Daily Stock Analysis: An AI System That Turns a Watchlist Into a Daily Decision Dashboard

daily_stock_analysis by ZhuLinsen is one of the most-starred AI-finance projects of the moment — a #1 Python repository of the day on Trendshift. But the interesting part isn't the star count. It's that the project refuses to pretend it predicts prices. Instead it solves a narrower, far more useful problem: every trading day, take your watchlist and produce a structured, explainable analytical report — and deliver it where you actually read things, your messenger.
Disclaimer from the project author: for learning and research only. It is not investment advice. Markets carry risk.
Core Idea: Not a Bot, a Daily Analyst-Reporter
Most "AI trading" repos chase the same fantasy: model in, signal out, money up. daily_stock_analysis is built on a more honest premise — the hard part of investing isn't generating one more signal, it's assembling a complete, consistent picture of a name and writing it down the same way every day.
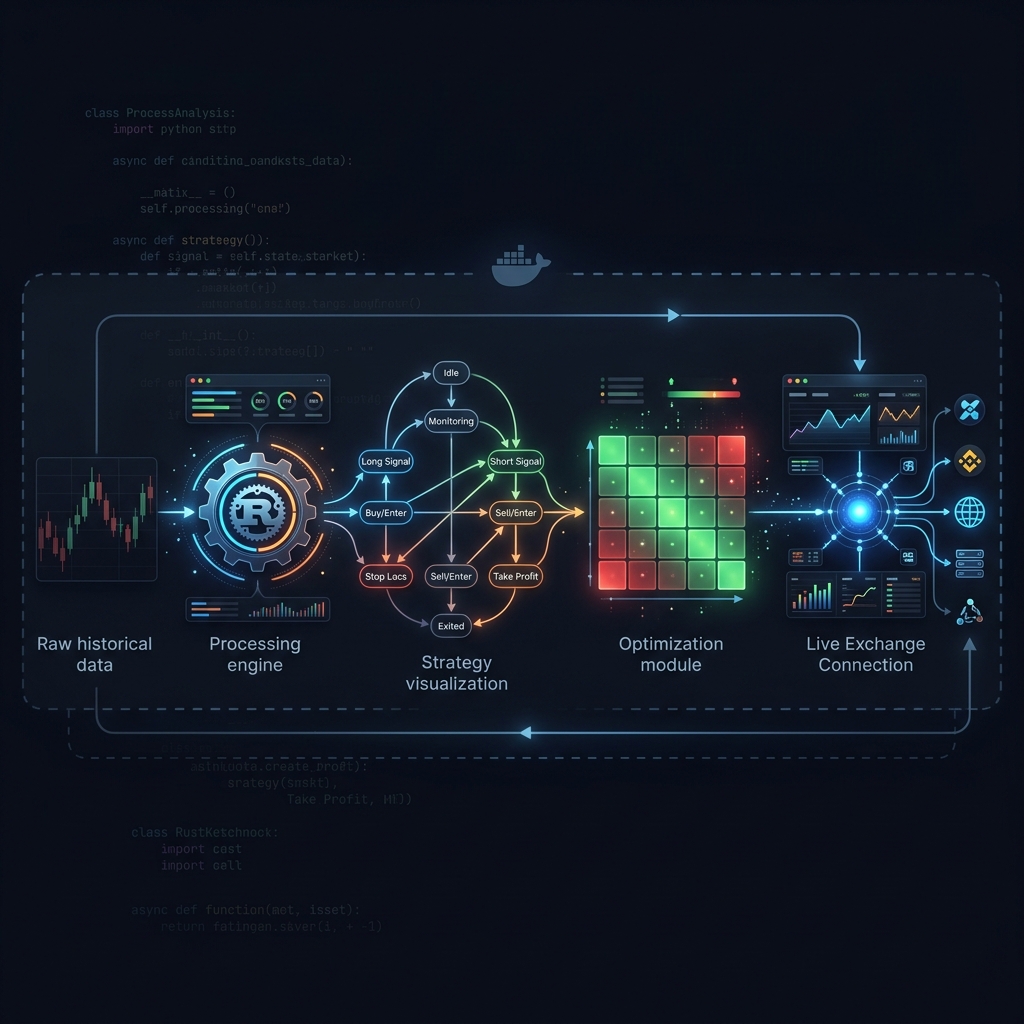
So it behaves like a junior analyst on a schedule. The pipeline is linear and legible:
| Stage | What happens |
|---|---|
| Data fetch | Quotes, daily candles, indicators, capital flow, fundamentals, chips |
| Technical analysis | Moving averages, RSI, volume, bias ratio, trend classification |
| News & intelligence | Searches recent news, announcements, sentiment per ticker |
| LLM analysis | Builds a context pack and prompt, produces a JSON decision dashboard |
| Report render | Markdown report, optionally converted to an image |
| Notification | Pushes to WeCom, Feishu, Telegram, Discord, Slack, or email |
By default it runs on a schedule (weekdays, after the close) and skips non-trading days. It covers A-shares, Hong Kong, US stocks and ETFs, with Japanese and Korean markets supported at a reduced level where data sources don't reach.
The Quietly Smart Part: Data Fallback

The most robust engineering decision in the project isn't the LLM — it's how it treats data as unreliable by default.
Market data is fetched through a priority chain of six providers, each a fallback for the last:
Efinance (P0) → Tencent (P0) → Akshare (P1) → Pytdx (P2) → Baostock (P3) → Yfinance (P4)
When you analyze a US ticker, the system automatically skips the China-only providers and routes to Yahoo Finance. If a source fails, times out, or returns partial data, the run degrades that one block instead of crashing the whole report. The prompt is even told which blocks are fallback, partial, or missing — so the model is required to write "data unavailable" rather than invent a number.
This is the right instinct for any production system: a single data source failing should never take down the whole analysis. Treat every feed as best-effort, standardize the fields, and make missing data visible rather than silently filled.
The Decision Dashboard
The LLM doesn't return prose — it returns a strict JSON "decision dashboard" that the report renders into a consistent layout:
- Core conclusion — one sentence: buy, hold, or wait, plus time sensitivity.
- Split advice — different guidance for someone holding the position vs. someone in cash.
- Data perspective — MA alignment, price vs. support/resistance, bias ratio, volume read.
- Intelligence — risk alerts and positive catalysts, each required to carry a date.
- Battle plan — concrete sniper points: ideal buy, stop-loss, target, position sizing.
- Checklist — every condition marked ✅ / ⚠️ / ❌ (bullish alignment, bias in range, volume, no major bad news, valuation).
The discipline baked into the prompt is opinionated and sensible: don't chase (a bias of more than 5% above MA5 is a hard "no buy"), only trade bullish MA alignment (MA5 > MA10 > MA20), prefer buying a shrink-volume pullback to support, and never flip between buy and sell on a single day's move.
Agent Strategies: Ask the System a Question
Beyond the daily report, the project ships an agent mode with 15 built-in strategy playbooks you can interrogate per ticker:
| Family | Examples |
|---|---|
| Trend / moving averages | MA golden cross, bull trend |
| Structure theory | Chan (Zen) theory, Elliott wave |
| Behavior / liquidity | emotion cycle, volume breakout, bottom volume, shrink pullback |
| Catalyst / narrative | hot theme, event-driven, expectation repricing |
| Quality / growth | growth quality |
Each strategy is a YAML file with its own rules, required tools, and scoring adjustments — so the "intelligence" is configurable and auditable, not hidden inside one giant prompt.
How to Read It Without Self-Deception
Any project like this is easy to over-trust. An honest evaluation checklist:
- News source quality. The intelligence block is only as good as your configured search providers — without them, sentiment and catalysts go empty and the report leans entirely on technicals.
- Determinism. LLM outputs vary; the same ticker can read slightly differently across runs. Treat the dashboard as a structured opinion, not a fixed truth.
- Coverage by market. A-share depth (capital flow, chips, dragon-tiger) gracefully degrades to
not_supportedon markets the data doesn't cover. - Data freshness. Watch for
fallback/partialflags — degraded inputs should lower your confidence, exactly as the prompt instructs. - Backtesting ≠ profit. The report is decision support, not a verified edge.
Limitations and Honest Assessment
What daily_stock_analysis is not:
- Not an execution system. It analyzes and reports; it doesn't place orders or model liquidity.
- Model-dependent. Output quality tracks the LLM you point it at.
- Search-dependent. Without news API keys, the qualitative half of the report thins out.
- Non-deterministic. Identical inputs can yield slightly different dashboards.
Links
- 💻 GitHub: ZhuLinsen/daily_stock_analysis
- 📄 License: MIT
Conclusion
daily_stock_analysis is valuable not as an oracle but as a repeatable analytical habit, automated:
- Standardize what "looking at a stock" means, every day.
- Treat data as unreliable and make gaps visible.
- Make the conclusion explainable — score, levels, checklist, risks.
- Separate idea generation (15 strategies) from a disciplined decision frame.
For learning, daily review, and prototyping a research workflow, it's well-built. For production, the next layer is the same one every serious system needs: validated data, model-drift control, realistic execution, and risk rules that live in code, not just prompts.
Authors

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Read More

AI Hedge Fund: A Multi-Agent Fund Where AI Analysts Vote on Trades

Kronos: A Foundation Model That Teaches Candlestick Charts to Speak Transformer Language