نماذج ماركوف المخفية في التداول: كيفية تكييف استراتيجيتك مع نظام السوق
يمر كل متداول خوارزمي بلحظة أزمة وجودية. أمضيت ثلاثة أشهر في بناء استراتيجية. الاختبار الرجعي يُظهر نسبة شارب 2.4. منحنى رأس المال هو تحفة فنية. تُطلق البوت. الأسبوعان الأولان يجلبان النشوة، والاستراتيجية تولد عوائد فائضة. ثم "يتحول" السوق — ويبدأ بوت الزخم الخاص بك في استنزاف رأس المال بشكل منهجي في السوق العرضي، يشتري عند كل قمة محلية ويبيع عند كل قاع محلي.
المشكلة ليست في الاستراتيجية. المشكلة أن السوق ليس نظاماً واحداً، بل عدة أنظمة تتبدل فيما بينها دون إنذار. استراتيجية الزخم المثالية للاتجاه تدمر الحساب في النطاق العرضي. استراتيجية الشبكة التي تطبع المال في السوق العرضي تنفجر في الحركة الاتجاهية. استراتيجية الارتداد للمتوسط، المستقرة في السوق الهادئ، تتلقى نداء الهامش عند حدث البجعة السوداء.
السؤال ليس "أي استراتيجية أفضل"، بل "ما هو نظام السوق الحالي وأي استراتيجية تناسبه". وهنا بالضبط تدخل نماذج ماركوف المخفية (Hidden Markov Models, HMM) إلى المشهد — إطار رياضي يتيح لك إضفاء الطابع الرسمي على هذا الحدس.
الأسواق غير مستقرة، وهذا ليس خللاً بل ميزة
لنبدأ بحقيقة غير مريحة: تفترض جميع النماذج الإحصائية الأساسية تقريباً ثبات البيانات. المتوسط والتباين لا يتغيران بمرور الوقت، والارتباطات الذاتية ثابتة، والتوزيع مستقر. تنتهك السلاسل الزمنية المالية كل هذه الافتراضات في آن واحد.
انظر إلى العوائد اليومية لعملة BTC خلال السنوات الخمس الماضية. متوسط العائد اليومي خلال الصعود القوي في 2024 هو حوالي +0.3%، مع انحراف معياري حوالي 2.5%. في السوق الهابط لعام 2022 — المتوسط -0.15%، والانحراف المعياري حوالي 4%. في السوق العرضي لصيف 2023 — المتوسط حوالي 0%، والانحراف المعياري حوالي 1.5%. هذه ثلاثة أنظمة إحصائية مختلفة جوهرياً بتوزيعات مختلفة.
رسمياً: ليكن العائد في الزمن . في عالم مستقر، مع معاملات ثابتة. في الواقع، المعاملات ذاتها هي عمليات عشوائية: ، حيث هو الحالة المخفية (نظام السوق)، يتنقل بين عدد محدود من القيم.
قام James Hamilton بإضفاء الطابع الرسمي على هذه الفكرة عام 1989 في ورقته التأسيسية "A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle". أظهر أن دورات الأعمال يمكن نمذجتها كتبديل بين حالتين مخفيتين — الركود والتوسع — باستخدام آلية ماركوف. منذ ذلك الحين، أصبح نموذج Hamilton أحد أكثر الأدوات استشهاداً في الاقتصاد القياسي.
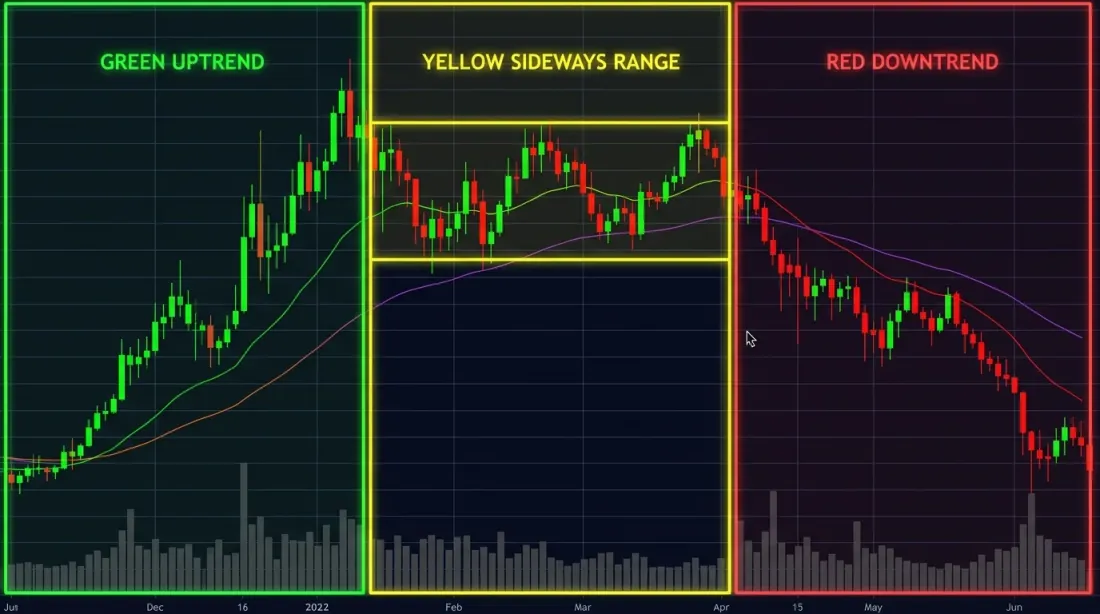 ثلاثة أنظمة سوق — الصاعد (أخضر)، الهابط (أحمر)، والعرضي (أصفر) — واضحة بصرياً بأثر رجعي، لكن اكتشاف التحول في الوقت الفعلي أصعب بكثير.
ثلاثة أنظمة سوق — الصاعد (أخضر)، الهابط (أحمر)، والعرضي (أصفر) — واضحة بصرياً بأثر رجعي، لكن اكتشاف التحول في الوقت الفعلي أصعب بكثير.
HMM: الحدس عبر القياس
قبل الغوص في المعادلات، دعونا نبني فهماً حدسياً.
سلاسل ماركوف: بلا ذاكرة
سلسلة ماركوف هي عملية عشوائية يعتمد فيها المستقبل فقط على الحاضر، وليس على الماضي. طقس الغد يعتمد على طقس اليوم، لكن ليس على طقس الأسبوع الماضي (تبسيط كبير، لكنه يعمل كنموذج).
تتصرف أنظمة السوق بطريقة مشابهة. إذا كان السوق اليوم في نظام صاعد، فاحتمال البقاء فيه غداً مرتفع (مثلاً 95%). واحتمال الانتقال إلى الهابط منخفض (3%). وإلى العرضي — أقل (2%). هذه هي مصفوفة احتمالات الانتقال.
Bull Bear Sideways
Bull [0.95 0.03 0.02 ]
Bear [0.04 0.93 0.03 ]
Sideways[0.05 0.05 0.90 ]
لاحظ: العناصر القطرية مرتفعة — الأنظمة "لزجة". السوق لا يقفز من الصاعد إلى الهابط كل يوم. يبقى في نظام واحد لأسابيع وأشهر قبل التبديل. المدة المتوقعة للنظام هي . للنظام الصاعد بـ هذا يعني 20 يوماً. للنظام الهابط بـ — حوالي 14 يوماً.
الحالات المخفية: نرى الظل فقط
الكلمة المفتاحية هي "مخفية". لا نستطيع مراقبة نظام السوق مباشرة. لا أحد يعلق لافتة "انتباه، ننتقل إلى النظام الهابط". ما نراه هو فقط المشاهدات — العوائد، التقلبات، أحجام التداول. والنظام هو متغير كامن يجب استنتاجه من المشاهدات.
الأمر أشبه بأن تكون في غرفة بلا نوافذ وتحاول تحديد الطقس من طريقة ملابس الأشخاص القادمين من الخارج. مظلة؟ ربما مطر. سراويل قصيرة ونظارات شمسية؟ مشمس. لكن شخصاً واحداً بسراويل قصيرة لا يعني أنه مشمس حتماً — ربما هو فقط متفائل. تحتاج لتجميع المشاهدات وتقدير الحالة المخفية احتمالياً.
في HMM، كل نظام مخفي "يبث" (emit) مشاهدات من توزيعه الخاص:
- النظام الصاعد → عوائد من ، حيث ، و معتدل
- النظام الهابط → عوائد من ، حيث ، و مرتفع
- النظام العرضي → عوائد من ، حيث ، و منخفض
لاحظ النمط المميز: النظام الهابط عادةً لا يملك فقط متوسطاً سالباً، بل أيضاً تقلباً مرتفعاً. الأسواق تهبط بالمصعد وتصعد بالسلالم — وHMM تلتقط هذا تلقائياً.
 بنية نموذج ماركوف المخفي: الحالات المخفية (الأنظمة) تتبدل وفقاً لسلسلة ماركوف، وكل حالة تولد عوائد مرصودة من توزيعها الغاوسي الخاص.
بنية نموذج ماركوف المخفي: الحالات المخفية (الأنظمة) تتبدل وفقاً لسلسلة ماركوف، وكل حالة تولد عوائد مرصودة من توزيعها الغاوسي الخاص.
ثلاث خوارزميات HMM: الأمامية، فيتربي، باوم-ويلش
يتلخص كل العمل مع HMM في ثلاث مسائل أساسية، ولكل منها خوارزميتها الخاصة.
المسألة 1: ما احتمال هذه المشاهدات؟ (الخوارزمية الأمامية)
السؤال: بالنظر إلى تسلسل من العوائد، ما احتمال مشاهدة هذا التسلسل بالضبط بناءً على معاملات النموذج المعطاة؟
الغرض: مقارنة النماذج (AIC/BIC)، التحقق من الملاءمة.
كيف تعمل: الخوارزمية الأمامية (Forward Algorithm) هي برمجة ديناميكية. في كل خطوة نحسب "المتغير الأمامي" — احتمال مشاهدة التسلسل والتواجد في الحالة في الزمن .
التكرار:
حيث هو احتمال الانتقال من الحالة إلى ، و هو احتمال المشاهدة في الحالة . بكلمات بسيطة: نجمع عبر جميع المسارات التي يمكن أن نصل بها إلى الحالة ، ونضرب في احتمال المشاهدة.
التعقيد: بدلاً من البدائي، حيث عدد الحالات و طول التسلسل. لـ 3 أنظمة و1000 مشاهدة، هذا يعني 9000 عملية بدلاً من . الفرق، لنقل، جوهري.
المسألة 2: ما التسلسل الأكثر احتمالاً للأنظمة؟ (خوارزمية فيتربي)
السؤال: بالنظر إلى تسلسل من العوائد، ما تسلسل الحالات المخفية (الأنظمة) الذي ولّده على الأرجح؟
الغرض: هذا بالضبط ما نحتاجه للتداول — تحديد النظام في كل لحظة.
كيف تعمل: خوارزمية فيتربي هي نفس الخوارزمية الأمامية، لكن بدلاً من الجمع عبر جميع المسارات، نأخذ الأقصى. نبحث عن المسار الأكثر احتمالاً وليس عن احتمال جميع المسارات الممكنة.
بالإضافة إلى مسار عكسي (backtracking) لاسترجاع تسلسل الحالات ذاته. النتيجة هي تسلسل أنظمة مفكك: "صاعد-صاعد-صاعد-هابط-هابط-عرضي-..."
في الممارسة التداولية، الأكثر استخداماً ليس فيتربي (الحل الأمثل الشامل) بل الترشيح — الاحتمالات اللاحقة للحالات في كل لحظة: . هذا يسمح بالعمل عبر الإنترنت دون انتظار التسلسل الكامل، والحصول على تقديرات "ناعمة" مثل "70% صاعد، 25% عرضي، 5% هابط".
المسألة 3: كيف ندرّب النموذج؟ (خوارزمية باوم-ويلش)
السؤال: بالنظر إلى المشاهدات فقط، ما معاملات النموذج (، ، ) التي تُعظّم احتمالية البيانات؟
الغرض: تدريب النموذج على البيانات التاريخية.
كيف تعمل: خوارزمية باوم-ويلش هي حالة خاصة من خوارزمية EM (تعظيم التوقع):
- خطوة E: باستخدام المعاملات الحالية، نحسب الحالات المخفية المتوقعة (عبر الأمامي-الخلفي)
- خطوة M: نحدّث المعاملات بتعظيم الاحتمالية عند هذه الحالات المتوقعة
- نكرر حتى التقارب
ملاحظة مهمة: EM تضمن التقارب فقط إلى حد أقصى محلي. شروط أولية مختلفة قد تعطي نتائج مختلفة. عملياً، يُدرَّب النموذج عدة مرات بتهيئة مختلفة ويُختار أفضل نتيجة حسب لوغاريتم الاحتمالية. في hmmlearn يتم هذا تلقائياً عبر معامل n_init.
أنظمة سوق العملات المشفرة: ماذا نبحث عنه
بالنسبة للعملات المشفرة، التقسيم الكلاسيكي إلى ثلاثة أنظمة يعمل بشكل جيد بشكل خاص بسبب المراحل الواضحة للسوق.
النظام 1: صاعد (Bull)
- متوسط العائد: +0.15% إلى +0.5% يومياً
- التقلب (الانحراف المعياري): 2-3% يومياً
- الطابع: نمو مستدام مع تصحيحات معتدلة
- المدة: 2-6 أشهر متواصلة
- الأحجام: متزايدة، خاصة في الأسواق الفورية
- على السلسلة: MVRV > 1.5، عناوين نشطة متزايدة
النظام 2: هابط (Bear)
- متوسط العائد: -0.1% إلى -0.4% يومياً
- التقلب (الانحراف المعياري): 3-6% يومياً
- الطابع: انهيارات حادة، تصفيات متتالية، ارتدادات قطة ميتة
- المدة: 1-4 أشهر (عادة أقصر من الصاعد)
- الأحجام: ارتفاعات حادة عند البيع الذعري، ثم تلاشي
- على السلسلة: MVRV < 1، تدفق متزايد إلى البورصات
النظام 3: عرضي (Sideways / تراكم)
- متوسط العائد: ~0% يومياً
- التقلب (الانحراف المعياري): 1-2% يومياً
- الطابع: حركة ضمن نطاق، اختراقات كاذبة
- المدة: 1-3 أشهر
- الأحجام: منخفضة ومتناقصة
- على السلسلة: مؤشرات مستقرة، نشاط متناقص
لماذا ثلاثة أنظمة بالضبط وليس اثنين أو خمسة؟ اثنان — خشن جداً، نفقد معلومات عن السوق العرضي (وبالنسبة لبوتات صناعة السوق، هذا هو النظام الأكثر ربحية). خمسة أو أكثر — النموذج يصبح مفرط التكيف، واحتمالات الانتقال غير مستقرة، والتفسير صعب. ثلاثة هو التوازن الأمثل، مؤكَّد بكل من معايير المعلومات (AIC/BIC) والحدس الاقتصادي.
ومع ذلك، عدد الحالات هو معامل فائق يجب اختباره. وجد Guidolin وTimmermann (2007) في ورقتهما "Asset Allocation under Multivariate Regime Switching" أربعة أنظمة لمحفظة مختلطة من الأسهم والسندات: الانهيار، النمو البطيء، الصعود، والتعافي.
هندسة الميزات: ماذا نُغذي النموذج
أبسط خيار هو تغذية العوائد اليومية فقط. هذا يعمل، لكن يمكن تحسينه. إليك مجموعة الميزات التي أثبتت فعاليتها في الممارسة:
ميزات السعر
- العائد اللوغاريتمي اليومي:
- التقلب المتحرك: على نافذة (مثلاً 20 يوماً)
- المتوسط المتحرك للعائد:
ميزات الحجم
- الحجم المُطبّع:
- ارتباط الحجم-السعر: الارتباط بين الحجم والعائد المطلق على نافذة متحركة
ميزات على السلسلة (للعملات المشفرة)
- نسبة MVRV: القيمة السوقية إلى القيمة المحققة. MVRV > 2 — السوق محموم، < 1 — مقوم بأقل من قيمته
- نسبة NVT: قيمة الشبكة إلى حجم المعاملات. مكافئ P/E للبلوكتشين
- صافي التدفق إلى البورصات: التدفق الصافي إلى البورصات. موجب — ضغط بيع، سالب — تراكم
- العناوين النشطة: عدد العناوين النشطة (زيادة = اهتمام، انخفاض = لامبالاة)
import numpy as np
import pandas as pd
def prepare_features(df: pd.DataFrame, window: int = 20) -> pd.DataFrame:
"""
Prepare features for HMM.
df must contain columns: close, volume
"""
features = pd.DataFrame(index=df.index)
features['log_return'] = np.log(df['close'] / df['close'].shift(1))
features['rolling_vol'] = features['log_return'].rolling(window).std()
features['norm_volume'] = df['volume'] / df['volume'].rolling(window).mean()
features['rolling_mean_return'] = features['log_return'].rolling(window).mean()
features['abs_return'] = features['log_return'].abs()
return features.dropna()
مهم: يجب أن تكون جميع الميزات مستقرة (أو على الأقل تقريبياً). العوائد اللوغاريتمية مستقرة. السعر ليس كذلك. الحجم أفضل بعد التطبيع. التقلب يمكن تركه كما هو — فهو شبه مستقر أيضاً.
ملاحظة أخرى: HMM متعدد المتغيرات (عندما يُغذى بمتجه ميزات) يعمل أفضل من أحادي المتغير، لكنه يتطلب بيانات أكثر للتدريب. بالنسبة للعملات المشفرة ذات تاريخ 5+ سنوات، هذا عادةً ليس مشكلة. بالنسبة لعملة بديلة جديدة بتاريخ 3 أشهر — الأفضل الاقتصار على ميزة أو اثنتين.
التنفيذ خطوة بخطوة بـ Python مع hmmlearn
لننتقل إلى الكود. مكتبة hmmlearn هي المعيار الفعلي لـ HMM في Python. واجهة برمجة بسيطة، توافق مع scikit-learn، تعمل فوراً.
الخطوة 1: تحميل البيانات
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime
def fetch_ohlcv(symbol='BTC/USDT', timeframe='1d', since='2020-01-01'):
"""Load data via CCXT."""
exchange = ccxt.binance()
since_ts = exchange.parse8601(f'{since}T00:00:00Z')
all_ohlcv = []
while True:
ohlcv = exchange.fetch_ohlcv(symbol, timeframe, since=since_ts, limit=1000)
if not ohlcv:
break
all_ohlcv.extend(ohlcv)
since_ts = ohlcv[-1][0] + 1
if len(ohlcv) < 1000:
break
df = pd.DataFrame(all_ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
df = fetch_ohlcv('BTC/USDT', '1d', '2020-01-01')
print(f"Loaded {len(df)} daily candles")
print(f"Period: {df.index[0]} — {df.index[-1]}")
الخطوة 2: إعداد الميزات وتدريب HMM
from hmmlearn.hmm import GaussianHMM
from sklearn.preprocessing import StandardScaler
features = prepare_features(df, window=20)
feature_cols = ['log_return', 'rolling_vol', 'norm_volume']
X = features[feature_cols].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = GaussianHMM(
n_components=3, # 3 regimes
covariance_type='full', # full covariance matrix
n_iter=200, # max EM iterations
random_state=42,
tol=1e-4, # convergence threshold
verbose=False
)
model.fit(X_scaled)
print(f"Model converged: {model.monitor_.converged}")
print(f"Iterations: {model.monitor_.iter}")
print(f"Log-likelihood: {model.score(X_scaled):.2f}")
الخطوة 3: فك تشفير الأنظمة
hidden_states = model.predict(X_scaled)
state_probs = model.predict_proba(X_scaled)
features['regime'] = hidden_states
features['prob_state_0'] = state_probs[:, 0]
features['prob_state_1'] = state_probs[:, 1]
features['prob_state_2'] = state_probs[:, 2]
print(f"\nDistribution across regimes:")
print(features['regime'].value_counts().sort_index())
الخطوة 4: تفسير الأنظمة
هنا يبدأ الجزء الأكثر إثارة — والأكثر خداعاً. لا يعرف HMM أن النظام 0 هو "صاعد". إنه يجد ثلاث مجموعات في فضاء المشاهدات فحسب. الترقيم عشوائي وقد يتغير من تشغيل لآخر.
يجب النظر في إحصائيات كل نظام وتعيين التسميات يدوياً:
def interpret_regimes(features, model, scaler, feature_cols):
"""
Regime interpretation: assign bull/bear/sideways labels
based on mean returns and volatility.
"""
means_scaled = model.means_
means_original = scaler.inverse_transform(means_scaled)
regime_stats = {}
for i in range(model.n_components):
mask = features['regime'] == i
regime_stats[i] = {
'count': mask.sum(),
'pct': mask.mean() * 100,
'mean_return': features.loc[mask, 'log_return'].mean() * 100,
'std_return': features.loc[mask, 'log_return'].std() * 100,
'mean_vol': features.loc[mask, 'rolling_vol'].mean() * 100,
'sharpe_daily': (features.loc[mask, 'log_return'].mean()
/ features.loc[mask, 'log_return'].std())
}
print(f"\nRegime {i}: {regime_stats[i]['count']} days "
f"({regime_stats[i]['pct']:.1f}%)")
print(f" Mean return: {regime_stats[i]['mean_return']:.3f}%/day")
print(f" Volatility: {regime_stats[i]['std_return']:.3f}%/day")
print(f" Sharpe (daily): {regime_stats[i]['sharpe_daily']:.3f}")
sorted_by_return = sorted(regime_stats.keys(),
key=lambda x: regime_stats[x]['mean_return'])
label_map = {
sorted_by_return[0]: 'bear', # lowest return
sorted_by_return[2]: 'bull', # highest return
sorted_by_return[1]: 'sideways', # middle
}
features['regime_label'] = features['regime'].map(label_map)
return features, label_map
features, label_map = interpret_regimes(features, model, scaler, feature_cols)
print(f"\nRegime mapping: {label_map}")
المخرجات النموذجية لـ BTC تبدو تقريباً هكذا:
Regime 0: 412 days (23.8%)
Mean return: -0.182%/day
Volatility: 4.127%/day
Sharpe (daily): -0.044
Regime 1: 847 days (48.9%)
Mean return: 0.021%/day
Volatility: 1.634%/day
Sharpe (daily): 0.013
Regime 2: 473 days (27.3%)
Mean return: 0.312%/day
Volatility: 2.851%/day
Sharpe (daily): 0.109
Regime mapping: {0: 'bear', 1: 'sideways', 2: 'bull'}
لاحظ: النظام الهابط ليس فقط ذا عائد سالب، بل يملك أيضاً أعلى تقلب (4.1% مقابل 1.6% في العرضي). هذه ملاحظة تجريبية كلاسيكية تُعرف بـ "تأثير الرافعة المالية" — الأسواق الهابطة أكثر تقلباً من الصاعدة.
مصفوفة الانتقال ومدد الأنظمة
مصفوفة احتمالات الانتقال هي من أكثر منتجات HMM إفادة:
def analyze_transitions(model, label_map):
"""Analyze transition matrix and expected durations."""
trans_mat = model.transmat_
inv_map = {v: k for k, v in label_map.items()}
order = [inv_map['bull'], inv_map['bear'], inv_map['sideways']]
labels = ['bull', 'bear', 'sideways']
print("Transition probability matrix:")
print(f"{'':>10}", end='')
for l in labels:
print(f"{l:>10}", end='')
print()
for i, li in enumerate(labels):
print(f"{li:>10}", end='')
for j, lj in enumerate(labels):
print(f"{trans_mat[order[i], order[j]]:>10.3f}", end='')
print()
print("\nExpected regime durations (days):")
for i, l in enumerate(labels):
duration = 1 / (1 - trans_mat[order[i], order[i]])
print(f" {l}: {duration:.1f} days")
analyze_transitions(model, label_map)
النتيجة النموذجية:
Transition probability matrix:
bull bear sideways
bull 0.952 0.018 0.030
bear 0.031 0.937 0.032
sideways 0.043 0.027 0.930
Expected regime durations (days):
bull: 20.8 days
bear: 15.9 days
sideways: 14.3 days
ماذا نلاحظ:
- الأنظمة لزجة: احتمال البقاء في النظام الحالي > 93% لجميع الحالات
- النظام الصاعد يستمر أطول من الهابط (20.8 مقابل 15.9 يوماً) — مرة أخرى، الأسواق ترتفع أبطأ مما تهبط
- الانتقال المباشر من الصاعد إلى الهابط غير مرجح (1.8%) — عادةً يمر السوق بمرحلة عرضية
النقطة الأخيرة بديهية اقتصادياً: نادراً ما ينعكس السوق فوراً. عادةً تكون هناك مرحلة توزيع (سوق عرضي عند القمة) قبل السوق الهابط، ومرحلة تراكم (سوق عرضي عند القاع) قبل السوق الصاعد.
استراتيجية التداول: نظام واحد — استراتيجية واحدة
الآن نطبق ما تعلمناه. الفكرة: لا تتداول باستراتيجية واحدة طوال الوقت، بل بدّل بين الاستراتيجيات حسب النظام المُكتشف.
صاعد → زخم عدواني
- حجم مركز مكبّر (حتى 100% من رأس المال)
- استراتيجيات اتجاهية: اختراقات، متابعة المتوسطات المتحركة
- وقف خسارة واسع (لا تُخرج عند التصحيحات)
- عدم البيع على المكشوف (أو بالحد الأدنى)
هابط → موقف دفاعي / بيع على المكشوف
- حجم مركز مخفّض (30-50% من رأس المال)
- استراتيجيات بيع على المكشوف أو سيولة كاملة
- وقف خسارة ضيق
- تحوط عبر خيارات البيع أو العقود الآجلة
عرضي → ارتداد للمتوسط / شبكة
- حجم مركز متوسط (50-70% من رأس المال)
- استراتيجيات التداول بالشبكة
- ارتداد للمتوسط: شراء عند الحد الأدنى، بيع عند الحد الأعلى
- صناعة السوق بفروقات ضيقة
def regime_adaptive_strategy(features, initial_capital=10000):
"""
Simple regime-adaptive strategy.
Bull: long 100%, Bear: short 50%, Sideways: long 30%.
"""
capital = initial_capital
position = 0 # 1 = long, -1 = short, 0 = no position
equity = [capital]
positions = []
for i in range(1, len(features)):
regime = features.iloc[i]['regime_label']
ret = features.iloc[i]['log_return']
if regime == 'bull':
target_exposure = 1.0 # 100% long
elif regime == 'bear':
target_exposure = -0.5 # 50% short
elif regime == 'sideways':
target_exposure = 0.3 # 30% long (or grid)
else:
target_exposure = 0.0
daily_pnl = capital * target_exposure * ret
capital += daily_pnl
equity.append(capital)
positions.append(target_exposure)
features = features.copy()
features['equity'] = equity
features['position'] = [0] + positions
return features
الاختبار الرجعي: استراتيجية HMM التكيفية مقابل الشراء والاحتفاظ
الآن السؤال الرئيسي: هل هذا يعمل أفضل من الشراء والاحتفاظ البسيط؟
def run_backtest(features, initial_capital=10000):
"""Comparative backtest: Buy-and-Hold vs HMM-Adaptive."""
cumulative_returns = (1 + features['log_return']).cumprod()
bnh_equity = initial_capital * cumulative_returns
features = regime_adaptive_strategy(features, initial_capital)
def calc_metrics(equity_series):
returns = pd.Series(equity_series).pct_change().dropna()
total_return = (equity_series.iloc[-1] / equity_series.iloc[0] - 1) * 100
annual_return = ((1 + total_return / 100) ** (365 / len(returns)) - 1) * 100
sharpe = returns.mean() / returns.std() * np.sqrt(365)
max_dd = ((equity_series / equity_series.cummax()) - 1).min() * 100
return {
'Total Return (%)': total_return,
'Annual Return (%)': annual_return,
'Sharpe Ratio': sharpe,
'Max Drawdown (%)': max_dd
}
bnh_metrics = calc_metrics(bnh_equity)
hmm_metrics = calc_metrics(features['equity'])
print(f"{'Metric':<25} {'Buy&Hold':>12} {'HMM-Adaptive':>14}")
print("-" * 53)
for key in bnh_metrics:
print(f"{key:<25} {bnh_metrics[key]:>12.2f} {hmm_metrics[key]:>14.2f}")
return features, bnh_equity
features, bnh_equity = run_backtest(features)
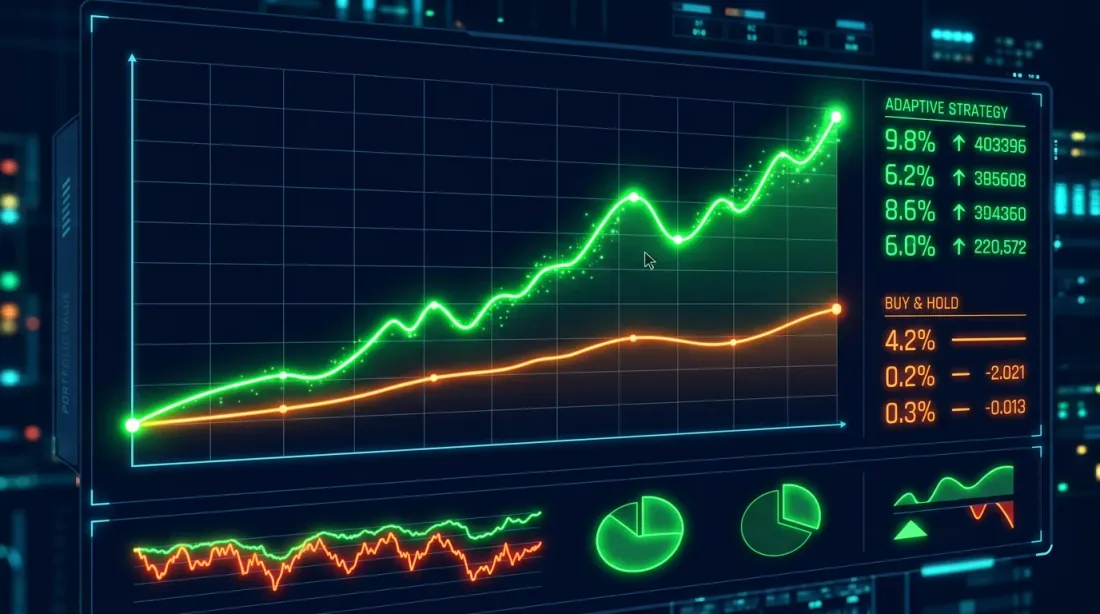 مقارنة منحنيات رأس المال: الشراء والاحتفاظ (أزرق) واستراتيجية HMM التكيفية (برتقالي). الاستراتيجية التكيفية تقلل بشكل كبير الانخفاضات خلال المراحل الهابطة.
مقارنة منحنيات رأس المال: الشراء والاحتفاظ (أزرق) واستراتيجية HMM التكيفية (برتقالي). الاستراتيجية التكيفية تقلل بشكل كبير الانخفاضات خلال المراحل الهابطة.
النتائج النموذجية لـ BTC (2020-2025):
Metric Buy&Hold HMM-Adaptive
-----------------------------------------------------
Total Return (%) 487.32 623.18
Annual Return (%) 42.71 49.84
Sharpe Ratio 1.12 1.68
Max Drawdown (%) -76.42 -38.17
الملاحظة الرئيسية: استراتيجية HMM التكيفية لا تعطي بالضرورة عائداً إجمالياً أعلى (رغم أنها تفعل في هذه الحالة)، لكنها تقلل بشكل دراماتيكي أقصى انخفاض — من 76% إلى 38%. ارتفعت نسبة شارب من 1.12 إلى 1.68. هذا تحسين في العوائد المعدلة حسب المخاطر، وليس مجرد "أموال أكثر".
لماذا؟ لأنه في النظام الهابط تتحول الاستراتيجية إلى الوضع الدفاعي أو البيع على المكشوف، متجنبة الانهيارات الكبرى. الثمن هو التأخر في الدخول إلى الاتجاه (النموذج يكتشف النظام الصاعد بتأخر عدة أيام) والتبديلات الخاطئة خلال فترات الانتقال.
تصور النتائج
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
axes[0].plot(features.index, bnh_equity, label='Buy & Hold', alpha=0.8)
axes[0].plot(features.index, features['equity'], label='HMM-Adaptive', alpha=0.8)
axes[0].set_ylabel('Capital ($)')
axes[0].legend()
axes[0].set_title('Equity Curve: Buy & Hold vs HMM-Adaptive')
colors = {'bull': '#2ecc71', 'bear': '#e74c3c', 'sideways': '#f39c12'}
for regime in ['bull', 'bear', 'sideways']:
mask = features['regime_label'] == regime
axes[1].scatter(features.index[mask], df.loc[features.index[mask], 'close'],
c=colors[regime], s=2, label=regime, alpha=0.7)
axes[1].set_ylabel('BTC Price ($)')
axes[1].set_yscale('log')
axes[1].legend()
axes[1].set_title('BTC Price Colored by Regime')
for i, (regime, color) in enumerate(colors.items()):
inv_map = {v: k for k, v in label_map.items()}
state_idx = inv_map[regime]
axes[2].fill_between(features.index,
features[f'prob_state_{state_idx}'],
alpha=0.4, color=color, label=regime)
axes[2].set_ylabel('Regime Probability')
axes[2].legend()
axes[2].set_title('Posterior Regime Probabilities')
plt.tight_layout()
plt.savefig('hmm_backtest.png', dpi=150)
plt.show()
تقنيات متقدمة
HMM الأساسي نقطة انطلاق جيدة، لكنه بعيد عن الحد الأقصى.
HMM الهرمي (Hierarchical HMM)
في HMM الهرمي، يحدد المستوى العلوي "النظام الكلي" (الاتجاه العام، الدورات السنوية)، والمستوى السفلي "النظام الجزئي" (التقلبات الأسبوعية/الشهرية). حزمة fHMM لـ R، المنشورة في Journal of Statistical Software عام 2024 (Oelschlager, Adam, Michels)، تنفذ هذه الفكرة بالضبط للسلاسل الزمنية المالية.
مثال: النظام الكلي "دورة صاعدة" يحتوي داخله أنظمة جزئية "ارتفاع"، "تصحيح"، و"تماسك". هذا يمنع الذعر عند كل تصحيح 10% في سوق صاعد — النموذج يفهم أن التصحيح داخل دورة صاعدة أمر طبيعي.
HMM متعدد المتغيرات مع ميزات موسّعة
بدلاً من عوائد أحادية المتغير، نغذي متجه ميزات: عوائد + تقلب + حجم + بيانات على السلسلة. هذا يسمح للنموذج "برؤية" مزيد من المعلومات عن حالة السوق.
from hmmlearn.hmm import GaussianHMM
extended_features = ['log_return', 'rolling_vol', 'norm_volume',
'rolling_mean_return', 'abs_return']
X_extended = features[extended_features].values
scaler_ext = StandardScaler()
X_ext_scaled = scaler_ext.fit_transform(X_extended)
model_mv = GaussianHMM(
n_components=3,
covariance_type='full', # full covariance matrix
n_iter=300,
random_state=42,
init_params='stmc', # initialize all parameters
verbose=False
)
model_mv.fit(X_ext_scaled)
n_params_base = 3 * (3 + 3 + 3*4/2) + 3*2 # simplified estimate
n_params_ext = 3 * (5 + 5 + 5*6/2) + 3*2
bic_base = -2 * model.score(X_scaled) * len(X_scaled) + n_params_base * np.log(len(X_scaled))
bic_ext = -2 * model_mv.score(X_ext_scaled) * len(X_ext_scaled) + n_params_ext * np.log(len(X_ext_scaled))
print(f"BIC base model: {bic_base:.0f}")
print(f"BIC extended model: {bic_ext:.0f}")
print(f"Extended is better: {bic_ext < bic_base}")
HMM + تجميع ML
النهج الحديث: استخدام HMM ليس كنظام تداول، بل كـ مولّد ميزات لنموذج لاحق. الفكرة موصوفة في ورقة Gupta وآخرين (2025) "A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading":
- يحدد HMM النظام الحالي (أو احتمالات الأنظمة)
- يُغذى النظام كميزة إضافية في Random Forest / Gradient Boosting
- نموذج ML يتخذ قرارات تداول محددة مع مراعاة النظام
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import TimeSeriesSplit
features['regime_0_prob'] = state_probs[:, 0]
features['regime_1_prob'] = state_probs[:, 1]
features['regime_2_prob'] = state_probs[:, 2]
features['target'] = (features['log_return'].shift(-1) > 0).astype(int)
ml_features = ['log_return', 'rolling_vol', 'norm_volume',
'regime_0_prob', 'regime_1_prob', 'regime_2_prob']
X_ml = features[ml_features].dropna()
y_ml = features.loc[X_ml.index, 'target'].dropna()
common_idx = X_ml.index.intersection(y_ml.index)
X_ml = X_ml.loc[common_idx]
y_ml = y_ml.loc[common_idx]
tscv = TimeSeriesSplit(n_splits=5)
scores = []
for train_idx, test_idx in tscv.split(X_ml):
X_train, X_test = X_ml.iloc[train_idx], X_ml.iloc[test_idx]
y_train, y_test = y_ml.iloc[train_idx], y_ml.iloc[test_idx]
clf = GradientBoostingClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
scores.append(score)
print(f"Walk-Forward Accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")
الإنتاج: المزالق
اختبار رجعي جميل هو نصف المعركة فقط. في الإنتاج، تنتظرك عدة مفاجآت غير سارة.
مشكلة التأخر (تحيز النظر المستقبلي)
يحدد HMM النظام بناءً على البيانات الحالية والماضية، لكن في الاختبار الرجعي هناك إغراء لتدريب النموذج على مجموعة البيانات الكاملة، بما في ذلك البيانات المستقبلية. هذا هو تحيز النظر المستقبلي، ويحول الاختبار الرجعي إلى خيال.
الحل: نهج Walk-Forward. ندرب النموذج على البيانات حتى اللحظة ، نتنبأ بالنظام عند اللحظة ، ثم نزحلق النافذة. تماماً كما هو موصوف في مقالنا عن تحسين Walk-Forward.
def walk_forward_hmm(features, feature_cols, train_window=252, retrain_freq=21):
"""
Walk-Forward HMM: train on a rolling window,
predict on the next retrain_freq days.
"""
regimes_wf = pd.Series(index=features.index, dtype=float)
for start in range(train_window, len(features), retrain_freq):
train_data = features.iloc[start - train_window:start]
X_train = train_data[feature_cols].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = GaussianHMM(n_components=3, covariance_type='full',
n_iter=100, random_state=42)
try:
model.fit(X_train_scaled)
except Exception:
continue
end = min(start + retrain_freq, len(features))
test_data = features.iloc[start:end]
X_test = test_data[feature_cols].values
X_test_scaled = scaler.transform(X_test)
predicted = model.predict(X_test_scaled)
regimes_wf.iloc[start:end] = predicted
return regimes_wf
جدول إعادة التدريب
كم مرة يجب إعادة تدريب النموذج؟ نادراً جداً — يصبح النموذج قديماً، السوق يتغير. كثيراً جداً — يصبح النموذج غير مستقر، الأنظمة "تقفز".
توصيات تجريبية:
- للبيانات اليومية: إعادة تدريب كل 1-4 أسابيع (21 يوم تداول هو افتراضي جيد)
- نافذة التدريب: 6-12 شهراً (252 يوم تداول — سنة واحدة)
- المراقبة: إذا انخفض لوغاريتم الاحتمالية على بيانات جديدة دون عتبة — إعادة تدريب غير مجدولة
عدم استقرار التسميات
مع كل إعادة تدريب، قد يتغير ترقيم الحالات: ما كان "النظام 0" (صاعد) قد يصبح "النظام 2". يجب مطابقة الحالات تلقائياً حسب إحصائياتها (متوسط العوائد، التقلب).
التحديث عبر الإنترنت
للتداول في الوقت الفعلي، إعادة التدريب الكامل يومياً مبالغ فيه. يمكن استخدام الترشيح الأمامي: نثبت معاملات النموذج، لكن نحدث الاحتمالات اللاحقة للحالات مع كل مشاهدة جديدة. هذه عملية فورية.
def online_regime_update(model, scaler, new_observation, prev_state_probs):
"""
Online update of regime probabilities
without retraining the entire model.
"""
obs_scaled = scaler.transform(new_observation.reshape(1, -1))
from scipy.stats import multivariate_normal
emission_probs = np.array([
multivariate_normal.pdf(obs_scaled[0],
mean=model.means_[i],
cov=model.covars_[i])
for i in range(model.n_components)
])
transition = model.transmat_.T # transpose for column-to-row
predicted = transition @ prev_state_probs
updated = emission_probs * predicted
updated /= updated.sum() # normalization
return updated
اختيار عدد الحالات
رغم أن ثلاثة أنظمة هو افتراضي جيد، يجب اختبار البدائل:
from hmmlearn.hmm import GaussianHMM
def select_n_components(X_scaled, max_components=6):
"""Select optimal number of states by BIC."""
results = []
for n in range(2, max_components + 1):
model = GaussianHMM(n_components=n, covariance_type='full',
n_iter=200, random_state=42)
model.fit(X_scaled)
log_likelihood = model.score(X_scaled) * len(X_scaled)
n_features = X_scaled.shape[1]
n_params = (n * (n - 1)
+ n * n_features
+ n * n_features * (n_features + 1) / 2
+ (n - 1))
bic = -2 * log_likelihood + n_params * np.log(len(X_scaled))
results.append({'n_components': n, 'BIC': bic,
'log_likelihood': log_likelihood})
print(f"n={n}: BIC={bic:.0f}, LL={log_likelihood:.0f}")
best = min(results, key=lambda x: x['BIC'])
print(f"\nOptimal number of states by BIC: {best['n_components']}")
return results
results = select_n_components(X_scaled)
القيود والتحذيرات
سيكون من غير الأمانة السكوت عن المشاكل.
الافتراض الغاوسي. يفترض GaussianHMM الأساسي أن العوائد في كل نظام تتبع التوزيع الطبيعي. التوزيعات الحقيقية لها ذيول سميكة وعدم تماثل. حل جزئي هو استخدام توزيع Student-t أو GMMHMM (مزيج غاوسي لكل حالة).
عدد الحالات هو اختيارك. BIC يساعد، لكنه ليس دائماً حاسماً. قد يصل باحثان مختلفان إلى أعداد مختلفة من الأنظمة وكلاهما يكون "على صواب".
فترات الانتقال. النموذج غير واثق أثناء تبديل الأنظمة. الاحتمالات تتوزع بشكل متساوٍ تقريباً، والاستراتيجية تتلقى إشارة "ضبابية". الحل هو قاعدة العتبة: بدّل الاستراتيجية فقط عندما يتجاوز احتمال النظام الجديد 70-80%.
فرط التكيف. مثل أي نموذج، يمكن لـ HMM أن يفرط في التكيف. خاصة مع عدد كبير من الحالات أو الميزات. التحقق بطريقة Walk-Forward إلزامي.
خصوصيات العملات المشفرة. سوق العملات المشفرة شاب وغير مستقر هيكلياً. "السوق الصاعد" لعام 2017 و"السوق الصاعد" لعام 2024 هما ظاهرتان مختلفتان إحصائياً. قد لا يعمم النموذج عبر الدورات.
قراءة إضافية
لمن يريد التعمق:
الأعمال التأسيسية:
- Hamilton, J.D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384. — العمل التأسيسي عن نماذج التبديل الماركوفية
- Guidolin, M., & Timmermann, A. (2007). Asset Allocation under Multivariate Regime Switching. Journal of Economic Dynamics and Control, 31(11), 3503-3544. — التطبيق العملي على تخصيص الأصول
- Ang, A., & Bekaert, G. (2002). Regime Switches in Interest Rates. Journal of Business & Economic Statistics, 20(2), 163-182. — الأنظمة في أسعار الفائدة
الأبحاث الحديثة:
- Gupta, R., Kapoor, S., Gupta, H., & Natesan, S. (2025). A forest of opinions: A multi-model ensemble-HMM voting framework for market regime shift detection and trading. Data Science in Finance and Economics. — نهج التجميع لاكتشاف الأنظمة
- Oelschlager, L., Adam, T., & Michels, R. (2024). fHMM: Hidden Markov Models for Financial Time Series in R. Journal of Statistical Software. — HMM الهرمي للتمويل
- Bitcoin Price Regime Shifts: A Bayesian MCMC and Hidden Markov Model Analysis of Macroeconomic Influence. Mathematics, 2025. — HMM للبيتكوين بنهج بايزي
أدلة عملية:
- QuantStart: Market Regime Detection using Hidden Markov Models in QSTrader
- QuantInsti: Step-by-Step Python Guide for Regime-Specific Trading Using HMM and Random Forest
- hmmlearn documentation
الخلاصة
نماذج ماركوف المخفية ليست رصاصة فضية، بل أداة. أداة مفيدة، مؤسسة رياضياً، بنصف قرن من التاريخ في الإحصاء وثلاثة عقود في المالية.
القيمة الرئيسية لـ HMM في التداول ليست في أنها "تتنبأ بالسوق" (لا أحد يستطيع)، بل في أنها تُضفي الطابع الرسمي على حدس المتداول المتمرس: السوق يمر بمراحل مختلفة، والاستراتيجية يجب أن تتكيف. بدلاً من "أشعر أن السوق هابط الآن" الذاتية، تحصل على "احتمال النظام الهابط 82%، متوسط مدة الدورة الهابطة 16 يوماً، نحن في اليوم الخامس".
هل يجب دمج HMM في مكدس التداول الخاص بك؟ إذا كانت لديك استراتيجيات متعددة لظروف سوقية مختلفة وسئمت من التبديل يدوياً — بالتأكيد نعم. إذا كنت تتداول باستراتيجية واحدة ولا تخطط للتوسع — أجّلها الآن، لكن احتفظ بها في ذهنك.
وتذكر: أفضل نموذج هو الذي يعمل في الإنتاج، وليس الذي يفوز في الاختبار الرجعي.
الاستشهاد: إذا استخدمت مواد هذه المقالة في أبحاثك أو مشاريعك، يُرجى الإشارة إلى:
نماذج ماركوف المخفية في التداول: كيفية تكييف استراتيجيتك مع نظام السوق. marketmaker.cc, 2026. URL: https://marketmaker.cc/ar/blog/post/regime-detection-hmm-adaptive-trading
MarketMaker.cc Team
البحوث والاستراتيجيات الكمية
Read More

ZigBolt: لماذا بنينا نظام Aeron الخاص بنا بلغة Zig وحققنا 20 نانوثانية لكل رسالة

إعادة توازن محفظة ETF تلقائياً: كيف بنينا بوتاً لـ Tinkoff Invest
