Backtesting Without Fooling Yourself
A step-by-step path from what your backtest really optimizes to proving an edge survives overfitting, multiple testing, and live execution. Read top to bottom — each part builds on the last.
- 01
 Jul 2, 2026 #algotrading
Jul 2, 2026 #algotradingObjective-Function Design: The Metric You Optimize Secretly Picks Your Strategy
To search for the 'best' strategy you must first define 'best' — and that scalar silently chooses the winner. On synthetic data with a known edge (600 seeds, T=2000, 80 thresholds), a naive per-trade Sharpe crowns a lottery: it picks a sub-5%-exposure winner in 56% of seeds and degenerates in 57% — on the starkest seed, 8 trades posting an in-sample Sharpe of 21.09 that collapses to 0.13 out of sample. The honest repair is almost dull: measure on the full timeline, which never degenerates (out-of-sample 1.71). A trade-count (conf_k) shrinkage and an exposure floor can retrofit a per-trade metric, but even fully repaired they only match full-timeline Sharpe (1.70 vs 1.71) — never beat it. Goodhart's law, in a backtest, with controlled ground truth.
- 02
 Mar 15, 2026 #algotrading
Mar 15, 2026 #algotradingWalk-Forward Optimization: The Only Honest Strategy Test
Why a single train/test split does not protect against overfitting, how walk-forward optimization systematically verifies parameter robustness, and why a strategy with +3342% PnL@ML on 21 parameters is a ticking time bomb without WFO.
- 03
 Mar 12, 2026 #algotrading
Mar 12, 2026 #algotradingPlateau Analysis: How to Distinguish a Robust Optimum from Overfitting
Why finding the best strategy parameters is only half the work. How to visually and quantitatively distinguish a stable plateau from a fragile peak, and why Optuna contour plots are a mandatory step before launching an optimized strategy into production.
- 04
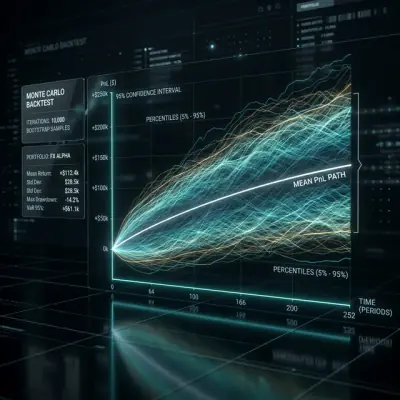 Mar 6, 2026 #algotrading
Mar 6, 2026 #algotradingMonte Carlo Bootstrap: How to Get Confidence Intervals for a Backtest in 10 Lines of Code
Why a single-point estimate from a backtest is a dangerous illusion. How Monte Carlo bootstrap in 2 seconds of computation gives you a 95% confidence interval for PnL and MaxDD, and why this is a mandatory step before launching a strategy in production.
- 05
 Jul 2, 2026 #algotrading
Jul 2, 2026 #algotradingThe Probability of Backtest Overfitting: Did Your Search Beat a Coin Flip?
The Deflated Sharpe Ratio prices the winning strategy; PBO prices the search that picked it. Combinatorially Symmetric Cross-Validation runs C(16,8) = 12,870 train/test splits over a 1000x200 performance matrix and asks: does the in-sample winner land in the bottom half out of sample? The catch almost everyone misses — PBO's null is 0.5, not 1. On 200 zero-edge strategies the best in-sample annualized Sharpe of 1.98 collapses to 0.06 out of sample and PBO = 0.476: a coin flip, fully overfit. Plant a real edge (annualized Sharpe 2.38) and PBO drops to 0.001, the in-sample 3.73 surviving to an out-of-sample 2.34. A moving-average grid on a pure random walk has no out-of-sample skill either — PBO 0.463 averaged over 60 matrices, statistically indistinguishable from the null — and on one representative matrix the mirage is vivid: a best in-sample Sharpe of 2.33 collapses to a median out-of-sample -0.22, PBO 0.573, a 63% chance of a loss.
- 06
 Jul 2, 2026 #algotrading
Jul 2, 2026 #algotradingThe Deflated Sharpe Ratio: How Many of Your Backtest 'Winners' Survive Multiple Testing?
A parameter search is a machine for manufacturing luck. On pure noise — 1,000 strategies with zero true edge — the best annual Sharpe averages 1.63 and the naive significance test flags a discovery 100% of the time. We build controlled ground truth and show that the Deflated Sharpe Ratio, the Harvey-Liu haircut, and White's Reality Check restore honesty: false discoveries drop from 1.000 to 0.001-0.057, genuine edges above the noise ceiling are kept with power ~1 — and one real trap (correlated grids) where the raw DSR over-deflates and the verdict must be read across a whole band of effective-trial estimates, not one.
- 07
 Mar 7, 2026 #algotrading
Mar 7, 2026 #algotradingBacktest-live parity: why your bot trades differently from the backtest
Complete taxonomy of divergences between backtesting and live trading: from slippage and partial fills to codebase desynchronization. Architectural patterns for achieving parity, Python examples of a shared core module, and a production monitoring checklist.