part builds on the last.
- 01
 Jul 2, 2026 #算法交易
Jul 2, 2026 #算法交易目标函数设计:你优化的那个指标,正悄悄替你选好了策略
要搜索'最好'的策略,你必须先定义什么是'最好'——而那个标量,会悄悄替你选出赢家。在带有已知优势的合成数据上(600 个种子,T=2000,80 个候选阈值),朴素的逐笔(per-trade)夏普比率会加冕一张彩票:它在 56% 的种子上选出曝光率低于 5% 的赢家,在 57% 的种子上发生退化——在最极端的那个种子上,8 笔交易的样本内夏普比率高达 21.09,样本外却崩塌到 0.13。诚实的修复几乎平淡无奇:在整条时间线上测量,它从不退化(样本外 1.71)。交易笔数(conf_k)收缩与曝光率下限可以给逐笔指标打补丁,但即便完全修复,它们也只能追平整条时间线夏普比率(1.70 对 1.71)——永远无法超过它。古德哈特定律,在回测里,配上受控的真实基准。
- 02
 Mar 15, 2026 #算法交易
Mar 15, 2026 #算法交易Walk-Forward 优化:唯一诚实的策略测试方法
为什么单次训练/测试分割无法防止过拟合,walk-forward 优化如何系统性地验证参数稳健性,以及为什么一个具有 21 个参数、PnL@ML 达 +3342% 的策略在没有 WFO 的情况下是一颗定时炸弹。
- 03
 Mar 12, 2026 #算法交易
Mar 12, 2026 #算法交易平台分析:如何区分稳健最优与过拟合
为什么找到最佳策略参数只是工作的一半。如何从视觉和定量两方面区分稳定的平台与脆弱的尖峰,以及为什么Optuna等高线图是将优化后的策略投入生产前的必要步骤。
- 04
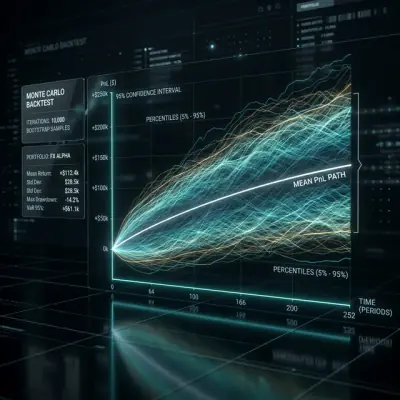 Mar 6, 2026 #算法交易
Mar 6, 2026 #算法交易蒙特卡洛自助法:如何用10行代码获取回测的置信区间
为什么回测的单点估计是一种危险的幻觉。蒙特卡洛自助法如何在2秒内计算出PnL和MaxDD的95%置信区间,以及为什么这是策略上线前的必要步骤。
- 05
 Jul 2, 2026 #算法交易
Jul 2, 2026 #算法交易回测过拟合概率(PBO):你的搜索跑赢抛硬币了吗?
Deflated Sharpe Ratio 给获胜策略定价;PBO 给挑出它的那次搜索定价。组合对称交叉验证(Combinatorially Symmetric Cross-Validation)在一个 1000x200 的表现矩阵上跑 C(16,8) = 12,870 次训练/测试切分,问的是:样本内赢家会不会落入样本外的后一半?几乎每个人都会看错的地方——PBO 的零假设值是 0.5,不是 1。在 200 个零优势策略上,最佳样本内年化夏普比率 1.98 在样本外坍缩到 0.06,PBO = 0.476:如同抛硬币,彻底过拟合。植入一个真实优势(年化夏普比率 2.38),PBO 降到 0.001,样本内的 3.73 在样本外仍保住 2.34。在纯随机游走上跑移动平均线网格,同样没有任何样本外的技巧——60 个矩阵平均 PBO 0.463,在统计上和零假设无法区分——而在其中一个具有代表性的矩阵上,这场海市蜃楼十分鲜明:最佳样本内夏普比率 2.33 坍缩到样本外中位数 -0.22,PBO 0.573,63% 的概率会亏钱。
- 06
 Jul 2, 2026 #算法交易
Jul 2, 2026 #算法交易Deflated Sharpe Ratio:你回测里的'赢家',有多少能扛过多重检验?
参数搜索是一台制造运气的机器。在纯噪声上——1,000 个真实优势为零的策略——最佳年化夏普比率平均达到 1.63,朴素显著性检验 100% 的时候都会宣布发现。我们构建受控的真实基准,证明 Deflated Sharpe Ratio、Harvey-Liu 折价法与 White's Reality Check 能够恢复诚实:假发现率从 1.000 降到 0.001-0.057,噪声上限之上的真实优势仍以接近 1 的功效被保留——还有一个真实的陷阱(相关网格),在那里原始 DSR 会过度折损,其结论必须放在一整条有效试验数估计的区间上通读,而不是只看一个数字。
- 07
 Mar 7, 2026 #算法交易
Mar 7, 2026 #算法交易回测与实盘一致性:为什么你的机器人交易表现与回测不同
回测与实盘交易之间差异的完整分类:从滑点和部分成交到代码库不同步。实现一致性的架构模式、共享核心模块的 Python 示例以及生产环境监控清单。