Drill-Down Adaptif: Backtest dengan Granularitas Bervariasi dari Menit hingga Trade Mentah
Candle menit adalah granularitas standar untuk backtest. Namun di dalam satu candle menit, harga bisa bergerak berbeda-beda: kadang sebesar 0,01%, di lain waktu sebesar 2%. Ketika stop-loss dan take-profit sama-sama jatuh dalam rentang [low, high] dari satu candle menit, backtest tidak tahu mana yang terpicu lebih dulu. Inilah masalah ambiguitas eksekusi (fill ambiguity).
Solusi naif adalah beralih ke data tingkat detik untuk seluruh backtest. Namun selama dua tahun, itu berarti ~63 juta bar detik alih-alih ~1 juta bar menit. Penyimpanan meningkat 60x, kecepatan turun secara proporsional.
Drill-down adaptif menyelesaikan masalah ini: gunakan granularitas halus hanya di tempat yang benar-benar membutuhkannya.
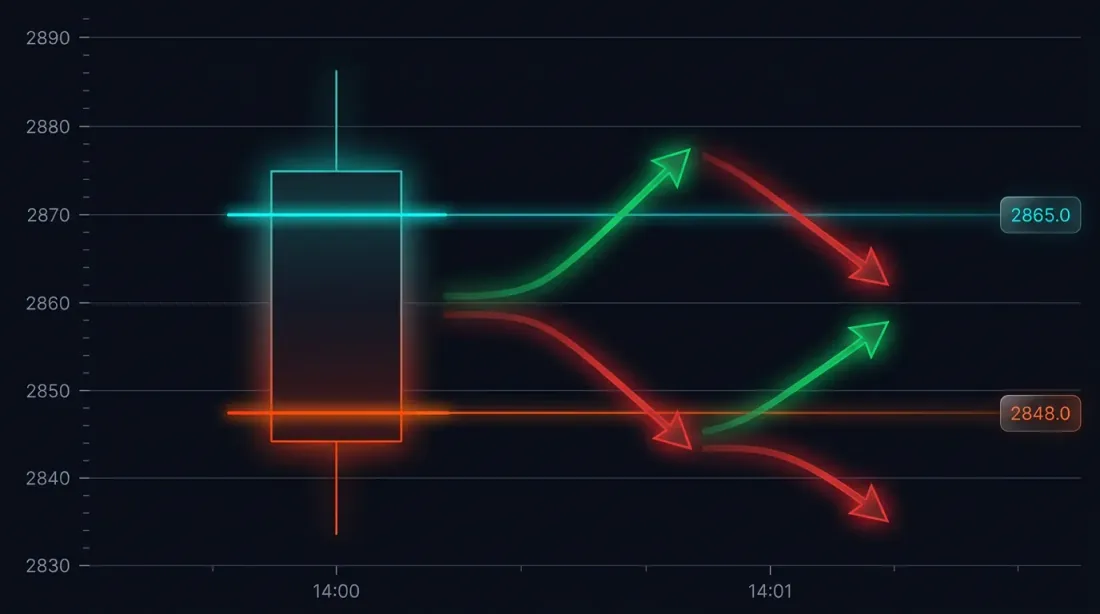
Masalah: Ambiguitas Eksekusi pada Candle Besar
Perhatikan situasi spesifik. Strategi membuka posisi long pada 3000 USDT. Stop-loss: 2970 (-1%). Take-profit: 3060 (+2%).
Candle menit pada 14:37:
- Open: 3010
- High: 3065
- Low: 2965
- Close: 3050
Baik SL (2970) maupun TP (3060) jatuh dalam rentang [2965, 3065]. Mana yang terpicu lebih dulu?
Kemungkinan hasil:
- Harga turun lebih dulu -> SL terpicu -> rugi -1%
- Harga naik lebih dulu -> TP terpicu -> untung +2%
Selisih dalam satu trade: 3 poin persentase. Dengan leverage 10x — 30%. Untuk backtest dengan ratusan trade, penyelesaian ambiguitas eksekusi yang keliru secara sistematis mendistorsi hasil.
Bagaimana Framework Menanganinya Secara Default
Sebagian besar mesin backtest menggunakan salah satu dari dua heuristik:
- Optimistis: TP terpicu lebih dulu -> hasil membengkak (overstated)
- Pesimistis: SL terpicu lebih dulu -> hasil menyusut (understated)
Kedua pendekatan ini hanya tebakan. Data nyata tersedia pada tingkat detik atau bahkan milidetik, dan tidak ada alasan untuk menebak ketika Anda bisa melihat.
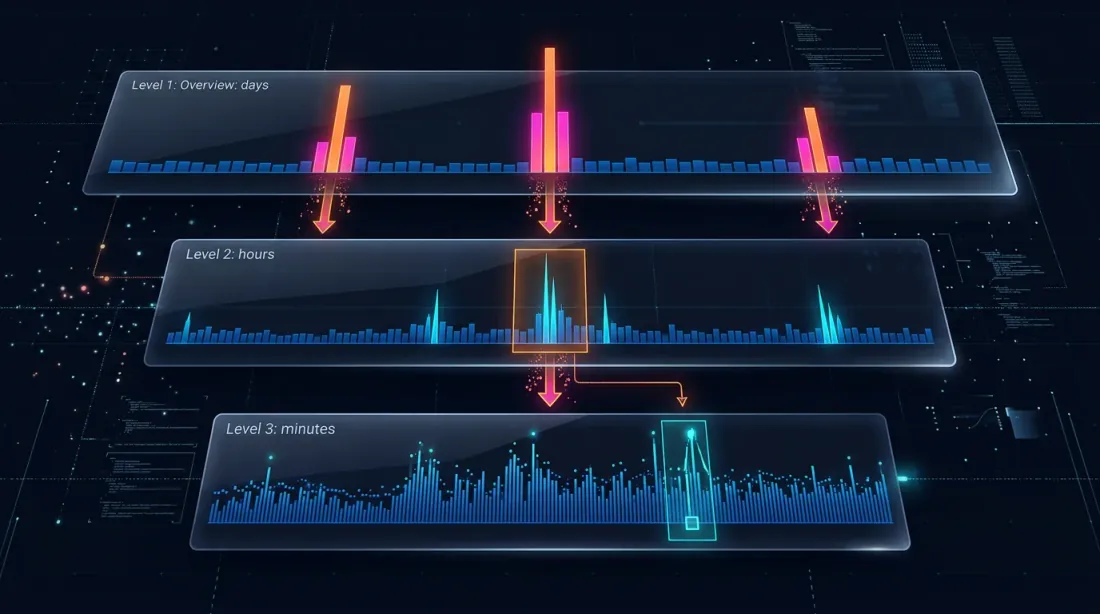
Drill-Down: Strategi Empat Tingkat

Ide drill-down: mulai pada tingkat menit dan "menggali turun" ke tingkat yang lebih rendah hanya ketika ada ambiguitas — entah karena pergerakan harga maupun lonjakan volume.
Level 1: 1m (candle menit)
-> Jika SL atau TP jelas berada di luar rentang [low, high] — selesaikan di tempat
-> Jika keduanya berada dalam rentang — drill down
Level 2: 1s (candle detik)
-> Muat 60 bar detik untuk menit ini
-> Telusuri detik demi detik: mana yang terpicu lebih dulu?
-> Jika bar detik ambigu, ATAU price_move >= min_pct, ATAU volume >= median_1s * vol_mult — drill down
Level 3: 100ms (candle milidetik)
-> Muat hingga 10 bar 100ms untuk detik ini
-> Telusuri 100ms demi 100ms
-> Jika bar 100ms ambigu, ATAU price_move >= min_pct, ATAU volume >= median_100ms * vol_mult — drill down
Level 4: Trade mentah
-> Muat trade individual untuk bucket 100ms ini
-> Selesaikan eksekusi pada tingkat trade-demi-trade — presisi maksimum yang mungkin
Kapan Drill-Down Tidak Diperlukan
Dalam 95% kasus, drill-down tidak diperlukan. Skenario tipikal:
SL tidak ambigu: high candle tidak mencapai TP, low menembus SL -> SL terpicu, tidak perlu drill-down.
TP tidak ambigu: low tidak mencapai SL, high menembus TP -> TP terpicu, tidak perlu drill-down.
Tidak ada yang terpicu: kedua level berada di luar rentang -> posisi tetap terbuka.
Deteksi gap: open candle berikutnya melompati SL atau TP -> eksekusi pada harga open, tanpa drill-down.
Drill-down hanya diperlukan untuk ~5% bar — ketika kedua level jatuh dalam rentang satu candle.
class AdaptiveFillSimulator:
"""
Four-level drill-down for determining fill order.
"""
def __init__(self, data_loader):
self.loader = data_loader
self.cache_1s = {} # Cache of second data by month
def check_fill(self, timestamp, candle_1m, sl_price, tp_price, side):
"""
Checks whether SL or TP triggered on the given minute candle.
Returns: ('sl', fill_price) | ('tp', fill_price) | None
"""
low, high = candle_1m['low'], candle_1m['high']
open_price = candle_1m['open']
if side == 'long':
if open_price <= sl_price:
return ('sl', open_price)
if open_price >= tp_price:
return ('tp', open_price)
else:
if open_price >= sl_price:
return ('sl', open_price)
if open_price <= tp_price:
return ('tp', open_price)
sl_hit = self._level_hit(sl_price, low, high, side, 'sl')
tp_hit = self._level_hit(tp_price, low, high, side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if not sl_hit and not tp_hit:
return None
return self._drill_down_1s(timestamp, sl_price, tp_price, side)
def _drill_down_1s(self, minute_ts, sl_price, tp_price, side):
"""Level 2: second-by-second pass."""
bars_1s = self.loader.load_1s_for_minute(minute_ts)
if bars_1s is None or len(bars_1s) == 0:
return self._pessimistic_fill(side, sl_price, tp_price)
for bar in bars_1s:
sl_hit = self._level_hit(sl_price, bar['low'], bar['high'], side, 'sl')
tp_hit = self._level_hit(tp_price, bar['low'], bar['high'], side, 'tp')
if sl_hit and not tp_hit:
return ('sl', sl_price)
if tp_hit and not sl_hit:
return ('tp', tp_price)
if sl_hit and tp_hit:
result = self._drill_down_100ms(bar['timestamp'], sl_price, tp_price, side)
if result:
return result
return self._pessimistic_fill(side, sl_price, tp_price)
def _pessimistic_fill(self, side, sl_price, tp_price):
"""Pessimistic assumption: SL for longs, TP for shorts."""
if side == 'long':
return ('sl', sl_price)
else:
return ('sl', sl_price)
Performa
| Mode | Waktu per pemeriksaan eksekusi | Kapan digunakan |
|---|---|---|
| 1m (tanpa drill-down) | ~0ms | ~95% kasus |
| Drill-down 1s | ~5ms (akses pertama ke bulan) | ~5% kasus |
| Drill-down 100ms | ~1ms | <0,5% kasus |
| Drill-down trade mentah | ~0,5ms | <0,1% kasus |
Selama backtest 2 tahun dengan ~400 trade, drill-down dipanggil untuk sekitar 20 candle. Total overhead — kurang dari 1 detik untuk seluruh backtest.
Penyimpanan Data Adaptif
Drill-down membutuhkan data detik dan milidetik. Namun menyimpan semuanya pada granularitas maksimum tidak praktis:
| Granularitas | Bar selama 2 tahun | Ukuran Parquet |
|---|---|---|
| 1m | ~1,05 jt | ~15 MB |
| 1s | ~63 jt | ~550 MB/bulan |
| 100ms | ~630 jt | ~5 GB/bulan |
Arsip 1s lengkap selama 2 tahun sekitar 13 GB. 100ms — lebih dari 100 GB. Menyimpan semuanya memang mungkin tetapi boros, mengingat drill-down hanya menggunakan kurang dari 1% data ini.
Deteksi Detik Panas (Hot-Second)
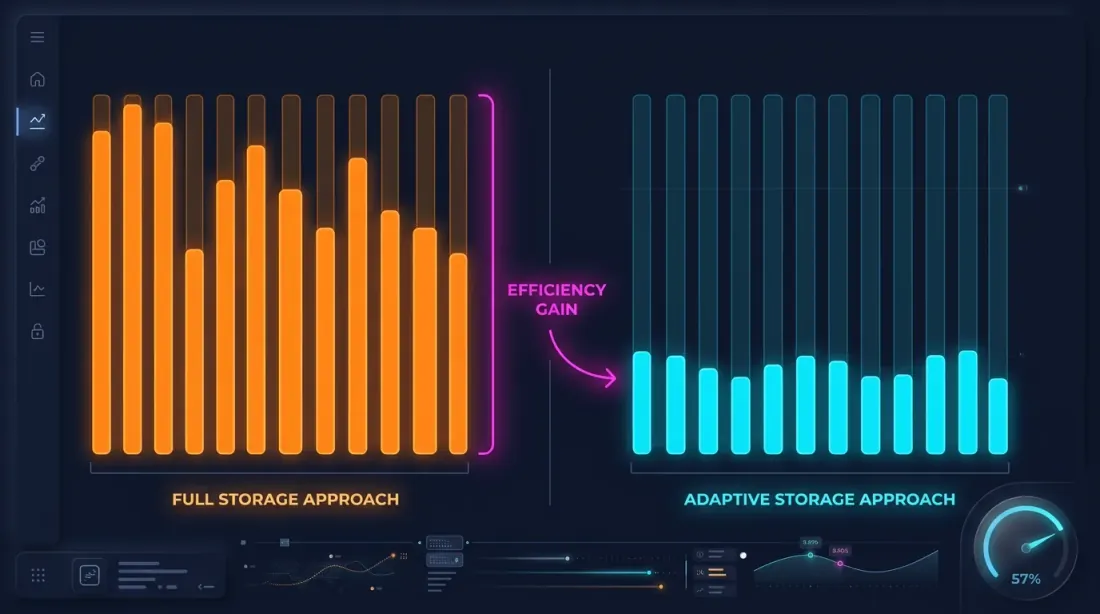
Pengamatan kunci: detik di mana harga bergerak signifikan hanyalah sebagian kecil. Jika harga berubah kurang dari 0,1% dalam satu detik — tidak ada gunanya menyimpan rincian 100ms untuk detik tersebut.
Deteksi detik panas: saat mengunduh dan memproses data, kita menganalisis setiap detik dan menghasilkan candle 100ms hanya untuk detik "panas" — yaitu detik di mana pergerakan harga melampaui ambang batas.
def process_trades_adaptive(
trades: pd.DataFrame,
min_price_change_pct: float = 1.0,
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Processes raw trades into an adaptive structure:
- 1s candles for all seconds
- 100ms candles only for "hot" seconds
Args:
trades: DataFrame with columns [timestamp, price, quantity]
min_price_change_pct: threshold for drill-down to 100ms
Returns:
(df_1s, df_100ms_hot) — second candles and 100ms for hot seconds
"""
trades['second'] = trades['timestamp'].dt.floor('1s')
df_1s = trades.groupby('second').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
df_1s['price_change_pct'] = (df_1s['high'] - df_1s['low']) / df_1s['open'] * 100
hot_seconds = df_1s[df_1s['price_change_pct'] >= min_price_change_pct].index
hot_trades = trades[trades['second'].isin(hot_seconds)]
hot_trades['bucket_100ms'] = hot_trades['timestamp'].dt.floor('100ms')
df_100ms = hot_trades.groupby('bucket_100ms').agg(
open=('price', 'first'),
high=('price', 'max'),
low=('price', 'min'),
close=('price', 'last'),
volume=('quantity', 'sum'),
)
return df_1s, df_100ms
Penghematan Penyimpanan
Sebagai contoh — ETHUSDT selama satu bulan tipikal:
| Pendekatan | Ukuran | Granularitas |
|---|---|---|
| 1m saja | ~1 MB | 1 menit |
| Semua 1s | ~550 MB | 1 detik |
| Semua 100ms | ~5 GB | 100 ms |
| Adaptif | ~600 MB | 1s + 100ms hanya untuk detik panas |
Dengan ambang batas min_price_change_pct = 1.0%, detik panas mencakup kurang dari 1% dari seluruh detik. Data 100ms untuk detik tersebut menambah ~50 MB pada 550 MB data detik — overhead yang dapat diabaikan.
Jika data detik juga disimpan secara adaptif (hanya ketika pergerakan dalam satu menit melampaui 0,1%), volumenya dapat dikurangi 3-5x lagi.
Struktur Penyimpanan Parquet
data/{SYMBOL}/
├── source.json # Exchange source: {"exchange": "binance"} or {"exchange": "bybit"}
├── stats.json # Precomputed median volumes: {"median_volume_1s": ..., "median_volume_100ms": ...}
├── klines_1m/
│ ├── 2024-01.parquet # ~1 MB
│ ├── 2024-02.parquet
│ └── ...
├── klines_1s/
│ ├── 2024-01.parquet # ~550 MB
│ └── ...
├── klines_100ms_hot/
│ ├── 2024-01.parquet # ~50 MB (hot seconds only)
│ └── ...
├── trades_hot/
│ ├── 2024-01.parquet # Raw trades for hot 100ms buckets
│ └── ...
└── states_1m.parquet # Precomputed rolling state cache (~112 MB)
Setiap file mencakup satu bulan data. Data detik, milidetik, dan trade dimuat secara lazy — hanya ketika drill-down memintanya. File stats.json berisi volume median terkomputasi sebelumnya yang digunakan untuk pemicu drill-down berbasis volume.
Optimasi Parquet untuk Data Keuangan
Data keuangan memiliki karakteristik spesifik: timestamp tumbuh secara monoton, harga berubah dengan mulus, volume bervariasi secara signifikan. Pengaturan optimal:
import pyarrow as pa
import pyarrow.parquet as pq
schema = pa.schema([
pa.field("timestamp", pa.int32()), # Seconds from epoch — int32 is sufficient
pa.field("open", pa.float32()),
pa.field("high", pa.float32()),
pa.field("low", pa.float32()),
pa.field("close", pa.float32()),
pa.field("volume", pa.float32()),
])
column_encodings = {
"timestamp": "DELTA_BINARY_PACKED", # Monotonic int -> delta compression
"open": "BYTE_STREAM_SPLIT", # Float -> byte-stream split
"high": "BYTE_STREAM_SPLIT",
"low": "BYTE_STREAM_SPLIT",
"close": "BYTE_STREAM_SPLIT",
"volume": "BYTE_STREAM_SPLIT",
}
def save_optimized_parquet(df, path):
table = pa.Table.from_pandas(df, schema=schema)
pq.write_table(
table, path,
compression="zstd",
compression_level=9,
use_dictionary=False,
write_statistics=False,
column_encoding=column_encodings,
)
Mengapa pengaturan ini:
- DELTA_BINARY_PACKED untuk timestamp: timestamp berurutan berbeda dengan nilai tetap (60 untuk 1m, 1 untuk 1s). Pengkodean delta memampatkannya hampir menjadi nol.
- BYTE_STREAM_SPLIT untuk float: memecah byte float32 menjadi beberapa aliran (semua byte pertama bersama, semua byte kedua bersama, dan seterusnya). Untuk harga yang berubah mulus, ini mencapai kompresi 2-3x lebih baik dibanding pengkodean standar.
- ZSTD level 9: kompresi bagus dengan kecepatan dekompresi yang dapat diterima.
- float32 alih-alih float64: cukup untuk harga dan volume, menghemat 50% memori.
Pemuatan Lazy dengan Caching
Drill-down meminta data detik untuk menit tertentu. Memuat file parquet untuk setiap permintaan itu lambat. Solusinya — pemuatan lazy dengan cache LRU per bulan.
from functools import lru_cache
import pyarrow.parquet as pq
import pandas as pd
class AdaptiveDataLoader:
"""
Lazy loader with cache: loads second data by month,
keeps the last N months in memory.
"""
def __init__(self, symbol: str, data_dir: str = "data", cache_months: int = 2):
self.symbol = symbol
self.data_dir = data_dir
self.cache_months = cache_months
self._cache_1s: dict[str, pd.DataFrame] = {}
def load_1s_for_minute(self, minute_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 1s data for a specific minute."""
month_key = minute_ts.strftime("%Y-%m")
if month_key not in self._cache_1s:
self._load_month_1s(month_key)
if month_key not in self._cache_1s:
return None
df = self._cache_1s[month_key]
minute_start = minute_ts.floor('1min')
minute_end = minute_start + pd.Timedelta(minutes=1)
return df[(df.index >= minute_start) & (df.index < minute_end)]
def load_100ms_for_second(self, second_ts: pd.Timestamp) -> pd.DataFrame | None:
"""Load 100ms data for a hot second."""
month_key = second_ts.strftime("%Y-%m")
path = f"{self.data_dir}/{self.symbol}/klines_100ms_hot/{month_key}.parquet"
try:
df = pd.read_parquet(path)
second_start = second_ts.floor('1s')
second_end = second_start + pd.Timedelta(seconds=1)
return df[(df.index >= second_start) & (df.index < second_end)]
except FileNotFoundError:
return None
def _load_month_1s(self, month_key: str):
"""Load a month of 1s data, evict old data from cache."""
path = f"{self.data_dir}/{self.symbol}/klines_1s/{month_key}.parquet"
try:
df = pd.read_parquet(path)
df.index = pd.to_datetime(df['timestamp'], unit='s')
if len(self._cache_1s) >= self.cache_months:
oldest = min(self._cache_1s.keys())
del self._cache_1s[oldest]
self._cache_1s[month_key] = df
except FileNotFoundError:
pass
Menerapkan Drill-Down ke Backtesting
Integrasi ke dalam loop backtest:
def backtest_with_adaptive_fill(
states: pd.DataFrame,
strategy_params: dict,
data_loader: AdaptiveDataLoader,
) -> list:
"""
Backtest with adaptive drill-down for fill simulation.
"""
fill_sim = AdaptiveFillSimulator(data_loader)
trades = []
position = None
for i in range(len(states)):
row = states.iloc[i]
ts = states.index[i]
candle_1m = {
'open': row['open'], 'high': row['high'],
'low': row['low'], 'close': row['close'],
'timestamp': ts,
}
if position is not None:
fill = fill_sim.check_fill(
ts, candle_1m,
position['sl'], position['tp'],
position['side'],
)
if fill is not None:
fill_type, fill_price = fill
trades.append({
'entry_time': position['entry_time'],
'exit_time': ts,
'side': position['side'],
'entry_price': position['entry_price'],
'exit_price': fill_price,
'exit_type': fill_type,
'drill_down': fill_sim.last_drill_depth, # 0, 1, or 2
})
position = None
continue
signal = check_entry_signal(row, strategy_params)
if signal and position is None:
position = {
'side': signal['side'],
'entry_price': row['close'],
'entry_time': ts,
'sl': signal['sl'],
'tp': signal['tp'],
}
return trades
Hubungan dengan Rolling State Cache
Drill-down melengkapi cache parquet teragregasi — keduanya menyelesaikan masalah yang berbeda:
| Rolling state cache | Drill-down adaptif | |
|---|---|---|
| Tujuan | Nilai indikator HTF yang benar | Urutan eksekusi SL/TP yang presisi |
| Beroperasi pada | Setiap candle 1m | Hanya saat ambiguitas eksekusi (~5%) |
| Data | Terkomputasi sebelumnya, disimpan permanen | Dimuat lazy, cache bulan-bulan terbaru |
| Memengaruhi | Sinyal masuk/keluar | Harga dan waktu eksekusi |
Kedua pendekatan menghilangkan kesalahan yang tak terlihat pada tingkat candle harian tetapi krusial untuk backtest yang realistis.
Ringkasan: Perbandingan Pendekatan Simulasi Eksekusi
| Pendekatan | Akurasi | Kecepatan | Penyimpanan |
|---|---|---|---|
| Heuristik OHLC (optimis/pesimis) | Rendah | Instan | 1m saja |
| Backtest 1s penuh | Tinggi | Lambat (x60) | ~550 MB/bulan |
| Backtest 100ms penuh | Sangat tinggi | Sangat lambat (x600) | ~5 GB/bulan |
| Backtest trade mentah penuh | Maksimum | Sangat lambat sekali | ~50 GB/bulan |
| Drill-down adaptif (4 tingkat) | Maksimum | ~Instan | 1m + 1s + 100ms panas + trade panas |
Drill-down memberikan akurasi backtest 1s penuh pada kecepatan backtest 1m. Pengamatan kunci: granularitas tinggi tidak dibutuhkan di mana-mana — hanya pada titik keputusan.
Drill-Down Berbasis Volume
Drill-down asli hanya terpicu pada pergerakan harga — ketika rentang [low, high] sebuah candle cukup lebar untuk menciptakan ambiguitas eksekusi. Namun harga bukan satu-satunya sinyal bahwa sesuatu yang menarik terjadi dalam satu bar.
Lonjakan volume adalah pemicu yang sama pentingnya. Sebuah detik di mana volumenya 500x median biasanya berkaitan dengan order pasar besar, kaskade likuidasi, atau flash crash. Bahkan jika badan candle tampak kecil, jalur harga aktual dalam detik tersebut mungkin liar — menyentuh titik ekstrem yang disembunyikan oleh representasi OHLC.
Kondisi drill-down kini bersifat berbasis OR: entah pergerakan harga signifikan ATAU lonjakan volume anomali memicu penurunan ke granularitas lebih halus.
def is_hot(bar, median_volume, min_pct=0.1, vol_mult=500):
"""
Determines if a bar warrants drill-down to the next level.
Two independent triggers (OR logic):
- price moved >= min_pct within the bar
- volume exceeded median * vol_mult
"""
price_move = (bar['high'] - bar['low']) / bar['open'] * 100
return price_move >= min_pct or bar['volume'] >= median_volume * vol_mult
Ini menangkap skenario yang tak terlihat oleh deteksi berbasis harga saja: sebuah bar dengan open=3000, close=3001 tetapi volume 50.000x normal mungkin sempat menyentuh 2950 dan 3050 dalam hitungan milidetik. Tanpa drill-down berbasis volume, backtest tidak akan pernah memeriksa detik ini lebih dekat.
Trade Mentah: Tingkat Keempat
Hierarki tiga tingkat asli (1m -> 1s -> 100ms) masih menyisakan celah: dalam satu bucket 100ms, beberapa trade bisa dieksekusi pada harga berbeda. Untuk bucket dengan high=3060 dan low=2965, kita masih tidak tahu urutan persisnya.
Solusinya: drill down ke trade mentah sebagai tingkat keempat dan terakhir.
1m candles (base)
└─> 1s candles (when 1s shows price_move >= min_pct OR volume >= median_1s * vol_mult)
└─> 100ms candles (when hot second detected)
└─> Raw trades (when 100ms shows price_move >= min_pct OR volume >= median_100ms * vol_mult)
Pada tingkat trade mentah, tidak ada ambiguitas — setiap trade memiliki harga dan timestamp yang tepat. Eksekusi diselesaikan secara definitif:
def resolve_from_trades(trades, sl_price, tp_price, side):
"""
Walk through individual trades in chronological order.
The first trade that crosses SL or TP determines the fill.
"""
for trade in trades:
price = trade['price']
if side == 'long':
if price <= sl_price:
return ('sl', price)
if price >= tp_price:
return ('tp', price)
else: # short
if price >= sl_price:
return ('sl', price)
if price <= tp_price:
return ('tp', price)
return None
Tingkat trade mentah dipanggil sangat jarang — kurang dari 0,1% dari seluruh bar — tetapi ketika dipanggil, ia memberikan ground truth yang tidak dapat ditandingi oleh aproksimasi berbasis candle mana pun.
Ambang Batas Terpisah per Transisi
Transisi resolusi yang berbeda memiliki karakteristik berbeda. Pergerakan harga 0,1% dalam satu detik itu signifikan; 0,1% yang sama dalam satu bucket 100ms itu ekstrem. Demikian pula, distribusi volume berbeda pada setiap skala waktu.
Setiap transisi tingkat kini memiliki parameter min_pct dan vol_mult sendiri:
1s → 100ms: --min-pct-1s 0.1 --vol-mult-1s 500
100ms → trades: --min-pct-100ms 0.1 --vol-mult-100ms 500
Ini memungkinkan penyetelan halus sensitivitas setiap transisi secara independen. Dalam praktiknya, transisi 100ms-ke-trade dapat menggunakan ambang batas yang lebih ketat karena biaya memuat trade mentah untuk satu bucket 100ms sangat minimal.
@dataclass
class DrillDownConfig:
min_pct_1s: float = 0.1
vol_mult_1s: float = 500
min_pct_100ms: float = 0.1
vol_mult_100ms: float = 500
Statistik Median Persisten
Drill-down berbasis volume membutuhkan pengetahuan tentang volume median pada setiap skala waktu. Menghitung median secara on-the-fly untuk setiap backtest akan meniadakan manfaat performa. Solusinya: hitung median sekali dan cache.
Untuk setiap simbol, volume median pada granularitas 1s dan 100ms dihitung dari data historis dan disimpan dalam file stats.json:
{
"ETHUSDT": {
"median_volume_1s": 12.5,
"median_volume_100ms": 1.8
},
"BTCUSDT": {
"median_volume_1s": 0.45,
"median_volume_100ms": 0.06
}
}
Statistik dihitung sekali per simbol ketika data pertama kali diunduh dan digunakan kembali di seluruh backtest berikutnya. Jika data diperbarui (bulan baru diunduh), statistik dihitung ulang secara inkremental.
def compute_median_stats(symbol, data_dir):
"""Compute and cache median volume stats for a symbol."""
stats_path = f"{data_dir}/{symbol}/stats.json"
all_1s = load_all_months(f"{data_dir}/{symbol}/klines_1s/")
median_1s = all_1s['volume'].median()
all_100ms = load_all_months(f"{data_dir}/{symbol}/klines_100ms_hot/")
median_100ms = all_100ms['volume'].median()
stats = {
"median_volume_1s": float(median_1s),
"median_volume_100ms": float(median_100ms),
}
with open(stats_path, 'w') as f:
json.dump(stats, f, indent=2)
return stats

Dukungan Multi-Exchange: Bybit
Tidak semua simbol tersedia di Binance. Untuk aset seperti XAUTUSDT (emas), data harus berasal dari exchange lain. Sistem drill-down kini mendukung Bybit sebagai sumber data alternatif.
Untuk simbol Bybit, semua tingkat candle (1m, 1s, 100ms) dan trade mentah dibangun dari aliran trade mentah Bybit. Prosesnya sama — trade mentah diagregasi menjadi candle pada setiap skala waktu — tetapi sumber datanya berbeda.
data/{SYMBOL}/
├── source.json # {"exchange": "bybit"} or {"exchange": "binance"}
├── klines_1m/
│ └── ...
├── klines_1s/
│ └── ...
├── klines_100ms_hot/
│ └── ...
└── trades_hot/ # Raw trades for hot 100ms buckets
└── ...
Data loader memeriksa source.json dan menggunakan pipeline unduhan yang sesuai. Dari sudut pandang mesin backtest, format data identik terlepas dari exchange sumbernya — logika drill-down bersifat agnostik terhadap exchange.
Hal ini sangat penting untuk strategi lintas-exchange atau simbol yang diperdagangkan secara eksklusif di venue tertentu.
Kesimpulan
Drill-down adaptif adalah penerapan prinsip sederhana: alokasikan sumber daya komputasi dan penyimpanan secara proporsional terhadap pentingnya data.
Empat tingkat granularitas:
- 1m — lintasan dasar untuk 95% bar
- 1s — drill-down saat ambiguitas eksekusi atau lonjakan volume
- 100ms — drill-down untuk detik panas dengan pergerakan ekstrem atau volume anomali
- Trade mentah — drill-down untuk bucket 100ms panas, menyelesaikan eksekusi pada tingkat trade individual
Empat tingkat penyimpanan:
- Semua 1m — arsip lengkap, ~15 MB untuk 2 tahun
- Semua 1s — arsip lengkap atau adaptif, ~550 MB/bulan
- Hanya 100ms panas — <1% detik, ~50 MB/bulan
- Hanya trade panas — trade mentah untuk bucket 100ms paling ekstrem
Dua pemicu drill-down (logika OR):
- Berbasis harga: rentang harga bar melampaui
min_pct - Berbasis volume: volume bar melampaui
median * vol_mult
Hasilnya: backtest dengan akurasi simulator tick pada kecepatan tingkat menit. Penyimpanan yang tumbuh secara linear, bukan eksponensial. Dan dukungan untuk banyak exchange — Binance dan Bybit — dengan logika drill-down yang agnostik terhadap exchange.
Untuk lebih lanjut tentang cache terkomputasi untuk strategi multi-timeframe, lihat artikel Cache Parquet Teragregasi. Tentang dampak funding rate pada hasil dengan leverage tinggi — Funding rate membunuh leverage Anda.
Tautan Bermanfaat
- Apache Parquet — format penyimpanan data
- Apache Arrow — pengkodean BYTE_STREAM_SPLIT
- Zstandard — algoritma kompresi
- Lopez de Prado — Advances in Financial Machine Learning
- Binance — Historical Market Data
Sitasi
@article{soloviov2026adaptivedrilldown,
author = {Soloviov, Eugen},
title = {Adaptive Drill-Down: Backtest with Variable Granularity from Minutes to Raw Trades},
year = {2026},
url = {https://marketmaker.cc/ru/blog/post/adaptive-resolution-drill-down-backtest},
description = {Bagaimana granularitas data adaptif mempercepat backtest dan menghemat penyimpanan: drill-down dari 1m ke 1s, 100ms, dan trade mentah hanya di tempat harga bergerak signifikan atau volume melonjak.}
}
Penulis

Trading-systems engineer
Trading-systems engineer building bots since 2017: cross-exchange arbitrage (connected up to 30 venues), cointegration-based pairs arbitrage across spot and futures, scalping, news and sentiment-driven strategies, trend algorithms, and portfolio management and balancing algorithms. Also builds sub-millisecond order execution, big-data warehouses, backtesting engines, AI agents, and trading interfaces (incl. open-source profitmaker.cc). Stack: JS/TS, Python, Rust/Zig/Go, DevOps, backend, frontend, architecture.
Baca Selengkapnya

Cache Parquet Teragregasi: Cara Mempercepat Backtest Multi-Timeframe Ratusan Kali Lipat

Kapan GPU Terbayar: Roofline Sweep Parameter, di Mana Headline 167x Sebenarnya adalah 27x Algoritma Kali 6.2x Hardware
