LLM Alpha挖掘:如何从财报电话会议和金融文档中提取交易信号

华尔街有个笑话:"财报电话会议中最有价值的信息不是CEO说了什么,而是他怎么说的。"当蒂姆·库克说"我们持谨慎乐观态度"而不是去年的"我们非常满意"——这不是语言游戏,而是价值数亿美元的信号。
数十年来,量化基金一直试图系统化地提取这些信号。最初,他们用词典统计"积极"和"消极"词汇的频率。后来引入了BERT。而现在我们拥有GPT-4o、Claude和开源LLM,它们能以令研究者自己都感到惊讶的精度解析企业话术的微妙之处。
让我们深入了解如何构建一个完整的财报电话会议交易信号提取流水线——从获取会议记录到回测累计异常收益。
为什么财报电话会议是Alpha的金矿
盈余公告后漂移:不死的市场异象
1968年,Ball和Brown发现了一个奇怪的现象:在季度业绩公布后,股票会在"惊喜"方向上继续漂移60-90天。他们将其命名为盈余公告后漂移(Post-Earnings Announcement Drift,PEAD)。自那以后已过去半个多世纪,发表了数百篇论文,从十几个角度解释了这一异象——但它仍然有效。
PEAD是金融史上最持久的市场异象之一。"买入正面惊喜,卖出负面惊喜"的组合策略历史上产生了10-25%的年化超额收益。为什么市场至今未将其套利消除?原因有几个:
- 投资者注意力有限——当200家公司在同一周公布业绩时,物理上不可能阅读所有会议记录
- 认知复杂性——财报电话会议持续45-60分钟,关键信号可能隐藏在Q&A环节第38分钟的某一句话中
- 语言模糊性——CFO说"we are navigating headwinds",不了解上下文就无法判断这是温和的警告还是标准的套话
这正是LLM登场的时刻。我们第一次拥有了一个工具,能在一个晚上处理500份会议记录,同时捕捉到即使经验丰富的分析师也可能遗漏的细微之处。
PEAD.txt:文本比数字更重要
费城联储的研究人员(Meursault、Liang、Routledge、Scanlon)发表了PEAD.txt论文,颠覆了人们对文本信息价值的认知。他们构建了标准盈余惊喜的文本类似物——SUE.txt——完全不使用利润的数值。
结果如何?SUE.txt产生的漂移是经典PEAD的两倍。更重要的是:近年来,当基于数值惊喜的经典PEAD几乎消失时(市场已经学会了),文本漂移仍然显著。市场学会了快速处理数字,但在文本解读方面仍然不够。
这是支持基于NLP方法分析财报电话会议的根本论据。
从情感到语义:方法的演进

第一代:词袋模型和词典(2000-2015)
一切始于Loughran-McDonald词典(2011)——一份将词汇标注为"积极"、"消极"、"不确定"和"诉讼相关"的词表。其理念在简洁中彰显优雅:统计10-K报告中消极词汇的比例,然后据此交易。
问题是?"outstanding"在金融语境中更常意味着"未偿还的债务"而非"出色的业绩"。Risk Management中的"risk"不是消极信号,而是流程描述。标准NLP情感词典在金融文本上的表现令人尴尬。
Loughran和McDonald创建了专业词典,情况有所改善,但根本问题依然存在:词袋模型不理解上下文。"We did not fail to meet expectations"——这里有两个"消极"词汇,但含义是积极的。
第二代:FinBERT和Transformer(2019-2023)
2019年,Dogu Araci发布了FinBERT——在路透社TRC2金融文本上微调的BERT。结果令人印象深刻:在Financial PhraseBank数据集上比最先进水平提高了14个百分点。FinBERT理解上下文:"outstanding"与"debt"相邻——消极,与"performance"相邻——积极。
但FinBERT有一个限制:512个token的上下文窗口。财报电话会议有8000-12000个词。分块并平均情感意味着丢失段落间的语义关联。CEO可能以乐观开场,然后在Q&A中不经意提到供应链问题。FinBERT独立分析每个片段,看不到这种对比。
第三代:长上下文LLM(2023至今)
GPT-4、Claude、Gemini拥有128K-1M token的上下文窗口,改变了游戏规则。现在可以一次加载整个会议记录,并提出需要理解全文才能回答的问题。
关键研究——Lopez-Lira & Tang(2023)《Can ChatGPT Forecast Stock Price Movements?》。在50000+条标题上,GPT-4在预测市场初始反应方向上显示出~90%的命中率,并且显著预测了后续漂移,特别是对于小盘股和负面新闻。而早期模型(GPT-1、GPT-2、BERT)没有表现出这种能力——预测能力作为大模型的涌现属性而出现。
BloombergGPT(2023)——在Bloomberg金融语料库上训练的500亿参数模型——在金融NER、新闻分类和情感分析方面取得了改进。FinGPT——其开源替代方案——通过以数据为中心的方法和RAG在金融情感任务上达到89%的准确率。
使用GPT-4配合Chain-of-Thought和In-Context Learning分析S&P 100的MarketSenseAI,在15个月的测试中显示出10-30%的超额alpha和高达72%的累计收益。是的,这些数字需要谨慎对待(回测≠实盘交易),但趋势是明确的。
数据流水线:数据从哪来
SEC EDGAR:官方来源
对于美股,主要来源是SEC EDGAR。财报电话会议通常不直接提交,但相关文件可获取:
- 8-K文件(Item 2.02——经营业绩)——包含业绩的新闻稿,通常包括附有会议记录的exhibit 99
- 10-Q / 10-K——季度和年度报告,包含管理层讨论与分析(MD&A)——也是宝贵的文本来源
- DEF 14A——包含管理层薪酬信息的代理声明
from edgar import Company
company = Company("AAPL")
filings = company.get_filings(form="8-K")
for filing in filings.latest(10):
if "2.02" in str(filing.items):
doc = filing.document()
text = doc.text() # 包含附件的完整文本
print(f"{filing.filing_date}: {len(text)} chars")
Seeking Alpha和商业API
财报电话会议记录是独立的产品。Seeking Alpha历来是主要的免费来源,但现在限制了访问。商业选项:
- Seeking Alpha Premium API——带有说话人标注的完整记录
- AlphaVantage Earnings API——有限制的免费层
- Financial Modeling Prep——会议记录+基本面数据
- Earnings Call Edge / Motley Fool Transcripts——替代来源
加密货币:治理电话会议和DAO提案
这里更有意思。大型DeFi协议举行相当于财报电话会议的活动:
- Uniswap——治理电话会议、社区电话会议,YouTube录播
- Aave——月度社区电话会议+治理论坛提案
- MakerDAO——治理电话会议+详细的论坛讨论
- Compound——带有详细讨论的治理提案
加密电话会议的记录通常没有结构化。解决方案——使用OpenAI的Whisper转录YouTube录播:
import openai
from yt_dlp import YoutubeDL
def transcribe_governance_call(youtube_url: str) -> str:
"""从YouTube下载音频并通过Whisper转录。"""
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '64', # 低码率对语音足够
}],
'outtmpl': '/tmp/governance_call.%(ext)s',
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([youtube_url])
client = openai.OpenAI()
with open("/tmp/governance_call.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="verbose_json",
timestamp_granularities=["segment"]
)
return transcript.text
通过Whisper API转录的成本:0.36。自托管方案——Whisper Large-v3 Turbo在现代GPU上约17秒内转录60分钟的文件(216倍实时速度)。
LLM提示策略:从简单到工业级

策略1:直接情感分析(弱)
最简单的方法——直接询问模型:
"Is this earnings call positive or negative for the stock price?"
这有效吗?令人惊讶的是,有效。Lopez-Lira & Tang表明,即使如此原始的提示也能产生统计显著的预测。但存在问题:
- 二元输出——丢失了梯度。"灾难"和"轻微失望"得到相同的标签
- 缺乏解释——不清楚模型基于什么做出决策
- 不稳定性——重复运行可能给出不同的答案
策略2:带Chain-of-Thought的结构化提取(强)
思路:不是提取单一数字,而是提取结构化的信号集合,强制模型解释每一步。
from pydantic import BaseModel, Field
from openai import OpenAI
from enum import Enum
from typing import Optional
class SentimentLevel(str, Enum):
VERY_BEARISH = "very_bearish"
BEARISH = "bearish"
NEUTRAL = "neutral"
BULLISH = "bullish"
VERY_BULLISH = "very_bullish"
class GuidanceSurprise(BaseModel):
"""前瞻性指引与一致预期的偏差。"""
revenue_guidance_vs_consensus: Optional[float] = Field(
None, description="营收指引与一致预期的偏差百分比"
)
margin_guidance_direction: Optional[str] = Field(
None, description="expanding / stable / contracting"
)
key_quote: str = Field(
description="包含指引的原文引用"
)
reasoning: str = Field(
description="CoT:为什么这个指引很重要"
)
class ConfidenceMetrics(BaseModel):
"""管理层信心指标。"""
hedge_word_count: int = Field(
description="对冲词数量:'approximately'、'potentially'、'subject to'"
)
forward_looking_ratio: float = Field(
description="前瞻性声明占总声明的比例"
)
q_and_a_evasion_count: int = Field(
description="CEO/CFO给出含糊回答的问题数量"
)
ceo_vs_cfo_sentiment_delta: float = Field(
description="CEO和CFO情感差异(-1到1)。分歧是危险信号"
)
class CompetitiveIntelligence(BaseModel):
"""竞争对手提及和市场定位。"""
competitors_mentioned: list[str] = Field(
description="提及的竞争对手列表"
)
market_share_claims: list[str] = Field(
description="市场份额声明"
)
new_product_signals: list[str] = Field(
description="新产品/服务信号"
)
class ManagementSignals(BaseModel):
"""管理层信号。"""
turnover_risk: SentimentLevel = Field(
description="关键管理层变动风险"
)
tone_shift_from_previous: Optional[str] = Field(
None, description="与上季度相比语气如何变化"
)
insider_language_flags: list[str] = Field(
description="标记性短语:'exploring strategic alternatives'、'right-sizing'等"
)
class EarningsCallAnalysis(BaseModel):
"""完整的财报电话会议分析。"""
ticker: str
quarter: str
overall_sentiment: SentimentLevel
sentiment_score: float = Field(description="从 -1.0 到 1.0")
guidance_surprise: GuidanceSurprise
confidence_metrics: ConfidenceMetrics
competitive_intel: CompetitiveIntelligence
management_signals: ManagementSignals
key_risks: list[str]
key_catalysts: list[str]
one_line_summary: str
def analyze_earnings_call(transcript: str, ticker: str, quarter: str) -> EarningsCallAnalysis:
"""
从财报电话会议中提取结构化信号。
成本:每次调用约$0.15-0.30(GPT-4o,约10K token输入)。
"""
client = OpenAI()
system_prompt = """You are a senior equity research analyst with 20 years of experience.
Analyze the following earnings call transcript and extract structured trading signals.
IMPORTANT INSTRUCTIONS:
1. Use Chain-of-Thought reasoning for each field — explain WHY before giving the value
2. Focus on DEVIATIONS from expectations, not absolute statements
3. Pay special attention to Q&A section — management is less scripted there
4. Compare management's language to typical corporate hedging baseline
5. Flag any "strategic alternatives", "right-sizing", or other euphemisms
6. Score sentiment relative to market expectations, not in absolute terms
HEDGE WORDS TO COUNT: approximately, potentially, subject to, may, might,
could, uncertain, challenging, headwinds, navigate, prudent, cautious,
evolving, dynamic, unprecedented, transitional"""
completion = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Ticker: {ticker}\nQuarter: {quarter}\n\n{transcript}"}
],
response_format=EarningsCallAnalysis,
temperature=0.1, # 低温度以保证可重复性
)
return completion.choices[0].message.parsed
注意几个关键点:
Pydantic模式——OpenAI结构化输出保证100%符合模式。不再出现"sorry, I cannot parse the JSON"。每个字段都有description,作为特定分析维度的迷你提示。
模式中的Chain-of-Thought——reasoning和key_quote字段迫使模型"展示工作过程"。这不仅提高了质量(模型被迫在做出判断前找到具体引用),还为监管机构创建了审计追踪。
Temperature 0.1——我们不需要创造力。我们需要可重复性。Temperature为0时,模型有时会"卡"在某些模式上,0.1是最佳折衷。
策略3:带历史示例的Few-Shot
更强大的方法——给模型提供过去的财报电话会议示例及实际市场反应:
few_shot_examples = """
EXAMPLE 1:
Transcript excerpt: "We are cautiously optimistic about the second half...
While we continue to navigate macro headwinds, our pipeline remains robust."
Actual market reaction: -3.2% (next day)
Analysis: Despite surface-level positivity, "cautiously optimistic" is a
DOWNGRADE from previous quarter's "very confident". Five hedge words in
two sentences. Market read through the hedging.
EXAMPLE 2:
Transcript excerpt: "Frankly, demand has exceeded our ability to supply.
We're expediting CapEx to address this."
Actual market reaction: +7.8% (next day)
Analysis: "Frankly" signals genuine surprise even from management.
Accelerated CapEx on demand = strong confidence. No hedging language.
"""
Few-shot示例帮助模型校准:它学到"cautiously optimistic"在华尔街语言中不是积极的——而是温和的消极信号。没有示例,LLM可能会字面理解词语。
四种信号类型
1. 业绩指引惊喜
最直接的信号。公司提供下一季度/年的预测(guidance),市场对偏离一致预期的程度做出反应。即使管理层表达模糊,LLM也能提取指引:
- "We expect revenues in the range of..."——直接指引,容易解析
- "We feel comfortable with current Street estimates"——隐含确认一致预期
- "There are puts and takes relative to consensus"——隐含的风险信号
LLM能理解这三种表述;正则表达式只能理解第一种。
2. 信心指标:对冲词密度
这是我最喜欢的信号,因为它是反直觉的。本质在于:管理者是受过法律训练、拥有偏执法律部门的人。当一切顺利时,他们允许自己具体化。当问题酝酿时——他们开始对冲。
需要跟踪的指标:
| 指标 | 描述 | 看空信号 |
|---|---|---|
| 对冲词密度 | 每1000词中对冲词的比例 | > 每1000词15个 |
| 确定性比率 | "will/expect"与"may/could"的比值 | < 1.5 |
| Q&A回避率 | 未直接回答的问题百分比 | > 30% |
| CEO/CFO差异 | CEO和CFO语气的分歧度 | > 0.3([-1, 1]量表) |
最后一点特别有趣。CEO是讲故事的人——他的工作是描绘美好的画面。CFO是对审计师负责的人。当CEO说"transformative growth ahead"而CFO立即插入"while maintaining disciplined cost management"——这种分歧信号着内部紧张。
3. 竞争情报
LLM可以从会议记录中提取竞争对手的提及,即使管理层避免直接点名。"The largest player in the market"——如果GPT-4了解行业,这并不是什么谜。
交易信号:如果A公司在财报电话会议中以负面语境提到竞争对手B("we're taking share from..."),这不仅是A的信号(做多),也是B的信号(做空)。配对交易。
4. 管理层变动信号
标志管理层变更或战略转向的短语:
- "Exploring strategic alternatives"——可能出售公司
- "Right-sizing our operations"——大规模裁员
- "The board has initiated a comprehensive review"——CEO即将离任
- "We're bringing in fresh perspectives"——现任团队失败了
这些短语中的每一个都与后续价格走势有统计显著的相关性。LLM可以零误报地检测它们——因为它理解上下文,而正则表达式可能在产品线描述中误捕"strategic alternatives"。
回测:事件研究方法论
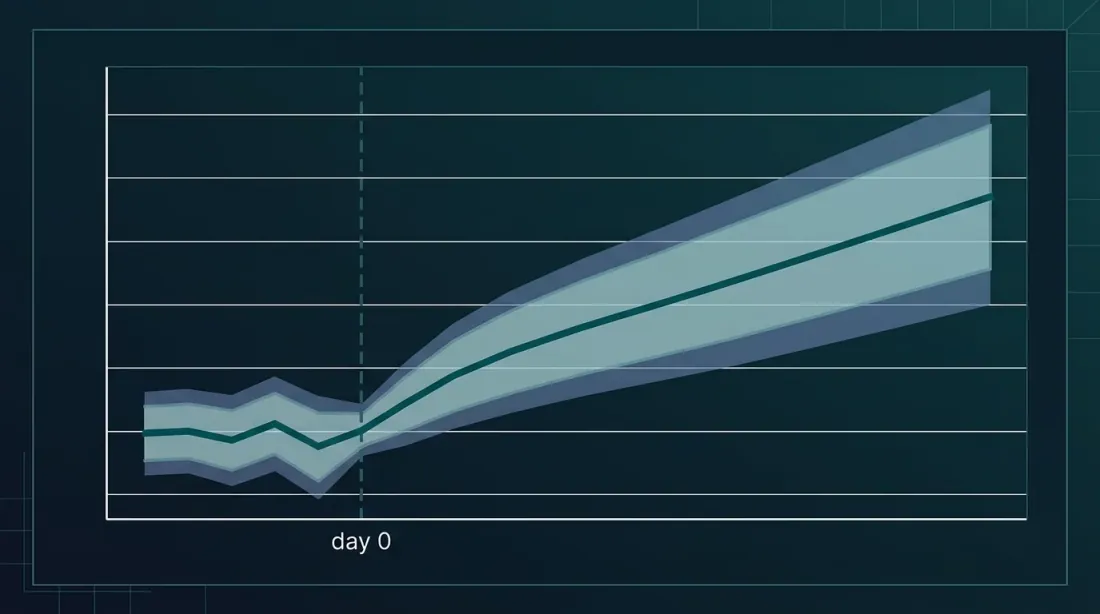
我们生成了信号——很好。但它们有效吗?标准验证方法是计算累计异常收益(CAR)的事件研究。
方法论
- 定义事件——财报电话会议日期
- 估计窗口——事件前[-250, -30]个交易日,用于估计"正常"收益
- 事件窗口——事件前后[-1, +60]天
- 计算正常收益——通过市场模型:
- 异常收益——实际收益与"正常"收益的差值
- CAR——事件窗口内异常收益的累计和
import numpy as np
import pandas as pd
from scipy import stats
from dataclasses import dataclass
@dataclass
class EventStudyResult:
car: np.ndarray # 按天的累计异常收益
t_stats: np.ndarray # 每天的t统计量
avg_car_3d: float # CAR[-1, +1]
avg_car_30d: float # CAR[-1, +30]
avg_car_60d: float # CAR[-1, +60]
p_value_3d: float
p_value_30d: float
n_events: int
def run_event_study(
returns: pd.DataFrame, # 股票日收益率(columns = ticker)
market_returns: pd.Series, # 市场指数日收益率
events: pd.DataFrame, # DataFrame,columns: [ticker, date, signal_score]
estimation_window: int = 220,
gap: int = 30,
event_window: tuple = (-1, 60),
) -> EventStudyResult:
"""
事件研究,用于评估LLM信号的预测能力。
按signal_score排序事件,构建多空组合,
计算CAR并测试统计显著性。
"""
all_cars = []
for _, event in events.iterrows():
ticker = event['ticker']
event_date = event['date']
if ticker not in returns.columns:
continue
try:
event_idx = returns.index.get_loc(event_date, method='ffill')
except KeyError:
continue
est_start = event_idx - estimation_window - gap
est_end = event_idx - gap
if est_start < 0:
continue
y = returns.iloc[est_start:est_end][ticker].values
x = market_returns.iloc[est_start:est_end].values
mask = ~(np.isnan(y) | np.isnan(x))
if mask.sum() < 60: # 最少60个观测值
continue
y_clean, x_clean = y[mask], x[mask]
slope, intercept, _, _, _ = stats.linregress(x_clean, y_clean)
residual_std = np.std(y_clean - (intercept + slope * x_clean))
ev_start = event_idx + event_window[0]
ev_end = event_idx + event_window[1] + 1
if ev_end > len(returns):
continue
actual = returns.iloc[ev_start:ev_end][ticker].values
market = market_returns.iloc[ev_start:ev_end].values
expected = intercept + slope * market
ar = actual - expected
car = np.cumsum(ar)
all_cars.append(car)
if not all_cars:
raise ValueError("No valid events found")
min_len = min(len(c) for c in all_cars)
all_cars = np.array([c[:min_len] for c in all_cars])
mean_car = np.mean(all_cars, axis=0)
std_car = np.std(all_cars, axis=0) / np.sqrt(len(all_cars))
t_stats = mean_car / (std_car + 1e-10)
offset = -event_window[0] # 到事件日期的偏移
car_3d = mean_car[min(offset + 1, min_len - 1)] if min_len > offset + 1 else mean_car[-1]
car_30d = mean_car[min(offset + 30, min_len - 1)] if min_len > offset + 30 else mean_car[-1]
car_60d = mean_car[min(offset + 60, min_len - 1)] if min_len > offset + 60 else mean_car[-1]
n = len(all_cars)
p_3d = 2 * (1 - stats.t.cdf(abs(car_3d / (np.std([c[min(offset+1, min_len-1)] for c in all_cars]) / np.sqrt(n) + 1e-10)), df=n-1))
p_30d = 2 * (1 - stats.t.cdf(abs(car_30d / (np.std([c[min(offset+30, min_len-1)] for c in all_cars]) / np.sqrt(n) + 1e-10)), df=n-1))
return EventStudyResult(
car=mean_car,
t_stats=t_stats,
avg_car_3d=car_3d,
avg_car_30d=car_30d,
avg_car_60d=car_60d,
p_value_3d=p_3d,
p_value_30d=p_30d,
n_events=n,
)
def backtest_llm_signals(
llm_signals: pd.DataFrame, # [ticker, date, sentiment_score]
returns: pd.DataFrame,
market_returns: pd.Series,
):
"""回测:做多顶部五分位信号,做空底部五分位。"""
llm_signals['quintile'] = pd.qcut(
llm_signals['sentiment_score'], 5, labels=[1, 2, 3, 4, 5]
)
long_events = llm_signals[llm_signals['quintile'] == 5].copy()
short_events = llm_signals[llm_signals['quintile'] == 1].copy()
long_result = run_event_study(returns, market_returns, long_events)
short_result = run_event_study(returns, market_returns, short_events)
print(f"LONG portfolio (top quintile LLM sentiment):")
print(f" CAR[0,+3]: {long_result.avg_car_3d:+.2%} (p={long_result.p_value_3d:.4f})")
print(f" CAR[0,+30]: {long_result.avg_car_30d:+.2%} (p={long_result.p_value_30d:.4f})")
print(f" N events: {long_result.n_events}")
print(f"\nSHORT portfolio (bottom quintile LLM sentiment):")
print(f" CAR[0,+3]: {short_result.avg_car_3d:+.2%} (p={short_result.p_value_3d:.4f})")
print(f" CAR[0,+30]: {short_result.avg_car_30d:+.2%} (p={short_result.p_value_30d:.4f})")
print(f" N events: {short_result.n_events}")
ls_3d = long_result.avg_car_3d - short_result.avg_car_3d
ls_30d = long_result.avg_car_30d - short_result.avg_car_30d
print(f"\nLONG-SHORT spread:")
print(f" CAR[0,+3]: {ls_3d:+.2%}")
print(f" CAR[0,+30]: {ls_30d:+.2%}")
预期结果
基于现有研究,LLM信号的现实CAR:
| 窗口 | 多头组合 | 空头组合 | 多空价差 |
|---|---|---|---|
| [0, +1] | +0.8% — +1.5% | -0.5% — -1.2% | 1.3% — 2.7% |
| [0, +30] | +1.5% — +3.0% | -1.0% — -2.5% | 2.5% — 5.5% |
| [0, +60] | +2.0% — +4.0% | -1.5% — -3.5% | 3.5% — 7.5% |
关键指标是统计显著性。当p < 0.01且N > 200个事件时,可以说信号是稳健的。当p > 0.05——可能是随机噪声。
生产部署:从Jupyter到生产环境
实时流水线架构
YouTube/Audio Stream
│
▼
┌─────────────────┐ ┌──────────────────┐
│ Whisper │───▶│ Transcript │
│ Transcription │ │ Buffer │
│ (streaming) │ │ (Redis Stream) │
└─────────────────┘ └──────────────────┘
│
┌─────────┴─────────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Real-time │ │ Full-call │
│ Chunk Anal. │ │ Analysis │
│ (every 5min) │ │ (after call │
│ │ │ ends) │
└──────────────┘ └──────────────┘
│ │
▼ ▼
┌──────────────────────────────┐
│ Signal Aggregator │
│ (confidence-weighted merge) │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ Trading Engine │
│ (position sizing, risk mgmt)│
└──────────────────────────────┘
成本分析:处理一次财报电话会议要多少钱
让我们分析生产环境中处理一次财报电话会议的经济账:
| 组件 | 成本 | 延迟 |
|---|---|---|
| Whisper API转录(60分钟) | $0.36 | ~17秒(Turbo) |
| GPT-4o结构化提取 | $0.15-0.30 | ~8-15秒 |
| GPT-4o实时分块分析(x12) | $1.80-3.60 | 每次~5秒 |
| RAG存储的Embedding | $0.01 | <1秒 |
| 合计(完整流水线) | $2.30-4.30 | ~30秒 |
等等,之前说的是每次$30-50。这些数字从哪来?取决于模型和方法:
- 经济方案(GPT-4o-mini,单次处理):$0.50-1.00
- 标准方案(GPT-4o,结构化提取+分块分析):$2-5
- 高级方案(GPT-4o,多次处理、交叉验证、历史比较):$15-30
- 对冲基金级别(多模型+人工审核+实时流处理):$30-50+
对于交易500只股票的量化基金来说,处理一个财报季(6周内约2000次电话会议)的成本在标准方案下为10,000。当每个仓位的平均alpha为1-3%时——投资回报率是天文数字。
延迟:毫秒级的竞赛
在高频交易的世界中,延迟就是一切。但对于基于财报的策略,情况不同:
- 财报电话会议持续45-60分钟——你有时间
- PEAD持续60天——不需要在第一秒就入场
- 主要的定价偏离发生在电话会议结束后的前30分钟
最优策略是两阶段的:
- 阶段1(实时):在电话会议期间每5分钟分析一个片段,形成初步信号
- 阶段2(会后):电话会议结束后2-5分钟内完成完整转录分析
阶段1比等待电话会议结束的市场参与者提前5-10分钟获得优势。对于中盘股来说,这就足够了。
扩展到加密货币:DeFi治理和DAO提案
加密市场是LLM alpha挖掘的理想试验场。原因如下:
- 机构参与者较少——意味着有更多低效率可以利用
- 治理=财报电话会议——DAO决策直接影响代币经济学
- 7x24小时市场——可以立即交易反应
- 公开数据——所有提案和投票都在链上
加密事件分析类型
治理提案(Aave、Compound、Uniswap)
提案改变协议参数——利率、抵押因子、手续费开关。LLM可以评估经济影响:
crypto_analysis_prompt = """Analyze this DeFi governance proposal.
Extract:
1. Economic impact on token holders (positive/negative/neutral)
2. TVL impact estimate (increase/decrease/stable + magnitude)
3. Competitive positioning vs other protocols
4. Risk factors introduced by the proposal
5. Historical precedent (similar proposals in other protocols)
6. Likely voting outcome based on forum discussion sentiment
Proposal: {proposal_text}
Forum discussion: {discussion_text}
"""
协议更新公告
当Uniswap宣布带hooks的v4,或Aave推出GHO时——这相当于传统金融中的产品发布。LLM可以评估叙事动量和技术重要性。
财库报告
大型DAO拥有数亿美元的财库。季度财库报告是财报的直接类比。运营期限、消耗率、多元化——所有这些都适合LLM分析。
加密信号的特殊性
与传统金融不同,在加密领域:
- 链上数据确认或反驳叙事——可以将治理电话会议上说的内容与协议的实际指标(TVL、交易量、活跃用户)进行交叉比对
- 巨鲸钱包如同内幕交易——治理讨论后大钱包的转移往往先于投票
- 通过CT(Crypto Twitter)放大情绪——治理电话会议的信号可以被Twitter叙事放大或压制
陷阱和局限性
幻觉:当模型编造数字
LLM可能"提取"出转录中不存在的指引。在分析对冲词密度时尤其危险:模型可能比实际数多或少地计算词汇。
解决方案:两阶段验证。LLM提取,确定性代码验证。对于对冲词——正则表达式与LLM评估并行计数。偏差 > 20%——标记为需要人工审核。
import re
HEDGE_WORDS = [
r'\bapproximately\b', r'\bpotentially\b', r'\bsubject to\b',
r'\bmay\b', r'\bmight\b', r'\bcould\b', r'\buncertain\b',
r'\bchallenging\b', r'\bheadwinds\b', r'\bnavigate\b',
r'\bprudent\b', r'\bcautious\b', r'\bevolving\b',
r'\bdynamic\b', r'\bunprecedented\b', r'\btransitional\b',
]
def verify_hedge_count(text: str, llm_count: int) -> dict:
"""确定性验证LLM的对冲词计数。"""
regex_count = sum(
len(re.findall(pattern, text, re.IGNORECASE))
for pattern in HEDGE_WORDS
)
deviation = abs(llm_count - regex_count) / (regex_count + 1)
return {
"llm_count": llm_count,
"regex_count": regex_count,
"deviation": deviation,
"needs_review": deviation > 0.2,
}
上下文窗口限制
即使128K个token也可能不够,如果你想输入:
- 当前转录(~10K token)
- 用于比较的上季度转录(~10K)
- 分析师一致预期(~2K)
- Few-shot示例(~3K)
- System prompt(~1K)
总计~26K——可以容纳。但如果加上10-K文件(~80-120K token)作为上下文——已经处于边缘。解决方案:使用RAG从长文档中检索相关片段。
偏差和系统性错误
LLM在历史数据上训练,其中某些短语与特定结果相关联。但市场会适应:
- 如果所有人都开始用GPT-4统计对冲词,管理者会改变他们的语言
- 模型可能高估训练数据中模式的重要性(幸存者偏差)
- 企业语言在进化:"synergies"在2010年意味着一种东西,在2026年意味着另一种
拥挤交易风险
如果50家量化基金使用相同的GPT-4分析相同的转录——信号会衰减。类比:当所有人都开始根据数值惊喜交易PEAD时,异象缩小了。文本信号也会发生同样的事情,但有延迟:
- 当前(2026)——很少有人系统性地将LLM用于财报电话会议。Alpha显著
- 2-3年后——广泛采用,alpha下降
- 5年后——基础LLM信号成为大宗商品,优势仅存在于定制模型和独特数据中
这是alpha信号的标准生命周期。趁还来得及享受吧。
代替结论:行动策略
如果你想开始使用LLM进行财报电话会议分析,以下是最小可行计划:
- 从免费数据开始——SEC EDGAR + EdgarTools获取8-K/10-Q文件
- 使用结构化提取——通过OpenAI结构化输出的Pydantic模式
- 通过事件研究回测——历史数据上的CAR,最少200个事件
- 添加few-shot示例——5-10个标注示例能显著提升质量
- 确定性验证——LLM提取,正则表达式验证,人工审计
- 从中盘股开始——更多alpha,与大型基金的竞争更少
- 扩展到加密货币——治理电话会议和DAO提案是未开发的领域
记住量化分析的首要法则:如果一个信号好得不像真的——再检查一遍。LLM创造了理解的幻觉,但背后是统计模式匹配。强大的工具——但是工具,不是神谕。
参考文献
-
Ball, R., Brown, P. (1968). An Empirical Evaluation of Accounting Income Numbers. Journal of Accounting Research, 6(2), 159-178. — 首次发现PEAD。
-
Bernard, V.L., Thomas, J.K. (1989). Post-Earnings-Announcement Drift: Delayed Price Response or Risk Premium? Journal of Accounting Research, 27, 1-36. — 经典PEAD论文。
-
Loughran, T., McDonald, B. (2011). When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. Journal of Finance, 66(1), 35-65. — 金融情感词典。
-
Araci, D. (2019). FinBERT: Financial Sentiment Analysis with Pre-trained Language Models. arXiv:1908.10063. — 金融NLP的BERT,比SOTA高14pp。
-
Wu, S. et al. (2023). BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564. — Bloomberg的500亿参数模型。
-
Yang, H. et al. (2023). FinGPT: Open-Source Financial Large Language Models. arXiv:2306.06031. — BloombergGPT的开源替代,89%准确率。
-
Lopez-Lira, A., Tang, Y. (2023). Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models. arXiv:2304.07619. — GPT-4以~90%命中率预测收益。
-
Meursault, V., Liang, P.J., Routledge, B., Scanlon, M.M. (2023). PEAD.txt: Post-Earnings-Announcement Drift Using Text. Journal of Financial and Quantitative Analysis. — 文本PEAD是数值PEAD的两倍。
-
Fatouros, G. et al. (2024). Can Large Language Models Beat Wall Street? Evaluating GPT-4's Impact on Financial Decision-Making with MarketSenseAI. Neural Computing and Applications. — S&P 100上10-30%超额alpha的GPT-4框架。
-
Chen, Y. et al. (2025). GPT-Signal: Generative AI for Semi-automated Feature Engineering in the Alpha Research Process. arXiv:2410.18448. — 通过LLM自动生成交易信号。
-
Zhang, X. et al. (2025). Can LLMs Hit Moving Targets? Tracking Evolving Signals in Corporate Disclosures. arXiv:2510.03195. — 企业披露中"移动目标"的检测。
-
Chen, Z. et al. (2025). Large Language Models in Equity Markets: Applications, Techniques, and Insights. Frontiers in Artificial Intelligence. — 金融领域84项LLM研究综述。
本文仅供教育目的,不构成投资建议。此处描述的任何交易策略在使用真实资本之前,都需要经过彻底的回测和风险管理。
MarketMaker.cc Team
量化研究与策略