تنقيب ألفا بالنماذج اللغوية الكبيرة: كيفية استخراج إشارات التداول من مكالمات الأرباح والوثائق المالية

هناك نكتة في وول ستريت تقول: "المعلومة الأكثر قيمة في مكالمة الأرباح ليست ما قاله المدير التنفيذي، بل كيف قاله." عندما يقول تيم كوك "نحن متفائلون بحذر" بدلاً من "نحن سعداء جداً" التي قالها العام الماضي — هذه ليست لعبة لغوية، إنها إشارة بمئات الملايين من الدولارات.
على مدى عقود، حاولت صناديق الكم تنظيم استخراج هذه الإشارات. في البداية، قاموا بعدّ تكرار الكلمات "الإيجابية" و"السلبية" باستخدام القواميس. ثم أطلقوا BERT. والآن لدينا GPT-4o وClaude ونماذج LLM مفتوحة المصدر قادرة على تحليل دقائق اللغة المؤسسية بدقة تخيف حتى الباحثين أنفسهم.
دعونا نستعرض كيفية بناء خط أنابيب متكامل لاستخراج إشارات التداول من مكالمات الأرباح — من الحصول على النص المكتوب إلى الاختبار الرجعي للعوائد التراكمية غير الطبيعية.
لماذا تعتبر مكالمات الأرباح منجم ذهب لألفا
انجراف ما بعد إعلان الأرباح: الشذوذ الذي لا يموت
في عام 1968، اكتشف بول وبراون شيئاً غريباً: بعد نشر النتائج الفصلية، تستمر الأسهم في الانجراف في اتجاه "المفاجأة" لمدة 60-90 يوماً إضافياً. أسموه انجراف ما بعد إعلان الأرباح (Post-Earnings Announcement Drift - PEAD). مضى أكثر من نصف قرن منذ ذلك الحين، كُتبت مئات الأوراق البحثية، وشُرح الشذوذ من عشرات الزوايا — لكنه لا يزال يعمل.
PEAD هو أحد أكثر الشذوذات السوقية استمرارية في تاريخ التمويل. استراتيجية المحفظة "اشترِ المفاجأة الإيجابية، وبِع المفاجأة السلبية" حققت تاريخياً عوائد فائضة سنوية تتراوح بين 10-25%. لماذا لم يقم السوق بالمراجحة على هذا حتى الآن؟ عدة أسباب:
- محدودية انتباه المستثمرين — عندما تقدم 200 شركة تقاريرها في أسبوع واحد، يستحيل مادياً قراءة جميع النصوص المكتوبة
- التعقيد المعرفي — تستمر مكالمة الأرباح 45-60 دقيقة، وقد تكون الإشارة الرئيسية مخبأة في جملة واحدة في الدقيقة 38 من جلسة الأسئلة والأجوبة
- غموض اللغة — يقول المدير المالي "we are navigating headwinds"، وبدون سياق لا يُعرف إن كان هذا تحذيراً خفيفاً أم تحوطاً معتاداً
هنا تدخل النماذج اللغوية الكبيرة. لأول مرة، لدينا أداة تستطيع معالجة 500 نص مكتوب في مساء واحد مع التقاط فروق دقيقة قد يغفل عنها حتى المحلل ذو الخبرة.
PEAD.txt: النص أهم من الأرقام
نشر باحثون من بنك الاحتياطي الفيدرالي في فيلادلفيا (Meursault، Liang، Routledge، Scanlon) ورقة PEAD.txt التي قلبت المفاهيم حول قيمة المعلومات النصية. بنوا نظيراً نصياً لمفاجأة الأرباح القياسية — SUE.txt — الذي لا يستخدم القيمة الرقمية للأرباح على الإطلاق.
النتيجة؟ يولّد SUE.txt انجرافاً يبلغ ضعف PEAD الكلاسيكي. علاوة على ذلك: في السنوات الأخيرة، بينما اختفى PEAD الكلاسيكي القائم على المفاجآت الرقمية تقريباً (تعلّم السوق)، يظل الانجراف النصي ذا دلالة إحصائية. تعلّم السوق معالجة الأرقام بسرعة لكنه لا يزال يعاني مع تفسير النصوص.
هذه هي الحجة الأساسية لصالح نهج معالجة اللغات الطبيعية في تحليل مكالمات الأرباح.
من المشاعر إلى الدلالات: تطور المقاربات

الجيل الأول: حقيبة الكلمات والقواميس (2000-2015)
بدأ كل شيء مع قاموس Loughran-McDonald (2011) — قائمة كلمات مصنفة كـ"إيجابية" و"سلبية" و"غير مؤكدة" و"قضائية". كانت الفكرة أنيقة في بساطتها: احسب نسبة الكلمات السلبية في تقرير 10-K وتداول بناءً على ذلك.
المشكلة؟ كلمة "outstanding" في السياق المالي غالباً ما تعني "دين غير مسدد" وليس "نتائج ممتازة". كلمة "risk" في Risk Management ليست إشارة سلبية بل وصف لعملية. أداء قواميس المشاعر القياسية من معالجة اللغات الطبيعية كان محرجاً على النصوص المالية.
أنشأ Loughran وMcDonald قاموساً متخصصاً، مما حسّن الوضع، لكن المشكلة الأساسية بقيت: حقيبة الكلمات لا تفهم السياق. "We did not fail to meet expectations" — هناك كلمتان "سلبيتان" لكن المعنى إيجابي.
الجيل الثاني: FinBERT والمحولات (2019-2023)
في 2019، نشر Dogu Araci نموذج FinBERT — BERT مضبوط على نصوص مالية من Reuters TRC2. كانت النتائج مبهرة: تحسن بمقدار 14 نقطة مئوية على أحدث التقنيات في مجموعة بيانات Financial PhraseBank. فهم FinBERT السياق: "outstanding" بجانب "debt" — سلبي، بجانب "performance" — إيجابي.
لكن لـ FinBERT قيد: نافذة سياق 512 رمزاً. تبلغ مكالمة الأرباح 8,000-12,000 كلمة. تقسيمها إلى أجزاء ومتوسطة المشاعر يعني فقدان الدلالات بين الفقرات. قد يبدأ المدير التنفيذي بالتفاؤل، ثم يشير عرضاً في جلسة الأسئلة والأجوبة إلى مشاكل سلسلة التوريد. يحلل FinBERT كل جزء على حدة ولا يرى هذا التباين.
الجيل الثالث: النماذج اللغوية الكبيرة ذات السياق الطويل (2023-الحاضر)
GPT-4 وClaude وGemini بنوافذ سياق 128K-1M رمز غيّرت قواعد اللعبة. الآن يمكن تحميل النص المكتوب بالكامل مرة واحدة وطرح أسئلة تتطلب فهم الوثيقة كلها.
الدراسة الرئيسية — Lopez-Lira & Tang (2023) "Can ChatGPT Forecast Stock Price Movements?" على أكثر من 50,000 عنوان، أظهر GPT-4 معدل إصابة ~90% في التنبؤ باتجاه رد فعل السوق الأولي وتنبأ بشكل ذي دلالة إحصائية بالانجراف اللاحق، خاصة للشركات الصغيرة والأخبار السلبية. النماذج المبكرة (GPT-1، GPT-2، BERT) لم تُظهر هذه القدرة — القدرة التنبؤية تظهر كخاصية ناشئة للنماذج الكبيرة.
BloombergGPT (2023) — نموذج بـ 50 مليار معامل مدرب على مجموعة Bloomberg المالية — أظهر تحسينات في التعرف على الكيانات المالية وتصنيف الأخبار وتحليل المشاعر. FinGPT — بديله مفتوح المصدر — يحقق دقة 89% في مهام المشاعر المالية باستخدام نهج محوره البيانات وRAG.
MarketSenseAI، الذي يستخدم GPT-4 مع Chain-of-Thought وIn-Context Learning لتحليل S&P 100، أظهر ألفا فائضة 10-30% وعوائد تراكمية تصل إلى 72% خلال 15 شهراً من الاختبار. نعم، يجب أخذ هذه الأرقام بحذر (الاختبار الرجعي ≠ التداول الحي)، لكن الاتجاه واضح.
خط أنابيب البيانات: من أين نحصل على البيانات
SEC EDGAR: المصدر الرسمي
للأسهم الأمريكية، المصدر الرئيسي هو SEC EDGAR. مكالمات الأرباح لا تُقدم مباشرة عادةً، لكن الوثائق ذات الصلة متاحة:
- ملفات 8-K (البند 2.02 — نتائج العمليات) — بيانات صحفية بالنتائج، غالباً تتضمن exhibit 99 مع النص المكتوب
- 10-Q / 10-K — التقارير الفصلية والسنوية مع مناقشة وتحليل الإدارة (MD&A) — مصدر نصي قيّم أيضاً
- DEF 14A — بيانات التوكيل مع معلومات تعويضات الإدارة
from edgar import Company
company = Company("AAPL")
filings = company.get_filings(form="8-K")
for filing in filings.latest(10):
if "2.02" in str(filing.items):
doc = filing.document()
text = doc.text() # النص الكامل مع المرفقات
print(f"{filing.filing_date}: {len(text)} chars")
Seeking Alpha والواجهات البرمجية التجارية
نصوص مكالمات الأرباح منتج مستقل. كان Seeking Alpha تاريخياً المصدر المجاني الرئيسي، لكنه الآن يقيّد الوصول. الخيارات التجارية:
- Seeking Alpha Premium API — نصوص كاملة مع تسميات المتحدثين
- AlphaVantage Earnings API — مستوى مجاني بقيود
- Financial Modeling Prep — نصوص + بيانات أساسية
- Earnings Call Edge / Motley Fool Transcripts — مصادر بديلة
العملات المشفرة: مكالمات الحوكمة ومقترحات DAO
هنا يصبح الأمر أكثر إثارة. تُجري بروتوكولات DeFi الكبرى ما يعادل مكالمات الأرباح:
- Uniswap — مكالمات الحوكمة، مكالمات المجتمع، تسجيلات على YouTube
- Aave — مكالمات مجتمعية شهرية + مقترحات منتدى الحوكمة
- MakerDAO — مكالمات حوكمة + نقاشات منتدى واسعة
- Compound — مقترحات حوكمة مع مناقشات تفصيلية
عادةً ما تكون نصوص مكالمات العملات المشفرة غير منظمة. الحل — Whisper من OpenAI لتفريغ تسجيلات YouTube:
import openai
from yt_dlp import YoutubeDL
def transcribe_governance_call(youtube_url: str) -> str:
"""تحميل الصوت من YouTube وتفريغه عبر Whisper."""
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '64', # معدل بت منخفض كافٍ للكلام
}],
'outtmpl': '/tmp/governance_call.%(ext)s',
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([youtube_url])
client = openai.OpenAI()
with open("/tmp/governance_call.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="verbose_json",
timestamp_granularities=["segment"]
)
return transcript.text
تكلفة التفريغ عبر Whisper API: 0.36. للخيار المستضاف ذاتياً — Whisper Large-v3 Turbo يفرّغ ملفاً مدته 60 دقيقة في ~17 ثانية (216 ضعف الوقت الفعلي) على GPU حديث.
استراتيجيات التوجيه للنماذج اللغوية: من البسيط إلى المستوى الإنتاجي

الاستراتيجية 1: المشاعر المباشرة (ضعيفة)
النهج الأكثر بساطة — اسأل النموذج مباشرة:
"Is this earnings call positive or negative for the stock price?"
هل يعمل هذا؟ نعم، بشكل مفاجئ. أظهر Lopez-Lira & Tang أن حتى هذا التوجيه البدائي ينتج تنبؤات ذات دلالة إحصائية. لكن هناك مشاكل:
- مخرج ثنائي — تضيع التدرجات. "كارثة" و"خيبة أمل خفيفة" تحصلان على نفس التسمية
- غياب التفسير — غير واضح على أي أساس اتخذ النموذج قراره
- عدم الاستقرار — إعادة التشغيل قد تعطي إجابة مختلفة
الاستراتيجية 2: الاستخراج المنظم مع Chain-of-Thought (قوية)
الفكرة: بدلاً من رقم واحد، استخرج مجموعة منظمة من الإشارات، مع إجبار النموذج على شرح كل خطوة.
from pydantic import BaseModel, Field
from openai import OpenAI
from enum import Enum
from typing import Optional
class SentimentLevel(str, Enum):
VERY_BEARISH = "very_bearish"
BEARISH = "bearish"
NEUTRAL = "neutral"
BULLISH = "bullish"
VERY_BULLISH = "very_bullish"
class GuidanceSurprise(BaseModel):
"""انحراف التوجيه المستقبلي عن توقعات الإجماع."""
revenue_guidance_vs_consensus: Optional[float] = Field(
None, description="نسبة انحراف توجيه الإيرادات عن الإجماع %"
)
margin_guidance_direction: Optional[str] = Field(
None, description="expanding / stable / contracting"
)
key_quote: str = Field(
description="اقتباس حرفي يتضمن التوجيه"
)
reasoning: str = Field(
description="CoT: لماذا هذا التوجيه مهم"
)
class ConfidenceMetrics(BaseModel):
"""مقاييس ثقة الإدارة."""
hedge_word_count: int = Field(
description="عدد كلمات التحوط: 'approximately'، 'potentially'، 'subject to'"
)
forward_looking_ratio: float = Field(
description="نسبة البيانات المستقبلية من إجمالي البيانات"
)
q_and_a_evasion_count: int = Field(
description="عدد الأسئلة التي أعطى فيها CEO/CFO إجابة مراوغة"
)
ceo_vs_cfo_sentiment_delta: float = Field(
description="فرق المشاعر بين CEO وCFO (من -1 إلى 1). التباين علامة تحذير"
)
class CompetitiveIntelligence(BaseModel):
"""إشارات المنافسين والموقف السوقي."""
competitors_mentioned: list[str] = Field(
description="قائمة المنافسين المذكورين"
)
market_share_claims: list[str] = Field(
description="ادعاءات الحصة السوقية"
)
new_product_signals: list[str] = Field(
description="إشارات حول منتجات/خدمات جديدة"
)
class ManagementSignals(BaseModel):
"""إشارات الإدارة."""
turnover_risk: SentimentLevel = Field(
description="مخاطر تغيير الإدارة الرئيسية"
)
tone_shift_from_previous: Optional[str] = Field(
None, description="كيف تغيرت النبرة مقارنة بالربع الماضي"
)
insider_language_flags: list[str] = Field(
description="عبارات دالة: 'exploring strategic alternatives'، 'right-sizing' إلخ"
)
class EarningsCallAnalysis(BaseModel):
"""تحليل كامل لمكالمة الأرباح."""
ticker: str
quarter: str
overall_sentiment: SentimentLevel
sentiment_score: float = Field(description="من -1.0 إلى 1.0")
guidance_surprise: GuidanceSurprise
confidence_metrics: ConfidenceMetrics
competitive_intel: CompetitiveIntelligence
management_signals: ManagementSignals
key_risks: list[str]
key_catalysts: list[str]
one_line_summary: str
def analyze_earnings_call(transcript: str, ticker: str, quarter: str) -> EarningsCallAnalysis:
"""
استخراج إشارات منظمة من مكالمة الأرباح.
التكلفة: ~$0.15-0.30 لكل مكالمة (GPT-4o، ~10K رمز مدخل).
"""
client = OpenAI()
system_prompt = """You are a senior equity research analyst with 20 years of experience.
Analyze the following earnings call transcript and extract structured trading signals.
IMPORTANT INSTRUCTIONS:
1. Use Chain-of-Thought reasoning for each field — explain WHY before giving the value
2. Focus on DEVIATIONS from expectations, not absolute statements
3. Pay special attention to Q&A section — management is less scripted there
4. Compare management's language to typical corporate hedging baseline
5. Flag any "strategic alternatives", "right-sizing", or other euphemisms
6. Score sentiment relative to market expectations, not in absolute terms
HEDGE WORDS TO COUNT: approximately, potentially, subject to, may, might,
could, uncertain, challenging, headwinds, navigate, prudent, cautious,
evolving, dynamic, unprecedented, transitional"""
completion = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Ticker: {ticker}\nQuarter: {quarter}\n\n{transcript}"}
],
response_format=EarningsCallAnalysis,
temperature=0.1, # حرارة منخفضة لقابلية الاستنساخ
)
return completion.choices[0].message.parsed
لاحظ عدة نقاط رئيسية:
مخطط Pydantic — تضمن OpenAI Structured Outputs توافقاً 100% مع المخطط. لا مزيد من "sorry, I cannot parse the JSON". كل حقل له description يعمل كتوجيه مصغر لجانب محدد من التحليل.
Chain-of-Thought داخل المخطط — حقلا reasoning وkey_quote يجبران النموذج على "إظهار عمله". هذا لا يحسن الجودة فحسب (النموذج مجبر على إيجاد اقتباس محدد قبل إصدار الحكم)، بل يخلق أيضاً مسار تدقيق للجهات التنظيمية.
Temperature 0.1 — لا نريد إبداعاً. نحتاج قابلية الاستنساخ. عند Temperature 0 قد "يعلق" النموذج أحياناً في أنماط. 0.1 هو الحل الوسط الأمثل.
الاستراتيجية 3: Few-Shot مع أمثلة تاريخية
أقوى حتى — إعطاء النموذج أمثلة من مكالمات أرباح سابقة مع ردود فعل السوق الفعلية:
few_shot_examples = """
EXAMPLE 1:
Transcript excerpt: "We are cautiously optimistic about the second half...
While we continue to navigate macro headwinds, our pipeline remains robust."
Actual market reaction: -3.2% (next day)
Analysis: Despite surface-level positivity, "cautiously optimistic" is a
DOWNGRADE from previous quarter's "very confident". Five hedge words in
two sentences. Market read through the hedging.
EXAMPLE 2:
Transcript excerpt: "Frankly, demand has exceeded our ability to supply.
We're expediting CapEx to address this."
Actual market reaction: +7.8% (next day)
Analysis: "Frankly" signals genuine surprise even from management.
Accelerated CapEx on demand = strong confidence. No hedging language.
"""
أمثلة Few-shot تساعد النموذج على المعايرة: يتعلم أن "cautiously optimistic" بلغة وول ستريت ليست إيجابية — بل سلبية خفيفة. بدون أمثلة، قد يفسر النموذج الكلمات حرفياً.
أربعة أنواع من الإشارات
1. مفاجأة التوجيه
الإشارة الأكثر مباشرة. تقدم الشركة توقعاتها (التوجيه) للربع/السنة القادمة، ويتفاعل السوق مع الانحراف عن الإجماع. يمكن للنموذج اللغوي استخراج التوجيه حتى عندما تنقله الإدارة بشكل غامض:
- "We expect revenues in the range of..." — توجيه مباشر، سهل التحليل
- "We feel comfortable with current Street estimates" — تأكيد ضمني للإجماع
- "There are puts and takes relative to consensus" — إشارة مخاطر ضمنية
النموذج اللغوي يفهم الصياغات الثلاث؛ التعبيرات النمطية تفهم الأولى فقط.
2. مقاييس الثقة: كثافة كلمات التحوط
هذه إشارتي المفضلة لأنها معاكسة للحدس. الجوهر: المديرون أشخاص ذوو تعليم قانوني وأقسام قانونية مصابة بجنون الارتياب. عندما تسير الأمور على ما يرام، يسمحون لأنفسهم بأن يكونوا محددين. عندما تتفاقم المشاكل — يبدأون التحوط.
مقاييس للمتابعة:
| المقياس | الوصف | إشارة هبوطية |
|---|---|---|
| كثافة كلمات التحوط | نسبة كلمات التحوط لكل 1,000 كلمة | > 15 لكل 1,000 كلمة |
| نسبة اليقين | نسبة "will/expect" مقابل "may/could" | < 1.5 |
| معدل التهرب في Q&A | نسبة الأسئلة بدون إجابة مباشرة | > 30% |
| تباين CEO/CFO | فجوة النبرة بين CEO وCFO | > 0.3 على مقياس [-1, 1] |
النقطة الأخيرة مثيرة بشكل خاص. CEO هو راوي القصص — وظيفته رسم صورة جميلة. CFO هو المسؤول أمام المدققين. عندما يقول CEO "transformative growth ahead" ويتدخل CFO فوراً بـ "while maintaining disciplined cost management" — هذا التباين يشير إلى توترات داخلية.
3. الاستخبارات التنافسية
يمكن للنموذج اللغوي استخراج ذكر المنافسين من النص المكتوب، حتى عندما تتجنب الإدارة الأسماء المباشرة. "The largest player in the market" — هذا ليس لغزاً لـ GPT-4 إذا كان يعرف الصناعة.
إشارة التداول: إذا ذكرت الشركة أ المنافس ب في سياق سلبي خلال مكالمة أرباحها ("we're taking share from...")، فهذا إشارة ليس فقط لـ أ (شراء) بل أيضاً لـ ب (بيع). صفقة أزواج.
4. إشارات تغيير الإدارة
عبارات دالة على تغيير الإدارة أو تحول استراتيجي:
- "Exploring strategic alternatives" — بيع الشركة المحتمل
- "Right-sizing our operations" — تسريح جماعي
- "The board has initiated a comprehensive review" — CEO سيغادر قريباً
- "We're bringing in fresh perspectives" — الفريق الحالي فشل
كل من هذه العبارات لها ارتباط ذو دلالة إحصائية مع ديناميكيات الأسعار اللاحقة. يمكن للنموذج اللغوي اكتشافها بصفر إنذارات كاذبة — لأنه يفهم السياق، على عكس التعبيرات النمطية التي قد تلتقط "strategic alternatives" في وصف خط المنتجات.
الاختبار الرجعي: منهجية دراسة الأحداث
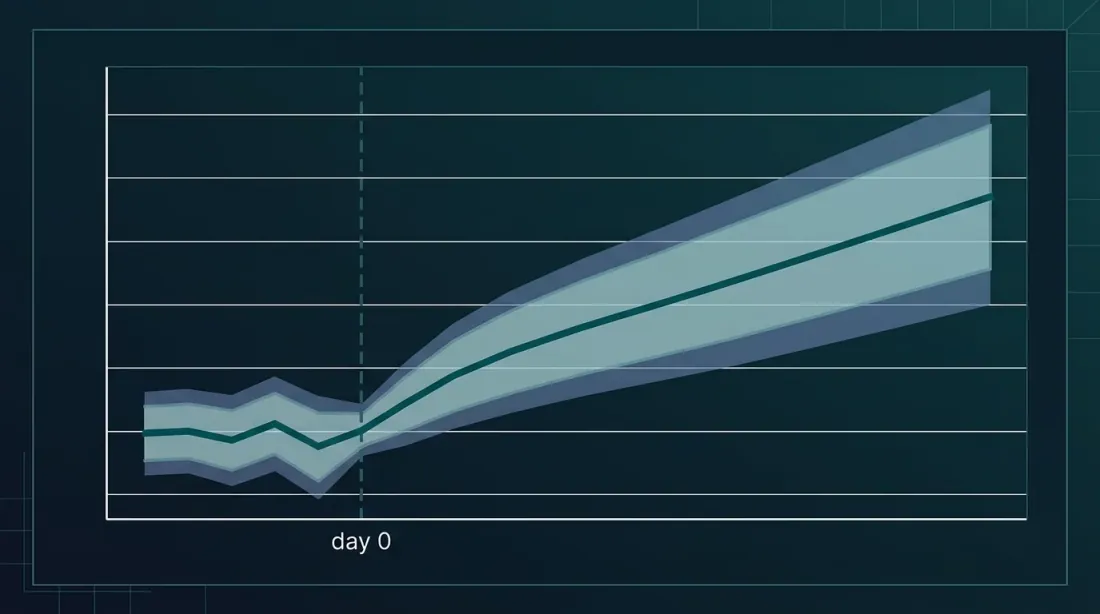
نحن ننتج الإشارات — ممتاز. لكن هل تعمل؟ الطريقة المعيارية للتحقق هي دراسة الأحداث مع حساب العوائد التراكمية غير الطبيعية (CAR).
المنهجية
- تحديد الحدث — تاريخ مكالمة الأرباح
- نافذة التقدير — [-250, -30] يوم تداول قبل الحدث لتقدير العائد "الطبيعي"
- نافذة الحدث — [-1, +60] يوماً حول الحدث
- حساب العائد الطبيعي عبر نموذج السوق:
- العائد غير الطبيعي — الفرق بين العائد الفعلي و"الطبيعي"
- CAR — المجموع التراكمي للعوائد غير الطبيعية خلال نافذة الحدث
import numpy as np
import pandas as pd
from scipy import stats
from dataclasses import dataclass
@dataclass
class EventStudyResult:
car: np.ndarray # العوائد التراكمية غير الطبيعية يومياً
t_stats: np.ndarray # إحصائيات t لكل يوم
avg_car_3d: float # CAR[-1, +1]
avg_car_30d: float # CAR[-1, +30]
avg_car_60d: float # CAR[-1, +60]
p_value_3d: float
p_value_30d: float
n_events: int
def run_event_study(
returns: pd.DataFrame, # عوائد الأسهم اليومية (columns = رموز)
market_returns: pd.Series, # عوائد مؤشر السوق اليومية
events: pd.DataFrame, # DataFrame بأعمدة: [ticker, date, signal_score]
estimation_window: int = 220,
gap: int = 30,
event_window: tuple = (-1, 60),
) -> EventStudyResult:
"""
دراسة أحداث لتقييم القدرة التنبؤية لإشارات LLM.
ترتيب الأحداث حسب signal_score، تشكيل محافظ شراء/بيع،
حساب CAR واختبار الدلالة الإحصائية.
"""
all_cars = []
for _, event in events.iterrows():
ticker = event['ticker']
event_date = event['date']
if ticker not in returns.columns:
continue
try:
event_idx = returns.index.get_loc(event_date, method='ffill')
except KeyError:
continue
est_start = event_idx - estimation_window - gap
est_end = event_idx - gap
if est_start < 0:
continue
y = returns.iloc[est_start:est_end][ticker].values
x = market_returns.iloc[est_start:est_end].values
mask = ~(np.isnan(y) | np.isnan(x))
if mask.sum() < 60: # حد أدنى 60 مشاهدة
continue
y_clean, x_clean = y[mask], x[mask]
slope, intercept, _, _, _ = stats.linregress(x_clean, y_clean)
residual_std = np.std(y_clean - (intercept + slope * x_clean))
ev_start = event_idx + event_window[0]
ev_end = event_idx + event_window[1] + 1
if ev_end > len(returns):
continue
actual = returns.iloc[ev_start:ev_end][ticker].values
market = market_returns.iloc[ev_start:ev_end].values
expected = intercept + slope * market
ar = actual - expected
car = np.cumsum(ar)
all_cars.append(car)
if not all_cars:
raise ValueError("No valid events found")
min_len = min(len(c) for c in all_cars)
all_cars = np.array([c[:min_len] for c in all_cars])
mean_car = np.mean(all_cars, axis=0)
std_car = np.std(all_cars, axis=0) / np.sqrt(len(all_cars))
t_stats = mean_car / (std_car + 1e-10)
offset = -event_window[0] # الإزاحة إلى تاريخ الحدث
car_3d = mean_car[min(offset + 1, min_len - 1)] if min_len > offset + 1 else mean_car[-1]
car_30d = mean_car[min(offset + 30, min_len - 1)] if min_len > offset + 30 else mean_car[-1]
car_60d = mean_car[min(offset + 60, min_len - 1)] if min_len > offset + 60 else mean_car[-1]
n = len(all_cars)
p_3d = 2 * (1 - stats.t.cdf(abs(car_3d / (np.std([c[min(offset+1, min_len-1)] for c in all_cars]) / np.sqrt(n) + 1e-10)), df=n-1))
p_30d = 2 * (1 - stats.t.cdf(abs(car_30d / (np.std([c[min(offset+30, min_len-1)] for c in all_cars]) / np.sqrt(n) + 1e-10)), df=n-1))
return EventStudyResult(
car=mean_car,
t_stats=t_stats,
avg_car_3d=car_3d,
avg_car_30d=car_30d,
avg_car_60d=car_60d,
p_value_3d=p_3d,
p_value_30d=p_30d,
n_events=n,
)
def backtest_llm_signals(
llm_signals: pd.DataFrame, # [ticker, date, sentiment_score]
returns: pd.DataFrame,
market_returns: pd.Series,
):
"""اختبار رجعي: شراء الخُمس الأعلى، بيع الخُمس الأدنى."""
llm_signals['quintile'] = pd.qcut(
llm_signals['sentiment_score'], 5, labels=[1, 2, 3, 4, 5]
)
long_events = llm_signals[llm_signals['quintile'] == 5].copy()
short_events = llm_signals[llm_signals['quintile'] == 1].copy()
long_result = run_event_study(returns, market_returns, long_events)
short_result = run_event_study(returns, market_returns, short_events)
print(f"LONG portfolio (top quintile LLM sentiment):")
print(f" CAR[0,+3]: {long_result.avg_car_3d:+.2%} (p={long_result.p_value_3d:.4f})")
print(f" CAR[0,+30]: {long_result.avg_car_30d:+.2%} (p={long_result.p_value_30d:.4f})")
print(f" N events: {long_result.n_events}")
print(f"\nSHORT portfolio (bottom quintile LLM sentiment):")
print(f" CAR[0,+3]: {short_result.avg_car_3d:+.2%} (p={short_result.p_value_3d:.4f})")
print(f" CAR[0,+30]: {short_result.avg_car_30d:+.2%} (p={short_result.p_value_30d:.4f})")
print(f" N events: {short_result.n_events}")
ls_3d = long_result.avg_car_3d - short_result.avg_car_3d
ls_30d = long_result.avg_car_30d - short_result.avg_car_30d
print(f"\nLONG-SHORT spread:")
print(f" CAR[0,+3]: {ls_3d:+.2%}")
print(f" CAR[0,+30]: {ls_30d:+.2%}")
ما نتوقع رؤيته
بناءً على الأبحاث الحالية، CAR واقعية لإشارات LLM:
| النافذة | محفظة الشراء | محفظة البيع | فارق الشراء/البيع |
|---|---|---|---|
| [0, +1] | +0.8% — +1.5% | -0.5% — -1.2% | 1.3% — 2.7% |
| [0, +30] | +1.5% — +3.0% | -1.0% — -2.5% | 2.5% — 5.5% |
| [0, +60] | +2.0% — +4.0% | -1.5% — -3.5% | 3.5% — 7.5% |
المؤشر الرئيسي هو الدلالة الإحصائية. عند p < 0.01 وN > 200 حدث، يمكن الحديث عن إشارة متينة. عند p > 0.05 — قد يكون ضوضاء.
التنفيذ الإنتاجي: من Jupyter إلى الإنتاج
بنية خط الأنابيب الفوري
YouTube/Audio Stream
│
▼
┌─────────────────┐ ┌──────────────────┐
│ Whisper │───▶│ Transcript │
│ Transcription │ │ Buffer │
│ (streaming) │ │ (Redis Stream) │
└─────────────────┘ └──────────────────┘
│
┌─────────┴─────────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Real-time │ │ Full-call │
│ Chunk Anal. │ │ Analysis │
│ (every 5min) │ │ (after call │
│ │ │ ends) │
└──────────────┘ └──────────────┘
│ │
▼ ▼
┌──────────────────────────────┐
│ Signal Aggregator │
│ (confidence-weighted merge) │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ Trading Engine │
│ (position sizing, risk mgmt)│
└──────────────────────────────┘
تحليل التكاليف: كم تكلف مكالمة أرباح واحدة
دعونا نحلل اقتصاديات معالجة مكالمة أرباح واحدة في الإنتاج:
| المكون | التكلفة | زمن الاستجابة |
|---|---|---|
| تفريغ Whisper API (60 دقيقة) | $0.36 | ~17 ثانية (Turbo) |
| استخراج منظم GPT-4o | $0.15-0.30 | ~8-15 ثانية |
| تحليل أجزاء فوري GPT-4o (x12) | $1.80-3.60 | ~5 ثوانٍ لكل جزء |
| Embedding لتخزين RAG | $0.01 | <1 ثانية |
| المجموع (خط الأنابيب الكامل) | $2.30-4.30 | ~30 ثانية |
لحظة، كانت التقديرات $30-50 لكل مكالمة. من أين جاءت هذه الأرقام؟ يعتمد على النموذج والنهج:
- الخيار الاقتصادي (GPT-4o-mini، تمرير واحد): $0.50-1.00
- الخيار القياسي (GPT-4o، استخراج منظم + تحليل أجزاء): $2-5
- الخيار المتقدم (GPT-4o، تمريرات متعددة، تحقق متبادل، مقارنة تاريخية): $15-30
- مستوى صناديق التحوط (نماذج متعددة + مراجعة بشرية + بث فوري): $30-50+
لصندوق كم يتداول 500 رمز، تكلفة معالجة موسم الأرباح (~2,000 مكالمة في 6 أسابيع) هي 10,000 بالخيار القياسي. بمتوسط ألفا لكل مركز 1-3% — العائد على الاستثمار فلكي.
زمن الاستجابة: سباق المللي ثانية
في عالم التداول عالي التردد، زمن الاستجابة هو كل شيء. لكن بالنسبة للاستراتيجيات القائمة على الأرباح، الوضع مختلف:
- مكالمة الأرباح تستمر 45-60 دقيقة — لديك وقت
- PEAD يمتد 60 يوماً — لا حاجة للدخول في الثانية الأولى
- الانزياح الرئيسي يحدث في أول 30 دقيقة بعد انتهاء المكالمة
الاستراتيجية المثلى هي ثنائية المرحلة:
- المرحلة 1 (فورية): تحليل أجزاء كل 5 دقائق أثناء المكالمة، تشكيل إشارة أولية
- المرحلة 2 (بعد المكالمة): تحليل كامل للنص خلال 2-5 دقائق بعد الانتهاء
المرحلة 1 تمنح أفضلية 5-10 دقائق على المشاركين في السوق الذين ينتظرون انتهاء المكالمة. بالنسبة لأسهم الشركات المتوسطة، هذا كافٍ.
التوسع نحو العملات المشفرة: حوكمة DeFi ومقترحات DAO
سوق العملات المشفرة هو ميدان اختبار مثالي لتنقيب ألفا بالنماذج اللغوية. والسبب:
- عدد أقل من اللاعبين المؤسسيين — أي عدم كفاءة أكثر لاستغلالها
- الحوكمة = مكالمة أرباح — قرارات DAO تؤثر مباشرة على اقتصاديات الرمز
- سوق يعمل 24/7 — يمكن تداول ردة الفعل فوراً
- بيانات عامة — جميع المقترحات والتصويتات على السلسلة
أنواع أحداث العملات المشفرة للتحليل
مقترحات الحوكمة (Aave، Compound، Uniswap)
يغير المقترح معاملات البروتوكول — أسعار الفائدة، عوامل الضمان، مفاتيح الرسوم. يمكن للنموذج اللغوي تقييم الأثر الاقتصادي:
crypto_analysis_prompt = """Analyze this DeFi governance proposal.
Extract:
1. Economic impact on token holders (positive/negative/neutral)
2. TVL impact estimate (increase/decrease/stable + magnitude)
3. Competitive positioning vs other protocols
4. Risk factors introduced by the proposal
5. Historical precedent (similar proposals in other protocols)
6. Likely voting outcome based on forum discussion sentiment
Proposal: {proposal_text}
Forum discussion: {discussion_text}
"""
إعلانات تحديث البروتوكول
عندما يعلن Uniswap عن v4 مع hooks، أو يطلق Aave عملة GHO — هذا يعادل إطلاق منتج في التمويل التقليدي. يمكن للنموذج اللغوي تقييم زخم السردية والأهمية التقنية.
تقارير الخزينة
تمتلك المنظمات اللامركزية الكبرى خزائن بمئات الملايين. تقارير الخزينة الفصلية هي نظير مباشر للأرباح. المدرج، معدل الحرق، التنويع — كلها قابلة لتحليل النماذج اللغوية.
خصوصية إشارات العملات المشفرة
على عكس التمويل التقليدي، في العملات المشفرة:
- البيانات على السلسلة تؤكد أو تنفي السردية — يمكن مقارنة ما يُقال في مكالمات الحوكمة مع مقاييس البروتوكول الفعلية (TVL، الحجم، المستخدمون النشطون)
- محافظ الحيتان كتداول من الداخل — تحركات المحافظ الكبيرة بعد نقاشات الحوكمة غالباً تسبق التصويت
- تضخيم المشاعر عبر CT (Crypto Twitter) — إشارة من مكالمة حوكمة يمكن أن تُضخم أو تُكبت بسردية تويتر
المزالق والقيود
الهلوسة: عندما يختلق النموذج أرقاماً
قد "يستخرج" النموذج اللغوي توجيهاً لم يكن في النص المكتوب. هذا خطير بشكل خاص عند تحليل كثافة كلمات التحوط: قد يعدّ النموذج كلمات أكثر أو أقل مما هو موجود فعلاً.
الحل: تحقق ثنائي المرحلة. النموذج اللغوي يستخرج، الكود الحتمي يتحقق. لكلمات التحوط — عدّ بالتعبيرات النمطية بالتوازي مع تقييم النموذج. انحراف > 20% — علامة للمراجعة اليدوية.
import re
HEDGE_WORDS = [
r'\bapproximately\b', r'\bpotentially\b', r'\bsubject to\b',
r'\bmay\b', r'\bmight\b', r'\bcould\b', r'\buncertain\b',
r'\bchallenging\b', r'\bheadwinds\b', r'\bnavigate\b',
r'\bprudent\b', r'\bcautious\b', r'\bevolving\b',
r'\bdynamic\b', r'\bunprecedented\b', r'\btransitional\b',
]
def verify_hedge_count(text: str, llm_count: int) -> dict:
"""تحقق حتمي من عدّ النموذج لكلمات التحوط."""
regex_count = sum(
len(re.findall(pattern, text, re.IGNORECASE))
for pattern in HEDGE_WORDS
)
deviation = abs(llm_count - regex_count) / (regex_count + 1)
return {
"llm_count": llm_count,
"regex_count": regex_count,
"deviation": deviation,
"needs_review": deviation > 0.2,
}
قيود نافذة السياق
حتى 128K رمز قد لا يكفي إذا أردت إدخال:
- النص الحالي (~10K رمز)
- نص الربع السابق للمقارنة (~10K)
- توقعات إجماع المحللين (~2K)
- أمثلة Few-shot (~3K)
- System prompt (~1K)
المجموع ~26K — نستوعب ذلك. لكن إذا أضفنا تقرير 10-K (~80-120K رمز) للسياق — نكون على الحافة. الحل: RAG لاسترجاع الأجزاء ذات الصلة من الوثائق الطويلة.
التحيز والأخطاء المنهجية
تُدرب النماذج اللغوية على بيانات تاريخية حيث ارتبطت عبارات معينة بنتائج معينة. لكن السوق يتكيف:
- إذا بدأ الجميع بعدّ كلمات التحوط باستخدام GPT-4، سيغير المديرون لغتهم
- قد يبالغ النموذج في تقدير أهمية أنماط من بيانات التدريب (تحيز البقاء)
- اللغة المؤسسية تتطور: "synergies" في 2010 كانت تعني شيئاً، في 2026 شيئاً آخر
مخاطر الصفقة المزدحمة
إذا استخدم 50 صندوق كم نفس GPT-4 لتحليل نفس النصوص — تتدهور الإشارة. قياساً: عندما بدأ الجميع بتداول PEAD على المفاجآت الرقمية، تقلص الشذوذ. سيحدث نفس الشيء مع الإشارات النصية، لكن بتأخير:
- الآن (2026) — قلة يستخدمون النماذج اللغوية بشكل منهجي لمكالمات الأرباح. ألفا كبيرة
- خلال 2-3 سنوات — تبنٍّ واسع، ألفا تنخفض
- خلال 5 سنوات — إشارات LLM الأساسية تصبح سلعة، الأفضلية تبقى فقط في النماذج المخصصة والبيانات الفريدة
هذه هي دورة حياة إشارة ألفا المعيارية. استمتع بها ما دامت متاحة.
بدلاً من الخاتمة: خطة العمل
إذا أردت البدء باستخدام النماذج اللغوية لتحليل مكالمات الأرباح، إليك الخطة الدنيا القابلة للتطبيق:
- ابدأ بالبيانات المجانية — SEC EDGAR + EdgarTools لملفات 8-K/10-Q
- استخدم الاستخراج المنظم — مخططات Pydantic عبر OpenAI Structured Outputs
- اختبر رجعياً بدراسة الأحداث — CAR على البيانات التاريخية، حد أدنى 200 حدث
- أضف أمثلة few-shot — 5-10 أمثلة مُعلّمة تحسن الجودة جذرياً
- تحقق حتمياً — النموذج يستخرج، التعبيرات النمطية تتحقق، الإنسان يراجع
- ابدأ بالشركات المتوسطة — ألفا أكثر، منافسة أقل مع الصناديق الكبرى
- توسع نحو العملات المشفرة — مكالمات الحوكمة ومقترحات DAO كأرض غير مستكشفة
تذكر القاعدة الذهبية للتحليل الكمي: إذا بدت الإشارة جيدة جداً لتكون حقيقية — تحقق مرة أخرى. تخلق النماذج اللغوية وهم الفهم، لكن وراءه مطابقة أنماط إحصائية. أداة قوية — لكنها أداة، وليست عرّافة.
المراجع
-
Ball, R., Brown, P. (1968). An Empirical Evaluation of Accounting Income Numbers. Journal of Accounting Research, 6(2), 159-178. — أول اكتشاف لـ PEAD.
-
Bernard, V.L., Thomas, J.K. (1989). Post-Earnings-Announcement Drift: Delayed Price Response or Risk Premium? Journal of Accounting Research, 27, 1-36. — الورقة المرجعية لـ PEAD.
-
Loughran, T., McDonald, B. (2011). When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. Journal of Finance, 66(1), 35-65. — قاموس المشاعر المالية.
-
Araci, D. (2019). FinBERT: Financial Sentiment Analysis with Pre-trained Language Models. arXiv:1908.10063. — BERT للمعالجة اللغوية المالية، +14 نقطة مئوية عن SOTA.
-
Wu, S. et al. (2023). BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564. — نموذج Bloomberg بـ 50 مليار معامل.
-
Yang, H. et al. (2023). FinGPT: Open-Source Financial Large Language Models. arXiv:2306.06031. — بديل مفتوح المصدر لـ BloombergGPT، دقة 89%.
-
Lopez-Lira, A., Tang, Y. (2023). Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models. arXiv:2304.07619. — GPT-4 يتنبأ بالعوائد بمعدل إصابة ~90%.
-
Meursault, V., Liang, P.J., Routledge, B., Scanlon, M.M. (2023). PEAD.txt: Post-Earnings-Announcement Drift Using Text. Journal of Financial and Quantitative Analysis. — PEAD النصي يبلغ ضعف PEAD الرقمي.
-
Fatouros, G. et al. (2024). Can Large Language Models Beat Wall Street? Evaluating GPT-4's Impact on Financial Decision-Making with MarketSenseAI. Neural Computing and Applications. — إطار GPT-4 بألفا فائضة 10-30% على S&P 100.
-
Chen, Y. et al. (2025). GPT-Signal: Generative AI for Semi-automated Feature Engineering in the Alpha Research Process. arXiv:2410.18448. — توليد آلي لإشارات التداول عبر LLM.
-
Zhang, X. et al. (2025). Can LLMs Hit Moving Targets? Tracking Evolving Signals in Corporate Disclosures. arXiv:2510.03195. — اكتشاف "الأهداف المتحركة" في الإفصاحات المؤسسية.
-
Chen, Z. et al. (2025). Large Language Models in Equity Markets: Applications, Techniques, and Insights. Frontiers in Artificial Intelligence. — مراجعة 84 دراسة LLM في التمويل.
هذا المقال ذو طابع تعليمي ولا يشكل نصيحة استثمارية. أي استراتيجيات تداول موصوفة هنا تتطلب اختباراً رجعياً شاملاً وإدارة مخاطر قبل الاستخدام مع رأس مال حقيقي.
MarketMaker.cc Team
البحوث والاستراتيجيات الكمية
Read More
أنواع الأوامر في التداول الخوارزمي: من أوامر الحد المطاردة إلى الأوامر الافتراضية

ZigBolt: لماذا بنينا نظام Aeron الخاص بنا بلغة Zig وحققنا 20 نانوثانية لكل رسالة
