每个算法交易者都有一个存在主义危机时刻。你花了三个月打磨一个策略。回测显示夏普比率 2.4。权益曲线堪称艺术品。你启动了机器人。前两周充满喜悦,策略在源源不断地产生超额收益。然后市场"切换"了——你的动量机器人开始在横盘中系统性地亏损资金,不断追高杀低。
问题不在于策略本身。问题在于市场不是一个系统,而是多个系统,它们之间的切换毫无预警。在趋势中表现完美的动量策略会在震荡市中吞噬本金。在横盘中稳定盈利的网格策略会在单边行情中爆仓。在平静市场中稳定的均值回归策略会在黑天鹅事件中遭遇爆仓。
问题不是"哪个策略更好",而是"当前的市场处于什么状态,哪个策略与之匹配"。这正是隐马尔可夫模型(Hidden Markov Models,HMM)登场的地方——一种数学框架,让你能够将这种直觉形式化。
市场是非平稳的,这不是缺陷,而是特征
让我们从一个不愉快的事实开始:几乎所有基本统计模型都假设数据是平稳的。均值和方差不随时间变化,自相关性恒定,分布稳定。金融时间序列同时违反了所有这些假设。
观察 BTC 过去 5 年的日收益率。2024 年牛市期间的平均日收益率约为 +0.3%,标准差约 2.5%。2022 年熊市中——平均 -0.15%,标准差约 4%。2023 年夏季横盘中——平均约 0%,标准差约 1.5%。这是三种截然不同的统计状态,具有不同的分布。
形式化地说:设 为时刻 的收益率。在平稳世界中,,参数恒定。而在现实中,参数本身就是随机过程:,其中 是隐藏状态(市场状态),在有限数量的值之间切换。
这个思想由 James Hamilton 于 1989 年在其开创性论文《A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle》中形式化。他证明了商业周期可以建模为两个隐藏状态——衰退和扩张——之间的切换,使用马尔可夫机制。从那时起,Hamilton 模型成为计量经济学中被引用最多的工具之一。
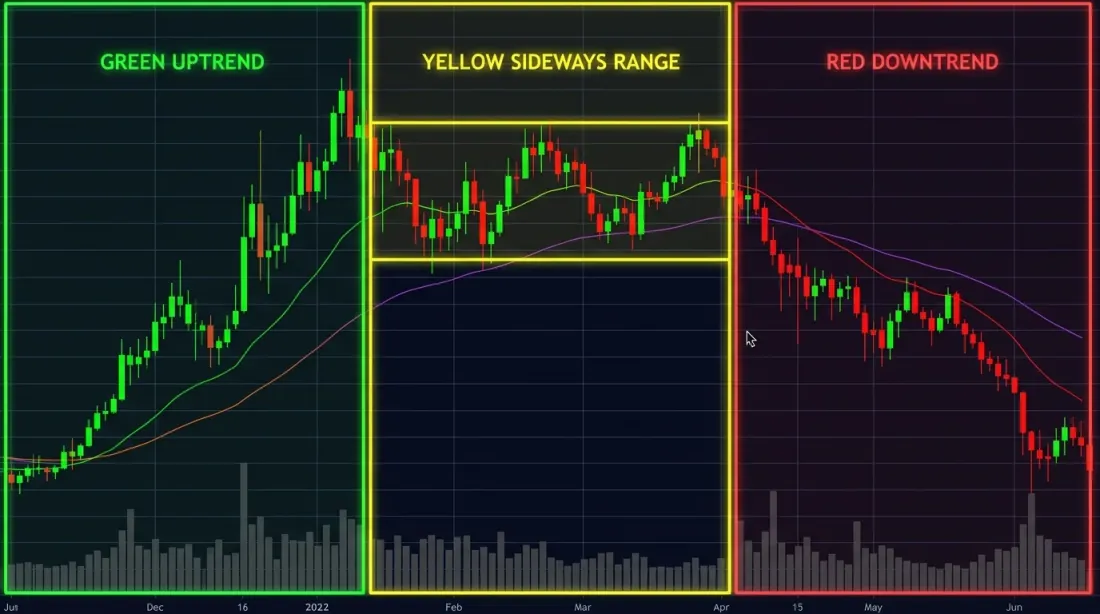 三种市场状态——牛市(绿色)、熊市(红色)和横盘(黄色)——事后来看显而易见,但实时检测切换要困难得多。
三种市场状态——牛市(绿色)、熊市(红色)和横盘(黄色)——事后来看显而易见,但实时检测切换要困难得多。
HMM:通过类比建立直觉
在深入公式之前,让我们先建立直觉性的理解。
马尔可夫链:无记忆性
马尔可夫链是一种随机过程,其中未来只取决于现在,而不取决于过去。明天的天气取决于今天的天气,但不取决于一周前的天气(这是一个很强的简化,但作为模型是可行的)。
市场状态的行为类似。如果今天市场处于牛市状态,明天继续保持牛市的概率很高(比如 95%)。转入熊市的概率很低(3%)。转入横盘的概率更低(2%)。这就是转移概率矩阵。
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
注意:对角线元素很高——状态是"黏性"的。市场不会每天在牛市和熊市之间跳跃。它会在一个状态中持续数周甚至数月,然后才切换。状态的预期持续时间为 。对于 的牛市状态,这是 20 天。对于 的熊市状态——大约 14 天。
隐藏状态:我们只能看到影子
关键词是"隐藏"。我们不能直接观察到市场状态。没有人会挂出"注意,正在转入熊市"的标牌。我们只能看到观测值——收益率、波动率、成交量。而状态是一个需要从观测值中推断出来的潜变量。
这就像在一个没有窗户的房间里,试图通过从外面进来的人的穿着来判断天气。拿着雨伞?大概是在下雨。穿着短裤戴太阳镜?可能是晴天。但一个穿短裤的人并不意味着一定是晴天——也许他只是个乐观主义者。你需要积累观测数据,概率性地估计隐藏状态。
在 HMM 中,每个隐藏状态"发射"(emit)来自其自身分布的观测值:
- 牛市状态 → 收益率来自 ,其中 , 适中
- 熊市状态 → 收益率来自 ,其中 , 较高
- 横盘 → 收益率来自 ,其中 , 较低
注意一个特征性的规律:熊市状态通常不仅具有负均值,还具有更高的波动率。市场下跌坐电梯,上涨走楼梯——HMM 会自动捕捉到这一点。
 隐马尔可夫模型架构:隐藏状态(市场状态)按照马尔可夫链切换,每个状态从其自身的高斯分布生成可观测的收益率。
隐马尔可夫模型架构:隐藏状态(市场状态)按照马尔可夫链切换,每个状态从其自身的高斯分布生成可观测的收益率。
HMM 的三个算法:前向、维特比、鲍姆-韦尔奇
所有 HMM 工作都归结为三个基本问题,每个问题都有其对应的算法。
问题 1:这些观测值的概率是多少?(前向算法)
问题: 给定一系列收益率,在给定模型参数下,观察到恰好这样一个序列的概率是多少?
用途: 模型比较(AIC/BIC)、充分性检验。
工作原理: 前向算法是动态规划。在每个时间步 ,我们计算"前向变量" ——观察到序列 并在时刻 处于状态 的概率。
递推关系:
其中 是从状态 到 的转移概率, 是在状态 中观测到 的概率。用通俗的话说:我们对所有可能到达状态 的路径求和,然后乘以观测概率。
复杂度:,而非朴素的 ,其中 是状态数, 是序列长度。对于 3 种状态和 1000 个观测值,这是 9000 次运算而不是 。差距可以说是相当显著的。
问题 2:最可能的状态序列是什么?(维特比算法)
问题: 给定一系列收益率,什么样的隐藏状态(市场状态)序列最可能生成了它?
用途: 这正是我们在交易中需要的——确定每个时间点的市场状态。
工作原理: 维特比算法与前向算法相同,但不是对所有路径求和,而是取最大值。我们寻找的不是所有可能路径的概率,而是最可能的路径。
加上回溯(backtracking)来恢复状态序列本身。结果是解码后的状态序列:"牛市-牛市-牛市-熊市-熊市-横盘-..."
在实际交易中,更常用的不是维特比(全局最优),而是滤波——每个时刻的后验状态概率:。这使得在线工作成为可能,无需等待整个序列,并能获得"软"估计,如"70% 牛市,25% 横盘,5% 熊市"。
问题 3:如何训练模型?(鲍姆-韦尔奇算法)
问题: 仅给定观测值,什么样的模型参数(、、)能最大化数据似然度?
用途: 在历史数据上训练模型。
工作原理: 鲍姆-韦尔奇算法是 EM 算法(期望最大化)的特例:
- E 步: 使用当前参数,计算期望隐藏状态(通过前向-后向算法)
- M 步: 更新参数,在这些期望状态下最大化似然度
- 重复直到收敛
一个重要的细节:EM 只保证收敛到局部最大值。不同的初始条件可能给出不同的结果。在实践中,模型会用不同的初始化训练多次,然后根据对数似然选择最佳结果。在 hmmlearn 中,这通过 n_init 参数自动完成。
加密市场状态:我们在寻找什么
对于加密货币,经典的三状态划分由于明显的市场阶段而效果特别好。
状态 1:牛市(Bull)
- 平均收益率: 每天 +0.15% ... +0.5%
- 波动率(标准差): 每天 2-3%
- 特征: 持续上涨,伴随适度回调
- 持续时间: 连续 2-6 个月
- 成交量: 增加,尤其是在现货市场
- 链上数据: MVRV > 1.5,活跃地址增长
状态 2:熊市(Bear)
- 平均收益率: 每天 -0.1% ... -0.4%
- 波动率(标准差): 每天 3-6%
- 特征: 急剧下跌、清算连锁反应、死猫反弹
- 持续时间: 1-4 个月(通常比牛市短)
- 成交量: 恐慌性抛售时激增,然后衰减
- 链上数据: MVRV < 1,交易所流入增加
状态 3:横盘(Sideways / 积累期)
- 平均收益率: 每天约 0%
- 波动率(标准差): 每天 1-2%
- 特征: 区间震荡,假突破
- 持续时间: 1-3 个月
- 成交量: 低且递减
- 链上数据: 指标稳定,活动减少
为什么是三种状态而不是两种或五种?两种太粗糙——丢失了横盘信息(而对于做市机器人来说,这是最赚钱的状态)。五种或更多——模型会过拟合,转移概率不稳定,解释困难。三种是最优平衡,被信息准则(AIC/BIC)和经济直觉所证实。
不过,状态数是一个超参数,应该进行测试。Guidolin 和 Timmermann(2007)在其论文《Asset Allocation under Multivariate Regime Switching》中为股债混合投资组合发现了四种状态:崩盘、缓慢增长、牛市和复苏。
特征工程:模型输入什么
最简单的方案是只输入日收益率。这可行,但可以做得更好。以下是在实践中经过验证的特征集:
价格特征
- 日对数收益率:
- 滚动波动率: ,窗口 (例如 20 天)
- 滚动平均收益率:
成交量特征
- 标准化成交量:
- 量价相关性: 成交量与绝对收益率在滚动窗口上的相关性
链上特征(加密货币适用)
- MVRV 比率: 市值与已实现市值之比。MVRV > 2——市场过热,< 1——被低估
- NVT 比率: 网络价值与交易量之比。区块链版本的市盈率
- 交易所净流量: 流入交易所的净量。正值——卖压,负值——积累
- 活跃地址数: 活跃地址数量(增长 = 兴趣,下降 = 冷淡)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
重要提示: 所有特征必须是平稳的(或至少近似平稳)。对数收益率是平稳的,价格不是。成交量最好标准化。波动率可以保持原样——它也是准平稳的。
另一个细节:多变量 HMM(输入特征向量)比单变量效果更好,但需要更多数据来训练。对于拥有 5 年以上历史的加密货币,这通常不是问题。对于只有 3 个月历史的新币——最好限制在一两个特征。
使用 hmmlearn 的 Python 逐步实现
进入代码部分。hmmlearn 库是 Python 中 HMM 的事实标准。API 简单,与 scikit-learn 兼容,开箱即用。
第 1 步:数据加载
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
第 2 步:特征准备与 HMM 训练
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
第 3 步:状态解码
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
第 4 步:状态解读
这里开始变得有趣——也最棘手。HMM 不知道状态 0 是"牛市"。它只是在观测空间中找到三个聚类。编号是任意的,可能每次运行都不同。
需要查看每个状态的统计数据并手动分配标签:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
BTC 的典型输出大致如下:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
注意:熊市状态不仅有负收益率,还有最高的波动率(4.1% 对比横盘的 1.6%)。这是一个经典的经验观察,被称为"杠杆效应"——下跌市场比上涨市场波动更大。
转移矩阵与状态持续时间
转移概率矩阵是 HMM 最具信息量的产物之一:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
典型结果:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
我们观察到:
- 状态是黏性的: 所有状态的维持概率 > 93%
- 牛市状态持续时间更长, 长于熊市(20.8 天 vs 15.9 天)——再次证明市场上涨慢于下跌
- 牛市直接转熊市的概率很低(1.8%)——通常市场会经过横盘阶段
最后一点在经济上是直觉性的:市场很少瞬间反转。通常在熊市之前有一个分发阶段(顶部横盘),在牛市之前有一个积累阶段(底部横盘)。
交易策略:一种状态对应一种策略
现在应用我们所学到的知识。核心思想:不要一直交易同一个策略,而是根据检测到的市场状态在不同策略之间切换。
牛市 → 激进动量
- 增大仓位(最高 100%)
- 趋势策略:突破、均线跟随
- 宽止损(避免在回调中被止损出局)
- 不做空(或极少做空)
熊市 → 防御型 / 做空
- 缩小仓位(30-50%)
- 做空策略或全部现金
- 紧止损
- 通过看跌期权或期货对冲
横盘 → 均值回归 / 网格
- 中等仓位(50-70%)
- 网格交易策略
- 均值回归:在下边界买入,在上边界卖出
- 窄价差做市
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
回测:HMM 自适应策略 vs 买入持有
现在是最关键的问题:这是否比简单的买入持有更好?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
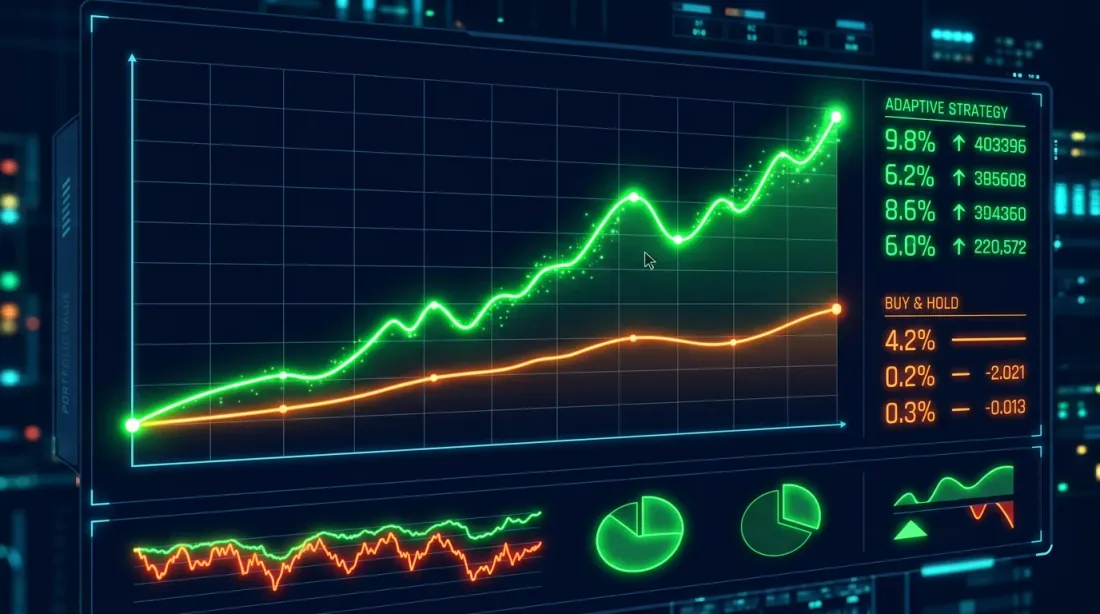 权益曲线比较:买入持有(蓝色)和 HMM 自适应策略(橙色)。自适应策略在熊市阶段显著降低了回撤。
权益曲线比较:买入持有(蓝色)和 HMM 自适应策略(橙色)。自适应策略在熊市阶段显著降低了回撤。
BTC 的典型结果(2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
关键观察:HMM 自适应策略不一定带来更高的总收益(尽管在这个案例中确实如此),但它大幅降低了最大回撤——从 76% 降至 38%。夏普比率从 1.12 上升到 1.68。这是风险调整后收益的改善,而不仅仅是"赚更多钱"。
为什么?因为在熊市状态下,策略切换到防御或做空模式,避开了主要的下跌。代价是进入趋势时的延迟(模型检测到牛市状态会有几天的滞后)以及过渡期间的错误切换。
结果可视化
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
高级技术
基础 HMM 是一个很好的起点,但远非极限。
层次 HMM(Hierarchical HMM)
在层次 HMM 中,上层确定"宏观状态"(全球趋势、年度周期),下层确定"微观状态"(周内/月内波动)。R 语言的 fHMM 包由 Oelschlager、Adam 和 Michels 在 2024 年发表于 Journal of Statistical Software,正是为金融时间序列实现了这个思想。
例如:宏观状态"牛市周期"内部包含微观状态"拉升"、"回调"和"整理"。这使得在牛市中每次 10% 的回调时不必恐慌——模型理解牛市周期内的回调是正常的。
扩展特征的多变量 HMM
不是输入单变量收益率,而是输入特征向量:收益率 + 波动率 + 成交量 + 链上数据。这使模型能够"看到"更多关于市场状态的信息。
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + ML 集成
现代方法:将 HMM 不作为交易系统,而是作为下游模型的特征生成器。这个思想在 Gupta 等人(2025)的论文《A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading》中有描述:
- HMM 确定当前状态(或状态概率)
- 状态作为额外特征输入随机森林 / 梯度提升模型
- ML 模型根据状态做出具体的交易决策
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
生产环境:常见陷阱
漂亮的回测只是成功的一半。在生产环境中,有几个令人不快的意外在等着你。
滞后问题(前瞻偏差)
HMM 基于当前和过去的数据确定状态,但在回测中存在一个诱惑——在整个数据集(包括未来数据)上训练模型。这就是前瞻偏差,它会把回测变成虚构。
解决方案: 滚动前向(Walk-Forward)方法。在时刻 之前的数据上训练模型,预测时刻 的状态,然后移动窗口。正如我们在Walk-Forward 优化一文中所描述的。
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
重新训练频率
多久重新训练一次模型?太少——模型过时,市场变化。太频繁——模型不稳定,状态"跳跃"。
经验性建议:
- 日线数据: 每 1-4 周重新训练(21 个交易日是一个好的默认值)
- 训练窗口: 6-12 个月(252 个交易日——一年)
- 监控: 如果新数据上的对数似然低于阈值——进行计划外重新训练
标签不稳定性
每次重新训练时,状态编号可能会改变:原来的"状态 0"(牛市)可能变成"状态 2"。需要根据统计特征(平均收益率、波动率)自动匹配状态。
在线更新
对于实时交易,每天完全重新训练过于冗余。可以使用前向滤波:固定模型参数,但每收到一个新观测值就更新后验状态概率。这是一个瞬时操作。
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
选择状态数
虽然三种状态是一个好的默认值,但应该测试其他选项:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
局限性与注意事项
隐瞒问题是不诚实的。
高斯假设。 基础 GaussianHMM 假设每个状态中的收益率服从正态分布。真实分布具有厚尾和不对称性。部分解决方案是使用 Student-t 分布或 GMMHMM(每个状态使用高斯混合)。
状态数是你的选择。 BIC 有帮助,但并不总是明确的。两个不同的研究者可能得出不同数量的状态,而且都是"正确的"。
过渡期。 模型在状态切换时表现不确定。概率大致均匀分布,策略收到"模糊"信号。解决方案是阈值规则:只有当新状态的概率超过 70-80% 时才切换策略。
过拟合。 像任何模型一样,HMM 也可能过拟合。尤其是状态数或特征数较多时。Walk-Forward 验证是必须的。
加密货币特性。 加密货币市场年轻且结构不稳定。2017 年的"牛市"和 2024 年的"牛市"是统计上不同的现象。模型可能无法跨周期泛化。
延伸阅读
给想要深入了解的读者:
基础性论文:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — 马尔可夫切换模型的奠基性工作
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — 在资产配置中的实际应用
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — 利率中的状态切换
现代研究:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — 状态检测的集成方法
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — 金融领域的层次 HMM
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — 贝叶斯方法的比特币 HMM
实践指南:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
结论
隐马尔可夫模型不是银弹,而是一种工具。一种有用的、数学上严谨的工具,在统计学中有半个世纪的历史,在金融领域有三十年的应用。
HMM 对交易的核心价值不在于它"预测市场"(没有人能做到),而在于它将经验丰富的交易者的直觉形式化:市场经历不同的阶段,策略必须适应。将主观的"我感觉市场现在是熊市"替换为"熊市状态的概率为 82%,熊市周期的平均持续时间为 16 天,我们已经处于第 5 天"。
是否应该将 HMM 集成到你的交易技术栈中?如果你有针对不同市场条件的多种策略,并且厌倦了手动切换——毫无疑问应该。如果你只交易一种策略且不打算扩展——暂时搁置,但记在心里。
记住:最好的模型是在生产环境中有效的模型,而不是在回测中获胜的模型。
引用: 如果您在研究或项目中使用了本文材料,请引用:
隐马尔可夫模型在交易中的应用:如何根据市场状态调整策略。 marketmaker.cc,2026。URL: https://marketmaker.cc/zh/blog/post/regime-detection-hmm-adaptive-trading
MarketMaker.cc Team
量化研究与策略