Скрытые марковские модели в трейдинге: как адаптировать стратегию к режиму рынка
У каждого алготрейдера есть момент экзистенциального кризиса. Вы потратили три месяца на стратегию. Бэктест показывает Sharpe 2.4. Equity curve — произведение искусства. Вы запускаете бота. Первые две недели — эйфория, стратегия генерирует альфу. А потом рынок «переключается» — и ваш моментум-бот начинает методично сливать капитал в боковике, покупая каждый локальный хай и продавая каждый лой.
Проблема не в стратегии. Проблема в том, что рынок — это не одна система, а несколько, и они переключаются между собой без предупреждения. Моментум-стратегия, идеальная для тренда, убивает депозит в рейндже. Гридовая стратегия, печатающая деньги в боковике, взрывается на направленном движении. Mean-reversion, стабильная в спокойном рынке, получает маржин-колл на чёрном лебеде.
Вопрос не «какая стратегия лучше», а «какой сейчас режим рынка и какая стратегия ему соответствует». И именно здесь на сцену выходят скрытые марковские модели (Hidden Markov Models, HMM) — математический аппарат, который позволяет формализовать эту интуицию.
Рынки нестационарны, и это не баг, а фича
Начнём с неприятной правды: практически все базовые статистические модели предполагают стационарность данных. Среднее и дисперсия не меняются во времени, автокорреляции постоянны, распределение стабильно. Финансовые ряды нарушают все эти предположения одновременно.
Посмотрите на дневные доходности BTC за последние 5 лет. Средняя дневная доходность в бычьем ралли 2024 года — около +0.3%, стандартное отклонение ~2.5%. В медвежьем рынке 2022 года — средняя -0.15%, стандартное отклонение ~4%. В боковике лета 2023 — средняя ~0%, стандартное отклонение ~1.5%. Это три принципиально разных статистических режима с разными распределениями.
Формально: пусть — доходность в момент . В стационарном мире с постоянными параметрами. В реальности параметры сами являются случайными процессами: , где — скрытое состояние (режим рынка), переключающееся между конечным числом значений.
Эту идею в 1989 году формализовал Джеймс Гамильтон в своей фундаментальной работе «A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle». Он показал, что бизнес-циклы можно моделировать как переключение между двумя скрытыми состояниями — рецессией и экспансией — с помощью марковского механизма. С тех пор модель Гамильтона стала одним из самых цитируемых инструментов в эконометрике.
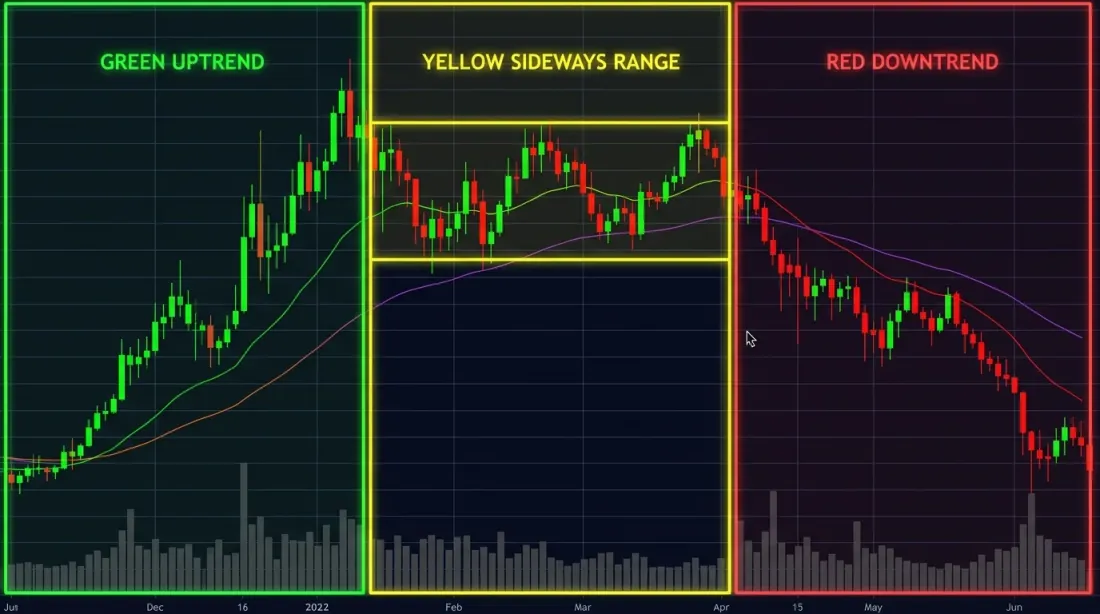 Три режима рынка — бычий (зелёный), медвежий (красный) и боковик (жёлтый) — визуально очевидны постфактум, но определить переключение в реальном времени значительно сложнее.
Три режима рынка — бычий (зелёный), медвежий (красный) и боковик (жёлтый) — визуально очевидны постфактум, но определить переключение в реальном времени значительно сложнее.
HMM: интуиция через аналогию
Прежде чем лезть в формулы, давайте разберёмся на интуитивном уровне.
Марковские цепи: без памяти
Марковская цепь — это случайный процесс, в котором будущее зависит только от настоящего, но не от прошлого. Погода завтра зависит от погоды сегодня, но не от того, какая погода была неделю назад (сильное упрощение, но как модель работает).
Рыночные режимы ведут себя похоже. Если сегодня рынок в бычьем режиме, вероятность остаться в нём завтра — высокая (скажем, 95%). Вероятность перейти в медвежий — низкая (3%). В боковик — ещё ниже (2%). Это и есть матрица переходных вероятностей.
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
Заметьте: диагональные элементы высоки — режимы «липкие». Рынок не скачет из бычьего в медвежий каждый день. Он проводит в одном режиме недели и месяцы, прежде чем переключиться. Ожидаемая длительность режима . Для бычьего режима с это 20 дней. Для медвежьего с — примерно 14 дней.
Скрытые состояния: мы видим только тень
Ключевое слово — «скрытые». Мы не наблюдаем режим рынка напрямую. Никто не вывешивает табличку «Внимание, переходим в медвежий режим». Мы видим только наблюдения (observations) — доходности, волатильность, объёмы. А режим — это латентная переменная, которую нужно вывести из наблюдений.
Это как быть в комнате без окон и пытаться определить погоду по тому, как одеты люди, входящие с улицы. Зонтик? Наверное, дождь. Шорты и солнечные очки? Солнечно. Но один человек в шортах не означает, что точно солнечно — может, он просто оптимист. Нужно накопить наблюдения и вероятностно оценить скрытое состояние.
В HMM каждый скрытый режим «излучает» (emit) наблюдения из своего распределения:
- Бычий режим → доходности из , где , умеренное
- Медвежий режим → доходности из , где , высокое
- Боковик → доходности из , где , низкое
Заметьте характерный паттерн: медвежий режим обычно имеет не просто отрицательное среднее, но и повышенную волатильность. Рынки падают лифтом, а поднимаются по лестнице — и HMM это автоматически улавливает.
 Архитектура Hidden Markov Model: скрытые состояния (режимы) переключаются по марковской цепи, каждое состояние генерирует наблюдаемые доходности из своего гауссова распределения.
Архитектура Hidden Markov Model: скрытые состояния (режимы) переключаются по марковской цепи, каждое состояние генерирует наблюдаемые доходности из своего гауссова распределения.
Три алгоритма HMM: Forward, Viterbi, Baum-Welch
Любая работа с HMM сводится к трём фундаментальным задачам, и для каждой есть свой алгоритм.
Задача 1: какова вероятность этих наблюдений? (Forward Algorithm)
Вопрос: Дана последовательность доходностей. Какова вероятность наблюдать именно такую последовательность при данных параметрах модели?
Зачем: Сравнение моделей (AIC/BIC), проверка адекватности.
Как работает: Прямой алгоритм (Forward Algorithm) — это динамическое программирование. На каждом шаге мы считаем «прямую переменную» — вероятность наблюдать последовательность и оказаться в состоянии в момент .
Рекурсия:
Где — вероятность перехода из состояния в , а — вероятность наблюдения в состоянии . На словах: суммируем по всем путям, как мы могли прийти в состояние , и умножаем на вероятность наблюдения.
Сложность: вместо наивных , где — число состояний, — длина последовательности. Для 3 режимов и 1000 наблюдений это 9000 операций вместо . Разница, скажем так, существенная.
Задача 2: какая последовательность режимов наиболее вероятна? (Viterbi Algorithm)
Вопрос: Дана последовательность доходностей. Какая последовательность скрытых состояний (режимов) её наиболее вероятно сгенерировала?
Зачем: Именно это нам нужно для трейдинга — определить режим в каждый момент времени.
Как работает: Алгоритм Витерби — это тот же Forward, но вместо суммирования по всем путям берётся максимум. Мы ищем не вероятность всех возможных путей, а самый вероятный путь.
Плюс обратный проход (backtracking) для восстановления самой последовательности состояний. Результат — декодированная последовательность режимов: «бычий-бычий-бычий-медвежий-медвежий-боковик-...».
На практике для трейдинга чаще используют не Viterbi (глобальный оптимум), а фильтрацию — апостериорные вероятности состояний в каждый момент: . Это позволяет работать онлайн, не дожидаясь всей последовательности, и получать «мягкие» оценки вроде «70% бычий, 25% боковик, 5% медвежий».
Задача 3: как обучить модель? (Baum-Welch Algorithm)
Вопрос: Даны только наблюдения. Какие параметры модели (, , ) максимизируют правдоподобие данных?
Зачем: Обучение модели на исторических данных.
Как работает: Алгоритм Баума-Уэлча — это частный случай EM-алгоритма (Expectation-Maximization):
- E-шаг: Используя текущие параметры, вычисляем ожидаемые скрытые состояния (через Forward-Backward)
- M-шаг: Обновляем параметры, максимизируя правдоподобие при этих ожидаемых состояниях
- Повторяем до сходимости
Важный нюанс: EM гарантирует сходимость только к локальному максимуму. Разные начальные условия могут дать разные результаты. На практике модель обучают несколько раз с разной инициализацией и выбирают лучший результат по логарифму правдоподобия. В hmmlearn это делается автоматически через параметр n_init.
Режимы крипторынка: что мы ищем
Для криптовалют классическое разбиение на три режима работает особенно хорошо из-за ярко выраженных фаз рынка.
Режим 1: Bull (бычий)
- Средняя доходность: +0.15% ... +0.5% в день
- Волатильность (std): 2-3% в день
- Характер: устойчивый рост с умеренными откатами
- Длительность: 2-6 месяцев непрерывно
- Объёмы: растущие, особенно на спотовых рынках
- On-chain: MVRV > 1.5, растущие активные адреса
Режим 2: Bear (медвежий)
- Средняя доходность: -0.1% ... -0.4% в день
- Волатильность (std): 3-6% в день
- Характер: резкие обвалы, ликвидационные каскады, dead cat bounces
- Длительность: 1-4 месяца (обычно короче бычьего)
- Объёмы: всплески на панических продажах, потом затухание
- On-chain: MVRV < 1, растущий exchange inflow
Режим 3: Sideways (боковик / accumulation)
- Средняя доходность: ~0% в день
- Волатильность (std): 1-2% в день
- Характер: движение в диапазоне, ложные пробои
- Длительность: 1-3 месяца
- Объёмы: низкие, затухающие
- On-chain: стабильные метрики, снижение активности
Почему именно три режима, а не два или пять? Два — слишком грубо, теряется информация о боковике (а для market-making ботов это самый прибыльный режим). Пять или больше — модель становится переобученной, переходные вероятности нестабильны, интерпретация затруднена. Три — оптимальный баланс, подтверждённый как информационными критериями (AIC/BIC), так и экономической интуицией.
Впрочем, выбор числа состояний — это гиперпараметр, и его стоит тестировать. Guidolin & Timmermann (2007) в своей работе «Asset Allocation under Multivariate Regime Switching» нашли четыре режима для смешанного портфеля акций и облигаций: crash, slow growth, bull и recovery.
Feature Engineering: что подавать на вход модели
Самый простой вариант — подать на вход только дневные доходности. Это работает, но можно лучше. Вот набор признаков, который хорошо зарекомендовал себя на практике:
Ценовые признаки
- Дневная логарифмическая доходность:
- Скользящая волатильность: за окно (например, 20 дней)
- Скользящее среднее доходности:
Объёмные признаки
- Нормализованный объём:
- Volume-price correlation: корреляция между объёмом и абсолютной доходностью за скользящее окно
On-chain признаки (для криптовалют)
- MVRV Ratio: отношение рыночной капитализации к реализованной. MVRV > 2 — рынок перегрет, < 1 — недооценён
- NVT Ratio: сетевая стоимость к объёму транзакций. Аналог P/E для блокчейна
- Exchange Net Flow: нетто-поток на биржи. Положительный — давление продаж, отрицательный — накопление
- Active Addresses: число активных адресов (рост = интерес, падение = апатия)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Подготовка признаков для HMM.
df должен содержать колонки: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
Важно: все признаки должны быть стационарны (или хотя бы приблизительно). Логарифмические доходности — стационарны. Цена — нет. Объём лучше нормализовать. Волатильность можно оставить как есть — она тоже квазистационарна.
Ещё один нюанс: мультивариантная HMM (когда на вход подаётся вектор признаков) работает лучше одномерной, но требует больше данных для обучения. Для крипты с историей в 5+ лет это обычно не проблема. Для свежего альткоина с историей в 3 месяца — лучше ограничиться одной-двумя фичами.
Пошаговая реализация на Python с hmmlearn
Переходим к коду. Библиотека hmmlearn — стандарт де-факто для HMM в Python. Простой API, совместимость со scikit-learn, работает из коробки.
Шаг 1: Загрузка данных
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Загрузка данных через CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Загружено {len(df)} дневных свечей")
print(f"Период: {df.index[0]} — {df.index[-1]}")
Шаг 2: Подготовка признаков и обучение HMM
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 режима
covariance_type='full', # полная ковариационная матрица
n_iter=200, # макс. итераций EM
random_state=42,
tol=1e-4, # порог сходимости
verbose=False
)
model.fit(X_scaled)
print(f"Модель сошлась: {model.monitor_.converged}")
print(f"Итераций: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
Шаг 3: Декодирование режимов
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nРаспределение по режимам:")
print(features['regime'].value_counts().sort_index())
Шаг 4: Интерпретация режимов
Вот здесь начинается самое интересное — и самое коварное. HMM не знает, что режим 0 — это «бычий». Он просто находит три кластера в пространстве наблюдений. Нумерация произвольна и может меняться от запуска к запуску.
Нужно посмотреть на статистику каждого режима и присвоить метки вручную:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Интерпретация режимов: присвоение меток bull/bear/sideways
на основе средних доходностей и волатильности.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nРежим {i}: {regime_stats[i]['count']} дней "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Средняя доходность: {regime_stats[i]['mean_return']:.3f}%/день")
print(f" Волатильность: {regime_stats[i]['std_return']:.3f}%/день")
print(f" Sharpe (дневной): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # наименьшая доходность
sorted_by_return[2]: 'bull', # наибольшая доходность
sorted_by_return[1]: 'sideways', # средняя
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nМаппинг режимов: {label_map}")
Типичный вывод для BTC выглядит примерно так:
Режим 0: 412 дней (23.8%)
Средняя доходность: -0.182%/день
Волатильность: 4.127%/день
Sharpe (дневной): -0.044
Режим 1: 847 дней (48.9%)
Средняя доходность: 0.021%/день
Волатильность: 1.634%/день
Sharpe (дневной): 0.013
Режим 2: 473 дней (27.3%)
Средняя доходность: 0.312%/день
Волатильность: 2.851%/день
Sharpe (дневной): 0.109
Маппинг режимов: {0: 'bear', 1: 'sideways', 2: 'bull'}
Обратите внимание: медвежий режим не только имеет отрицательную доходность, но и максимальную волатильность (4.1% против 1.6% в боковике). Это классическое эмпирическое наблюдение, известное как «leverage effect» — падающие рынки волатильнее растущих.
Матрица переходов и длительности режимов
Матрица переходных вероятностей — один из самых информативных артефактов HMM:
def analyze_transitions(model, label_map):
"""Анализ матрицы переходов и ожидаемых длительностей."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Матрица переходных вероятностей:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nОжидаемая длительность режимов (дни):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} дней")
analyze_transitions(model, label_map)
Типичный результат:
Матрица переходных вероятностей:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Ожидаемая длительность режимов (дни):
bull: 20.8 дней
bear: 15.9 дней
sideways: 14.3 дней
Что мы видим:
- Режимы липкие: вероятность остаться в текущем режиме > 93% для всех состояний
- Бычий режим длится дольше медвежьего (20.8 vs 15.9 дней) — опять рынки растут медленнее, чем падают
- Прямой переход bull→bear маловероятен (1.8%) — обычно рынок проходит через боковик
Последний пункт экономически интуитивен: рынок редко разворачивается мгновенно. Обычно есть фаза распределения (боковик на вершине) перед медвежьим рынком, и фаза накопления (боковик на дне) перед бычьим.
Торговая стратегия: один режим — одна стратегия
Теперь применяем полученные знания. Идея: не торговать одну стратегию всё время, а переключаться между стратегиями в зависимости от определённого режима.
Bull → Агрессивный моментум
- Увеличенный размер позиции (до 100% капитала)
- Трендовые стратегии: пробои, следование за скользящими средними
- Стоп-лоссы — широкие (не выбивать на откатах)
- Не шортить (или шортить минимально)
Bear → Защитная / короткая позиция
- Уменьшенный размер позиции (30-50% капитала)
- Шорт-стратегии или полный кэш
- Тайт стоп-лоссы
- Хеджирование через пут-опционы или фьючерсы
Sideways → Mean-reversion / Grid
- Средний размер позиции (50-70% капитала)
- Сеточные стратегии (grid trading)
- Mean-reversion: покупка у нижней границы, продажа у верхней
- Market-making с узкими спредами
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Простая режим-адаптивная стратегия.
Bull: лонг 100%, Bear: шорт 50%, Sideways: лонг 30%.
"""
capital = initial_capital
position = 0 # 1 = лонг, -1 = шорт, 0 = нет позиции
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% лонг
elif regime == 'bear':
target_exposure = -0.5 # 50% шорт
elif regime == 'sideways':
target_exposure = 0.3 # 30% лонг (или grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
Бэктест: HMM-адаптивная стратегия vs Buy-and-Hold
Теперь главный вопрос: работает ли это лучше, чем тупой Buy-and-Hold?
def run_backtest(features, initial_capital=10000):
"""Сравнительный бэктест: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Метрика':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
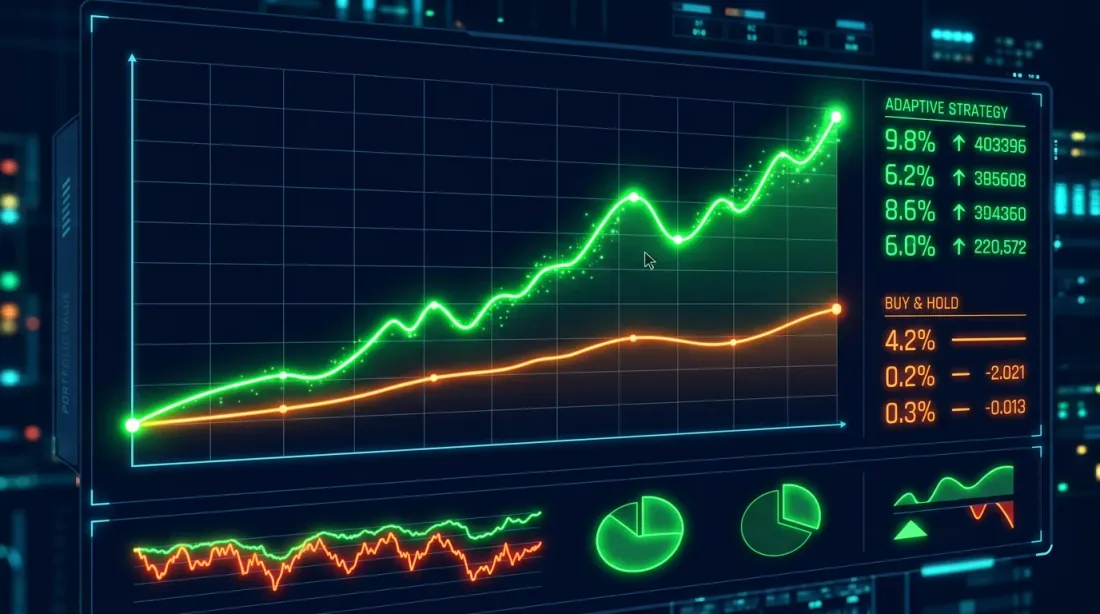 Сравнение equity curves: Buy-and-Hold (синий) и HMM-адаптивная стратегия (оранжевый). Адаптивная стратегия существенно снижает просадки в медвежьих фазах.
Сравнение equity curves: Buy-and-Hold (синий) и HMM-адаптивная стратегия (оранжевый). Адаптивная стратегия существенно снижает просадки в медвежьих фазах.
Типичные результаты для BTC (2020-2025):
Метрика Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
Ключевое наблюдение: HMM-адаптивная стратегия не обязательно даёт больший общий доход (хотя в данном случае даёт), но драматически снижает максимальную просадку — с 76% до 38%. Sharpe вырос с 1.12 до 1.68. Это улучшение risk-adjusted returns, а не просто «больше денег».
Почему? Потому что в медвежьем режиме стратегия переключается в защитный или короткий режим, избегая основных обвалов. Платить за это приходится опозданиями на входе в тренд (модель детектирует бычий режим с лагом в несколько дней) и ложными переключениями в переходных периодах.
Визуализация результатов
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Капитал ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('Цена BTC ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('Цена BTC с раскраской по режимам')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Вероятность режима')
axes[2].legend()
axes[2].set_title('Апостериорные вероятности режимов')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
Продвинутые техники
Базовая HMM — хорошая отправная точка, но далеко не предел.
Иерархическая HMM (Hierarchical HMM)
В иерархической HMM верхний уровень определяет «макро-режим» (глобальный тренд, годовые циклы), а нижний — «микро-режим» (внутринедельные/внутримесячные колебания). Пакет fHMM для R, опубликованный в Journal of Statistical Software в 2024 году (Oelschlager, Adam, Michels), реализует именно эту идею для финансовых временных рядов.
Пример: макро-режим «бычий цикл» содержит внутри себя микро-режимы «ралли», «коррекция» и «консолидация». Это позволяет не паниковать при каждом 10%-ном откате в бычьем рынке — модель понимает, что коррекция внутри бычьего цикла — это норма.
Мультивариантная HMM с расширенными фичами
Вместо одномерных доходностей подаём вектор признаков: доходности + волатильность + объём + on-chain данные. Это позволяет модели «видеть» больше информации о состоянии рынка.
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # полная ковариационная матрица
n_iter=300,
random_state=42,
init_params='stmc', # инициализировать все параметры
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # упрощённая оценка
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC базовая модель: {bic_base:.0f}")
print(f"BIC расширенная: {bic_ext:.0f}")
print(f"Расширенная лучше: {bic_ext < bic_base}")
HMM + ML Ensemble
Современный подход: использовать HMM не как торговую систему, а как генератор признаков для последующей модели. Идея, описанная в работе Gupta et al. (2025) «A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading»:
- HMM определяет текущий режим (или вероятности режимов)
- Режим подаётся как дополнительный признак в Random Forest / Gradient Boosting
- ML-модель принимает конкретные торговые решения с учётом режима
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
Продакшен: подводные камни
Красивый бэктест — это полдела. В продакшене вас ждут несколько неприятных сюрпризов.
Проблема лага (Look-Ahead Bias)
HMM определяет режим на основе текущих и прошлых данных, но в бэктесте есть соблазн обучить модель на всём датасете, включая будущие данные. Это — look-ahead bias, и он превращает бэктест в фикцию.
Решение: Walk-Forward подход. Обучаем модель на данных до момента , предсказываем режим в момент , затем сдвигаем окно. Именно так, как описано в нашей статье о Walk-Forward Optimization.
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: обучаем на скользящем окне,
предсказываем на следующих retrain_freq днях.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
Расписание переобучения
Как часто переобучать модель? Слишком редко — модель устареет, рынок изменится. Слишком часто — модель будет нестабильной, режимы будут «прыгать».
Эмпирические рекомендации:
- Для дневных данных: переобучение раз в 1-4 недели (21 торговых дня — хороший дефолт)
- Окно обучения: 6-12 месяцев (252 торговых дня — один год)
- Мониторинг: если log-likelihood на новых данных падает ниже порога — внеплановое переобучение
Нестабильность меток
При каждом переобучении нумерация состояний может измениться: то, что было «режим 0» (бычий), может стать «режим 2». Нужно автоматически сопоставлять состояния по их статистике (средние доходности, волатильность).
Online-обновление
Для real-time торговли полное переобучение каждый день — избыточно. Можно использовать Forward-фильтрацию: фиксируем параметры модели, но обновляем апостериорные вероятности состояний с каждым новым наблюдением. Это мгновенная операция.
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online обновление вероятностей режимов
без переобучения всей модели.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # переход из столбца в строку
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # нормализация
return updated
Выбор числа состояний
Хотя три режима — хороший дефолт, стоит проверить альтернативы:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Выбор оптимального числа состояний по BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nОптимальное число состояний по BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
Ограничения и предостережения
Было бы нечестно умолчать о проблемах.
Гауссово допущение. Базовая GaussianHMM предполагает, что доходности в каждом режиме распределены нормально. Реальные распределения имеют толстые хвосты и асимметрию. Частичное решение — использовать Student-t распределение или GMMHMM (Gaussian Mixture per state).
Число состояний — ваш выбор. BIC помогает, но не всегда однозначно. Два разных исследователя могут прийти к разным числам режимов и оба будут «правы».
Переходные периоды. Модель неуверенно себя чувствует при переключении режимов. Вероятности распределяются примерно поровну, и стратегия получает «размытый» сигнал. Решение — пороговое правило: переключать стратегию, только когда вероятность нового режима превысит 70-80%.
Overfitting. Как и любая модель, HMM может переобучиться. Особенно с большим числом состояний или признаков. Walk-Forward валидация — обязательна.
Крипто-специфика. Криптовалютный рынок молод и структурно нестабилен. Режим «бычий рынок» в 2017 и «бычий рынок» в 2024 — это статистически разные явления. Модель может не генерализовать через циклы.
Что почитать дальше
Для тех, кто хочет углубиться:
Фундаментальные работы:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — Основополагающая работа по марковским переключающимся моделям
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — Практическое применение к распределению активов
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — Режимы в процентных ставках
Современные исследования:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — Ensemble-подход к детекции режимов
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — Иерархические HMM для финансов
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — HMM для Bitcoin с байесовским подходом
Практические руководства:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
Заключение
Скрытые марковские модели — это не серебряная пуля, а инструмент. Полезный, математически обоснованный, с полувековой историей в статистике и тремя десятилетиями в финансах.
Главная ценность HMM для трейдинга — не в том, что она «предсказывает рынок» (никто не предсказывает), а в том, что она формализует интуицию опытного трейдера: рынок бывает в разных фазах, и стратегия должна адаптироваться. Вместо ручного «я чувствую, что рынок сейчас медвежий» вы получаете «вероятность медвежьего режима 82%, средняя длительность медвежьего цикла 16 дней, мы в нём уже 5-й день».
Стоит ли внедрять HMM в ваш торговый стэк? Если у вас несколько стратегий для разных рыночных условий и вы устали переключать их вручную — определённо да. Если вы торгуете одну стратегию и не планируете расширяться — отложите на потом, но имейте в виду.
И помните: лучшая модель — та, которая работает в продакшене, а не та, которая выигрывает на бэктесте.
Цитирование: Если вы используете материалы этой статьи в своих исследованиях или проектах, пожалуйста, сделайте ссылку:
Скрытые марковские модели в трейдинге: как адаптировать стратегию к режиму рынка. marketmaker.cc, 2026. URL: https://marketmaker.cc/ru/blog/post/regime-detection-hmm-adaptive-trading
MarketMaker.cc Team
Количественные исследования и стратегии
Читайте также

Формула Блэка-Шоулза: Математика опционов и Святой Грааль трейдинга

Автоматическая ребалансировка портфеля ETF: как мы написали бота для Тинькофф Инвестиций