トレーディングにおける隠れマルコフモデル:市場レジームに応じて戦略を適応させる方法
すべてのアルゴトレーダーに存在論的危機の瞬間が訪れる。3ヶ月かけて戦略を構築した。バックテストではシャープレシオ2.4。エクイティカーブはまさに芸術品。ボットを起動する。最初の2週間は高揚感に包まれ、戦略はアルファを生み出し続ける。そして市場が「切り替わる」――あなたのモメンタムボットはレンジ相場で計画的に資金を失い始め、ローカルの高値で買い、ローカルの安値で売り続ける。
問題は戦略にあるのではない。問題は、市場が一つのシステムではなく複数のシステムであり、それらが予告なしに切り替わるということだ。トレンドに最適なモメンタム戦略は、レンジ相場では口座を壊滅させる。レンジ相場で安定的に利益を出すグリッド戦略は、方向性のある動きで爆発する。穏やかな市場で安定していた平均回帰戦略は、ブラックスワンでマージンコールを受ける。
問題は「どの戦略が優れているか」ではなく、「現在の市場レジームは何であり、どの戦略がそれに対応しているか」である。そしてここでまさに隠れマルコフモデル(Hidden Markov Models、HMM)が登場する――この直感を形式化するための数学的フレームワークだ。
市場は非定常であり、それはバグではなく特徴である
不快な真実から始めよう。事実上すべての基本的な統計モデルはデータの定常性を仮定している。平均と分散は時間とともに変化せず、自己相関は一定で、分布は安定している。金融時系列はこれらすべての仮定を同時に破る。
過去5年間のBTCの日次リターンを見てみよう。2024年の強気ラリー中の平均日次リターンは約+0.3%、標準偏差は約2.5%。2022年の弱気市場では――平均-0.15%、標準偏差約4%。2023年夏のレンジ相場では――平均約0%、標準偏差約1.5%。これらは分布が異なる3つの本質的に異なる統計的レジームだ。
形式的に言えば: を時点 のリターンとする。定常世界では でパラメータは一定。現実では、パラメータ自体が確率過程である:、ここで は隠れ状態(市場レジーム)であり、有限個の値の間で切り替わる。
この考え方は1989年にJames Hamiltonが画期的な論文「A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle」で形式化した。彼はビジネスサイクルを2つの隠れ状態――景気後退と拡大――の間の切り替えとしてマルコフメカニズムを用いてモデル化できることを示した。以来、Hamiltonモデルは計量経済学で最も引用されるツールの一つとなった。
 3つの市場レジーム――強気(緑)、弱気(赤)、レンジ(黄)――は事後的には視覚的に明らかだが、リアルタイムでの切り替え検出ははるかに困難である。
3つの市場レジーム――強気(緑)、弱気(赤)、レンジ(黄)――は事後的には視覚的に明らかだが、リアルタイムでの切り替え検出ははるかに困難である。
HMM:アナロジーによる直感
数式に入る前に、直感的な理解を構築しよう。
マルコフ連鎖:記憶のないプロセス
マルコフ連鎖は、未来が現在のみに依存し、過去には依存しない確率過程である。明日の天気は今日の天気に依存するが、1週間前の天気には依存しない(大幅な簡略化だが、モデルとしては機能する)。
市場レジームも同様に振る舞う。今日市場が強気レジームにある場合、明日もそこに留まる確率は高い(例えば95%)。弱気に移行する確率は低い(3%)。レンジに移行する確率はさらに低い(2%)。これが遷移確率行列だ。
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
注目すべきは対角要素が高いことだ――レジームは「粘着性」がある。市場は毎日強気から弱気へ飛び移ったりしない。切り替わる前に数週間から数ヶ月同じレジームに留まる。レジームの期待持続期間は 。 の強気レジームでは20日。 の弱気レジームでは約14日。
隠れ状態:見えるのは影だけ
キーワードは「隠れた」。市場レジームを直接観察することはできない。「注意、弱気レジームに移行中」という看板を掲げる人はいない。我々が見るのは観測値のみ――リターン、ボラティリティ、出来高。レジームは観測値から推測すべき潜在変数だ。
これは窓のない部屋にいて、外から入ってくる人の服装から天気を判断しようとするようなものだ。傘を持っている?おそらく雨。短パンとサングラス?晴れ。しかし短パンの人が一人いるだけでは確実に晴れとは言えない――単なる楽観主義者かもしれない。観測を蓄積し、確率的に隠れ状態を推定する必要がある。
HMMでは、各隠れレジームが自身の分布から観測値を「発射」(emit)する:
- 強気レジーム → からのリターン、、 は中程度
- 弱気レジーム → からのリターン、、 は高い
- レンジ → からのリターン、、 は低い
特徴的なパターンに注目:弱気レジームは通常、単に負の平均を持つだけでなく、高いボラティリティも持つ。市場は下落時にはエレベーターで、上昇時には階段で動く――HMMはこれを自動的に捉える。
 隠れマルコフモデルのアーキテクチャ:隠れ状態(レジーム)はマルコフ連鎖に従って切り替わり、各状態が自身のガウス分布から観測可能なリターンを生成する。
隠れマルコフモデルのアーキテクチャ:隠れ状態(レジーム)はマルコフ連鎖に従って切り替わり、各状態が自身のガウス分布から観測可能なリターンを生成する。
HMMの3つのアルゴリズム:前向き、ビタビ、バウム・ウェルチ
HMMのすべての作業は3つの基本問題に帰着し、それぞれに対応するアルゴリズムがある。
問題1:これらの観測値の確率は?(前向きアルゴリズム)
問い: リターンの系列が与えられたとき、モデルパラメータの下でこの系列を正確に観測する確率はいくらか?
目的: モデル比較(AIC/BIC)、妥当性検証。
仕組み: 前向きアルゴリズム(Forward Algorithm)は動的計画法である。各ステップ で「前向き変数」――系列 を観測し、時点 で状態 にいる確率――を計算する。
再帰:
ここで は状態 から への遷移確率、 は状態 での観測 の確率。言葉で言えば:状態 に到達できるすべての経路を合計し、観測確率を掛ける。
計算量:素朴な に対して 。 は状態数、 は系列長。3つのレジームと1000個の観測値では、 ではなく9000回の演算。その差は、控えめに言っても大きい。
問題2:最も可能性の高いレジーム系列は?(ビタビアルゴリズム)
問い: リターンの系列が与えられたとき、それを最も可能性高く生成した隠れ状態(レジーム)の系列は何か?
目的: まさにトレーディングに必要なもの――各時点でのレジームを特定すること。
仕組み: ビタビアルゴリズムは前向きアルゴリズムと同じだが、すべての経路を合計する代わりに最大値を取る。すべての可能な経路の確率ではなく、最も確率の高い経路を求める。
さらに状態系列自体を復元するための逆方向パス(バックトラッキング)がある。結果はデコードされたレジーム系列:「強気-強気-強気-弱気-弱気-レンジ-...」。
実際のトレーディングでは、ビタビ(全体最適)よりもフィルタリング――各時点での事後状態確率 ――の方がよく使われる。これにより全系列を待たずにオンラインで作業でき、「70%強気、25%レンジ、5%弱気」のような「ソフト」な推定値を得られる。
問題3:モデルをどう学習させるか?(バウム・ウェルチアルゴリズム)
問い: 観測値のみが与えられたとき、データの尤度を最大化するモデルパラメータ(、、)は何か?
目的: 過去のデータでモデルを学習させること。
仕組み: バウム・ウェルチアルゴリズムはEMアルゴリズム(期待値最大化)の特殊ケース:
- Eステップ: 現在のパラメータを使い、期待される隠れ状態を計算(前向き・後ろ向きアルゴリズムで)
- Mステップ: これらの期待される状態の下で尤度を最大化してパラメータを更新
- 収束するまで繰り返す
重要な注意点:EMは局所最大値への収束のみを保証する。異なる初期条件は異なる結果をもたらす可能性がある。実際には、異なる初期化でモデルを複数回学習させ、対数尤度で最良の結果を選択する。hmmlearnでは n_init パラメータで自動的に行われる。
暗号通貨市場のレジーム:何を探しているのか
暗号通貨では、市場フェーズが明確なため、古典的な3レジーム分割が特に効果的に機能する。
レジーム1:ブル(強気)
- 平均リターン: 1日あたり+0.15%〜+0.5%
- ボラティリティ(標準偏差): 1日あたり2-3%
- 特性: 適度な押し目を伴う持続的な上昇
- 持続期間: 連続2-6ヶ月
- 出来高: 増加、特に現物市場で
- オンチェーン: MVRV > 1.5、アクティブアドレス増加
レジーム2:ベア(弱気)
- 平均リターン: 1日あたり-0.1%〜-0.4%
- ボラティリティ(標準偏差): 1日あたり3-6%
- 特性: 急落、清算の連鎖、デッドキャットバウンス
- 持続期間: 1-4ヶ月(通常、強気より短い)
- 出来高: パニック売りで急増、その後減衰
- オンチェーン: MVRV < 1、取引所流入量増加
レジーム3:レンジ(横ばい / 蓄積期)
- 平均リターン: 1日あたり約0%
- ボラティリティ(標準偏差): 1日あたり1-2%
- 特性: レンジ内の動き、ダマシのブレイクアウト
- 持続期間: 1-3ヶ月
- 出来高: 低い、減少傾向
- オンチェーン: 安定した指標、活動の減少
なぜ2つや5つではなく、ちょうど3つのレジームなのか?2つでは粗すぎる――レンジ相場の情報が失われる(マーケットメイキングボットにとっては最も収益性の高いレジーム)。5つ以上では――モデルが過学習し、遷移確率が不安定になり、解釈が困難になる。3つは最適なバランスであり、情報量基準(AIC/BIC)と経済的直感の両方で確認されている。
とはいえ、状態数はハイパーパラメータであり、テストすべきだ。GuidolinとTimmermann(2007)は論文「Asset Allocation under Multivariate Regime Switching」で、株式と債券の混合ポートフォリオに対して4つのレジーム(暴落、緩やかな成長、強気、回復)を発見した。
特徴量エンジニアリング:モデルに何を入力するか
最もシンプルなオプションは日次リターンのみを入力すること。これは機能するが、改善の余地がある。実践で効果が実証された特徴量セットは以下の通り:
価格特徴量
- 日次対数リターン:
- ローリングボラティリティ: 、ウィンドウ (例:20日)
- ローリング平均リターン:
出来高特徴量
- 正規化出来高:
- 出来高-価格相関: ローリングウィンドウでの出来高と絶対リターンの相関
オンチェーン特徴量(暗号通貨向け)
- MVRVレシオ: 時価総額と実現時価総額の比率。MVRV > 2 → 市場過熱、< 1 → 過小評価
- NVTレシオ: ネットワーク価値とトランザクション量の比率。ブロックチェーンのPER
- 取引所ネットフロー: 取引所への純流入。正 → 売り圧力、負 → 蓄積
- アクティブアドレス数: アクティブアドレスの数(増加 = 関心、減少 = 無関心)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
重要: すべての特徴量は定常(または少なくとも近似的に定常)でなければならない。対数リターンは定常。価格はそうではない。出来高は正規化するのが良い。ボラティリティはそのままで問題ない――準定常だ。
もう一つのポイント:多変量HMM(特徴量ベクトルを入力)は単変量より良く機能するが、学習により多くのデータを必要とする。5年以上の歴史がある暗号通貨では通常問題にならない。3ヶ月の歴史しかない新しいアルトコインでは、1つか2つの特徴量に限定する方が良い。
hmmlearnを使ったPythonによるステップバイステップの実装
コードに移ろう。hmmlearn ライブラリはPythonにおけるHMMのデファクトスタンダードだ。シンプルなAPI、scikit-learnとの互換性、すぐに使える。
ステップ1:データの読み込み
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
ステップ2:特徴量の準備とHMMの学習
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
ステップ3:レジームのデコード
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
ステップ4:レジームの解釈
ここからが最も興味深く、そして最もトリッキーな部分だ。HMMはレジーム0が「強気」であることを知らない。観測空間で3つのクラスターを見つけるだけだ。番号付けは任意であり、実行ごとに変わる可能性がある。
各レジームの統計を確認し、手動でラベルを付与する必要がある:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
BTCの典型的な出力は大体こうなる:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
注目:弱気レジームは負のリターンを持つだけでなく、最も高いボラティリティ(4.1% vs レンジの1.6%)も持つ。これは「レバレッジ効果」として知られる古典的な経験的観察――下落市場は上昇市場よりもボラティリティが高い。
遷移行列とレジーム持続期間
遷移確率行列はHMMの最も情報量の多い成果物の一つだ:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
典型的な結果:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
何がわかるか:
- レジームは粘着性がある: 現在のレジームに留まる確率はすべての状態で93%超
- 強気レジームは弱気より長く続く(20.8日 vs 15.9日)――やはり市場は下落より上昇が遅い
- 強気から弱気への直接遷移は起こりにくい(1.8%)――通常、市場はレンジ相場を経由する
最後の点は経済的に直感的だ。市場が即座に反転することはめったにない。通常、弱気市場の前には分配フェーズ(天井でのレンジ)があり、強気市場の前には蓄積フェーズ(底でのレンジ)がある。
トレーディング戦略:1つのレジームに1つの戦略
学んだことを応用しよう。アイデア:常に1つの戦略を取引するのではなく、検出されたレジームに応じて戦略を切り替える。
ブル → アグレッシブ・モメンタム
- ポジションサイズ拡大(資本の最大100%)
- トレンド戦略:ブレイクアウト、移動平均線フォロー
- ワイドなストップロス(押し目で振り落とされない)
- ショートしない(またはミニマルに)
ベア → ディフェンシブ / ショートポジション
- ポジションサイズ縮小(資本の30-50%)
- ショート戦略またはフルキャッシュ
- タイトなストップロス
- プットオプションまたは先物でヘッジ
レンジ → 平均回帰 / グリッド
- 中程度のポジションサイズ(資本の50-70%)
- グリッド・トレーディング戦略
- 平均回帰:下限で買い、上限で売り
- タイトスプレッドでのマーケットメイキング
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
バックテスト:HMM適応型戦略 vs バイ・アンド・ホールド
核心的な問いに答えよう:これは単純なバイ・アンド・ホールドより良いのか?
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
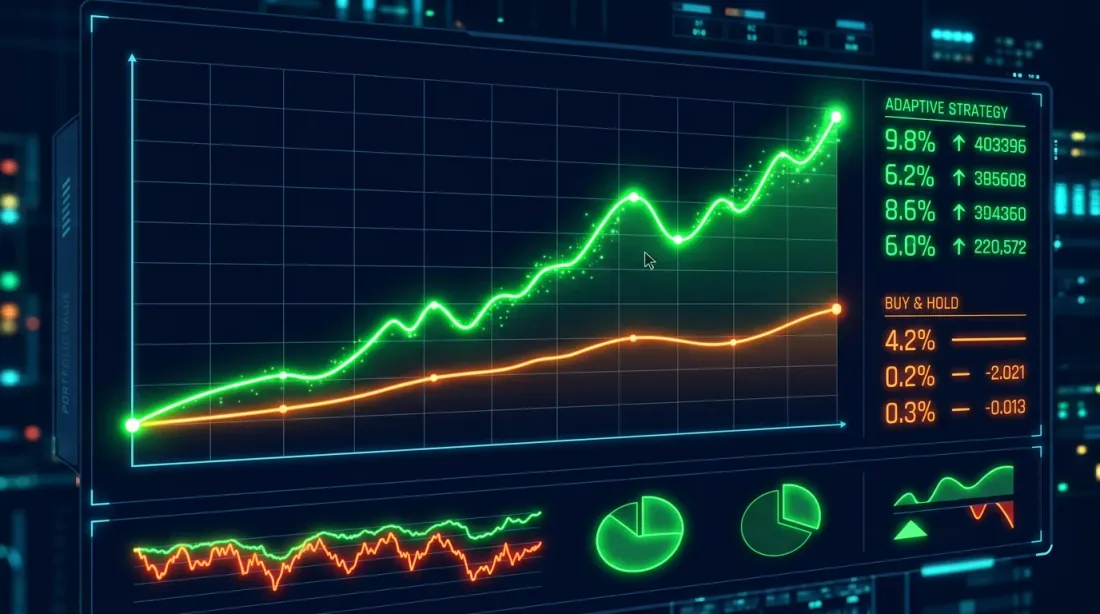 エクイティカーブの比較:バイ・アンド・ホールド(青)とHMM適応型戦略(オレンジ)。適応型戦略は弱気フェーズでのドローダウンを大幅に削減する。
エクイティカーブの比較:バイ・アンド・ホールド(青)とHMM適応型戦略(オレンジ)。適応型戦略は弱気フェーズでのドローダウンを大幅に削減する。
BTCの典型的な結果(2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
重要な観察:HMM適応型戦略は必ずしもより高い総リターンをもたらすわけではない(このケースでは実際にそうだが)、しかし最大ドローダウンを劇的に削減する――76%から38%へ。シャープレシオは1.12から1.68に上昇した。これは単に「より多くのお金」ではなく、リスク調整後リターンの改善だ。
なぜか?弱気レジームでは戦略がディフェンシブまたはショートモードに切り替わり、主要な暴落を回避するからだ。その代償は、トレンドへの参入遅延(モデルは数日のラグで強気レジームを検出する)と移行期間中の誤った切り替えだ。
結果の可視化
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
上級テクニック
基本的なHMMは良い出発点だが、限界からは程遠い。
階層的HMM(Hierarchical HMM)
階層的HMMでは、上位レベルが「マクロレジーム」(グローバルトレンド、年次サイクル)を決定し、下位レベルが「ミクロレジーム」(週内/月内の変動)を決定する。RのfHMMパッケージは、Oelschlager、Adam、Michelsにより2024年にJournal of Statistical Softwareで発表され、金融時系列向けにまさにこのアイデアを実装している。
例:マクロレジーム「強気サイクル」は内部にミクロレジーム「ラリー」「調整」「整理」を含む。これにより強気市場での10%の押し目ごとにパニックする必要がなくなる――モデルは強気サイクル内の調整が正常であることを理解する。
拡張特徴量を持つ多変量HMM
単変量リターンの代わりに、特徴量ベクトル(リターン + ボラティリティ + 出来高 + オンチェーンデータ)を入力する。これによりモデルは市場状態についてより多くの情報を「見る」ことができる。
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + MLアンサンブル
現代的なアプローチ:HMMをトレーディングシステムとしてではなく、下流モデルへの特徴量生成器として使用する。Guptaら(2025)の論文「A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading」で記述されたアイデア:
- HMMが現在のレジーム(またはレジーム確率)を決定
- レジームが追加特徴量としてRandom Forest / Gradient Boostingに入力される
- MLモデルがレジームを考慮して具体的なトレーディング決定を行う
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
本番環境:落とし穴
美しいバックテストは半分に過ぎない。本番環境ではいくつかの不快なサプライズが待っている。
ラグの問題(先読みバイアス)
HMMは現在と過去のデータに基づいてレジームを判定するが、バックテストでは将来のデータを含むデータセット全体でモデルを学習させたくなる誘惑がある。これは先読みバイアスであり、バックテストをフィクションに変えてしまう。
解決策: ウォークフォワード方式。時点 までのデータでモデルを学習させ、時点 のレジームを予測し、ウィンドウをシフトする。Walk-Forward最適化の記事で説明したとおり。
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
再学習スケジュール
モデルをどの程度の頻度で再学習させるか?頻度が低すぎると――モデルが古くなり、市場が変化する。頻度が高すぎると――モデルが不安定になり、レジームが「ジャンプ」する。
経験的な推奨:
- 日次データの場合: 1-4週間ごとに再学習(21営業日が良いデフォルト)
- 学習ウィンドウ: 6-12ヶ月(252営業日――1年)
- モニタリング: 新しいデータでの対数尤度が閾値を下回った場合――予定外の再学習
ラベルの不安定性
再学習のたびに状態の番号付けが変わる可能性がある:「レジーム0」(強気)だったものが「レジーム2」になることも。統計(平均リターン、ボラティリティ)に基づいて状態を自動的にマッチングする必要がある。
オンライン更新
リアルタイムトレーディングでは、毎日の完全な再学習は過剰だ。フォワードフィルタリングを使用できる:モデルパラメータは固定し、新しい観測値ごとに事後状態確率を更新する。これは瞬時の操作だ。
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
状態数の選択
3つのレジームは良いデフォルトだが、代替案もテストすべきだ:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
限界と注意事項
問題を隠すのは不誠実だ。
ガウス分布の仮定。 基本的なGaussianHMMは各レジームのリターンが正規分布に従うと仮定する。実際の分布はファットテールと非対称性を持つ。部分的な解決策はStudent-t分布またはGMMHMM(状態ごとのガウス混合)の使用だ。
状態数はあなたの選択。 BICは役立つが、常に決定的ではない。2人の研究者が異なるレジーム数に到達し、両方が「正しい」こともある。
過渡期。 レジーム切り替え時にモデルは不確実になる。確率がほぼ均等に分布し、戦略は「ぼやけた」シグナルを受け取る。解決策は閾値ルール:新しいレジームの確率が70-80%を超えた場合のみ戦略を切り替える。
過学習。 他のモデルと同様に、HMMも過学習する可能性がある。特に状態数や特徴量が多い場合。ウォークフォワード検証は必須。
暗号通貨固有の問題。 暗号通貨市場は若く、構造的に不安定だ。2017年の「強気市場」と2024年の「強気市場」は統計的に異なる現象だ。モデルはサイクルを跨いで一般化しない可能性がある。
さらに読む
より深く学びたい方へ:
基礎的な論文:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — マルコフ切り替えモデルの基礎的論文
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — 資産配分への実践的応用
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — 金利におけるレジーム
現代の研究:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — レジーム検出へのアンサンブルアプローチ
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — 金融向け階層的HMM
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — ベイズアプローチによるビットコインのHMM
実践ガイド:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
結論
隠れマルコフモデルは銀の弾丸ではなく、ツールだ。有用で、数学的に根拠があり、統計学で半世紀、金融で30年の歴史を持つ。
トレーディングにおけるHMMの主な価値は「市場を予測する」ことではなく(誰にもできない)、経験豊富なトレーダーの直感を形式化することだ:市場は異なるフェーズを経て、戦略は適応しなければならない。主観的な「今市場は弱気だと感じる」の代わりに「弱気レジームの確率は82%、弱気サイクルの平均持続期間は16日、現在5日目」を得られる。
HMMをあなたのトレーディングスタックに統合すべきか?異なる市場条件に対応する複数の戦略があり、手動での切り替えに疲れているなら――間違いなくYesだ。単一の戦略を取引し、拡張の予定がないなら――今は保留にして、頭の片隅に置いておこう。
そして覚えておこう:最良のモデルは本番環境で機能するモデルであり、バックテストで勝つモデルではない。
引用: この記事の資料を研究やプロジェクトで使用する場合は、以下を引用してください:
トレーディングにおける隠れマルコフモデル:市場レジームに応じて戦略を適応させる方法。 marketmaker.cc、2026。URL: https://marketmaker.cc/ja/blog/post/regime-detection-hmm-adaptive-trading
MarketMaker.cc Team
クオンツ・リサーチ&戦略