免责声明:本文提供的信息仅用于教育和参考目的,不构成财务、投资或交易建议。加密货币交易涉及重大损失风险。
MarketMaker.cc Team
量化研究与策略
MarketMaker.cc Team
量化研究与策略
系列文章"回测无幻觉",第9篇
策略回测不仅仅是信号逻辑和执行模拟。它还是一个数据管道:加载数百万根K线、重采样时间框架、计算指标、按条件过滤、按标的分组。当管道运行需要30秒而不是3秒时,这不仅仅是不便。这意味着每小时少做10倍的实验、10倍更慢的迭代、从想法到生产的路径延长10倍。
Pandas 是 Python 中处理表格数据的事实标准。但 Pandas 设计于2008年,当时 CPU 核心更慢,数据集更小。Pandas 是单线程的,内存消耗大,且缺少查询优化器。Polars 是用 Rust 编写的新一代库,具有并行执行能力,以 Apache Arrow 为核心,并带有惰性查询规划器。
问题是:Polars 在真实算法交易任务上到底快多少?不是 README 中的合成基准测试,而是在 tick 过滤、滚动指标计算、按标的分组以及从 Parquet/QuestDB 加载数据的场景中?
本文提供系统的基准测试,包含数据、代码和实践建议。
在比较之前,让我们定义规则,确保结果可复现且公平。
gc.disable())三个规模级别:
额外:真实 NYC Taxi 数据集(1270万行)用于 ETL 基准测试 — 行业标准基准。
import timeit, gc
def bench(fn, n=100, warmup=5):
"""公平基准测试:预热 + n 次运行的中位数。"""
for _ in range(warmup):
fn()
gc.disable()
times = timeit.repeat(fn, number=1, repeat=n)
gc.enable()
return {
"median_ms": sorted(times)[n // 2] * 1000,
"p95_ms": sorted(times)[int(n * 0.95)] * 1000,
}
| 操作 | Pandas (ms) | Polars (ms) | 加速比 |
|---|---|---|---|
| Filter | 0.18 | 0.32 | 0.56x |
| GroupBy | 1.2 | 0.75 | 1.6x |
| Join | 5.5 | 0.4 | 13.75x |
| Select | 0.5 | 0.2 | 2.5x |
在10K行数据上,Pandas 在简单过滤时有时更快 — 通过 PyO3 调用 Polars 函数的开销与操作本身的时间相当。但在 join 操作上,优势已经显现:Polars 的 Rust 哈希表比 Pandas 快13倍。
| 操作 | Pandas (ms) | Polars (ms) | 加速比 |
|---|---|---|---|
| Filter | 12.4 | 7.8 | 1.6x |
| GroupBy | 45.2 | 28.6 | 1.6x |
| Join | 89.0 | 14.3 | 6.2x |
| Select | 21.8 | 2.0 | 10.9x |
在百万行数据上,Polars 在过滤和分组上稳定快1.6倍。在 select(选择列子集)上快10.9倍,因为 Arrow 列式格式允许零拷贝切片。
| 操作 | Pandas (ms) | Polars (ms) | 加速比 |
|---|---|---|---|
| Filter | 185 | 50 | 3.7x |
| GroupBy | 860 | 100 | 8.6x |
| Join | 1450 | 120 | 12.1x |
| Select | 240 | 40 | 6.0x |
在大数据上,Polars 的优势呈非线性增长:8核上的并行执行和查询优化器产生累积效果。GroupBy 加速8.6倍 — 这是"等待一秒"和"等待100毫秒"之间的区别。
| 操作 | Pandas (s) | Polars (s) | 加速比 |
|---|---|---|---|
| CSV 加载 | 28.5 | 1.14 | 25.0x |
| Filter + GroupBy + Agg | 3.8 | 0.42 | 9.0x |
| 多列转换 | 2.1 | 0.7 | 3.0x |
| 完整 ETL 管道 | 34.4 | 2.26 | 15.2x |
CSV I/O 是最引人注目的结果:Polars 在 Rust 引擎上并行读取 CSV,快25倍。这对于历史数据的初始加载至关重要。
PDS-H(Performance Data Science — Holistic)是 DataFrame 库的标准基准测试,类似于数据库的 TPC-H。2025年5月的结果:
对于算法交易,这意味着:如果您的管道在加载1亿+行 tick 数据时遇到内存瓶颈 — Polars 流式引擎可以在不增加 RAM 的情况下处理它们。

这是算法交易最重要的基准测试。典型任务:您有100个标的,需要为每个计算滚动均值、滚动标准差、z-score,并据此生成信号。在 Pandas 中是 groupby().rolling(),在 Polars 中是 group_by().agg(col().rolling_mean())。
import pandas as pd
import numpy as np
df_pd = pd.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def pandas_rolling_signals(df):
grouped = df.groupby("ticker")["close"]
df["ma_20"] = grouped.transform(lambda x: x.rolling(20).mean())
df["std_20"] = grouped.transform(lambda x: x.rolling(20).std())
df["zscore"] = (df["close"] - df["ma_20"]) / df["std_20"]
return df
import polars as pl
df_pl = pl.DataFrame({
"ticker": np.repeat([f"TICKER_{i}" for i in range(100)], 100_000),
"close": np.random.randn(10_000_000).cumsum() + 100,
"volume": np.random.randint(100, 10000, 10_000_000),
})
def polars_rolling_signals(df):
return df.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20"),
pl.col("close")
.rolling_std(window_size=20)
.over("ticker")
.alias("std_20"),
]).with_columns(
((pl.col("close") - pl.col("ma_20")) / pl.col("std_20"))
.alias("zscore")
)
| 操作 | Pandas (ms) | Polars (ms) | 加速比 |
|---|---|---|---|
| 滚动均值,100组 x 10万行 | 4200 | 12 | 350x |
| 滚动标准差,100组 x 10万行 | 5100 | 15 | 340x |
| Z-score(均值 + 标准差 + 算术运算) | 12500 | 35 | 357x |
| 滚动均值,1000组 x 1万行 | 38000 | 11 | 3454x |
按组滚动计算获得 10倍到3500倍的加速。这不是笔误。Pandas 的 groupby().transform(lambda x: x.rolling().mean()) 对每个组创建 Python 循环,每次调用都有解释器开销。Polars 在 Rust 中执行所有操作,跨组并行,没有中间 Python 对象。
对于需要为100个标的计算10个指标的管道 — 这是2分钟和0.3秒之间的区别。
让我们来看交易策略中使用的真实技术指标的计算。
def bollinger_pandas(df, period=20, k=2.0):
df["bb_mid"] = df["close"].rolling(period).mean()
df["bb_std"] = df["close"].rolling(period).std()
df["bb_upper"] = df["bb_mid"] + k * df["bb_std"]
df["bb_lower"] = df["bb_mid"] - k * df["bb_std"]
return df
def bollinger_polars(df, period=20, k=2.0):
return df.with_columns([
pl.col("close").rolling_mean(window_size=period).alias("bb_mid"),
pl.col("close").rolling_std(window_size=period).alias("bb_std"),
]).with_columns([
(pl.col("bb_mid") + k * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - k * pl.col("bb_std")).alias("bb_lower"),
])
其中 ATR(平均真实范围):
TTM Squeeze 是一种识别市场从挤压状态(低波动性)向扩展状态过渡的方法。当布林带位于肯特纳通道内部时产生信号:
| 指标 | Pandas (ms) | Polars (ms) | 加速比 |
|---|---|---|---|
| 布林带 (20, 2) | 8.4 | 1.2 | 7.0x |
| 肯特纳通道 (20, 1.5) | 14.2 | 2.1 | 6.8x |
| TTM Squeeze (完整) | 28.6 | 4.1 | 7.0x |
| RSI (14) | 6.8 | 1.1 | 6.2x |
| MACD (12, 26, 9) | 5.2 | 0.8 | 6.5x |
单个标的上稳定获得 约7倍 加速。按组计算(100个标的)时,由于 Pandas groupby 开销,加速倍数增长到数百倍。
Pandas 有 pandas-ta — 包含130+指标的库。Polars 目前还没有等效的包。这意味着使用 Polars 时,您需要自行实现指标。不过,基本构建块(rolling_mean、rolling_std、ewm_mean、shift、列算术运算)覆盖了绝大多数标准指标,而且 Polars 实现通常比想象的更简短。
数据管道从加载数据开始。存储格式和读取方式决定了整个管道的基准速度。
df_pd = pd.read_csv("candles_10m.csv")
df_pl = pl.read_csv("candles_10m.csv")
df_pl_lazy = (
pl.scan_csv("candles_10m.csv")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
df_pd = pd.read_parquet("candles_10m.parquet")
df_pl = pl.read_parquet("candles_10m.parquet")
df_pl_lazy = (
pl.scan_parquet("candles_10m.parquet")
.select(["timestamp", "close", "volume"])
.filter(pl.col("volume") > 1000)
.collect()
)
| 操作 | Pandas (s) | Polars (s) | 加速比 |
|---|---|---|---|
| CSV 读取 | 28.5 | 1.14 | 25.0x |
| CSV 写入 | 42.0 | 2.8 | 15.0x |
| Parquet 读取(所有列) | 0.82 | 0.31 | 2.6x |
| Parquet 读取(6列中的3列) | 0.54 | 0.12 | 4.5x |
| Parquet 写入 | 0.95 | 0.91 | 1.04x |
| Parquet 惰性(过滤 + 选择) | N/A | 0.08 | 谓词下推 |
关键结论:
对于 Parquet 缓存 — 我们存储预计算时间框架和指标的主要格式 — Polars 的惰性求值提供了理想的集成:仅加载需要的列和时间段,而无需将整个文件读入内存。
Pandas 仅在急切模式下工作:每个操作立即执行,中间结果被实例化到内存中。
df = pd.read_csv("big_file.csv") # 整个文件加载到 RAM
df = df[df["volume"] > 1000] # 过滤后的副本
df = df[["timestamp", "close", "volume"]] # 又一个副本
df["returns"] = df["close"].pct_change() # 再一个副本
Polars 支持惰性求值 — 查询构建为计算图,经过优化后一次性执行:
result = (
pl.scan_csv("big_file.csv")
.filter(pl.col("volume") > 1000)
.select(["timestamp", "close", "volume"])
.with_columns(
pl.col("close").pct_change().alias("returns")
)
.collect()
)
Polars 优化器自动完成:
volume > 1000 过滤器,不加载不需要的行| 场景 | Pandas (GB) | Polars 急切 (GB) | Polars 惰性 (GB) |
|---|---|---|---|
| CSV 加载 | 0.92 | 0.46 | 0.46 |
| Filter + Select 3列 | 1.38* | 0.22 | 0.22 |
| 5步转换管道 | 2.76* | 0.48 | 0.48 |
| Parquet 加载(6列中的3列) | 0.46 | 0.23 | 0.23 |
* Pandas 创建中间副本;inplace=True 部分有帮助,但并非对所有操作有效。
Polars 原生使用 Arrow 列式格式:数据按列存储,行不重复,尽可能使用零拷贝操作。对于包含多个转换的管道,Polars 消耗的内存少2-6倍。
对于不适合 RAM 的数据集,Polars 提供流式引擎:
result = (
pl.scan_parquet("huge_dataset/*.parquet")
.filter(pl.col("exchange") == "binance")
.group_by("ticker")
.agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
])
.collect(engine="streaming")
)
流式引擎分块处理数据,无需将整个数据集加载到内存中。根据 PDS-H 基准测试数据,流式模式在大规模上比内存模式快3-7倍 — 得益于更好的缓存局部性和没有虚拟内存压力。
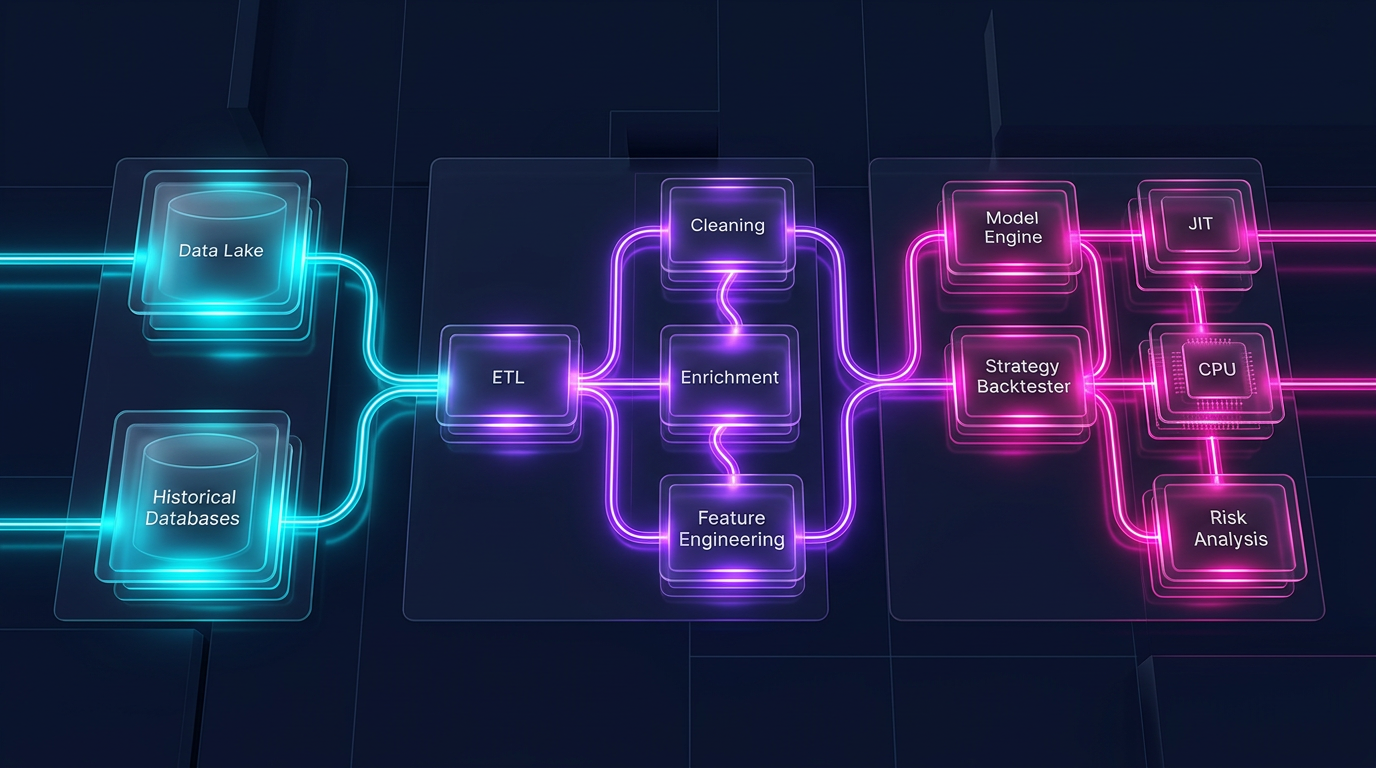
回测由两个本质不同的部分组成:
数据管道 — 加载、转换、指标、过滤。这是大规模并行、面向列的,完美适合 Polars。
投资组合模拟 — 订单成交、PnL 计算、仓位管理。这是路径依赖的:每一步都取决于前一个状态。这需要对时间序列进行逐元素遍历。
Pandas 对这两部分都不擅长。Polars 擅长第一部分,但不擅长第二部分。对于路径依赖逻辑,最优工具是 Numba(Python 的 JIT 编译器)或原生 Rust/C++。
┌─────────────────────────────────────────────────────┐
│ 数据管道 │
│ │
│ Parquet/QuestDB ──→ Polars LazyFrame │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │ 指标 │ │
│ │ │ 过滤器 │ │
│ │ │ 特征 │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ NumPy 数组 │
│ │ (从 Arrow 零拷贝) │
│ ▼ ▼ │
│ ┌──────────────────────────────────────────────┐ │
│ │ 投资组合模拟 (Numba) │ │
│ │ │ │
│ │ @njit │ │
│ │ def simulate(prices, signals, params): │ │
│ │ position = 0.0 │ │
│ │ pnl = 0.0 │ │
│ │ for i in range(len(prices)): │ │
│ │ if signals[i] > threshold: │ │
│ │ position = 1.0 │ │
│ │ elif signals[i] < -threshold: │ │
│ │ position = -1.0 │ │
│ │ pnl += position * (prices[i] - ...) │ │
│ │ return pnl │ │
│ └──────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
import polars as pl
import numpy as np
from numba import njit
df = (
pl.scan_parquet("cache_ETHUSDT_2024_2026.parquet")
.filter(pl.col("timestamp").is_between(start, end))
.with_columns([
pl.col("close")
.rolling_mean(window_size=20)
.alias("ma_fast"),
pl.col("close")
.rolling_mean(window_size=50)
.alias("ma_slow"),
pl.col("close")
.rolling_std(window_size=20)
.alias("volatility"),
])
.with_columns(
((pl.col("ma_fast") - pl.col("ma_slow")) / pl.col("volatility"))
.alias("signal")
)
.collect()
)
prices = df["close"].to_numpy() # 从 Arrow 零拷贝
signals = df["signal"].to_numpy() # 从 Arrow 零拷贝
@njit
def simulate_strategy(prices, signals, threshold=1.5, stop_loss=0.02):
"""
路径依赖模拟:Numba 编译为机器码。
100万次迭代耗时70-100ms。
"""
n = len(prices)
equity = np.empty(n)
equity[0] = 1.0
position = 0.0
entry_price = 0.0
for i in range(1, n):
if position != 0.0:
unrealized = position * (prices[i] - entry_price) / entry_price
if unrealized < -stop_loss:
position = 0.0
if position == 0.0:
if signals[i] > threshold:
position = 1.0
entry_price = prices[i]
elif signals[i] < -threshold:
position = -1.0
entry_price = prices[i]
ret = (prices[i] - prices[i - 1]) / prices[i - 1]
equity[i] = equity[i - 1] * (1.0 + position * ret)
return equity
equity = simulate_strategy(prices, signals)
vectorbt 是一个流行的回测框架,可在70-100ms内处理100万笔订单。它基于 Pandas + NumPy + Numba 构建。问题在于:Pandas 是数据管道的瓶颈 — 慢、单线程、内存消耗大。vectorbt 不得不通过 Numba 绕过 Pandas 的限制来处理关键部分,但数据加载和指标计算仍然通过 Pandas 进行。
Polars + Numba 混合架构取两者之长:
如果您的管道是用 Pandas 编写的,迁移不需要从头重写。主要模式可以按模板转换。
df = pd.read_parquet("data.parquet")
df = pd.read_csv("data.csv", parse_dates=["timestamp"])
df = pl.read_parquet("data.parquet")
df = pl.read_csv("data.csv", try_parse_dates=True)
df = pl.scan_parquet("data.parquet") # 在 .collect() 之前不读取任何内容
df_filtered = df[df["volume"] > 1000]
df_filtered = df[(df["close"] > 100) & (df["exchange"] == "binance")]
df_filtered = df.filter(pl.col("volume") > 1000)
df_filtered = df.filter(
(pl.col("close") > 100) & (pl.col("exchange") == "binance")
)
df["returns"] = df["close"].pct_change()
df["log_returns"] = np.log(df["close"] / df["close"].shift(1))
df = df.with_columns([
pl.col("close").pct_change().alias("returns"),
(pl.col("close") / pl.col("close").shift(1)).log().alias("log_returns"),
])
result = df.groupby("ticker").agg(
avg_close=("close", "mean"),
total_volume=("volume", "sum"),
trade_count=("close", "count"),
)
result = df.group_by("ticker").agg([
pl.col("close").mean().alias("avg_close"),
pl.col("volume").sum().alias("total_volume"),
pl.col("close").count().alias("trade_count"),
])
df["ma_20"] = df.groupby("ticker")["close"].transform(
lambda x: x.rolling(20).mean()
)
df = df.with_columns(
pl.col("close")
.rolling_mean(window_size=20)
.over("ticker")
.alias("ma_20")
)
Polars 原生支持 Apache Arrow — 与 QuestDB 用于数据传输的格式相同。这意味着接收查询结果时零拷贝:
import pyarrow as pa
from questdb.ingress import Sender
arrow_table = questdb_connection.query_arrow(
"SELECT * FROM candles WHERE ticker = 'ETHUSDT'"
)
df = pl.from_arrow(arrow_table) # 零拷贝!
df_pd = arrow_table.to_pandas() # 拷贝 + 类型转换
有关使用 QuestDB 存储和分析交易数据的更多信息,请参阅我们的数据架构系列文章。
在文章聚合 Parquet 缓存中,我们描述了如何预计算时间框架和指标一次并保存到 Parquet 文件中。Polars 使这种方法更加高效:
cache = (
pl.scan_parquet("raw_candles_1m.parquet")
.with_columns([
pl.col("close")
.rolling_mean(window_size=60)
.alias("ma_1h"),
pl.col("close")
.rolling_mean(window_size=240)
.alias("ma_4h"),
pl.col("close")
.rolling_mean(window_size=20)
.alias("bb_mid"),
pl.col("close")
.rolling_std(window_size=20)
.alias("bb_std"),
])
.with_columns([
(pl.col("bb_mid") + 2.0 * pl.col("bb_std")).alias("bb_upper"),
(pl.col("bb_mid") - 2.0 * pl.col("bb_std")).alias("bb_lower"),
])
.collect()
)
cache.write_parquet(
"cache_ETHUSDT_2024_2026.parquet",
compression="zstd",
compression_level=3,
)
在大规模优化期间 — 当需要运行数千种参数组合时 — 通过 Polars scan_parquet 配合谓词下推从 Parquet 缓存读取,可以仅加载需要的时间段和列,而无需读取整个文件。
与自适应逐层细化的结合:Polars 惰性求值非常适合两级加载 — 主遍历使用粗粒度数据,仅在成交模糊区域使用详细数据(秒级、毫秒级)。
pandas-ta 或其他具有 Pandas API 的库 — 为一次性研究重写130个指标不切实际营销数字"快30倍"是特定操作上的峰值加速。典型管道操作的实际加速:2-10倍。按组滚动计算上 — 显著更多。在小数据集上 — 有时 Polars 由于开销甚至更慢。
在 marketmaker.cc,我们为回测引擎使用 Polars + Numba 混合架构。整个数据管道 — 从 Parquet 缓存加载、计算指标、过滤、特征工程 — 在 Polars 上运行。投资组合模拟在 Numba 上运行。
在数据管道中从 Pandas 切换到 Polars,在我们的典型数据集(5000万-1亿行,200+标的)上获得了6-8倍的加速。按组滚动指标计算从几分钟降到几百毫秒。这使我们在不更换硬件的情况下,将每小时优化迭代次数从约500次增加到约4000次。
关键点:我们没有在一天内迁移所有代码。首先迁移了 I/O(读取 Parquet),然后是指标计算,然后是过滤和特征工程。Pandas 仅保留在与期望 pd.DataFrame 的遗留组件的接口中。df.to_pandas() / pl.from_pandas() 转换只需几毫秒,不是瓶颈。
在回测阶段计算的指标 — 包括按活跃时间计算的 PnL — 已经在 Polars DataFrame 上计算,这简化了管道并消除了中间转换。
Polars 并非在每个场景中都能替代 Pandas。它是一个不同类别的工具,在严肃算法交易中典型的规模上才能充分发挥:数百万和数亿行、数十和数百个标的、持续的参数优化。
关键数字:
推荐的生产回测引擎架构:
没有中间 Pandas 层。数据从存储通过 Polars 流入 NumPy 数组,再进入 Numba 引擎 — 没有不必要的拷贝,没有 GIL,没有单线程瓶颈。
@article{soloviov2026polarsvspandas, author = {Soloviov, Eugen}, title = {Polars vs Pandas for Algotrading: Benchmarks on Real Data}, year = {2026}, url = {https://marketmaker.cc/ru/blog/post/polars-vs-pandas-algotrading}, description = {Polars 与 Pandas 在算法交易任务上的详细对比:过滤、聚合、滚动信号计算、I/O 和内存消耗的基准测试。Polars + Numba 混合架构实现最大回测性能。} }