트레이딩에서의 은닉 마르코프 모델: 시장 레짐에 맞춰 전략을 적응시키는 방법
모든 알고 트레이더에게는 존재론적 위기의 순간이 있다. 3개월을 들여 전략을 만들었다. 백테스트는 샤프 비율 2.4를 보여준다. 에퀴티 커브는 예술 작품이다. 봇을 가동한다. 첫 2주는 희열에 가득 차, 전략이 알파를 창출한다. 그러다 시장이 "전환"된다 -- 모멘텀 봇이 횡보장에서 체계적으로 자금을 소진하기 시작하며, 매번 고점에서 사고 저점에서 판다.
문제는 전략이 아니다. 문제는 시장이 하나의 시스템이 아니라 여러 시스템이며, 예고 없이 서로 전환된다는 것이다. 추세에 완벽한 모멘텀 전략은 횡보장에서 계좌를 파괴한다. 횡보장에서 돈을 찍어내는 그리드 전략은 방향성 움직임에서 폭발한다. 조용한 시장에서 안정적이던 평균회귀 전략은 블랙스완에서 마진콜을 받는다.
질문은 "어떤 전략이 더 나은가"가 아니라 "현재 시장 레짐은 무엇이고 어떤 전략이 그에 맞는가"이다. 바로 여기서 은닉 마르코프 모델(Hidden Markov Models, HMM)이 등장한다 -- 이 직관을 수학적으로 정형화할 수 있는 프레임워크다.
시장은 비정상(Non-Stationary)이며, 그것은 버그가 아니라 특성이다
불편한 진실부터 시작하자. 사실상 모든 기본 통계 모델은 데이터의 정상성을 가정한다. 평균과 분산이 시간에 따라 변하지 않고, 자기상관이 일정하며, 분포가 안정적이라는 것이다. 금융 시계열은 이 모든 가정을 동시에 위반한다.
지난 5년간 BTC의 일일 수익률을 살펴보자. 2024년 상승 랠리 기간의 평균 일일 수익률은 약 +0.3%, 표준편차 약 2.5%. 2022년 하락장에서는 평균 -0.15%, 표준편차 약 4%. 2023년 여름 횡보장에서는 평균 약 0%, 표준편차 약 1.5%. 이것은 서로 다른 분포를 가진 근본적으로 다른 세 가지 통계적 레짐이다.
형식적으로: 를 시점 에서의 수익률이라 하자. 정상 세계에서는 이고 매개변수는 일정하다. 현실에서는 매개변수 자체가 확률 과정이다: , 여기서 는 은닉 상태(시장 레짐)로 유한한 수의 값 사이에서 전환된다.
이 아이디어는 1989년 James Hamilton이 그의 기념비적 논문 "A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle"에서 정형화했다. 그는 경기 순환을 마르코프 메커니즘을 사용하여 두 은닉 상태 -- 경기 침체와 확장 -- 사이의 전환으로 모델링할 수 있음을 보여주었다. 이후 Hamilton 모델은 계량경제학에서 가장 많이 인용되는 도구 중 하나가 되었다.
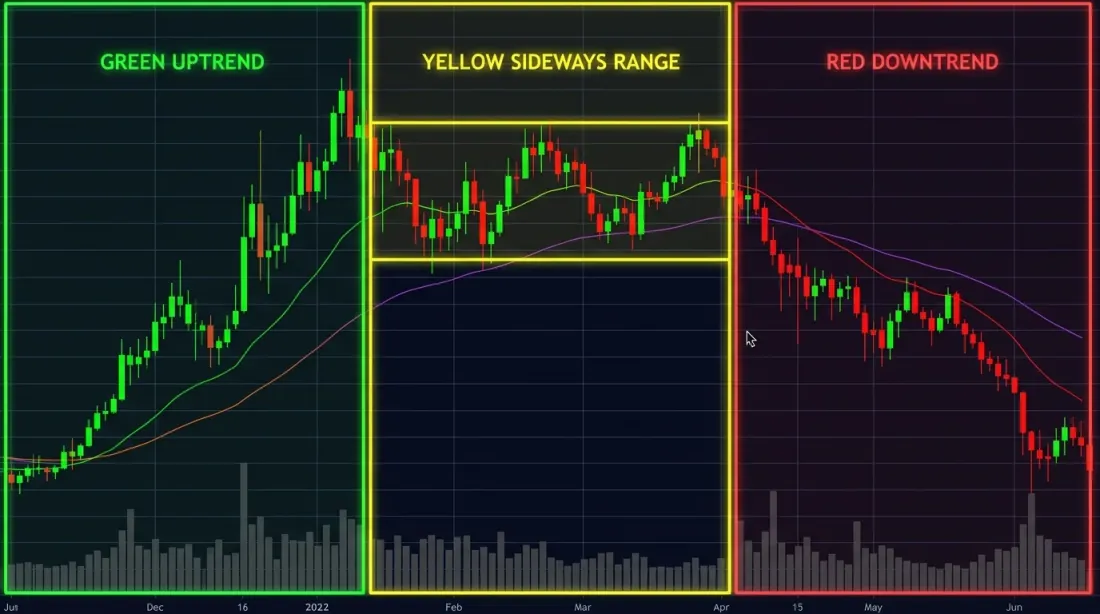 세 가지 시장 레짐 -- 상승(녹색), 하락(빨강), 횡보(노랑) -- 은 사후적으로 시각적으로 분명하지만, 실시간으로 전환을 감지하는 것은 훨씬 더 어렵다.
세 가지 시장 레짐 -- 상승(녹색), 하락(빨강), 횡보(노랑) -- 은 사후적으로 시각적으로 분명하지만, 실시간으로 전환을 감지하는 것은 훨씬 더 어렵다.
HMM: 비유를 통한 직관
수식에 들어가기 전에, 직관적 이해를 먼저 구축하자.
마르코프 체인: 기억 없는 과정
마르코프 체인은 미래가 현재에만 의존하고 과거에는 의존하지 않는 확률 과정이다. 내일의 날씨는 오늘의 날씨에 의존하지만, 일주일 전의 날씨에는 의존하지 않는다(강한 단순화이지만, 모델로서는 작동한다).
시장 레짐도 비슷하게 행동한다. 오늘 시장이 상승 레짐에 있다면, 내일도 그 상태를 유지할 확률이 높다(예: 95%). 하락으로 전환될 확률은 낮다(3%). 횡보로 전환될 확률은 더 낮다(2%). 이것이 전이 확률 행렬이다.
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
주목할 점: 대각선 요소가 높다 -- 레짐은 "점성"이 있다. 시장은 매일 상승과 하락 사이를 오가지 않는다. 전환되기 전에 몇 주에서 몇 달 동안 하나의 레짐에 머문다. 레짐의 기대 지속 기간은 이다. 인 상승 레짐의 경우 20일이다. 인 하락 레짐의 경우 약 14일이다.
은닉 상태: 우리는 그림자만 본다
핵심 단어는 "은닉"이다. 시장 레짐을 직접 관찰할 수 없다. 아무도 "주의, 하락 레짐으로 전환 중"이라는 표지판을 내걸지 않는다. 우리가 보는 것은 관측값 뿐이다 -- 수익률, 변동성, 거래량. 레짐은 관측값으로부터 추론해야 하는 잠재 변수다.
이것은 창문 없는 방에 있으면서, 밖에서 들어오는 사람들의 옷차림으로 날씨를 판단하려는 것과 같다. 우산? 아마 비. 반바지와 선글라스? 맑음. 하지만 반바지를 입은 한 사람이 있다고 해서 확실히 맑다는 뜻은 아니다 -- 그 사람이 단순히 낙관주의자일 수도 있다. 관측값을 축적하고 확률적으로 은닉 상태를 추정해야 한다.
HMM에서 각 은닉 레짐은 자체 분포에서 관측값을 "방출"(emit)한다:
- 상승 레짐 → 에서의 수익률, , 은 중간 수준
- 하락 레짐 → 에서의 수익률, , 는 높음
- 횡보 → 에서의 수익률, , 는 낮음
특징적인 패턴에 주목: 하락 레짐은 보통 음의 평균뿐만 아니라 높은 변동성도 갖는다. 시장은 하락할 때 엘리베이터를 타고, 상승할 때 계단을 오른다 -- HMM은 이를 자동으로 포착한다.
 은닉 마르코프 모델 아키텍처: 은닉 상태(레짐)는 마르코프 체인에 따라 전환되며, 각 상태는 자체 가우시안 분포에서 관측 가능한 수익률을 생성한다.
은닉 마르코프 모델 아키텍처: 은닉 상태(레짐)는 마르코프 체인에 따라 전환되며, 각 상태는 자체 가우시안 분포에서 관측 가능한 수익률을 생성한다.
HMM의 세 가지 알고리즘: 전방, 비터비, 바움-웰치
HMM의 모든 작업은 세 가지 기본 문제로 귀결되며, 각각 고유한 알고리즘이 있다.
문제 1: 이 관측값들의 확률은? (전방 알고리즘)
질문: 수익률 시퀀스가 주어졌을 때, 주어진 모델 매개변수 하에서 정확히 이 시퀀스를 관측할 확률은 얼마인가?
용도: 모델 비교(AIC/BIC), 적합성 검증.
작동 원리: 전방 알고리즘(Forward Algorithm)은 동적 프로그래밍이다. 각 단계 에서 "전방 변수" -- 시퀀스 를 관측하고 시점 에서 상태 에 있을 확률 -- 를 계산한다.
재귀:
여기서 는 상태 에서 로의 전이 확률이고, 는 상태 에서 관측 의 확률이다. 쉽게 말하면: 상태 에 도달할 수 있는 모든 경로를 합산하고 관측 확률을 곱한다.
계산 복잡도: 순진한 대신 . 은 상태 수, 는 시퀀스 길이. 3개 레짐과 1000개 관측값의 경우, 대신 9000번의 연산이다. 차이는, 가볍게 말해도, 상당하다.
문제 2: 가장 가능성 높은 레짐 시퀀스는? (비터비 알고리즘)
질문: 수익률 시퀀스가 주어졌을 때, 이를 가장 높은 확률로 생성한 은닉 상태(레짐)의 시퀀스는 무엇인가?
용도: 바로 트레이딩에 필요한 것 -- 각 시점에서 레짐을 식별하는 것.
작동 원리: 비터비 알고리즘은 전방 알고리즘과 동일하지만, 모든 경로를 합산하는 대신 최대값을 취한다. 모든 가능한 경로의 확률이 아니라 가장 확률이 높은 경로를 찾는다.
상태 시퀀스 자체를 복원하기 위한 역방향 패스(백트래킹)가 추가된다. 결과는 디코딩된 레짐 시퀀스: "상승-상승-상승-하락-하락-횡보-..."
실제 트레이딩에서는 비터비(전역 최적)보다 필터링 -- 각 시점에서의 사후 상태 확률 -- 이 더 자주 사용된다. 이를 통해 전체 시퀀스를 기다리지 않고 온라인으로 작업할 수 있으며, "70% 상승, 25% 횡보, 5% 하락"과 같은 "소프트" 추정을 얻을 수 있다.
문제 3: 모델을 어떻게 학습시키는가? (바움-웰치 알고리즘)
질문: 관측값만 주어졌을 때, 데이터 우도를 최대화하는 모델 매개변수(, , )는 무엇인가?
용도: 과거 데이터로 모델 학습.
작동 원리: 바움-웰치 알고리즘은 EM 알고리즘(기대값 최대화)의 특수한 경우이다:
- E 단계: 현재 매개변수를 사용하여 기대 은닉 상태를 계산(전방-후방 알고리즘으로)
- M 단계: 이 기대 상태 하에서 우도를 최대화하여 매개변수 업데이트
- 수렴할 때까지 반복
중요한 세부 사항: EM은 지역 최대값으로의 수렴만 보장한다. 서로 다른 초기 조건은 서로 다른 결과를 낼 수 있다. 실제로는 다른 초기화로 모델을 여러 번 학습시키고 로그 우도로 최선의 결과를 선택한다. hmmlearn에서는 n_init 매개변수로 자동 수행된다.
암호화폐 시장 레짐: 무엇을 찾고 있는가
암호화폐의 경우, 시장 단계가 뚜렷하기 때문에 고전적인 3레짐 분류가 특히 잘 작동한다.
레짐 1: 상승장(Bull)
- 평균 수익률: 일일 +0.15% ... +0.5%
- 변동성(표준편차): 일일 2-3%
- 특성: 적절한 조정을 동반한 지속적 상승
- 지속 기간: 연속 2-6개월
- 거래량: 증가, 특히 현물 시장에서
- 온체인: MVRV > 1.5, 활성 주소 증가
레짐 2: 하락장(Bear)
- 평균 수익률: 일일 -0.1% ... -0.4%
- 변동성(표준편차): 일일 3-6%
- 특성: 급격한 폭락, 청산 연쇄, 데드캣 바운스
- 지속 기간: 1-4개월(일반적으로 상승장보다 짧음)
- 거래량: 패닉 매도 시 급증, 이후 감소
- 온체인: MVRV < 1, 거래소 유입 증가
레짐 3: 횡보(Sideways / 축적기)
- 평균 수익률: 일일 약 0%
- 변동성(표준편차): 일일 1-2%
- 특성: 범위 내 움직임, 가짜 돌파
- 지속 기간: 1-3개월
- 거래량: 낮음, 감소 추세
- 온체인: 안정적 지표, 활동 감소
왜 2개나 5개가 아니라 정확히 3개의 레짐인가? 2개는 너무 거칠다 -- 횡보에 대한 정보를 잃게 된다(마켓메이킹 봇에게는 가장 수익성 높은 레짐). 5개 이상은 모델이 과적합되고, 전이 확률이 불안정해지며, 해석이 어려워진다. 3개가 최적의 균형이며, 정보 기준(AIC/BIC)과 경제적 직관 모두에 의해 확인된다.
다만 상태 수는 하이퍼파라미터이므로 테스트해야 한다. Guidolin과 Timmermann(2007)은 논문 "Asset Allocation under Multivariate Regime Switching"에서 주식과 채권 혼합 포트폴리오에 대해 4개의 레짐을 발견했다: 붕괴, 완만한 성장, 상승, 회복.
피처 엔지니어링: 모델에 무엇을 입력하는가
가장 간단한 옵션은 일일 수익률만 입력하는 것이다. 작동하지만 개선의 여지가 있다. 실전에서 검증된 피처 세트는 다음과 같다:
가격 피처
- 일일 로그 수익률:
- 롤링 변동성: , 윈도우 (예: 20일)
- 롤링 평균 수익률:
거래량 피처
- 정규화 거래량:
- 거래량-가격 상관관계: 롤링 윈도우에서 거래량과 절대 수익률의 상관관계
온체인 피처(암호화폐용)
- MVRV 비율: 시가총액 대 실현 시가총액. MVRV > 2 — 시장 과열, < 1 — 저평가
- NVT 비율: 네트워크 가치 대 거래량. 블록체인의 PER
- 거래소 순유입: 거래소로의 순유입. 양수 — 매도 압력, 음수 — 축적
- 활성 주소 수: 활성 주소 수(증가 = 관심, 감소 = 무관심)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
중요: 모든 피처는 정상(또는 최소한 근사적으로 정상)이어야 한다. 로그 수익률은 정상이다. 가격은 아니다. 거래량은 정규화하는 것이 좋다. 변동성은 그대로 둘 수 있다 -- 준정상이다.
또 하나의 세부 사항: 다변량 HMM(피처 벡터를 입력)은 단변량보다 잘 작동하지만, 학습에 더 많은 데이터가 필요하다. 5년 이상의 이력이 있는 암호화폐의 경우 보통 문제가 되지 않는다. 3개월 이력밖에 없는 신규 알트코인의 경우 -- 1-2개 피처로 제한하는 것이 낫다.
hmmlearn을 사용한 Python 단계별 구현
코드로 들어가자. hmmlearn 라이브러리는 Python에서 HMM의 사실상 표준이다. 간단한 API, scikit-learn 호환, 즉시 사용 가능.
1단계: 데이터 로딩
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
2단계: 피처 준비 및 HMM 학습
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
3단계: 레짐 디코딩
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
4단계: 레짐 해석
여기서부터가 가장 흥미롭고 -- 가장 까다로운 부분이다. HMM은 레짐 0이 "상승"이라는 것을 모른다. 단지 관측 공간에서 세 개의 클러스터를 찾을 뿐이다. 번호 매김은 임의적이며 실행마다 바뀔 수 있다.
각 레짐의 통계를 확인하고 수동으로 라벨을 부여해야 한다:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
BTC의 전형적인 출력은 대략 다음과 같다:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
주목: 하락 레짐은 음의 수익률뿐만 아니라 가장 높은 변동성(4.1% vs 횡보의 1.6%)도 갖는다. 이것은 "레버리지 효과"로 알려진 고전적 경험적 관찰이다 -- 하락 시장은 상승 시장보다 변동성이 크다.
전이 행렬과 레짐 지속 기간
전이 확률 행렬은 HMM의 가장 정보량이 풍부한 산출물 중 하나다:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
전형적인 결과:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
관찰 결과:
- 레짐은 점성이 있다: 현재 레짐에 머무를 확률이 모든 상태에서 93% 초과
- 상승 레짐이 하락보다 오래 지속된다(20.8일 vs 15.9일) -- 역시 시장은 하락보다 상승이 느리다
- 상승에서 하락으로의 직접 전이 확률이 낮다(1.8%) -- 보통 시장은 횡보를 거쳐간다
마지막 포인트는 경제적으로 직관적이다: 시장이 즉시 반전하는 경우는 드물다. 보통 하락장 전에 분배 단계(꼭대기에서의 횡보)가 있고, 상승장 전에 축적 단계(바닥에서의 횡보)가 있다.
트레이딩 전략: 하나의 레짐에 하나의 전략
배운 것을 적용하자. 핵심 아이디어: 항상 하나의 전략만 거래하지 말고, 감지된 레짐에 따라 전략 간 전환한다.
상승장 → 공격적 모멘텀
- 포지션 규모 확대(자본의 최대 100%)
- 추세 전략: 돌파, 이동평균선 추종
- 넓은 스톱로스(조정에서 청산되지 않도록)
- 숏 하지 않기(또는 최소한으로)
하락장 → 방어적 / 숏 포지션
- 포지션 규모 축소(자본의 30-50%)
- 숏 전략 또는 전액 현금
- 타이트한 스톱로스
- 풋옵션 또는 선물로 헤지
횡보 → 평균회귀 / 그리드
- 중간 포지션 규모(자본의 50-70%)
- 그리드 트레이딩 전략
- 평균회귀: 하단에서 매수, 상단에서 매도
- 좁은 스프레드로 마켓메이킹
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
백테스트: HMM 적응형 전략 vs 매수 후 보유
이제 핵심 질문: 이것이 단순한 매수 후 보유(Buy-and-Hold)보다 더 나은가?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
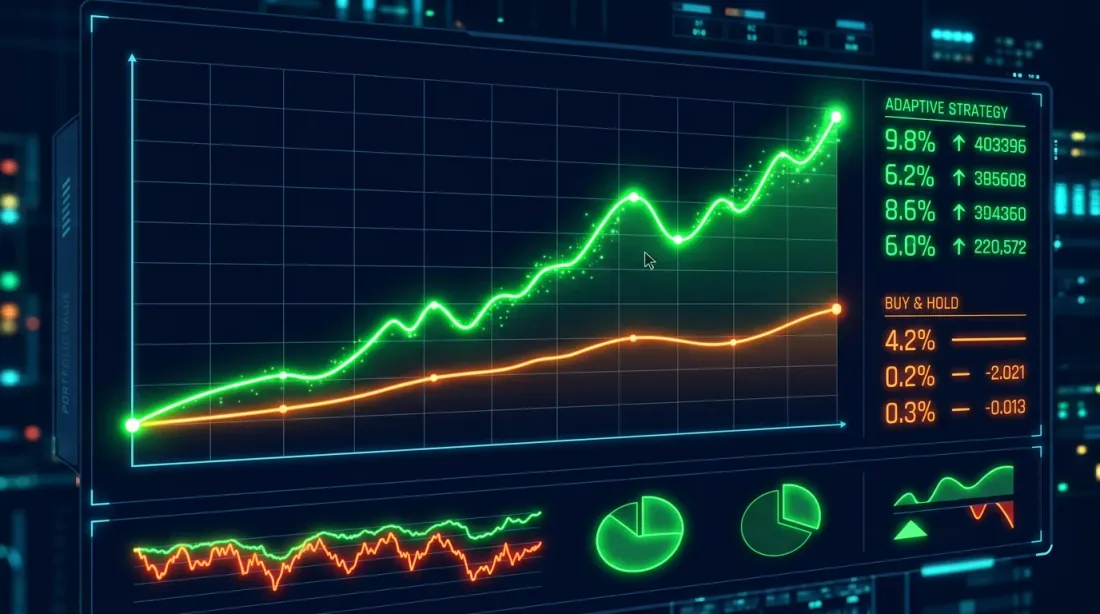 에퀴티 커브 비교: 매수 후 보유(파랑)와 HMM 적응형 전략(주황). 적응형 전략은 하락 구간에서 낙폭을 크게 줄인다.
에퀴티 커브 비교: 매수 후 보유(파랑)와 HMM 적응형 전략(주황). 적응형 전략은 하락 구간에서 낙폭을 크게 줄인다.
BTC의 전형적인 결과(2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
핵심 관찰: HMM 적응형 전략이 반드시 더 높은 총수익을 가져오는 것은 아니지만(이 사례에서는 실제로 그렇지만), 최대 낙폭을 극적으로 줄인다 -- 76%에서 38%로. 샤프 비율은 1.12에서 1.68로 상승했다. 이것은 단순히 "더 많은 돈"이 아니라 위험 조정 수익의 개선이다.
왜 그런가? 하락 레짐에서 전략이 방어적 또는 숏 모드로 전환되어 주요 폭락을 회피하기 때문이다. 대가는 추세 진입 지연(모델이 수일의 지연으로 상승 레짐을 감지)과 과도기 동안의 잘못된 전환이다.
결과 시각화
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
고급 기법
기본 HMM은 좋은 출발점이지만, 한계와는 거리가 멀다.
계층적 HMM(Hierarchical HMM)
계층적 HMM에서 상위 레벨은 "매크로 레짐"(글로벌 추세, 연간 사이클)을, 하위 레벨은 "마이크로 레짐"(주간/월간 변동)을 결정한다. R의 fHMM 패키지는 Oelschlager, Adam, Michels가 2024년 Journal of Statistical Software에 발표한 것으로, 금융 시계열을 위해 바로 이 아이디어를 구현한다.
예시: 매크로 레짐 "강세 사이클"은 내부에 마이크로 레짐 "랠리", "조정", "컨솔리데이션"을 포함한다. 이를 통해 강세장에서 10% 조정이 있을 때마다 패닉할 필요가 없어진다 -- 모델이 강세 사이클 내의 조정은 정상적이라는 것을 이해한다.
확장 피처를 가진 다변량 HMM
단변량 수익률 대신 피처 벡터(수익률 + 변동성 + 거래량 + 온체인 데이터)를 입력한다. 이를 통해 모델이 시장 상태에 대한 더 많은 정보를 "볼" 수 있다.
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + ML 앙상블
현대적 접근법: HMM을 트레이딩 시스템이 아닌 후속 모델을 위한 피처 생성기로 사용한다. Gupta 등(2025)의 논문 "A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading"에서 설명된 아이디어:
- HMM이 현재 레짐(또는 레짐 확률)을 결정
- 레짐이 Random Forest / Gradient Boosting에 추가 피처로 입력됨
- ML 모델이 레짐을 고려하여 구체적인 트레이딩 결정을 내림
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
프로덕션: 함정들
아름다운 백테스트는 절반에 불과하다. 프로덕션에서는 여러 불쾌한 서프라이즈가 기다리고 있다.
래그 문제(미래 참조 편향)
HMM은 현재와 과거 데이터를 기반으로 레짐을 결정하지만, 백테스트에서는 미래 데이터를 포함한 전체 데이터셋으로 모델을 학습시키고 싶은 유혹이 있다. 이것이 미래 참조 편향(Look-Ahead Bias)이며, 백테스트를 허구로 만든다.
해결책: 워크-포워드(Walk-Forward) 방식. 시점 까지의 데이터로 모델을 학습시키고, 시점 의 레짐을 예측한 뒤 윈도우를 이동한다. Walk-Forward 최적화 글에서 설명한 대로.
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
재학습 주기
모델을 얼마나 자주 재학습시켜야 하는가? 너무 드물면 -- 모델이 구식이 되고, 시장이 변한다. 너무 자주면 -- 모델이 불안정해지고, 레짐이 "점프"한다.
경험적 권장사항:
- 일간 데이터의 경우: 1-4주마다 재학습(21 거래일이 좋은 기본값)
- 학습 윈도우: 6-12개월(252 거래일 -- 1년)
- 모니터링: 새로운 데이터에서 로그 우도가 임계값 이하로 떨어지면 -- 비정기 재학습
라벨 불안정성
재학습할 때마다 상태 번호가 바뀔 수 있다: "레짐 0"(상승)이었던 것이 "레짐 2"가 될 수 있다. 통계(평균 수익률, 변동성)를 기반으로 상태를 자동으로 매칭해야 한다.
온라인 업데이트
실시간 트레이딩에서 매일 완전한 재학습은 과도하다. 포워드 필터링을 사용할 수 있다: 모델 매개변수를 고정하되, 새로운 관측값마다 사후 상태 확률을 업데이트한다. 이것은 순간적인 연산이다.
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
상태 수 선택
3개 레짐이 좋은 기본값이지만, 대안도 테스트해야 한다:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
한계와 주의사항
문제를 숨기는 것은 정직하지 않다.
가우시안 가정. 기본 GaussianHMM은 각 레짐의 수익률이 정규분포를 따른다고 가정한다. 실제 분포는 두꺼운 꼬리와 비대칭성을 가진다. 부분적 해결책은 Student-t 분포 또는 GMMHMM(상태별 가우시안 혼합)을 사용하는 것이다.
상태 수는 당신의 선택이다. BIC가 도움이 되지만 항상 결정적이지는 않다. 두 명의 연구자가 서로 다른 레짐 수에 도달할 수 있고, 둘 다 "옳을" 수 있다.
과도기. 레짐 전환 시 모델은 불확실해진다. 확률이 대략 균등하게 분포되고, 전략은 "흐릿한" 신호를 받는다. 해결책은 임계값 규칙: 새 레짐의 확률이 70-80%를 초과할 때만 전략을 전환한다.
과적합. 다른 모델과 마찬가지로 HMM도 과적합될 수 있다. 특히 상태 수나 피처 수가 많을 때. 워크-포워드 검증은 필수다.
암호화폐 특수성. 암호화폐 시장은 젊고 구조적으로 불안정하다. 2017년의 "강세장"과 2024년의 "강세장"은 통계적으로 다른 현상이다. 모델이 사이클을 넘어 일반화하지 못할 수 있다.
더 읽을거리
더 깊이 알고 싶은 분들을 위해:
기초적 논문:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — 마르코프 전환 모델의 기초적 저작
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — 자산 배분에의 실전 적용
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — 금리의 레짐 전환
현대 연구:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — 레짐 탐지의 앙상블 접근법
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — 금융을 위한 계층적 HMM
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — 베이지안 접근법의 비트코인 HMM
실전 가이드:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
결론
은닉 마르코프 모델은 은탄환이 아니라 도구다. 유용하고, 수학적으로 근거가 있으며, 통계학에서 반세기, 금융에서 30년의 역사를 가진 도구.
트레이딩에서 HMM의 핵심 가치는 "시장을 예측"하는 것이 아니라(아무도 할 수 없다), 경험 많은 트레이더의 직관을 정형화하는 것이다: 시장은 서로 다른 단계를 거치며, 전략은 적응해야 한다. 주관적인 "지금 시장이 하락세인 것 같다" 대신 "하락 레짐 확률 82%, 하락 사이클의 평균 지속 기간 16일, 현재 5일째"를 얻게 된다.
HMM을 당신의 트레이딩 스택에 통합해야 할까? 서로 다른 시장 상황에 맞는 복수의 전략이 있고, 수동 전환에 지쳤다면 -- 확실히 그렇다. 하나의 전략만 거래하고 확장 계획이 없다면 -- 일단 보류하되, 기억해 두자.
그리고 기억하자: 최고의 모델은 프로덕션에서 작동하는 모델이지, 백테스트에서 이기는 모델이 아니다.
인용: 이 글의 자료를 연구나 프로젝트에 사용하신다면, 인용해 주세요:
트레이딩에서의 은닉 마르코프 모델: 시장 레짐에 맞춰 전략을 적응시키는 방법. marketmaker.cc, 2026. URL: https://marketmaker.cc/ko/blog/post/regime-detection-hmm-adaptive-trading
MarketMaker.cc Team
퀀트 리서치 및 전략