1987年,摩根士丹利的一群物理学家通过一种他们谁也无法向银行管理层完全解释清楚的算法进行股票配对交易,一年赚了5000万美元。管理层没有反对。2026年,你可以在加密货币交易所上运行同样的策略——永续合约、7×24小时市场,以及令Nunzio Tartaglia都羡慕的流动性。但有个问题:在互联网时代之前对福特和通用汽车股票有效的方法,在BTC可能一夜暴跌20%、资金费率可能在一个区块内反转的世界里,需要严肃的调整。
本文是加密货币市场统计套利和配对交易的全面解析。从数学理论(协整、Ornstein-Uhlenbeck过程、卡尔曼滤波)到可在真实数据上运行的Python代码。风格偏工程化:公式要讲明白,代码要展示出来,陷阱也不会隐藏。
1. 简史:从耶稣会士到量化交易员
现代形式的统计套利诞生于1980年代中期摩根士丹利的交易台。Nunzio Tartaglia——一位拥有物理学博士学位的前耶稣会神父——组建了一支由数学家、物理学家和计算机科学家组成的团队。目标:发现传统交易员看不到的股价规律。
这个想法简单得令人惊讶。如果可口可乐和百事可乐的股票历史上一起波动(这合乎逻辑——它们卖的是不同颜色的同一种甜水),那么它们价格的偏离就是暂时的异常。买入落后的,卖出领先的,等待回归,锁定利润。这是一种市场中性策略:市场方向与我们无关。
Tartaglia的团队中包括后来改变了整个华尔街的人物:
- David Shaw——后来创立了D.E. Shaw & Co.,最大的量化对冲基金之一
- Peter Muller——创立了PDT Partners,摩根士丹利内部的传奇统计套利团队
- Robert Frey——后来加入了Jim Simons的Renaissance Technologies
该团队像投资银行内部的研究实验室一样运作。自动化程度很高:VAX集群生成信号,通过终端执行交易。在最好的年份(1987-1988),该策略赚了数千万美元。然后连续两年亏损,1989年摩根士丹利关闭了该交易台。
但这个想法已经传播开来。团队的毕业生将配对交易的概念传遍了整个华尔街。Gatev、Goetzmann和Rouwenhorst在2006年发表了经典学术论文"Pairs Trading: Performance of a Relative-Value Arbitrage Rule",表明一个简单的配对交易策略在1962年至2002年间美国股票市场上稳定产生了约11%的年回报率。这是对有效市场假说的有力回应:市场整体上可能是有效的,但特定资产的配对会系统性地偏离均衡。
如今,统计套利是一个管理资产达数千亿美元的行业,而加密货币市场为其提供了特别肥沃的土壤:碎片化的流动性、不成熟的微观结构、全天候交易,以及带有资金费率的永续合约——这是传统市场中根本不存在的工具。
2. 数学基础:相关性是一个陷阱
为什么相关性不起作用
让我们从每个初学者量化交易员都会犯的错误开始:"BTC和ETH的相关系数为0.85,所以可以交易这个配对。"不对。不行。准确地说,可以——但你会亏钱。
相关性衡量的是两个资产收益率之间的线性关系。两个资产可以完美相关,但它们的价格却永远发散。经典例子:两个具有相关增量的随机游走——尽管相关性很高,它们却无限发散。你会开仓等待永远不会到来的"收敛"。
协整:正确的方法
协整是价格序列的属性,而非收益率的属性。两个非平稳序列X(t)和Y(t)如果存在线性组合:
S(t) = Y(t) - β · X(t)
是平稳的——即回归到均值,则称它们是协整的。系数β称为对冲比率(hedge ratio),S(t)称为价差。
直觉:BTC和ETH可以涨到天上或跌到深渊,但如果它们的差值(经过正确缩放)围绕固定水平波动——这就是协整。而这正是我们交易所需要的。
Engle-Granger检验(1987)
两步程序,Robert Engle和Clive Granger因此获得了2003年诺贝尔经济学奖:
第一步。 OLS回归:Y(t) = α + β · X(t) + ε(t)。获得对冲比率β和残差ε(t)。
第二步。 对残差ε(t)进行ADF(Augmented Dickey-Fuller)检验。零假设:ε(t)具有单位根(非平稳)。如果p值 < 0.05,则拒绝H₀——序列是协整的。
重要提示:对于协整检验,不能使用标准的ADF临界值。Engle-Granger临界值是通过蒙特卡罗模拟得到的,考虑了OLS回归中变量之间的依赖性。在statsmodels中,coint()函数正确实现了这一点。
Johansen检验
对于两个以上变量的系统(例如,同时考虑BTC、ETH和SOL),使用Johansen检验。它可以找到系统中的所有协整关系,并允许构建多资产组合。该检验基于VAR(向量自回归)模型,使用两个统计量:迹统计量和最大特征值统计量。
Ornstein-Uhlenbeck过程
如果价差是协整的,其动态可以用Ornstein-Uhlenbeck(OU)过程建模:
dS(t) = θ(μ - S(t))dt + σ dW(t)
其中:
- θ — 均值回归速度
- μ — 长期均值水平
- σ — 波动率
- W(t) — 维纳过程(布朗运动)
从OU过程参数可以计算均值回归半衰期:
t½ = ln(2) / θ
半衰期是一个至关重要的指标。如果t½ = 5天,价差大约在5天内回归均值。如果t½ = 200天,你需要持仓半年才能等到收敛。对于加密货币策略,最佳半衰期为1-30天。更短——太快,手续费吞噬利润。更长——太慢,存在结构性转变的风险。
在实践中,θ通过回归估计:
ΔS(t) = a + b · S(t-1) + ε(t)
其中θ = -b,t½ = -ln(2) / b。
Z-score标准化
为了生成交易信号,对价差进行标准化:
z(t) = (S(t) - μ̂) / σ̂
其中μ̂和σ̂是价差的滚动均值和标准差。Z-score表示价差偏离均值多少个标准差。典型的入场阈值:|z| > 2.0;出场阈值:|z| < 0.5。
3. 加密货币市场的配对选择
BTC-ETH:有时有效的经典组合
BTC和ETH是最明显、流动性最好的配对。收益率相关性稳定在0.7以上。但协整是另一回事。它会出现和消失:
- 在2023年的横盘行情中,BTC/ETH可靠地协整(p值 < 0.01)
- 在2024-2025年的分化期间(BTC因ETF而上涨,ETH落后),协整被打破
- 到2026年初,在ETH ETF推出和ETH/BTC比率恢复后,协整再次稳定
结论:必须持续监测协整。回归参数在滚动窗口上重新计算,如果ADF检验的p值超过阈值,策略会自动关闭。
行业配对
加密货币市场按行业划分非常方便,行业内的配对通常表现出稳定的协整:
| 行业 | 配对示例 | 特征 |
|---|---|---|
| L1区块链 | SOL/AVAX, NEAR/APT | 高流动性,半衰期3-10天 |
| DeFi协议 | AAVE/COMP, UNI/SUSHI | 中等流动性,半衰期5-15天 |
| L2解决方案 | ARB/OP, MATIC/MANTA | 价差波动性高 |
| Meme币 | DOGE/SHIB | 不可预测但有趣(不推荐) |
统计套利最佳配对具有三个特性:(1) 在超过6个月的历史窗口上稳定的协整,(2) 足够的流动性——每个资产日交易量 > 1000万美元,(3) 合理的半衰期——1到30天。
现货 vs 永续合约(基差)
另一类"配对"是同一资产在现货和期货市场上的价格。永续合约价格与现货价格之间的差异(基差)从定义上来说是平稳的:资金费率机制将其压回零附近。这使得基差交易成为加密货币中最可靠的统计套利形式之一。
4. 三种交易方式
A. 基差交易:现货-期货与资金费率套利
加密货币中最"纯粹"的统计套利形式。机制:
- 在现货市场买入资产(例如,1 BTC)
- 在永续合约上开空(1 BTC)
- 如果资金费率为正(多头向空头支付)——你每8小时收取一次资金费
平均资金费率为每8小时0.01%时,约为每天0.03%或年化约11%——没有方向性风险。在牛市期间,资金费率可以升至每8小时0.05-0.1%——这已经是年化55-110%了。
风险:负资金费率(市场反转)、价格急剧上涨时空头仓位被清算(需要保证金缓冲),以及交易所手续费。
截至2026年3月,BTC平均资金费率稳定在每8小时约0.015%——比2024年水平高出约50%。
B. 跨交易所套利
同一币种,两个交易所,不同价格。原因——流动性差异、交易者构成和订单簿更新速度不同。
示例: Binance上BTC:87,175。价差:$25(0.029%)。
策略:在Binance买入,在Bybit卖出。问题:到两个订单都执行时,价差可能已经消失。解决方案:在两个交易所都保持余额并同时执行。
典型手续费:
- Binance:
0.075% taker(折扣后0.05%) - Bybit:~0.03% taker(VIP)
- 总计:~0.08%
这意味着价差必须超过0.08%策略才能盈利。2026年,这样的价差出现在:
- 流动性较低的交易对(山寨币)——经常出现
- 主要交易对(BTC、ETH)——仅在高波动性时刻
- CEX和DEX之间——更频繁,但有MEV风险和滑点
没有托管(co-location),API延迟为10-100毫秒。优化网络下约1毫秒。大多数散户交易者在100-500毫秒范围内操作,这对许多套利策略来说足够,但不足以与机构竞争。
C. 杠杆配对交易
在两种不同资产上使用杠杆的经典配对交易。这是三种策略中最复杂的——也是潜在利润最高的。
以SOL/AVAX配对为例的机制:
- 计算对冲比率β(例如,β = 1.3)
- 当z-score > +2时:做空 SOL,做多 AVAX × β
- 当z-score < -2时:做多 SOL,做空 AVAX × β
- 出场:|z-score| < 0.5 或超时(例如,30天)
每条腿3倍杠杆,平均价差回归2σ → 3σ:
- 每笔交易目标收益:~3-6%
- 平均频率:每对每月2-4笔交易
- 预期年化收益:30-60%(扣除手续费和滑点前)
主要风险:相关性可能在最不合适的时候崩溃(通常在市场崩盘时)。更多内容见第8节。
5. 卡尔曼滤波实现自适应对冲比率
为什么静态对冲比率有问题
经典方法:在历史窗口上通过OLS估计β并固定。问题:β随时间变化。加密市场特别非平稳——叙事转变(DeFi Summer → NFT热潮 → AI代币)改变了资产之间的基本关系。
使用滚动OLS(滚动回归)只是权宜之计。你必须选择窗口长度:太短——噪声;太长——滞后。卡尔曼滤波优雅地解决了这个问题。
状态空间模型
我们将Y(t)和X(t)之间的关系表示为具有时变系数的线性模型:
观测方程:
Y(t) = α(t) + β(t) · X(t) + ε(t), ε(t) ~ N(0, R)
状态方程:
[α(t+1), β(t+1)]ᵀ = [α(t), β(t)]ᵀ + w(t), w(t) ~ N(0, Q)
参数α(t)和β(t)被视为缓慢漂移(随机游走)的隐藏状态。卡尔曼滤波从含噪观测中最优地估计这个隐藏状态。
- R(观测噪声)——观测噪声的方差。R越大,滤波器对新数据的响应越慢。
- Q(状态噪声)——状态噪声的协方差矩阵。Q越大,滤波器适应越快。
Q/R比率决定了滤波器的"平滑度"——类似于在滚动OLS中选择窗口长度,但不会硬截断数据。
相比滚动OLS的优势
使用卡尔曼滤波计算的价差显著更加平稳和均值回归,优于滚动回归的价差。卡尔曼滤波使用所有过去的观测值,并以指数衰减的权重,而不是在固定窗口长度处截断数据。此外,卡尔曼滤波不需要调整"窗口长度"参数——它通过Q和R矩阵自动校准惯性和自适应性之间的平衡。
使用filterpy实现
import numpy as np
from filterpy.kalman import KalmanFilter
def create_kalman_filter(
delta: float = 1e-4,
obs_noise: float = 1.0
) -> KalmanFilter:
"""
创建用于估计自适应对冲比率的卡尔曼滤波器。
delta: 状态噪声方差 (Q = delta * I)。
delta越大 → 适应越快,噪声越多。
obs_noise: 观测噪声方差 (R)。
"""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * delta
kf.R = np.array([[obs_noise]])
return kf
def estimate_hedge_ratio(
prices_y: np.ndarray,
prices_x: np.ndarray,
delta: float = 1e-4,
obs_noise: float = 1.0
) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
"""
使用卡尔曼滤波估计自适应对冲比率。
返回:
alphas: 截距数组 (α)
betas: 对冲比率数组 (β)
spreads: 价差数组 Y - α - β*X
"""
n = len(prices_y)
kf = create_kalman_filter(delta, obs_noise)
alphas = np.zeros(n)
betas = np.zeros(n)
spreads = np.zeros(n)
for t in range(n):
kf.H = np.array([[1.0, prices_x[t]]])
kf.predict()
kf.update(np.array([[prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = prices_y[t] - kf.x[0, 0] - kf.x[1, 0] * prices_x[t]
return alphas, betas, spreads
delta参数是关键。对于高波动性的加密货币配对(meme币、小市值山寨币),使用delta = 1e-3。对于稳定配对(BTC/ETH、SOL/AVAX)——delta = 1e-5。
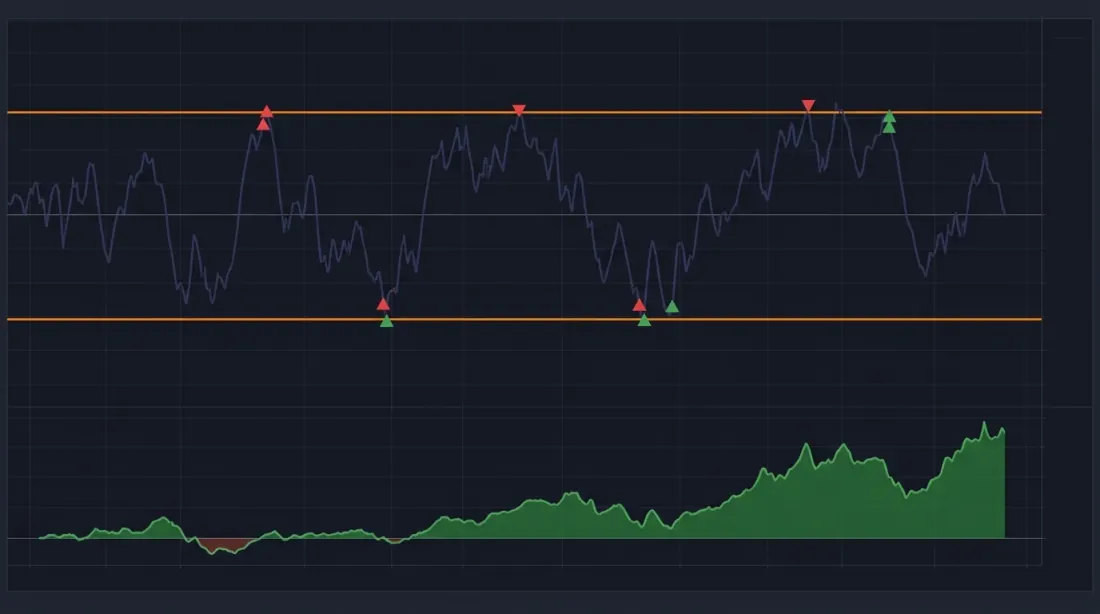
6. 入场和出场信号
Z-Score阈值
基本信号逻辑:
def generate_signals(
spreads: np.ndarray,
lookback: int = 60,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0
) -> np.ndarray:
"""
根据价差z-score生成交易信号。
返回数组: +1(做多价差), -1(做空价差), 0(空仓)
"""
signals = np.zeros(len(spreads))
position = 0
for t in range(lookback, len(spreads)):
window = spreads[t - lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
if position == 0:
if z > entry_z:
position = -1 # 做空价差(做空Y,做多X)
elif z < -entry_z:
position = 1 # 做多价差(做多Y,做空X)
else:
if position == 1 and z > -exit_z:
position = 0
elif position == -1 and z < exit_z:
position = 0
elif abs(z) > stop_z:
position = 0
signals[t] = position
return signals
动量过滤器
纯均值回归信号可以通过过滤器改进:
-
动量过滤器: 如果价差继续发散,不要开仓。等待价差反转后再入场。技术上:z-score已穿越阈值,但当前价差变化已经朝均值方向运动。
-
波动率过滤器: 在高波动性期间提高入场阈值。当市场恐慌时,z-score可能持续数周保持在3σ以上。
-
协整过滤器: 在每次交易前验证协整是否仍然有效(滚动ADF检验)。如果p值 > 0.1——暂停交易。
基于时间的出场
如果持仓时间超过2倍半衰期且价差未回归——强制平仓。如果价差在2倍预期时间内未回归,协整很可能已经破裂,没有继续等待的意义。
7. 回测:正确的方法
前推分析
标准回测(在所有数据上训练 → 在所有数据上测试)对统计套利来说没有用处。回归参数过拟合了数据,结果将过于乐观。
前推方法:
- 将数据分为若干期间:[训练₁ → 测试₁] → [训练₂ → 测试₂] → ...
- 在每个训练期间:估计协整、计算对冲比率、选择z-score阈值
- 在测试期间:使用固定参数进行交易
- 合并所有测试期间进行最终评估
加密货币的典型配置:训练 = 180天,测试 = 30天,步长 = 30天。
交易成本模型
对于加密货币需要考虑:
| 组成部分 | 典型值 | 备注 |
|---|---|---|
| Maker手续费 | 0.02% | 限价单 |
| Taker手续费 | 0.05-0.075% | 市价单 |
| 滑点 | 0.01-0.1% | 取决于流动性 |
| 资金费率 | ±0.01%/8小时 | 期货仓位 |
| 价差(买卖差价) | 0.01-0.05% | 主要交易所 |
进出配对仓位涉及4笔交易(2条腿 × 入场 + 出场)。总成本:每个往返约0.3-0.5%。这意味着每笔交易的平均利润必须超过0.5%才能有正的期望值。
滑点模型
线性模型:slippage = k × (order_size / ADV),其中ADV是平均日交易量。对于加密货币,前10大币种k ≈ 0.1,山寨币k ≈ 0.3-0.5。
更现实的模型是平方根冲击:slippage = k × sqrt(order_size / ADV)。它更好地反映了真实的市场微观结构。
指标
def calculate_metrics(returns: np.ndarray, rf: float = 0.04) -> dict:
"""
计算策略关键指标。
rf: 无风险利率(年化)
"""
daily_rf = rf / 365
excess = returns - daily_rf
ann_return = np.mean(returns) * 365
ann_vol = np.std(returns) * np.sqrt(365)
sharpe = (ann_return - rf) / ann_vol if ann_vol > 0 else 0
cumulative = np.cumprod(1 + returns)
running_max = np.maximum.accumulate(cumulative)
drawdowns = (cumulative - running_max) / running_max
max_dd = np.min(drawdowns)
calmar = ann_return / abs(max_dd) if max_dd != 0 else 0
win_rate = np.mean(returns > 0) if len(returns) > 0 else 0
gains = returns[returns > 0].sum()
losses = abs(returns[returns < 0].sum())
profit_factor = gains / losses if losses > 0 else float('inf')
return {
'annual_return': f'{ann_return:.1%}',
'annual_volatility': f'{ann_vol:.1%}',
'sharpe_ratio': f'{sharpe:.2f}',
'max_drawdown': f'{max_dd:.1%}',
'calmar_ratio': f'{calmar:.2f}',
'win_rate': f'{win_rate:.1%}',
'profit_factor': f'{profit_factor:.2f}',
}
加密统计套利的基准:
- Sharpe > 1.5 — 好策略
- 最大回撤 < 15% — 可接受的风险
- Calmar > 2.0 — 优秀的收益/回撤比
- 盈利因子 > 1.5 — 持续的优势
8. 现实世界的问题
滑点与流动性
在回测中,你以中间价即时入场。现实中——不是这样。在日交易量500万美元的山寨币上,5万美元的订单可能推动价格0.2-0.5%。对于配对策略,这是双倍滑点(两条腿),可能吃掉所有利润。
解决方案:使用限价单(maker,而非taker),将订单分割成部分(TWAP/VWAP),严格限制仓位大小相对于ADV的比例(最多日交易量的1-2%)。
资金费率风险
在基差交易中,你收取资金费率,但它可能变为负数。在2022年12月的熊市中,BTC的资金费率为每8小时-0.02%——如果你持有"多头现货 + 空头永续"仓位,每10万美元仓位你每天要支付60美元。
保护措施:实时监控资金费率,在费率反转时平仓。更高级的方法是交易所间资金费率套利(在低费率交易所做多,在高费率交易所做空)。
危机中的相关性崩溃
2020年3月、2021年5月、2022年11月、2024年8月——在每次加密货币崩盘中,相关性都会被打破。更准确地说,相关性增强(一切同时下跌),但协整被破坏——价差可能飞到10σ而不再回归。
这是配对交易的致命弱点。策略稳定地赚取小额利润,然后在一天内损失大笔资金。经典的"在蒸汽压路机前捡硬币"模式。
保护措施:
- 严格止损: 当z-score > 4σ时平仓
- 杠杆限制: 每条腿最多2-3倍
- VIX/波动率过滤器: 在隐含波动率高时减少仓位
- 分散化: 同时交易10-20个配对,不要把一切押在一个上
资金要求
对于严肃的加密统计套利:
- 基差交易:5万美元起(单一配对,单一交易所)
- 跨交易所套利:10万美元起(两个交易所余额)
- 配对交易组合(10个配对):20万美元起
- 机构级别:100万美元起
金额更少时,手续费和最小仓位限制使策略变得无效。
9. 端到端Python实现
数据获取
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
def fetch_ohlcv(
exchange_id: str,
symbol: str,
timeframe: str = '1h',
days: int = 365
) -> pd.DataFrame:
"""通过ccxt获取OHLCV数据。"""
exchange = getattr(ccxt, exchange_id)({
'enableRateLimit': True,
})
since = int((datetime.now() - timedelta(days=days)).timestamp() * 1000)
all_candles = []
while True:
candles = exchange.fetch_ohlcv(
symbol, timeframe, since=since, limit=1000
)
if not candles:
break
all_candles.extend(candles)
since = candles[-1][0] + 1
if len(candles) < 1000:
break
df = pd.DataFrame(
all_candles,
columns=['timestamp', 'open', 'high', 'low', 'close', 'volume']
)
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
sol = fetch_ohlcv('binance', 'SOL/USDT', '1h', 365)
avax = fetch_ohlcv('binance', 'AVAX/USDT', '1h', 365)
prices = pd.DataFrame({
'SOL': sol['close'],
'AVAX': avax['close']
}).dropna()
协整检验
from statsmodels.tsa.stattools import coint, adfuller
from statsmodels.regression.linear_model import OLS
from statsmodels.tools import add_constant
def test_cointegration(y: np.ndarray, x: np.ndarray) -> dict:
"""
完整的协整检验及诊断。
"""
score, pvalue, crit_values = coint(y, x)
x_const = add_constant(x)
model = OLS(y, x_const).fit()
alpha, beta = model.params
spread = y - alpha - beta * x
adf_stat, adf_pvalue, _, _, adf_crit, _ = adfuller(spread, maxlag=20)
spread_lag = spread[:-1]
spread_diff = np.diff(spread)
spread_lag_const = add_constant(spread_lag)
hl_model = OLS(spread_diff, spread_lag_const).fit()
theta = -hl_model.params[1]
half_life = np.log(2) / theta if theta > 0 else np.inf
return {
'coint_pvalue': pvalue,
'cointegrated': pvalue < 0.05,
'hedge_ratio': beta,
'intercept': alpha,
'adf_statistic': adf_stat,
'adf_pvalue': adf_pvalue,
'half_life_hours': half_life,
'half_life_days': half_life / 24,
'spread_mean': np.mean(spread),
'spread_std': np.std(spread),
}
result = test_cointegration(
prices['SOL'].values,
prices['AVAX'].values
)
print(f"协整: {result['cointegrated']} "
f"(p值: {result['coint_pvalue']:.4f})")
print(f"对冲比率: {result['hedge_ratio']:.4f}")
print(f"半衰期: {result['half_life_days']:.1f} 天")
卡尔曼滤波 + 回测器
from filterpy.kalman import KalmanFilter
class PairsBacktester:
"""
使用卡尔曼滤波的配对交易前推回测器。
"""
def __init__(
self,
prices_y: np.ndarray,
prices_x: np.ndarray,
kalman_delta: float = 1e-4,
obs_noise: float = 1.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0,
lookback: int = 60,
fee_rate: float = 0.001, # 每条腿0.1%往返
slippage_rate: float = 0.0005, # 每条腿0.05%滑点
):
self.prices_y = prices_y
self.prices_x = prices_x
self.n = len(prices_y)
self.kalman_delta = kalman_delta
self.obs_noise = obs_noise
self.entry_z = entry_z
self.exit_z = exit_z
self.stop_z = stop_z
self.lookback = lookback
self.fee_rate = fee_rate
self.slippage_rate = slippage_rate
def run(self) -> pd.DataFrame:
"""运行回测。返回包含结果的DataFrame。"""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * self.kalman_delta
kf.R = np.array([[self.obs_noise]])
alphas = np.zeros(self.n)
betas = np.zeros(self.n)
spreads = np.zeros(self.n)
for t in range(self.n):
kf.H = np.array([[1.0, self.prices_x[t]]])
kf.predict()
kf.update(np.array([[self.prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = (
self.prices_y[t] - kf.x[0, 0]
- kf.x[1, 0] * self.prices_x[t]
)
positions = np.zeros(self.n)
z_scores = np.zeros(self.n)
position = 0
for t in range(self.lookback, self.n):
window = spreads[t - self.lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
z_scores[t] = z
if position == 0:
if z > self.entry_z:
position = -1
elif z < -self.entry_z:
position = 1
else:
if position == 1 and z > -self.exit_z:
position = 0
elif position == -1 and z < self.exit_z:
position = 0
elif abs(z) > self.stop_z:
position = 0
positions[t] = position
spread_returns = np.diff(spreads) / np.abs(
spreads[:-1] + 1e-10
)
pnl = np.zeros(self.n)
for t in range(1, self.n):
if positions[t - 1] != 0:
raw_return = positions[t - 1] * spread_returns[t - 1]
pnl[t] = raw_return
if positions[t] != positions[t - 1]:
total_cost = 2 * (self.fee_rate + self.slippage_rate)
pnl[t] -= total_cost
return pd.DataFrame({
'price_y': self.prices_y,
'price_x': self.prices_x,
'alpha': alphas,
'beta': betas,
'spread': spreads,
'z_score': z_scores,
'position': positions,
'pnl': pnl,
'cumulative_pnl': np.cumsum(pnl),
})
bt = PairsBacktester(
prices_y=prices['SOL'].values,
prices_x=prices['AVAX'].values,
kalman_delta=1e-4,
entry_z=2.0,
exit_z=0.5,
stop_z=4.0,
lookback=60,
fee_rate=0.001,
slippage_rate=0.0005,
)
results = bt.run()
daily_pnl = results['pnl'].resample('D').sum() if hasattr(
results.index, 'freq'
) else results['pnl']
metrics = calculate_metrics(daily_pnl.values)
for k, v in metrics.items():
print(f'{k}: {v}')
实盘交易骨架
import ccxt
import asyncio
import logging
logger = logging.getLogger(__name__)
class LivePairsTrader:
"""
实盘配对交易的最小骨架。
生产环境需要:添加重试逻辑、监控、
告警、余额对账。
"""
def __init__(
self,
exchange_id: str,
symbol_y: str,
symbol_x: str,
api_key: str,
secret: str,
position_size_usd: float = 1000.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
):
self.exchange = getattr(ccxt, exchange_id)({
'apiKey': api_key,
'secret': secret,
'enableRateLimit': True,
})
self.symbol_y = symbol_y
self.symbol_x = symbol_x
self.position_size = position_size_usd
self.entry_z = entry_z
self.exit_z = exit_z
self.position = 0 # +1, -1, 0
self.kf = create_kalman_filter(delta=1e-4)
self.spread_history = []
async def update(self):
"""一个更新周期。"""
ticker_y = self.exchange.fetch_ticker(self.symbol_y)
ticker_x = self.exchange.fetch_ticker(self.symbol_x)
price_y = ticker_y['last']
price_x = ticker_x['last']
self.kf.H = np.array([[1.0, price_x]])
self.kf.predict()
self.kf.update(np.array([[price_y]]))
alpha = self.kf.x[0, 0]
beta = self.kf.x[1, 0]
spread = price_y - alpha - beta * price_x
self.spread_history.append(spread)
if len(self.spread_history) < 60:
logger.info(f"Warming up: {len(self.spread_history)}/60")
return
window = np.array(self.spread_history[-60:])
z = (spread - np.mean(window)) / np.std(window)
logger.info(
f"β={beta:.4f} spread={spread:.4f} z={z:.2f} "
f"pos={self.position}"
)
new_position = self.position
if self.position == 0:
if z > self.entry_z:
new_position = -1
elif z < -self.entry_z:
new_position = 1
else:
if self.position == 1 and z > -self.exit_z:
new_position = 0
elif self.position == -1 and z < self.exit_z:
new_position = 0
if new_position != self.position:
await self._execute_trade(
new_position, price_y, price_x, beta
)
self.position = new_position
async def _execute_trade(
self, target: int, price_y: float, price_x: float,
beta: float
):
"""执行配对交易。"""
if target == 0:
logger.info("Closing position")
elif target == 1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Long spread: buy {size_y:.4f} {self.symbol_y}, "
f"sell {size_x:.4f} {self.symbol_x}"
)
elif target == -1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Short spread: sell {size_y:.4f} {self.symbol_y}, "
f"buy {size_x:.4f} {self.symbol_x}"
)
async def run_loop(self, interval_seconds: int = 60):
"""主循环。"""
logger.info(
f"Starting live trading: "
f"{self.symbol_y}/{self.symbol_x}"
)
while True:
try:
await self.update()
except Exception as e:
logger.error(f"Error in update: {e}")
await asyncio.sleep(interval_seconds)
结语
统计套利不是圣杯。它是一门手艺。在"我知道什么是协整"和"我有一个稳定运行的策略"之间,隔着一道工程细节的鸿沟:正确的数据处理、正确的前推回测、现实的滑点模型、实时监控。
加密货币市场仍然为统计套利提供了比传统市场更多的机会——碎片化的流动性、不成熟的市场基础设施,以及永续合约与资金费率等独特工具,创造了在纽约证券交易所早已被套利到零的低效率。
但窗口正在关闭。机构玩家正在进入加密市场,套利资本在增长(据估计,2025年加密交易所上的套利资本增长了215%),利润空间在压缩。如果你打算在加密货币中进行统计套利——最好现在就开始。
本文中的所有代码都可以作为起点。不要在没有认真测试的情况下将其投入生产。请记住:唯一保证有效的策略是风险管理。
关键学术文献:
- Engle, R.F. & Granger, C.W.J. (1987). "Co-Integration and Error Correction: Representation, Estimation, and Testing". Econometrica, 55(2), 251-276.
- Gatev, E., Goetzmann, W.N. & Rouwenhorst, K.G. (2006). "Pairs Trading: Performance of a Relative-Value Arbitrage Rule". The Review of Financial Studies, 19(3), 797-827.
- Vidyamurthy, G. (2004). Pairs Trading: Quantitative Methods and Analysis. Wiley.
- Avellaneda, M. & Lee, J.H. (2010). "Statistical Arbitrage in the US Equities Market". Quantitative Finance, 10(7), 761-782.
- Frontiers (2026). "Deep learning-based pairs trading: real-time forecasting of co-integrated cryptocurrency pairs". Frontiers in Applied Mathematics and Statistics.
实用库:
- statsmodels — 协整、ADF、OLS
- filterpy — 卡尔曼滤波
- ccxt — 100+交易所统一API
- arbitragelab — 配对交易专用库(OU、Kalman、copulas)
MarketMaker.cc Team
量化研究与策略