암호화폐 시장의 통계적 차익거래와 페어 트레이딩: 공적분에서 칼만 필터까지
1987년, 모건 스탠리의 물리학자 그룹은 은행 경영진에게 완전히 설명할 수 없는 알고리즘을 사용해 주식 페어 트레이딩으로 1년에 5천만 달러를 벌었다. 경영진은 이의를 제기하지 않았다. 2026년, 당신은 암호화폐 거래소에서 같은 아이디어를 실행할 수 있다 — 무기한 선물, 24/7 시장, 그리고 Nunzio Tartaglia도 부러워할 유동성이 있다. 하지만 주의할 점이 있다: 인터넷 이전 시대에 포드와 GM 주식에서 작동했던 것은, BTC가 하룻밤에 20% 폭락하고 펀딩 비율이 한 블록 만에 뒤집힐 수 있는 세계에서는 본격적인 적응이 필요하다.
이 글은 암호화폐 시장을 위한 통계적 차익거래와 페어 트레이딩의 완전한 분석이다. 수학 이론(공적분, Ornstein-Uhlenbeck 과정, 칼만 필터)에서 실제 데이터로 실행할 수 있는 Python 코드까지. 스타일은 엔지니어링 지향적이다: 수식을 설명하고, 코드를 보여주며, 함정을 숨기지 않는다.
1. 간략한 역사: 예수회 사제에서 퀀트까지
현대적 형태의 통계적 차익거래는 1980년대 중반 모건 스탠리의 트레이딩 데스크에서 탄생했다. Nunzio Tartaglia — 물리학 박사학위를 가진 전 예수회 사제 — 가 수학자, 물리학자, 컴퓨터 과학자로 구성된 팀을 모았다. 목표: 전통적 트레이더가 볼 수 없는 주가 패턴을 찾는 것.
아이디어는 놀라울 정도로 단순했다. 코카콜라와 펩시 주가가 역사적으로 함께 움직인다면(당연하다 — 같은 달콤한 물을 다른 색으로 팔고 있으니), 가격의 괴리는 일시적 이상 현상이다. 뒤처진 것을 사고, 앞서가는 것을 팔고, 수렴을 기다리고, 이익을 확정한다. 시장 중립 전략: 시장 방향은 중요하지 않다.
Tartaglia의 팀에는 나중에 월스트리트 전체를 바꾸게 될 인물들이 포함되어 있었다:
- David Shaw — 이후 최대 퀀트 헤지펀드 중 하나인 D.E. Shaw & Co.를 설립
- Peter Muller — 모건 스탠리 내부의 전설적인 통계적 차익거래 그룹 PDT Partners를 설립
- Robert Frey — 이후 Jim Simons의 Renaissance Technologies에 합류
그룹은 투자은행 내부의 연구소처럼 운영되었다. 자동화는 최첨단이었다: VAX 클러스터가 시그널을 생성하고, 터미널을 통해 실행되었다. 최고의 해(1987-1988)에 이 전략은 수천만 달러를 벌었다. 그 후 2년 연속 손실이 발생했고, 1989년 모건 스탠리는 데스크를 폐쇄했다.
하지만 아이디어는 이미 퍼져나갔다. 그룹 출신들이 페어 트레이딩 개념을 월스트리트 전체에 전파했다. Gatev, Goetzmann, Rouwenhorst는 2006년 고전적 학술 논문 "Pairs Trading: Performance of a Relative-Value Arbitrage Rule"을 발표하여, 단순한 페어 트레이딩 전략이 1962년부터 2002년까지 미국 주식시장에서 연간 약 11%의 수익률을 안정적으로 달성했음을 보여주었다. 이는 효율적 시장 가설에 대한 설득력 있는 반론이었다: 시장 전체는 효율적일 수 있지만, 특정 자산의 페어는 체계적으로 균형에서 이탈한다.
오늘날 통계적 차익거래는 수천억 달러의 운용자산을 가진 산업이며, 암호화폐 시장은 특히 비옥한 토양을 제공한다: 분산된 유동성, 미성숙한 미시구조, 24시간 거래, 그리고 펀딩 비율이 있는 무기한 선물 — 전통 시장에는 존재하지 않는 상품이다.
2. 수학적 기초: 상관관계는 함정이다
상관관계가 작동하지 않는 이유
초보 퀀트 두 명 중 한 명이 저지르는 실수부터 시작하자: "BTC와 ETH의 상관계수가 0.85이니 페어를 거래할 수 있다." 아니다. 할 수 없다. 정확히는, 할 수 있지만 — 돈을 잃게 된다.
상관관계는 두 자산의 수익률 간의 선형 관계를 측정한다. 두 자산이 완벽하게 상관되어 있어도 가격은 영원히 발산할 수 있다. 고전적 예시: 상관된 증분을 가진 두 랜덤워크 — 높은 상관관계에도 불구하고 무한히 발산한다. "수렴"을 기대하며 포지션을 열지만, 수렴은 오지 않는다.
공적분: 올바른 접근법
공적분은 수익률이 아닌 가격 시계열의 속성이다. 두 비정상 시계열 X(t)와 Y(t)는 선형 결합:
S(t) = Y(t) - β · X(t)
이 정상적(stationary)일 때 — 즉 평균으로 회귀할 때 — 공적분이라 한다. 계수 β는 헤지 비율(hedge ratio), S(t)는 스프레드라 한다.
직관: BTC와 ETH가 달까지 오르거나 나락으로 떨어져도, 그들의 차이(적절히 스케일링된)가 고정된 수준 주위에서 진동한다면 — 그것이 공적분이다. 그리고 그것이 바로 거래에 필요한 것이다.
Engle-Granger 검정 (1987)
Robert Engle과 Clive Granger가 2003년 노벨 경제학상을 수상한 2단계 절차:
1단계. OLS 회귀: Y(t) = α + β · X(t) + ε(t). 헤지 비율 β와 잔차 ε(t)를 얻는다.
2단계. 잔차 ε(t)에 대한 ADF(Augmented Dickey-Fuller) 검정. 귀무가설: ε(t)는 단위근을 가짐(비정상). p-value < 0.05이면 H₀를 기각 — 시계열은 공적분이다.
중요: 공적분 검정에는 표준 ADF 임계값을 사용할 수 없다. Engle-Granger 임계값은 몬테카를로 시뮬레이션으로 도출되었으며 OLS 회귀에서 변수 간 의존성을 고려한다. statsmodels에서는 coint() 함수에서 올바르게 구현되어 있다.
Johansen 검정
두 개 이상의 변수 시스템(예: BTC, ETH, SOL 동시 분석)에는 Johansen 검정이 사용된다. 시스템 내의 모든 공적분 관계를 찾고 다중 자산 포트폴리오를 구축할 수 있다. 검정은 VAR(벡터 자기회귀) 모델을 기반으로 하며, 두 가지 기준을 사용한다: 추적 통계량과 최대 고유값 통계량.
Ornstein-Uhlenbeck 과정
스프레드가 공적분이라면, 그 동학은 Ornstein-Uhlenbeck(OU) 과정으로 모델링할 수 있다:
dS(t) = θ(μ - S(t))dt + σ dW(t)
여기서:
- θ — 평균 회귀 속도
- μ — 장기 평균 수준
- σ — 변동성
- W(t) — 위너 과정(브라운 운동)
OU 과정 파라미터로부터 평균 회귀 반감기를 계산한다:
t½ = ln(2) / θ
반감기는 매우 중요한 지표이다. t½ = 5일이면, 스프레드는 약 5일 만에 평균으로 회귀한다. t½ = 200일이면, 수렴을 기다리며 반년 동안 포지션을 유지해야 한다. 암호화폐 전략의 최적 반감기는 1-30일이다. 더 짧으면 — 너무 빠르고 수수료가 수익을 잡아먹는다. 더 길면 — 너무 느리고 구조적 레짐 변화 위험이 있다.
실무에서 θ는 회귀로 추정된다:
ΔS(t) = a + b · S(t-1) + ε(t)
여기서 θ = -b, t½ = -ln(2) / b.
Z-score 정규화
거래 시그널 생성을 위해 스프레드를 정규화한다:
z(t) = (S(t) - μ̂) / σ̂
여기서 μ̂와 σ̂는 스프레드의 이동 평균과 표준편차이다. Z-score는 스프레드가 평균에서 몇 표준편차 이탈했는지를 보여준다. 일반적인 진입 임계값: |z| > 2.0; 청산 임계값: |z| < 0.5.
3. 암호화폐 시장의 페어 선택
BTC-ETH: (때때로) 작동하는 클래식
BTC와 ETH는 가장 명확하고 유동성이 높은 페어이다. 수익률 상관관계는 안정적으로 0.7 이상이다. 하지만 공적분은 다른 문제다. 그것은 나타났다 사라진다:
- 2023년 횡보장에서 BTC/ETH는 확실히 공적분이었다 (p-value < 0.01)
- 2024-2025년 괴리 기간(BTC가 ETF로 상승, ETH가 뒤처짐)에는 공적분이 무너졌다
- 2026년 초, ETH ETF 출시와 ETH/BTC 비율 회복 후 공적분이 다시 안정화되었다
결론: 공적분은 지속적으로 모니터링해야 한다. 회귀 파라미터는 이동 윈도우에서 재계산되며, ADF 검정의 p-value가 임계값을 초과하면 전략이 자동으로 중단된다.
섹터 페어
암호화폐 시장은 섹터별로 편리하게 분류되며, 섹터 내 페어는 종종 안정적인 공적분을 보인다:
| 섹터 | 페어 예시 | 특성 |
|---|---|---|
| L1 블록체인 | SOL/AVAX, NEAR/APT | 높은 유동성, 반감기 3-10일 |
| DeFi 프로토콜 | AAVE/COMP, UNI/SUSHI | 중간 유동성, 반감기 5-15일 |
| L2 솔루션 | ARB/OP, MATIC/MANTA | 높은 스프레드 변동성 |
| 밈코인 | DOGE/SHIB | 예측 불가하지만 재미있음 (비추천) |
통계적 차익거래에 가장 좋은 페어는 세 가지 특성을 갖는다: (1) 6개월 이상의 기간에서 안정적인 공적분, (2) 충분한 유동성 — 자산당 일일 거래량 > 1,000만 달러, (3) 적절한 반감기 — 1일에서 30일.
현물 vs 무기한 선물 (베이시스)
별도의 "페어" 카테고리는 현물과 선물 시장에서의 동일한 자산이다. 무기한 선물 가격과 현물 가격의 차이(베이시스)는 정의상 정상적이다: 펀딩 비율 메커니즘이 이를 다시 0으로 압축한다. 이로 인해 베이시스 트레이딩은 암호화폐에서 가장 신뢰할 수 있는 통계적 차익거래 형태 중 하나이다.
4. 세 가지 거래 접근법
A. 베이시스 트레이딩: 현물-선물과 펀딩 비율 캐리
암호화폐에서 가장 "순수한" 통계적 차익거래 형태. 메커니즘:
- 현물에서 자산을 매수 (예: 1 BTC)
- 무기한 선물에서 숏 진입 (1 BTC)
- 펀딩 비율이 양수이면 (롱이 숏에 지불) — 8시간마다 펀딩을 받는다
평균 펀딩 비율이 8시간마다 0.01%일 때, 이는 하루 약 0.03% 또는 연 약 11%이다 — 방향 위험 없이. 상승장에서는 펀딩 비율이 8시간마다 0.05-0.1%까지 상승할 수 있다 — 이미 연 55-110%이다.
위험: 음의 펀딩(시장 반전), 급격한 가격 상승 시 숏 포지션 청산(증거금 버퍼 필요), 거래소 수수료.
2026년 3월 기준, BTC 평균 펀딩 비율은 8시간당 약 0.015%로 안정화되었다 — 2024년 수준보다 약 50% 높다.
B. 크로스 거래소 차익거래
같은 코인, 두 거래소, 다른 가격. 원인 — 유동성 차이, 트레이더 구성, 호가창 업데이트 속도의 차이.
예시: 바이낸스 BTC: 87,175. 스프레드: $25 (0.029%).
전략: 바이낸스에서 매수, 바이비트에서 매도. 문제: 두 주문이 모두 체결될 때까지 스프레드가 사라질 수 있다. 해결책: 양쪽 거래소에 잔고를 유지하고 동시에 실행한다.
일반적인 수수료:
- 바이낸스: 테이커 ~0.075% (할인 시 ~0.05%)
- 바이비트: 테이커 ~0.03% (VIP)
- 합계: ~0.08%
이는 전략이 수익을 내려면 스프레드가 0.08%를 초과해야 함을 의미한다. 2026년에 이런 스프레드가 발생하는 경우:
- 유동성이 낮은 페어(알트코인) — 정기적으로
- 주요 페어(BTC, ETH) — 고변동성 순간에만
- CEX와 DEX 사이 — 더 빈번하지만, MEV 위험과 슬리피지 있음
코로케이션 없이 API 지연은 10-100ms이다. 최적화된 네트워크에서는 약 1ms. 대부분의 개인 트레이더는 100-500ms 범위에서 작동하며, 이는 많은 차익거래 전략에 충분하지만 기관과 경쟁하기에는 부족하다.
C. 레버리지 페어 트레이딩
두 가지 다른 자산에 레버리지를 사용한 클래식 페어 트레이딩. 세 가지 전략 중 가장 복잡하며 — 가장 잠재적 수익이 높다.
SOL/AVAX 페어를 예로 든 메커니즘:
- 헤지 비율 β 계산 (예: β = 1.3)
- z-score > +2일 때: SOL 숏, AVAX × β 롱
- z-score < -2일 때: SOL 롱, AVAX × β 숏
- 청산: |z-score| < 0.5 또는 타임아웃 (예: 30일)
각 레그에 3배 레버리지, 평균 스프레드 회귀 2σ → 3σ:
- 거래당 목표 수익률: ~3-6%
- 평균 빈도: 페어당 월 2-4회 거래
- 기대 연간 수익률: 30-60% (수수료와 슬리피지 차감 전)
주요 위험: 상관관계가 최악의 순간에 무너질 수 있다 (보통 시장 폭락 시). 이에 대한 자세한 내용은 8절 참조.
5. 적응형 헤지 비율을 위한 칼만 필터
정적 헤지 비율이 문제인 이유
고전적 접근법: 과거 윈도우에서 OLS로 β를 추정하고 고정. 문제: β는 시간에 따라 변한다. 암호화폐 시장은 특히 비정상적이다 — 내러티브 전환(DeFi Summer → NFT 열풍 → AI 토큰)이 자산 간 근본적 관계를 바꾼다.
롤링 OLS(이동 회귀)의 사용은 반쪽짜리 대책이다. 윈도우 길이를 선택해야 한다: 너무 짧으면 — 노이즈, 너무 길면 — 지연. 칼만 필터는 이 문제를 우아하게 해결한다.
상태공간 모델
Y(t)와 X(t) 사이의 관계를 시변 계수를 가진 선형 모델로 표현한다:
관측 방정식:
Y(t) = α(t) + β(t) · X(t) + ε(t), ε(t) ~ N(0, R)
상태 방정식:
[α(t+1), β(t+1)]ᵀ = [α(t), β(t)]ᵀ + w(t), w(t) ~ N(0, Q)
파라미터 α(t)와 β(t)는 천천히 드리프트하는(랜덤워크) 은닉 상태로 취급된다. 칼만 필터는 노이즈가 있는 관측으로부터 이 은닉 상태를 최적으로 추정한다.
- R (관측 노이즈) — 관측 노이즈의 분산. R이 클수록 필터의 새 데이터에 대한 반응이 느려진다.
- Q (상태 노이즈) — 상태 노이즈의 공분산 행렬. Q가 클수록 필터의 적응이 빨라진다.
Q/R 비율은 필터의 "평활도"를 결정한다 — 롤링 OLS에서 윈도우 길이를 선택하는 것과 유사하지만, 데이터의 하드 절삭 없이.
롤링 OLS 대비 장점
칼만 필터로 계산된 스프레드는 롤링 회귀의 스프레드보다 훨씬 더 정상적이고 평균 회귀적이다. 칼만 필터는 고정 윈도우 길이에서 데이터를 절삭하는 대신 지수적으로 감소하는 가중치로 모든 과거 관측을 사용한다. 또한, 칼만 필터는 "윈도우 길이" 파라미터 조정이 필요 없다 — 대신 Q와 R 행렬을 통해 관성과 적응성 사이의 균형을 자동으로 보정한다.
filterpy로 구현
import numpy as np
from filterpy.kalman import KalmanFilter
def create_kalman_filter(
delta: float = 1e-4,
obs_noise: float = 1.0
) -> KalmanFilter:
"""
적응형 헤지 비율 추정을 위한 칼만 필터 생성.
delta: 상태 노이즈 분산 (Q = delta * I).
delta가 클수록 → 빠른 적응, 많은 노이즈.
obs_noise: 관측 노이즈 분산 (R).
"""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * delta
kf.R = np.array([[obs_noise]])
return kf
def estimate_hedge_ratio(
prices_y: np.ndarray,
prices_x: np.ndarray,
delta: float = 1e-4,
obs_noise: float = 1.0
) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
"""
칼만 필터로 적응형 헤지 비율 추정.
반환값:
alphas: 절편 배열 (α)
betas: 헤지 비율 배열 (β)
spreads: 스프레드 배열 Y - α - β*X
"""
n = len(prices_y)
kf = create_kalman_filter(delta, obs_noise)
alphas = np.zeros(n)
betas = np.zeros(n)
spreads = np.zeros(n)
for t in range(n):
kf.H = np.array([[1.0, prices_x[t]]])
kf.predict()
kf.update(np.array([[prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = prices_y[t] - kf.x[0, 0] - kf.x[1, 0] * prices_x[t]
return alphas, betas, spreads
delta 파라미터가 핵심이다. 높은 변동성의 암호화폐 페어(밈코인, 소형 알트)에는 delta = 1e-3를 사용한다. 안정적인 페어(BTC/ETH, SOL/AVAX)에는 delta = 1e-5.
6. 진입 및 청산 시그널
Z-Score 임계값
기본 시그널 로직:
def generate_signals(
spreads: np.ndarray,
lookback: int = 60,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0
) -> np.ndarray:
"""
스프레드 z-score 기반 거래 시그널 생성.
반환 배열: +1 (스프레드 롱), -1 (스프레드 숏), 0 (무포지션)
"""
signals = np.zeros(len(spreads))
position = 0
for t in range(lookback, len(spreads)):
window = spreads[t - lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
if position == 0:
if z > entry_z:
position = -1 # 스프레드 숏 (Y 숏, X 롱)
elif z < -entry_z:
position = 1 # 스프레드 롱 (Y 롱, X 숏)
else:
if position == 1 and z > -exit_z:
position = 0
elif position == -1 and z < exit_z:
position = 0
elif abs(z) > stop_z:
position = 0
signals[t] = position
return signals
모멘텀 필터
순수 평균 회귀 시그널은 필터로 개선할 수 있다:
-
모멘텀 필터: 스프레드가 계속 발산하면 포지션을 열지 않는다. 진입 전 스프레드의 반전을 기다린다. 기술적으로: z-score가 임계값을 넘었지만, 현재 스프레드 변화가 이미 평균 방향으로 향하고 있다.
-
변동성 필터: 고변동성 기간에는 진입 임계값을 높인다. 시장이 패닉일 때 z-score는 수주간 3σ 이상에 머물 수 있다.
-
공적분 필터: 각 거래 전에 공적분이 여전히 유효한지 확인한다 (롤링 ADF 검정). p-value > 0.1이면 거래를 중단한다.
시간 기반 청산
포지션이 반감기의 2배 이상 열려 있고 스프레드가 회귀하지 않으면 — 강제 청산한다. 스프레드가 예상 시간의 2배 내에 회귀하지 않으면, 공적분이 무너졌을 가능성이 높고 기다릴 이유가 없다.
7. 백테스팅: 올바르게 하기
워크포워드 분석
표준 백테스트(모든 데이터로 학습 → 모든 데이터로 테스트)는 통계적 차익거래에 무용지물이다. 회귀 파라미터가 데이터에 과적합되고, 결과는 낙관적이 된다.
워크포워드 접근법:
- 데이터를 기간으로 분할: [학습₁ → 테스트₁] → [학습₂ → 테스트₂] → ...
- 각 학습 기간에서: 공적분 추정, 헤지 비율 계산, z-score 임계값 선택
- 테스트 기간에서: 고정 파라미터로 거래
- 모든 테스트 기간을 결합하여 최종 평가
암호화폐의 일반적 설정: 학습 = 180일, 테스트 = 30일, 스텝 = 30일.
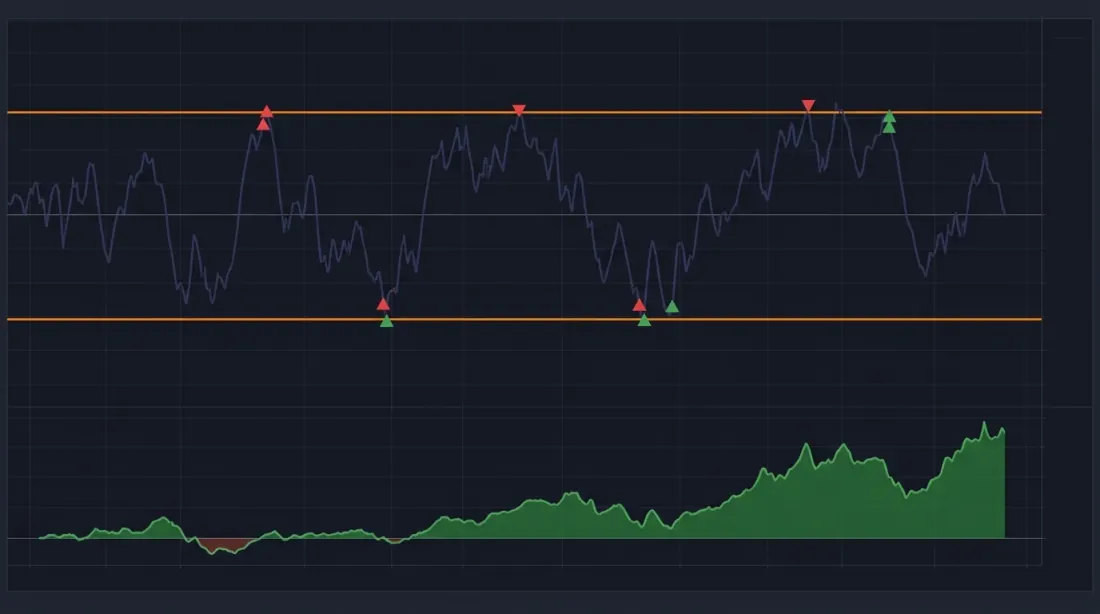
거래 비용 모델
암호화폐에서 고려해야 할 사항:
| 구성 요소 | 일반적 값 | 비고 |
|---|---|---|
| 메이커 수수료 | 0.02% | 지정가 주문 |
| 테이커 수수료 | 0.05-0.075% | 시장가 주문 |
| 슬리피지 | 0.01-0.1% | 유동성에 따라 다름 |
| 펀딩 비율 | ±0.01%/8시간 | 선물 포지션 |
| 스프레드 (매수-매도) | 0.01-0.05% | 주요 거래소 |
페어 포지션 진입과 청산에는 4건의 거래가 발생한다 (2레그 × 진입 + 청산). 총 비용: 왕복당 약 0.3-0.5%. 이는 양의 기대값을 가지려면 거래당 평균 수익이 0.5%를 초과해야 함을 의미한다.
슬리피지 모델
선형 모델: slippage = k × (order_size / ADV), 여기서 ADV는 평균 일일 거래량. 암호화폐에서 상위 10개 코인은 k ≈ 0.1, 알트코인은 k ≈ 0.3-0.5.
더 현실적인 모델은 제곱근 임팩트: slippage = k × sqrt(order_size / ADV). 실제 시장 미시구조를 더 잘 반영한다.
지표
def calculate_metrics(returns: np.ndarray, rf: float = 0.04) -> dict:
"""
전략의 주요 지표 계산.
rf: 무위험 이자율 (연율)
"""
daily_rf = rf / 365
excess = returns - daily_rf
ann_return = np.mean(returns) * 365
ann_vol = np.std(returns) * np.sqrt(365)
sharpe = (ann_return - rf) / ann_vol if ann_vol > 0 else 0
cumulative = np.cumprod(1 + returns)
running_max = np.maximum.accumulate(cumulative)
drawdowns = (cumulative - running_max) / running_max
max_dd = np.min(drawdowns)
calmar = ann_return / abs(max_dd) if max_dd != 0 else 0
win_rate = np.mean(returns > 0) if len(returns) > 0 else 0
gains = returns[returns > 0].sum()
losses = abs(returns[returns < 0].sum())
profit_factor = gains / losses if losses > 0 else float('inf')
return {
'annual_return': f'{ann_return:.1%}',
'annual_volatility': f'{ann_vol:.1%}',
'sharpe_ratio': f'{sharpe:.2f}',
'max_drawdown': f'{max_dd:.1%}',
'calmar_ratio': f'{calmar:.2f}',
'win_rate': f'{win_rate:.1%}',
'profit_factor': f'{profit_factor:.2f}',
}
암호화폐 통계적 차익거래 벤치마크:
- 샤프 비율 > 1.5 — 좋은 전략
- 최대 손실폭 < 15% — 허용 가능한 위험
- 칼마 비율 > 2.0 — 우수한 수익/손실폭 비율
- 수익 팩터 > 1.5 — 지속적인 우위
8. 현실 세계의 문제
슬리피지와 유동성
백테스트에서는 중간가로 즉시 진입한다. 현실에서는 — 그렇지 않다. 일일 거래량 500만 달러의 알트코인에서 5만 달러 주문은 가격을 0.2-0.5% 움직일 수 있다. 페어 전략에서 이는 두 배의 슬리피지(두 레그)이며, 모든 수익을 잡아먹을 수 있다.
해결책: 지정가 주문 사용(테이커가 아닌 메이커), 주문 분할(TWAP/VWAP), ADV 대비 포지션 크기를 엄격히 제한(일일 거래량의 최대 1-2%).
펀딩 비율 위험
베이시스 트레이딩에서 펀딩 비율을 받지만, 음수가 될 수 있다. 2022년 12월 약세장에서 BTC 펀딩 비율은 8시간마다 -0.02%였다 — "롱 현물 + 숏 무기한 선물" 포지션을 보유하고 있었다면, 10만 달러 포지션에 대해 하루 60달러를 지불하고 있었다.
방어: 펀딩 비율을 실시간으로 모니터링하고 비율이 반전되면 포지션을 청산한다. 더 고급 접근법은 거래소 간 펀딩 비율 차익거래(낮은 펀딩의 거래소에서 롱, 높은 펀딩의 거래소에서 숏).
위기 시 상관관계 붕괴
2020년 3월, 2021년 5월, 2022년 11월, 2024년 8월 — 모든 암호화폐 폭락에서 상관관계가 무너진다. 더 정확히는, 상관관계는 강화된다(모든 것이 함께 하락), 하지만 공적분은 파괴된다 — 스프레드가 10σ까지 날아가 돌아오지 않을 수 있다.
이것이 페어 트레이딩의 아킬레스건이다. 전략은 꾸준히 작은 금액을 벌다가, 하루에 큰 금액을 잃는다. 전형적인 "증기 롤러 앞에서 동전 줍기" 프로파일.
방어:
- 엄격한 손절: z-score > 4σ에서 포지션 청산
- 레버리지 제한: 각 레그 최대 2-3배
- VIX/변동성 필터: 내재 변동성이 높을 때 포지션 크기 축소
- 분산화: 동시에 10-20 페어 거래, 하나에 올인하지 않기
자본 요건
본격적인 암호화폐 통계적 차익거래를 위해:
- 베이시스 트레이딩: 5만 달러부터 (한 페어, 한 거래소)
- 크로스 거래소 차익거래: 10만 달러부터 (두 거래소 잔고)
- 페어 트레이딩 포트폴리오 (10페어): 20만 달러부터
- 기관 수준: 100만 달러부터
더 적은 금액에서는 수수료와 최소 포지션 크기로 인해 전략이 비효율적이 된다.
9. 엔드투엔드 Python 구현
데이터 수집
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
def fetch_ohlcv(
exchange_id: str,
symbol: str,
timeframe: str = '1h',
days: int = 365
) -> pd.DataFrame:
"""ccxt를 통한 OHLCV 데이터 수집."""
exchange = getattr(ccxt, exchange_id)({
'enableRateLimit': True,
})
since = int((datetime.now() - timedelta(days=days)).timestamp() * 1000)
all_candles = []
while True:
candles = exchange.fetch_ohlcv(
symbol, timeframe, since=since, limit=1000
)
if not candles:
break
all_candles.extend(candles)
since = candles[-1][0] + 1
if len(candles) < 1000:
break
df = pd.DataFrame(
all_candles,
columns=['timestamp', 'open', 'high', 'low', 'close', 'volume']
)
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
sol = fetch_ohlcv('binance', 'SOL/USDT', '1h', 365)
avax = fetch_ohlcv('binance', 'AVAX/USDT', '1h', 365)
prices = pd.DataFrame({
'SOL': sol['close'],
'AVAX': avax['close']
}).dropna()
공적분 검정
from statsmodels.tsa.stattools import coint, adfuller
from statsmodels.regression.linear_model import OLS
from statsmodels.tools import add_constant
def test_cointegration(y: np.ndarray, x: np.ndarray) -> dict:
"""
진단을 포함한 완전한 공적분 검정.
"""
score, pvalue, crit_values = coint(y, x)
x_const = add_constant(x)
model = OLS(y, x_const).fit()
alpha, beta = model.params
spread = y - alpha - beta * x
adf_stat, adf_pvalue, _, _, adf_crit, _ = adfuller(spread, maxlag=20)
spread_lag = spread[:-1]
spread_diff = np.diff(spread)
spread_lag_const = add_constant(spread_lag)
hl_model = OLS(spread_diff, spread_lag_const).fit()
theta = -hl_model.params[1]
half_life = np.log(2) / theta if theta > 0 else np.inf
return {
'coint_pvalue': pvalue,
'cointegrated': pvalue < 0.05,
'hedge_ratio': beta,
'intercept': alpha,
'adf_statistic': adf_stat,
'adf_pvalue': adf_pvalue,
'half_life_hours': half_life,
'half_life_days': half_life / 24,
'spread_mean': np.mean(spread),
'spread_std': np.std(spread),
}
result = test_cointegration(
prices['SOL'].values,
prices['AVAX'].values
)
print(f"공적분: {result['cointegrated']} "
f"(p-value: {result['coint_pvalue']:.4f})")
print(f"헤지 비율: {result['hedge_ratio']:.4f}")
print(f"반감기: {result['half_life_days']:.1f} 일")
칼만 필터 + 백테스터
from filterpy.kalman import KalmanFilter
class PairsBacktester:
"""
칼만 필터를 사용한 페어 트레이딩
워크포워드 백테스터.
"""
def __init__(
self,
prices_y: np.ndarray,
prices_x: np.ndarray,
kalman_delta: float = 1e-4,
obs_noise: float = 1.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0,
lookback: int = 60,
fee_rate: float = 0.001, # 레그당 0.1% 왕복
slippage_rate: float = 0.0005, # 레그당 0.05% 슬리피지
):
self.prices_y = prices_y
self.prices_x = prices_x
self.n = len(prices_y)
self.kalman_delta = kalman_delta
self.obs_noise = obs_noise
self.entry_z = entry_z
self.exit_z = exit_z
self.stop_z = stop_z
self.lookback = lookback
self.fee_rate = fee_rate
self.slippage_rate = slippage_rate
def run(self) -> pd.DataFrame:
"""백테스트 실행. 결과 DataFrame 반환."""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * self.kalman_delta
kf.R = np.array([[self.obs_noise]])
alphas = np.zeros(self.n)
betas = np.zeros(self.n)
spreads = np.zeros(self.n)
for t in range(self.n):
kf.H = np.array([[1.0, self.prices_x[t]]])
kf.predict()
kf.update(np.array([[self.prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = (
self.prices_y[t] - kf.x[0, 0]
- kf.x[1, 0] * self.prices_x[t]
)
positions = np.zeros(self.n)
z_scores = np.zeros(self.n)
position = 0
for t in range(self.lookback, self.n):
window = spreads[t - self.lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
z_scores[t] = z
if position == 0:
if z > self.entry_z:
position = -1
elif z < -self.entry_z:
position = 1
else:
if position == 1 and z > -self.exit_z:
position = 0
elif position == -1 and z < self.exit_z:
position = 0
elif abs(z) > self.stop_z:
position = 0
positions[t] = position
spread_returns = np.diff(spreads) / np.abs(
spreads[:-1] + 1e-10
)
pnl = np.zeros(self.n)
for t in range(1, self.n):
if positions[t - 1] != 0:
raw_return = positions[t - 1] * spread_returns[t - 1]
pnl[t] = raw_return
if positions[t] != positions[t - 1]:
total_cost = 2 * (self.fee_rate + self.slippage_rate)
pnl[t] -= total_cost
return pd.DataFrame({
'price_y': self.prices_y,
'price_x': self.prices_x,
'alpha': alphas,
'beta': betas,
'spread': spreads,
'z_score': z_scores,
'position': positions,
'pnl': pnl,
'cumulative_pnl': np.cumsum(pnl),
})
bt = PairsBacktester(
prices_y=prices['SOL'].values,
prices_x=prices['AVAX'].values,
kalman_delta=1e-4,
entry_z=2.0,
exit_z=0.5,
stop_z=4.0,
lookback=60,
fee_rate=0.001,
slippage_rate=0.0005,
)
results = bt.run()
daily_pnl = results['pnl'].resample('D').sum() if hasattr(
results.index, 'freq'
) else results['pnl']
metrics = calculate_metrics(daily_pnl.values)
for k, v in metrics.items():
print(f'{k}: {v}')
실시간 거래 스켈레톤
import ccxt
import asyncio
import logging
logger = logging.getLogger(__name__)
class LivePairsTrader:
"""
실시간 페어 트레이딩 최소 스켈레톤.
프로덕션용: 재시도 로직, 모니터링,
알림, 잔고 대조 추가 필요.
"""
def __init__(
self,
exchange_id: str,
symbol_y: str,
symbol_x: str,
api_key: str,
secret: str,
position_size_usd: float = 1000.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
):
self.exchange = getattr(ccxt, exchange_id)({
'apiKey': api_key,
'secret': secret,
'enableRateLimit': True,
})
self.symbol_y = symbol_y
self.symbol_x = symbol_x
self.position_size = position_size_usd
self.entry_z = entry_z
self.exit_z = exit_z
self.position = 0 # +1, -1, 0
self.kf = create_kalman_filter(delta=1e-4)
self.spread_history = []
async def update(self):
"""하나의 업데이트 사이클."""
ticker_y = self.exchange.fetch_ticker(self.symbol_y)
ticker_x = self.exchange.fetch_ticker(self.symbol_x)
price_y = ticker_y['last']
price_x = ticker_x['last']
self.kf.H = np.array([[1.0, price_x]])
self.kf.predict()
self.kf.update(np.array([[price_y]]))
alpha = self.kf.x[0, 0]
beta = self.kf.x[1, 0]
spread = price_y - alpha - beta * price_x
self.spread_history.append(spread)
if len(self.spread_history) < 60:
logger.info(f"Warming up: {len(self.spread_history)}/60")
return
window = np.array(self.spread_history[-60:])
z = (spread - np.mean(window)) / np.std(window)
logger.info(
f"β={beta:.4f} spread={spread:.4f} z={z:.2f} "
f"pos={self.position}"
)
new_position = self.position
if self.position == 0:
if z > self.entry_z:
new_position = -1
elif z < -self.entry_z:
new_position = 1
else:
if self.position == 1 and z > -self.exit_z:
new_position = 0
elif self.position == -1 and z < self.exit_z:
new_position = 0
if new_position != self.position:
await self._execute_trade(
new_position, price_y, price_x, beta
)
self.position = new_position
async def _execute_trade(
self, target: int, price_y: float, price_x: float,
beta: float
):
"""페어 거래 실행."""
if target == 0:
logger.info("Closing position")
elif target == 1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Long spread: buy {size_y:.4f} {self.symbol_y}, "
f"sell {size_x:.4f} {self.symbol_x}"
)
elif target == -1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Short spread: sell {size_y:.4f} {self.symbol_y}, "
f"buy {size_x:.4f} {self.symbol_x}"
)
async def run_loop(self, interval_seconds: int = 60):
"""메인 루프."""
logger.info(
f"Starting live trading: "
f"{self.symbol_y}/{self.symbol_x}"
)
while True:
try:
await self.update()
except Exception as e:
logger.error(f"Error in update: {e}")
await asyncio.sleep(interval_seconds)
마치며
통계적 차익거래는 성배가 아니다. 장인 기술이다. "공적분이 뭔지 안다"와 "안정적으로 작동하는 전략이 있다" 사이에는 엔지니어링 세부사항의 깊은 골이 있다: 올바른 데이터 처리, 정확한 워크포워드 백테스트, 현실적인 슬리피지 모델, 실시간 모니터링.
암호화폐 시장은 여전히 전통 시장보다 통계적 차익거래에 더 많은 기회를 제공한다 — 분산된 유동성, 미성숙한 시장 인프라, 그리고 펀딩 비율이 있는 무기한 선물과 같은 고유한 상품이 NYSE에서는 이미 제로까지 차익거래된 비효율성을 만들어낸다.
하지만 창문은 닫히고 있다. 기관 투자자들이 암호화폐 시장에 진입하고, 차익거래 자본은 성장하며(추정에 따르면 2025년 암호화폐 거래소의 차익거래 자본 규모가 215% 성장했다), 마진은 압축되고 있다. 암호화폐에서 통계적 차익거래를 할 계획이라면 — 지금 시작하는 것이 최선이다.
이 글의 모든 코드는 출발점으로 사용할 수 있다. 본격적인 테스트 없이 프로덕션에서 실행하지 마라. 그리고 기억하라: 보장된 유일한 전략은 리스크 관리다.
주요 학술 논문:
- Engle, R.F. & Granger, C.W.J. (1987). "Co-Integration and Error Correction: Representation, Estimation, and Testing". Econometrica, 55(2), 251-276.
- Gatev, E., Goetzmann, W.N. & Rouwenhorst, K.G. (2006). "Pairs Trading: Performance of a Relative-Value Arbitrage Rule". The Review of Financial Studies, 19(3), 797-827.
- Vidyamurthy, G. (2004). Pairs Trading: Quantitative Methods and Analysis. Wiley.
- Avellaneda, M. & Lee, J.H. (2010). "Statistical Arbitrage in the US Equities Market". Quantitative Finance, 10(7), 761-782.
- Frontiers (2026). "Deep learning-based pairs trading: real-time forecasting of co-integrated cryptocurrency pairs". Frontiers in Applied Mathematics and Statistics.
유용한 라이브러리:
- statsmodels — 공적분, ADF, OLS
- filterpy — 칼만 필터
- ccxt — 100개 이상 거래소 통합 API
- arbitragelab — 페어 트레이딩 전문 라이브러리 (OU, Kalman, copulas)
MarketMaker.cc Team
퀀트 리서치 및 전략