Statistical Arbitrage and Pairs Trading in Crypto Markets: From Cointegration to the Kalman Filter
In 1987, a group of physicists at Morgan Stanley earned $50 million in a single year by trading pairs of stocks using an algorithm that none of them could fully explain to the bank's management. Management didn't object. In 2026, you can launch the same idea on crypto exchanges — with perpetual futures, a 24/7 market, and liquidity that Nunzio Tartaglia would have envied. But there's a catch: what worked with Ford and GM shares in the pre-internet era requires serious adaptation for a world where BTC can drop 20% overnight and the funding rate can flip within a single block.
This article is a full breakdown of statistical arbitrage and pairs trading for crypto markets. From the mathematical theory (cointegration, the Ornstein-Uhlenbeck process, the Kalman filter) to working Python code you can run on real data. The style is engineering-oriented: we explain the formulas, show the code, and don't hide the pitfalls.
1. A Brief History: From a Jesuit to the Quants
Statistical arbitrage in its modern form was born on the trading desk at Morgan Stanley in the mid-1980s. Nunzio Tartaglia — a former Jesuit priest with a PhD in physics — assembled a team of mathematicians, physicists, and computer scientists. The objective: find patterns in stock prices that traditional traders couldn't see.
The idea was disarmingly simple. If Coca-Cola and Pepsi stocks historically move together (which makes sense — they sell the same sugary water in different-colored bottles), then a divergence in their prices is a temporary anomaly. Buy the laggard, sell the leader, wait for convergence, lock in the profit. A market-neutral strategy: the direction of the market doesn't concern us.
Tartaglia's team included people who would go on to transform all of Wall Street:
- David Shaw — later founded D.E. Shaw & Co., one of the largest quantitative hedge funds
- Peter Muller — founded PDT Partners, the legendary stat arb group inside Morgan Stanley
- Robert Frey — later joined Renaissance Technologies under Jim Simons
The group operated as a research laboratory inside an investment bank. Automation was state of the art: VAX clusters generated signals, and execution went through terminals. In the best years (1987-1988), the strategy earned tens of millions. Then came two consecutive losing years, and in 1989 Morgan Stanley shut the desk down.
But the idea had already escaped. Alumni of the group spread the concept of pairs trading across all of Wall Street. Gatev, Goetzmann, and Rouwenhorst published the classic academic paper in 2006 — "Pairs Trading: Performance of a Relative-Value Arbitrage Rule" — showing that a simple pairs trading strategy consistently delivered ~11% annual returns from 1962 to 2002 on U.S. equities. It was a compelling response to the efficient market hypothesis: the market as a whole may be efficient, but pairs of specific assets systematically deviate from equilibrium.
Today, statistical arbitrage is an industry with hundreds of billions of dollars in AUM, and crypto markets offer especially fertile ground: fragmented liquidity, immature microstructure, round-the-clock trading, and perpetual futures with funding rates — an instrument that simply doesn't exist in traditional markets.
2. The Mathematical Foundation: Correlation Is a Trap
Why Correlation Doesn't Work
Let's start with the mistake every other beginner quant makes: "BTC and ETH are correlated with a coefficient of 0.85, so we can trade the pair." No. You can't. Well, you can — but you'll lose money.
Correlation measures the linear relationship between the returns of two assets. Two assets can be perfectly correlated, yet their prices diverge forever. The classic example: two random walks with correlated increments — they diverge infinitely despite high correlation. You'll open a position expecting "convergence" that will never come.
Cointegration: The Right Approach
Cointegration is a property of price series, not returns. Two non-stationary series X(t) and Y(t) are called cointegrated if there exists a linear combination:
S(t) = Y(t) - β · X(t)
that is stationary — meaning it reverts to a mean value. The coefficient β is called the hedge ratio, and S(t) is the spread.
Intuition: BTC and ETH can rocket to the moon or plunge into an abyss, but if their difference (properly scaled) oscillates around a fixed level — that's cointegration. And that's exactly what we need for trading.
The Engle-Granger Test (1987)
A two-step procedure for which Robert Engle and Clive Granger received the Nobel Prize in Economics in 2003:
Step 1. OLS regression: Y(t) = α + β · X(t) + ε(t). We obtain the hedge ratio β and residuals ε(t).
Step 2. ADF (Augmented Dickey-Fuller) test on the residuals ε(t). Null hypothesis: ε(t) has a unit root (non-stationary). If the p-value < 0.05, we reject H₀ — the series are cointegrated.
Important: for the cointegration test, you cannot use the standard ADF critical values. The Engle-Granger critical values were derived via Monte Carlo simulation and account for the dependency between variables in the OLS regression. In statsmodels, this is correctly implemented in the coint() function.
The Johansen Test
For systems with more than two variables (e.g., BTC, ETH, and SOL simultaneously), the Johansen test is used. It finds all cointegration relationships in the system and allows constructing portfolios of multiple assets. The test is based on a VAR (vector autoregression) model and uses two criteria: the trace statistic and the maximum eigenvalue statistic.
The Ornstein-Uhlenbeck Process
If the spread is cointegrated, its dynamics can be modeled as an Ornstein-Uhlenbeck (OU) process:
dS(t) = θ(μ - S(t))dt + σ dW(t)
where:
- θ — the mean reversion speed
- μ — the long-term mean level
- σ — volatility
- W(t) — a Wiener process (Brownian motion)
From the OU process parameters, the half-life of mean reversion is calculated:
t½ = ln(2) / θ
The half-life is a critically important metric. If t½ = 5 days, the spread reverts to the mean in about 5 days. If t½ = 200 days, you'll be sitting in a position for half a year waiting for convergence. For crypto strategies, the optimal half-life is 1-30 days. Shorter — too fast, commissions eat up the profit. Longer — too slow, risk of structural regime change.
In practice, θ is estimated via regression:
ΔS(t) = a + b · S(t-1) + ε(t)
where θ = -b, and t½ = -ln(2) / b.
Z-Score Normalization
To generate trading signals, the spread is normalized:
z(t) = (S(t) - μ̂) / σ̂
where μ̂ and σ̂ are the rolling mean and standard deviation of the spread. The z-score shows how many standard deviations the spread has deviated from the mean. Typical entry thresholds: |z| > 2.0; exit thresholds: |z| < 0.5.
3. Selecting Pairs in the Crypto Market
BTC-ETH: The Classic That (Sometimes) Works
BTC and ETH are the most obvious and most liquid pair. Return correlation is consistently above 0.7. But cointegration is a different matter. It appears and disappears:
- During the 2023 sideways markets, BTC/ETH were reliably cointegrated (p-value < 0.01)
- During the 2024-2025 divergence (BTC rallied on ETF flows, ETH lagged), cointegration broke down
- By early 2026, after the ETH ETF launch and recovery of the ETH/BTC ratio, cointegration stabilized again
Conclusion: cointegration must be continuously monitored. Regression parameters are recalculated on a rolling window, and the strategy automatically shuts off if the ADF test p-value exceeds the threshold.
Sector Pairs
The crypto market is conveniently segmented by sector, and intra-sector pairs often exhibit stable cointegration:
| Sector | Example Pairs | Characteristics |
|---|---|---|
| L1 blockchains | SOL/AVAX, NEAR/APT | High liquidity, half-life 3-10 days |
| DeFi protocols | AAVE/COMP, UNI/SUSHI | Medium liquidity, half-life 5-15 days |
| L2 solutions | ARB/OP, MATIC/MANTA | High spread volatility |
| Memecoins | DOGE/SHIB | Unpredictable but fun (not recommended) |
The best pairs for stat arb have three properties: (1) stable cointegration over a historical window >6 months, (2) sufficient liquidity — daily volume >$10M per asset, (3) reasonable half-life — from 1 to 30 days.
Spot vs Perpetual Futures (Basis)
A separate category of "pairs" is the same asset on the spot and futures markets. The difference between the perpetual futures price and the spot price (the basis) is stationary by definition: the funding rate mechanism compresses it back toward zero. This makes basis trading one of the most reliable forms of stat arb in crypto.
4. Three Trading Approaches
A. Basis Trading: Spot-Futures and Funding Rate Carry
The "purest" form of stat arb in crypto. The mechanics:
- Buy the asset on spot (e.g., 1 BTC)
- Open a short on the perpetual future (1 BTC)
- If the funding rate is positive (longs pay shorts) — you receive funding every 8 hours
At an average funding rate of 0.01% every 8 hours, that's ~0.03% per day or ~11% annualized with no directional risk. During bull markets, the funding rate can rise to 0.05-0.1% every 8 hours — that's already 55-110% annualized.
Risks: negative funding (the market reverses), liquidation of the short position during a sharp price rally (margin buffer required), and exchange fees.
As of March 2026, the average BTC funding rate has stabilized at approximately ~0.015% per 8 hours — about 50% above 2024 levels.
B. Cross-Exchange Arbitrage
Same coin, two exchanges, different prices. The reason — differences in liquidity, trader composition, and order book update speeds.
Example: BTC on Binance: 87,175. Spread: $25 (0.029%).
Strategy: buy on Binance, sell on Bybit. Problem: by the time both orders are executed, the spread may have vanished. Solution: maintain balances on both exchanges and execute simultaneously.
Typical fees:
- Binance: ~0.075% taker (with discount ~0.05%)
- Bybit: ~0.03% taker (VIP)
- Total: ~0.08%
This means the spread must exceed 0.08% for the strategy to be profitable. In 2026, such spreads arise:
- On less liquid pairs (altcoins) — regularly
- On major pairs (BTC, ETH) — only during high-volatility moments
- Between CEX and DEX — more frequently, but with MEV risk and slippage
Without co-location, API latency is 10-100 ms. With optimized networks — ~1 ms. Most retail traders operate in the 100-500 ms range, which is sufficient for many arbitrage strategies but insufficient to compete with institutions.
C. Pairs Trading with Leverage
Classic pairs trading on two different assets using leverage. This is the most complex of the three strategies — and the most potentially profitable.
Mechanics using the SOL/AVAX pair as an example:
- Calculate hedge ratio β (e.g., β = 1.3)
- When z-score > +2: short SOL, long AVAX × β
- When z-score < -2: long SOL, short AVAX × β
- Exit: |z-score| < 0.5 or timeout (e.g., 30 days)
With 3x leverage on each leg and an average spread reversion of 2σ → 3σ:
- Target return per trade: ~3-6%
- Average frequency: 2-4 trades per month per pair
- Expected annual return: 30-60% (before commissions and slippage)
The main risk: the correlation can break down at the worst possible moment (usually during a market crash). More on this in section 8.
5. Kalman Filter for Adaptive Hedge Ratio
Why a Static Hedge Ratio Is a Problem
The classical approach: estimate β via OLS on a historical window and fix it. The problem: β changes over time. The crypto market is especially non-stationary — narrative shifts (DeFi summer → NFT hype → AI tokens) alter the fundamental relationships between assets.
Using rolling OLS (rolling regression) is a half-measure. You have to choose the window length: too short — noise; too long — lag. The Kalman filter solves this problem elegantly.
State-Space Model
We represent the relationship between Y(t) and X(t) as a linear model with time-varying coefficients:
Observation equation:
Y(t) = α(t) + β(t) · X(t) + ε(t), ε(t) ~ N(0, R)
State equation:
[α(t+1), β(t+1)]ᵀ = [α(t), β(t)]ᵀ + w(t), w(t) ~ N(0, Q)
The parameters α(t) and β(t) are treated as a hidden state that slowly drifts (random walk). The Kalman filter optimally estimates this hidden state from noisy observations.
- R (observation noise) — the variance of observation noise. The larger R, the slower the filter responds to new data.
- Q (state noise) — the covariance matrix of state noise. The larger Q, the faster the filter adapts.
The Q/R ratio determines the "smoothness" of the filter — analogous to choosing the window length in rolling OLS, but without hard data truncation.
Advantages Over Rolling OLS
Spreads computed using the Kalman filter are significantly more stationary and mean-reverting than spreads from rolling regression. The Kalman filter uses all past observations with exponentially decaying weights, rather than truncating data at a fixed window length. Additionally, the Kalman filter does not require tuning a "window length" parameter — instead, it automatically calibrates the balance between inertia and adaptivity through the Q and R matrices.
Implementation with filterpy
import numpy as np
from filterpy.kalman import KalmanFilter
def create_kalman_filter(
delta: float = 1e-4,
obs_noise: float = 1.0
) -> KalmanFilter:
"""
Creates a Kalman filter for adaptive hedge ratio estimation.
delta: state noise variance (Q = delta * I).
Larger delta → faster adaptation, more noise.
obs_noise: observation noise variance (R).
"""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * delta
kf.R = np.array([[obs_noise]])
return kf
def estimate_hedge_ratio(
prices_y: np.ndarray,
prices_x: np.ndarray,
delta: float = 1e-4,
obs_noise: float = 1.0
) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
"""
Estimates the adaptive hedge ratio using a Kalman filter.
Returns:
alphas: array of intercepts (α)
betas: array of hedge ratios (β)
spreads: array of spreads Y - α - β*X
"""
n = len(prices_y)
kf = create_kalman_filter(delta, obs_noise)
alphas = np.zeros(n)
betas = np.zeros(n)
spreads = np.zeros(n)
for t in range(n):
kf.H = np.array([[1.0, prices_x[t]]])
kf.predict()
kf.update(np.array([[prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = prices_y[t] - kf.x[0, 0] - kf.x[1, 0] * prices_x[t]
return alphas, betas, spreads
The delta parameter is key. For crypto pairs with high volatility (memecoins, small-cap alts), use delta = 1e-3. For stable pairs (BTC/ETH, SOL/AVAX) — delta = 1e-5.
6. Entry and Exit Signals
Z-Score Thresholds
Basic signal logic:
def generate_signals(
spreads: np.ndarray,
lookback: int = 60,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0
) -> np.ndarray:
"""
Generates trading signals based on spread z-score.
Returns array: +1 (long spread), -1 (short spread), 0 (flat)
"""
signals = np.zeros(len(spreads))
position = 0
for t in range(lookback, len(spreads)):
window = spreads[t - lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
if position == 0:
if z > entry_z:
position = -1 # Short spread (short Y, long X)
elif z < -entry_z:
position = 1 # Long spread (long Y, short X)
else:
if position == 1 and z > -exit_z:
position = 0
elif position == -1 and z < exit_z:
position = 0
elif abs(z) > stop_z:
position = 0
signals[t] = position
return signals
Momentum Filters
A pure mean-reversion signal can be improved with filters:
-
Momentum filter: don't open a position if the spread continues to diverge. Wait for the spread to reverse before entering. Technically: the z-score has crossed the threshold, but the current spread change is already directed toward the mean.
-
Volatility filter: increase the entry threshold during periods of high volatility. When the market panics, the z-score can remain above 3σ for weeks.
-
Cointegration filter: before each trade, verify that cointegration still holds (rolling ADF test). If p-value > 0.1 — pause trading.
Time-Based Exits
If a position has been open longer than 2× the half-life and the spread hasn't reverted — close it forcibly. If the spread hasn't reverted within 2× the expected time, cointegration has likely broken down, and there's nothing to wait for.
7. Backtesting: Doing It Right
Walk-Forward Analysis
A standard backtest (train on all data → test on all data) is useless for stat arb. The regression parameters are overfitted to the data, and the result will be optimistic.
Walk-forward approach:
- Divide data into periods: [train₁ → test₁] → [train₂ → test₂] → ...
- On each train period: estimate cointegration, calculate hedge ratio, select z-score thresholds
- On the test period: trade with fixed parameters
- Combine all test periods for the final evaluation
Typical configuration for crypto: train = 180 days, test = 30 days, step = 30 days.
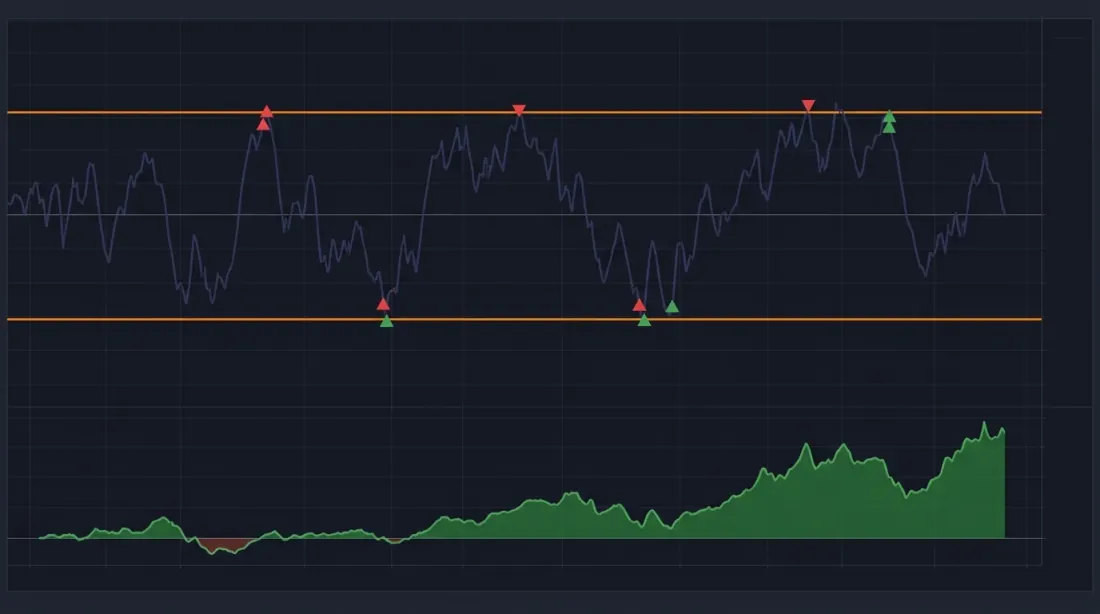
Transaction Cost Model
For crypto, you need to account for:
| Component | Typical Value | Comment |
|---|---|---|
| Maker fee | 0.02% | Limit orders |
| Taker fee | 0.05-0.075% | Market orders |
| Slippage | 0.01-0.1% | Depends on liquidity |
| Funding rate | ±0.01%/8h | For futures positions |
| Spread (bid-ask) | 0.01-0.05% | On major exchanges |
Entering and exiting a pairs position involves 4 trades (2 legs × entry + exit). Total costs: ~0.3-0.5% per round trip. This means the average profit per trade must exceed 0.5% for a positive expected value.
Slippage Model
Linear model: slippage = k × (order_size / ADV), where ADV is the average daily volume. For crypto, k ≈ 0.1 for top-10 coins and k ≈ 0.3-0.5 for altcoins.
A more realistic model is square-root impact: slippage = k × sqrt(order_size / ADV). It better reflects real market microstructure.
Metrics
def calculate_metrics(returns: np.ndarray, rf: float = 0.04) -> dict:
"""
Calculates key strategy metrics.
rf: risk-free rate (annual)
"""
daily_rf = rf / 365
excess = returns - daily_rf
ann_return = np.mean(returns) * 365
ann_vol = np.std(returns) * np.sqrt(365)
sharpe = (ann_return - rf) / ann_vol if ann_vol > 0 else 0
cumulative = np.cumprod(1 + returns)
running_max = np.maximum.accumulate(cumulative)
drawdowns = (cumulative - running_max) / running_max
max_dd = np.min(drawdowns)
calmar = ann_return / abs(max_dd) if max_dd != 0 else 0
win_rate = np.mean(returns > 0) if len(returns) > 0 else 0
gains = returns[returns > 0].sum()
losses = abs(returns[returns < 0].sum())
profit_factor = gains / losses if losses > 0 else float('inf')
return {
'annual_return': f'{ann_return:.1%}',
'annual_volatility': f'{ann_vol:.1%}',
'sharpe_ratio': f'{sharpe:.2f}',
'max_drawdown': f'{max_dd:.1%}',
'calmar_ratio': f'{calmar:.2f}',
'win_rate': f'{win_rate:.1%}',
'profit_factor': f'{profit_factor:.2f}',
}
Benchmarks for crypto stat arb:
- Sharpe > 1.5 — a good strategy
- Max drawdown < 15% — acceptable risk
- Calmar > 2.0 — excellent return/drawdown ratio
- Profit factor > 1.5 — sustainable edge
8. Real-World Problems
Slippage and Liquidity
In a backtest, you enter instantly at the mid-price. In reality — you don't. On altcoins with daily volume of 50K order can move the price by 0.2-0.5%. For a pairs strategy, that's doubled slippage (two legs), and it can eat up all the profit.
Solution: use limit orders (maker, not taker), split orders into parts (TWAP/VWAP), and strictly limit position size relative to ADV (maximum 1-2% of daily volume).
Funding Rate Risk
With basis trading, you receive the funding rate, but it can turn negative. In the bearish market of December 2022, the BTC funding rate was -0.02% every 8 hours — if you were sitting in a "long spot + short perp" position, you were paying 100K of position.
Protection: monitor the funding rate in real time and close the position when the rate reverses. A more advanced approach is funding rate arbitrage between exchanges (long on the exchange with low funding, short on the exchange with high funding).
Correlation Breakdown in a Crisis
March 2020, May 2021, November 2022, August 2024 — in every crypto crash, correlations break down. More precisely, correlations intensify (everything falls together), but cointegration breaks — the spread can fly to 10σ and never return.
This is the Achilles heel of pairs trading. The strategy earns small amounts consistently, then loses a large sum in a single day. The classic "picking up pennies in front of a steamroller" profile.
Protection:
- Strict stop-loss: close the position when z-score > 4σ
- Leverage limits: maximum 2-3x on each leg
- VIX/volatility filter: reduce position size when implied volatility is high
- Diversification: trade 10-20 pairs simultaneously, don't put everything on one
Capital Requirements
For serious crypto stat arb:
- Basis trading: from $50K (on one pair, one exchange)
- Cross-exchange arbitrage: from $100K (balances on two exchanges)
- Pairs trading portfolio (10 pairs): from $200K
- Institutional level: from $1M
With smaller amounts, commissions and minimum position sizes make the strategy unviable.
9. End-to-End Python Implementation
Data Retrieval
import ccxt
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
def fetch_ohlcv(
exchange_id: str,
symbol: str,
timeframe: str = '1h',
days: int = 365
) -> pd.DataFrame:
"""Fetch OHLCV data via ccxt."""
exchange = getattr(ccxt, exchange_id)({
'enableRateLimit': True,
})
since = int((datetime.now() - timedelta(days=days)).timestamp() * 1000)
all_candles = []
while True:
candles = exchange.fetch_ohlcv(
symbol, timeframe, since=since, limit=1000
)
if not candles:
break
all_candles.extend(candles)
since = candles[-1][0] + 1
if len(candles) < 1000:
break
df = pd.DataFrame(
all_candles,
columns=['timestamp', 'open', 'high', 'low', 'close', 'volume']
)
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
return df
sol = fetch_ohlcv('binance', 'SOL/USDT', '1h', 365)
avax = fetch_ohlcv('binance', 'AVAX/USDT', '1h', 365)
prices = pd.DataFrame({
'SOL': sol['close'],
'AVAX': avax['close']
}).dropna()
Cointegration Test
from statsmodels.tsa.stattools import coint, adfuller
from statsmodels.regression.linear_model import OLS
from statsmodels.tools import add_constant
def test_cointegration(y: np.ndarray, x: np.ndarray) -> dict:
"""
Full cointegration test with diagnostics.
"""
score, pvalue, crit_values = coint(y, x)
x_const = add_constant(x)
model = OLS(y, x_const).fit()
alpha, beta = model.params
spread = y - alpha - beta * x
adf_stat, adf_pvalue, _, _, adf_crit, _ = adfuller(spread, maxlag=20)
spread_lag = spread[:-1]
spread_diff = np.diff(spread)
spread_lag_const = add_constant(spread_lag)
hl_model = OLS(spread_diff, spread_lag_const).fit()
theta = -hl_model.params[1]
half_life = np.log(2) / theta if theta > 0 else np.inf
return {
'coint_pvalue': pvalue,
'cointegrated': pvalue < 0.05,
'hedge_ratio': beta,
'intercept': alpha,
'adf_statistic': adf_stat,
'adf_pvalue': adf_pvalue,
'half_life_hours': half_life,
'half_life_days': half_life / 24,
'spread_mean': np.mean(spread),
'spread_std': np.std(spread),
}
result = test_cointegration(
prices['SOL'].values,
prices['AVAX'].values
)
print(f"Cointegration: {result['cointegrated']} "
f"(p-value: {result['coint_pvalue']:.4f})")
print(f"Hedge ratio: {result['hedge_ratio']:.4f}")
print(f"Half-life: {result['half_life_days']:.1f} days")
Kalman Filter + Backtester
from filterpy.kalman import KalmanFilter
class PairsBacktester:
"""
Walk-forward backtester for pairs trading
with Kalman filter.
"""
def __init__(
self,
prices_y: np.ndarray,
prices_x: np.ndarray,
kalman_delta: float = 1e-4,
obs_noise: float = 1.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
stop_z: float = 4.0,
lookback: int = 60,
fee_rate: float = 0.001, # 0.1% round trip per leg
slippage_rate: float = 0.0005, # 0.05% slippage per leg
):
self.prices_y = prices_y
self.prices_x = prices_x
self.n = len(prices_y)
self.kalman_delta = kalman_delta
self.obs_noise = obs_noise
self.entry_z = entry_z
self.exit_z = exit_z
self.stop_z = stop_z
self.lookback = lookback
self.fee_rate = fee_rate
self.slippage_rate = slippage_rate
def run(self) -> pd.DataFrame:
"""Run the backtest. Returns a DataFrame with results."""
kf = KalmanFilter(dim_x=2, dim_z=1)
kf.x = np.zeros((2, 1))
kf.F = np.eye(2)
kf.P = np.eye(2) * 1000
kf.Q = np.eye(2) * self.kalman_delta
kf.R = np.array([[self.obs_noise]])
alphas = np.zeros(self.n)
betas = np.zeros(self.n)
spreads = np.zeros(self.n)
for t in range(self.n):
kf.H = np.array([[1.0, self.prices_x[t]]])
kf.predict()
kf.update(np.array([[self.prices_y[t]]]))
alphas[t] = kf.x[0, 0]
betas[t] = kf.x[1, 0]
spreads[t] = (
self.prices_y[t] - kf.x[0, 0]
- kf.x[1, 0] * self.prices_x[t]
)
positions = np.zeros(self.n)
z_scores = np.zeros(self.n)
position = 0
for t in range(self.lookback, self.n):
window = spreads[t - self.lookback:t]
mu = np.mean(window)
sigma = np.std(window)
if sigma < 1e-10:
continue
z = (spreads[t] - mu) / sigma
z_scores[t] = z
if position == 0:
if z > self.entry_z:
position = -1
elif z < -self.entry_z:
position = 1
else:
if position == 1 and z > -self.exit_z:
position = 0
elif position == -1 and z < self.exit_z:
position = 0
elif abs(z) > self.stop_z:
position = 0
positions[t] = position
spread_returns = np.diff(spreads) / np.abs(
spreads[:-1] + 1e-10
)
pnl = np.zeros(self.n)
for t in range(1, self.n):
if positions[t - 1] != 0:
raw_return = positions[t - 1] * spread_returns[t - 1]
pnl[t] = raw_return
if positions[t] != positions[t - 1]:
total_cost = 2 * (self.fee_rate + self.slippage_rate)
pnl[t] -= total_cost
return pd.DataFrame({
'price_y': self.prices_y,
'price_x': self.prices_x,
'alpha': alphas,
'beta': betas,
'spread': spreads,
'z_score': z_scores,
'position': positions,
'pnl': pnl,
'cumulative_pnl': np.cumsum(pnl),
})
bt = PairsBacktester(
prices_y=prices['SOL'].values,
prices_x=prices['AVAX'].values,
kalman_delta=1e-4,
entry_z=2.0,
exit_z=0.5,
stop_z=4.0,
lookback=60,
fee_rate=0.001,
slippage_rate=0.0005,
)
results = bt.run()
daily_pnl = results['pnl'].resample('D').sum() if hasattr(
results.index, 'freq'
) else results['pnl']
metrics = calculate_metrics(daily_pnl.values)
for k, v in metrics.items():
print(f'{k}: {v}')
Live Trading Skeleton
import ccxt
import asyncio
import logging
logger = logging.getLogger(__name__)
class LivePairsTrader:
"""
Minimal skeleton for live pairs trading.
For production: add retry logic, monitoring,
alerts, balance reconciliation.
"""
def __init__(
self,
exchange_id: str,
symbol_y: str,
symbol_x: str,
api_key: str,
secret: str,
position_size_usd: float = 1000.0,
entry_z: float = 2.0,
exit_z: float = 0.5,
):
self.exchange = getattr(ccxt, exchange_id)({
'apiKey': api_key,
'secret': secret,
'enableRateLimit': True,
})
self.symbol_y = symbol_y
self.symbol_x = symbol_x
self.position_size = position_size_usd
self.entry_z = entry_z
self.exit_z = exit_z
self.position = 0 # +1, -1, 0
self.kf = create_kalman_filter(delta=1e-4)
self.spread_history = []
async def update(self):
"""One update cycle."""
ticker_y = self.exchange.fetch_ticker(self.symbol_y)
ticker_x = self.exchange.fetch_ticker(self.symbol_x)
price_y = ticker_y['last']
price_x = ticker_x['last']
self.kf.H = np.array([[1.0, price_x]])
self.kf.predict()
self.kf.update(np.array([[price_y]]))
alpha = self.kf.x[0, 0]
beta = self.kf.x[1, 0]
spread = price_y - alpha - beta * price_x
self.spread_history.append(spread)
if len(self.spread_history) < 60:
logger.info(f"Warming up: {len(self.spread_history)}/60")
return
window = np.array(self.spread_history[-60:])
z = (spread - np.mean(window)) / np.std(window)
logger.info(
f"β={beta:.4f} spread={spread:.4f} z={z:.2f} "
f"pos={self.position}"
)
new_position = self.position
if self.position == 0:
if z > self.entry_z:
new_position = -1
elif z < -self.entry_z:
new_position = 1
else:
if self.position == 1 and z > -self.exit_z:
new_position = 0
elif self.position == -1 and z < self.exit_z:
new_position = 0
if new_position != self.position:
await self._execute_trade(
new_position, price_y, price_x, beta
)
self.position = new_position
async def _execute_trade(
self, target: int, price_y: float, price_x: float,
beta: float
):
"""Execute a pairs trade."""
if target == 0:
logger.info("Closing position")
elif target == 1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Long spread: buy {size_y:.4f} {self.symbol_y}, "
f"sell {size_x:.4f} {self.symbol_x}"
)
elif target == -1:
size_y = self.position_size / price_y
size_x = (self.position_size * beta) / price_x
logger.info(
f"Short spread: sell {size_y:.4f} {self.symbol_y}, "
f"buy {size_x:.4f} {self.symbol_x}"
)
async def run_loop(self, interval_seconds: int = 60):
"""Main loop."""
logger.info(
f"Starting live trading: "
f"{self.symbol_y}/{self.symbol_x}"
)
while True:
try:
await self.update()
except Exception as e:
logger.error(f"Error in update: {e}")
await asyncio.sleep(interval_seconds)
Instead of a Conclusion
Statistical arbitrage is not the Holy Grail. It's a craft. Between "I know what cointegration is" and "I have a consistently working strategy" lies a chasm of engineering details: proper data processing, correct walk-forward backtesting, a realistic slippage model, real-time monitoring.
Cryptocurrency markets still offer more opportunities for stat arb than traditional ones — fragmented liquidity, immature market infrastructure, and unique instruments like perpetual futures with funding rates create inefficiencies that have long been arbitraged to zero on the NYSE.
But the window is closing. Institutional players are entering crypto markets, arbitrage capital is growing (by estimates, the volume of arbitrage capital on crypto exchanges grew by 215% in 2025), and margins are compressing. If you're going to do stat arb in crypto — it's best to start now.
All the code in this article is available as a starting point. Don't run it in production without serious testing. And remember: the only strategy that's guaranteed to work is risk management.
Key academic works:
- Engle, R.F. & Granger, C.W.J. (1987). "Co-Integration and Error Correction: Representation, Estimation, and Testing". Econometrica, 55(2), 251-276.
- Gatev, E., Goetzmann, W.N. & Rouwenhorst, K.G. (2006). "Pairs Trading: Performance of a Relative-Value Arbitrage Rule". The Review of Financial Studies, 19(3), 797-827.
- Vidyamurthy, G. (2004). Pairs Trading: Quantitative Methods and Analysis. Wiley.
- Avellaneda, M. & Lee, J.H. (2010). "Statistical Arbitrage in the US Equities Market". Quantitative Finance, 10(7), 761-782.
- Frontiers (2026). "Deep learning-based pairs trading: real-time forecasting of co-integrated cryptocurrency pairs". Frontiers in Applied Mathematics and Statistics.
Useful libraries:
- statsmodels — cointegration, ADF, OLS
- filterpy — Kalman filter
- ccxt — unified API for 100+ exchanges
- arbitragelab — specialized library for pairs trading (OU, Kalman, copulas)
MarketMaker.cc Team
Сандық зерттеулер және стратегия
Read More

Funding Rate Arbitrage Across Exchanges: How to Profit from Rate Differences

Funding Rates Kill Your Leverage: Why PnL×50x Is a Fiction